相关博客
【自然语言处理】【大模型】极低资源微调大模型方法LoRA以及BLOOM-LORA实现代码
【自然语言处理】【大模型】DeepMind的大模型Gopher
【自然语言处理】【大模型】Chinchilla:训练计算利用率最优的大语言模型
【自然语言处理】【大模型】大语言模型BLOOM推理工具测试
【自然语言处理】【大模型】GLM-130B:一个开源双语预训练语言模型
【自然语言处理】【大模型】用于大型Transformer的8-bit矩阵乘法介绍
【自然语言处理】【大模型】BLOOM:一个176B参数且可开放获取的多语言模型
【自然语言处理】【大模型】PaLM:基于Pathways的大语言模型
【自然语言处理】【chatGPT系列】大语言模型可以自我改进
一、LoRA的原理
LoRA是一种以极低资源微调大模型的方法,其来自于论文LoRA: Low-Rank Adaptation of Large Language Models。
1. 大模型微调的困境
随着模型规模的不断扩大,模型会"涌现"出各种能力。特别是对大语言模型(LLM)来说,随着规模的扩大其在zero-shot、常识推理等能力上会有大幅度的提高。相比于规模较小的模型,大模型的微调成本和部署成本都非常高。例如,GPT-3 175B模型微调需要1.2TB的显存。此外,若针对不同下游任务微调多个模型,那么就需要为每个下游任务保存一份模型权重,成本非常高。在某些场景下,甚至可能需要针对不同的用户微调不同的模型,那么模型微调和部署的成本将不可接受。
因此,如何降低大模型微调和部署成本,将是大模型商用的重要一环。
2. LoRA之前的方法
在LoRA方法提出之前,也有很多方法尝试解决大模型微调困境的方法。其中有两个主要的方向:(1) 添加adapter层;(2) 由于某种形式的输入层激活。但是这两种方法都有局限性:
2.1 Adapter层会引入推理时延
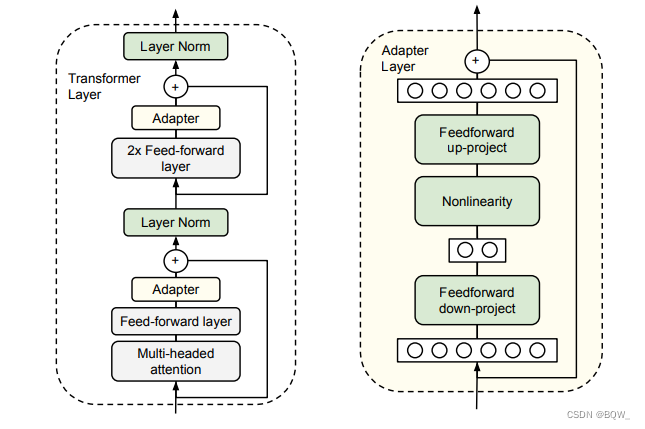
简单来说,adapter就是固定原有的参数,并添加一些额外参数用于微调。上图中会在原始的transformer block中添加2个adapter,一个在多头注意力后面,另一个这是FFN后面。
显然,adapter会在模型中添加额外的层,这些层会导致大模型在推理时需要更多的GPU通信,而且也会约束模型并行。这些问题都将导致模型推理变慢。
2.2 prefix-tuning难以优化

prefix-tuning方法是受语言模型in-context learning能力的启发,只要有合适的上下文则语言模型可以很好的解决自然语言任务。但是,针对特定的任务找到离散token的前缀需要花费很长时间,prefix-tuning提出使用连续的virtual token embedding来替换离散token。
具体来说,对于transformer中的每一层,都在句子表征前面插入可训练的virtual token embedding。对于自回归模型(GPT系列),在句子前添加连续前缀,即 z = [ PREFIX ; x ; y ] z=[\text{PREFIX};x;y] z=[PREFIX;x;y]。对于Encoder-Decoder模型(T5),则在Ecoder和Decoder前都添加连续前缀 z = [ PREFIX ; x ∣ PREFIX ′ ; y ] z=[\text{PREFIX};x|\text{PREFIX}';y] z=[PREFIX;x∣PREFIX′;y]。添加前缀的过程如上图所示。
虽然,prefix-tuning并没有添加太多的额外参数。但是,prefix-tuning难以优化,且会减少下游任务的序列长度。
3. 问题的正式表述
术语与约定。由于LoRA原理的介绍,会使用Transformer架构。因此,这里先给出一些术语约定。一个Transformer层的输入和输出维度尺寸为 d m o d e l d_{model} dmodel,使用 W q W_q Wq、 W k W_k Wk、 W v W_v Wv和 W o W_o Wo表示自注意力模块中的query/key/value/output投影矩阵。 W W W或 W 0 W_0 W0表示预训练模型的权重矩阵, Δ W \Delta W ΔW表示模型在适配过程中的梯度更新。 r r r来表示LoRA模块的秩。使用Adam作为模型优化器,Transformer MLP前馈层的维度为 d f f n = 4 × d m o d e l d_{ffn}=4\times d_{model} dffn=4×dmodel。
问题表述。LoRA虽然与训练目标无关,这里还是以语言建模为例。假设给定一个预训练的自回归语言模型 P Φ ( y ∣ x ) P_{\Phi}(y|x) PΦ(y∣x), Φ \Phi Φ是模型参数。目标是使该语言模型适应下游的摘要、机器阅读理解等任务。每个下游任务都有context-target样本对组成的训练集: Z = { ( x i , y i ) } i = 1 , … , N \mathcal{Z}=\{(x_i,y_i)\}_{i=1,\dots,N} Z={(xi,yi)}i=1,…,N,其中 x i x_i xi和 y i y_i yi都是token序列。例如,对于摘要任务, x i x_i xi是文章内容, y i y_i yi是摘要。
在完整微调的过程中,模型使用预训练好的权重
Φ
0
\Phi_0
Φ0来初始化模型,然后通过最大化条件语言模型来更新参数
Φ
0
+
Δ
Φ
\Phi_0+\Delta\Phi
Φ0+ΔΦ:
max
Φ
∑
(
x
,
y
)
∈
Z
∑
t
=
1
∣
y
∣
log
(
P
Φ
(
y
t
∣
x
,
y
<
t
)
)
(1)
\max_{\Phi}\sum_{(x,y)\in \mathcal{Z}}\sum_{t=1}^{|y|}\log (P_\Phi(y_t|x,y_{<t})) \tag{1}
Φmax(x,y)∈Z∑t=1∑∣y∣log(PΦ(yt∣x,y<t))(1)
完整微调的主要缺点:对于每个下游任务,都需要学习不同的参数更新
Δ
Φ
\Delta\Phi
ΔΦ,其中维度
∣
Δ
Φ
∣
=
∣
Φ
0
∣
|\Delta\Phi|=|\Phi_0|
∣ΔΦ∣=∣Φ0∣。因此,如果预训练模型很大,存储和部署许多独立的微调模型实例非常有挑战。
LoRA为了更加的参数高效,使用相对非常小的参数
Θ
\Theta
Θ来表示任务相关的参数增量
Δ
Φ
=
Δ
Φ
(
Θ
)
\Delta\Phi=\Delta\Phi(\Theta)
ΔΦ=ΔΦ(Θ),其中
∣
Θ
∣
≪
∣
Φ
0
∣
|\Theta|\ll |\Phi_0|
∣Θ∣≪∣Φ0∣。寻找
Δ
Φ
\Delta\Phi
ΔΦ的任务就变成对
Θ
\Theta
Θ的优化
max
Θ
∑
(
x
,
y
)
∈
Z
∑
t
=
1
∣
y
∣
log
(
p
Φ
0
+
Δ
Φ
(
Θ
)
(
y
t
∣
x
,
y
<
t
)
)
(2)
\max_{\Theta}\sum_{(x,y)\in\mathcal{Z}}\sum_{t=1}^{|y|}\log(p_{\Phi_0+\Delta\Phi(\Theta)}(y_t|x,y_{<t})) \tag{2}
Θmax(x,y)∈Z∑t=1∑∣y∣log(pΦ0+ΔΦ(Θ)(yt∣x,y<t))(2)
LoRA将会使用低秩表示来编码
Δ
Φ
\Delta\Phi
ΔΦ,同时实现计算高效和存储高效。当预训练模型是175B GPT-3,可训练参数
∣
Θ
∣
|\Theta|
∣Θ∣可以小至
∣
Φ
0
∣
|\Phi_0|
∣Φ0∣的
0.01
%
0.01\%
0.01%。
4. LoRA
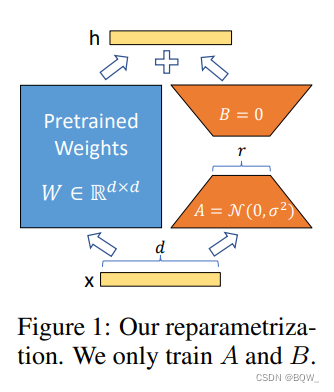
通常,神经网络中会包含许多进行矩阵乘法的稠密层,这些层通常是满秩的。Adgajanyan et al.等人的研究表示预训练语言模型具有低的"内在维度"。受该工作的启发,在模型适配下游任务的过程中,权重更新也应该具有低的“内在秩”。对于预训练权重矩阵
W
0
∈
R
d
×
k
W_0\in\mathbb{R}^{d\times k}
W0∈Rd×k,可以通过低秩分解来表示其更新
W
0
+
Δ
W
=
W
0
+
B
A
W_0+\Delta W=W_0+BA
W0+ΔW=W0+BA,
B
∈
R
d
×
r
,
A
∈
R
r
×
k
B\in\mathbb{R}^{d\times r},A\in\mathbb{R}^{r\times k}
B∈Rd×r,A∈Rr×k且秩
r
≪
min
(
d
,
k
)
r\ll\min(d,k)
r≪min(d,k)。在训练过程中,
W
0
W_0
W0被冻结且不接受梯度更新,
A
A
A和
B
B
B则是可训练参数。注意,
W
0
W_0
W0和
Δ
W
=
B
A
\Delta W=BA
ΔW=BA都会乘以相同的输入。对于
h
=
W
0
x
h=W_0x
h=W0x,前向传播变为:
h
=
W
0
x
+
Δ
W
x
=
W
0
x
+
B
A
x
(3)
h=W_0x+\Delta Wx=W_0x+BAx \tag{3}
h=W0x+ΔWx=W0x+BAx(3)
对矩阵 A A A使用随机高斯初始化,对矩阵 B B B使用0进行初始化,因此 Δ W = B A \Delta W=BA ΔW=BA在训练的开始为0。使用 α r \frac{\alpha}{r} rα来缩放 Δ W x \Delta Wx ΔWx,其中 α \alpha α是小于 r r r的常数。当使用Adam优化时,经过适当的缩放初始化,调优 α \alpha α与调优学习率大致相同。
当进行部署时,以显式的计算和存储 W = W 0 + B A W=W_0+BA W=W0+BA,并正常执行推理。 W 0 W_0 W0和 B A BA BA都是 R d × k \mathbb{R}^{d\times k} Rd×k。当需要转换至另一个下游任务,可以通过减去 B A BA BA来恢复 W 0 W_0 W0,然后添加不同的 B ′ A ′ B'A' B′A′。至关重要的是,这保证不会引人任何额外的推理时延。
5. LoRA应用于Transformer
理论上,LoRA可以应用于任何神经网络的权重矩阵,从而减少可训练参数的数量。Transformer架构中的自注意力模块有4个权重矩阵: W q , W k , W v , W o W_q,W_k,W_v,W_o Wq,Wk,Wv,Wo,以及两个MLP模型的权重矩阵。将 W q W_q Wq(或者 W k , W v W_k,W_v Wk,Wv)作为一个维度为 d m o d e l × d m o d e l d_{model}\times d_{model} dmodel×dmodel的单个矩阵。为了简单和参数高效,本研究仅限于适配下游任务的注意力权重,并冻结MLP模块。
优点。最显著的优点是显存和存储空间的减少。对于使用Adam训练的大型Transformer,若 r ≪ d m o d e l r\ll d_{model} r≪dmodel,由于不需要存储被冻结参数的优化器状态,VRAM使用量减少2/3。对于GPT-3 175B,训练中的显存消耗从1.2TB减少自350GB。当 r = 4 r=4 r=4并且仅调整query矩阵和value矩阵时,checkpoint大小减少10000倍(从350GB减少自35MB)。另一个优点是,可以在部署时以更低的成本切换任务,仅需要交换LoRA权重即可。此外,与完全微调相比,GPT-3 175B训练速度提高了25%,因为不需要计算绝大多数参数的梯度。
二、代码:实现BLOOM-LoRA
本小节展示如何使用LoRA微调大语言模型bloom。
-
数据:使用BELLE提供的100万指令微调数据;
-
模型:使用bloomz-7b1-mt,该版本的bloomz也是经过指令微调后的模型。BLOOM原理见:
【自然语言处理】【大模型】BLOOM:一个176B参数且可开放获取的多语言模型
-
依赖包:使用transformers提供模型加载和训练;使用peft提供LoRA实现;使用DeepSpeed提供训练假设。
注意:peft包目前还处于快速迭代当中,后续接口可能会有大的变动,也可能存在一些bug。关键依赖包版本:
transformers==4.26.1
torch==1.13.1
deepspeed==0.8.2
peft==0.2.0
1. 训练代码
为了简洁,假设训练代码位于train.py。
1.1 导入依赖包
import os
import torch
import random
import datasets
import numpy as np
from tqdm import tqdm
from typing import Dict
from torch.utils.data import DataLoader
from transformers import (
AutoModelForCausalLM,
AutoTokenizer,
DataCollatorForSeq2Seq,
TrainingArguments,
Trainer
)
from peft import (
LoraConfig,
TaskType,
get_peft_model,
get_peft_model_state_dict,
set_peft_model_state_dict
)
def set_random_seed(seed):
if seed is not None and seed > 0:
random.seed(seed)
np.random.seed(seed)
torch.manual_seed(seed)
torch.random.manual_seed(seed)
torch.cuda.manual_seed(seed)
torch.cuda.manual_seed_all(seed)
torch.backends.cudnn.deterministic = True
set_random_seed(1234)
1.2 设置参数
# LoRA参数
LORA_R = 8
LORA_ALPHA = 32
LORA_DROPOUT = 0.1
# 训练参数
EPOCHS=3
LEARNING_RATE=5e-5
OUTPUT_DIR="./checkpoints"
BATCH_SIZE=4 # 2
GRADIENT_ACCUMULATION_STEPS=3
# 其他参数
MODEL_PATH = "bigscience/bloomz-7b1-mt"
DATA_PATH = "./data/belle_open_source_1M.train.json"
MAX_LENGTH = 512
PATTERN = "{}\n{}"
DS_CONFIG = "ds_zero2_config.json"
tokenizer = AutoTokenizer.from_pretrained(MODEL_PATH) # 加载tokenizer
1.3 加载数据
dataset = datasets.load_dataset("json", data_files=DATA_PATH)
# print(dataset["train"][0])
1.4 tokenize
def tokenize(text: str, add_eos_token=True):
result = tokenizer(
text,
truncation=True,
max_length=MAX_LENGTH,
padding=False,
return_tensors=None)
# 判断是否要添加eos_token
if (result["input_ids"][-1] != tokenizer.eos_token_id
and len(result["input_ids"]) < MAX_LENGTH
and add_eos_token):
result["input_ids"].append(tokenizer.eos_token_id)
result["attention_mask"].append(1)
result["labels"] = result["input_ids"].copy()
return result
def preprocess(example: Dict, train_on_inputs: bool = False):
prompt = example["input"]
response = example["target"]
text = PATTERN.format(prompt, response)
tokenized_inp = tokenize(text)
# 若train_on_inputs为False,则将label中与input相关的token替换为-100
if not train_on_inputs:
tokenized_prompt = tokenize(prompt,add_eos_token=False)
prompt_tokens_len = len(tokenized_prompt["input_ids"])
tokenized_inp["labels"] = [-100]*prompt_tokens_len + tokenized_inp["labels"][prompt_tokens_len:]
return tokenized_inp
train_data = dataset["train"].shuffle().map(preprocess, remove_columns=["id", "input", "target"])
print(train_data[0])
1.5 collate_fn
# pad_to_multiple_of=8表示padding的长度是8的倍数
collate_fn = DataCollatorForSeq2Seq(tokenizer, pad_to_multiple_of=8, return_tensors="pt", padding=True)
1.6 加载模型
device_map = {"": int(os.environ.get("LOCAL_RANK") or 0)}
# device_map指定模型加载的GPU;troch_dtype=torch.float16表示半精度加载模型
model = AutoModelForCausalLM.from_pretrained(MODEL_PATH, torch_dtype=torch.float16, device_map=device_map)
1.7 LoRA相关
# 转换模型
model = get_peft_model(model, lora_config)
model.config.use_cache = False
old_state_dict = model.state_dict
model.state_dict = (
lambda self, *_, **__: get_peft_model_state_dict(self, old_state_dict())
).__get__(model, type(model))
# 打印模型中的可训练参数
model.print_trainable_parameters()
1.8 训练参数
args = TrainingArguments(
output_dir=OUTPUT_DIR, # checkpoint的存储目录
per_device_train_batch_size=BATCH_SIZE, # 单设备上的batch size
gradient_accumulation_steps=GRADIENT_ACCUMULATION_STEPS, # 梯度累加的step数
warmup_steps=100,
num_train_epochs=EPOCHS,
learning_rate=LEARNING_RATE,
fp16=True, # 使用混合精度训练
logging_steps=50,
evaluation_strategy="no", # 不进行评估
save_strategy="steps",
save_steps=2000, # 保存checkpoint的step数
save_total_limit=5, # 最多保存5个checkpoint
deepspeed=DS_CONFIG
)
1.9 模型训练
trainer = Trainer(
model=model,
train_dataset=train_data,
eval_dataset=None,
args=args,
data_collator=collate_fn
)
trainer.train()
model.save_pretrained("best_model")
2. DeepSpeed配置文件
DeepSpeed配置文件名为ds_zero2_config.json。
{
"train_micro_batch_size_per_gpu": "auto",
"gradient_accumulation_steps": "auto",
"steps_per_print": 50,
"gradient_clipping": 1.0,
"zero_optimization": {
"stage": 2,
"offload_optimizer": {
"device": "cpu"
},
"contiguous_gradients": true,
"overlap_comm": true
},
"zero_allow_untested_optimizer": true,
"fp16": {
"enabled": true,
"loss_scale": 0,
"loss_scale_window": 1000,
"hysteresis": 2,
"min_loss_scale": 1
},
"optimizer": {
"type": "Adam",
"params": {
"lr": "auto",
"betas": "auto",
"eps": "auto",
"weight_decay": "auto"
}
},
"activation_checkpointing": {
"partition_activations": true,
"contiguous_memory_optimization": true
},
"wall_clock_breakdown": false
}
3. 启动
deepspeed --include=localhost:0,1,2,3 train.py
4. 推理
推理文件名为inference.py
import torch
from peft import PeftModel
from transformers import AutoModelForCausalLM, AutoTokenizer
BASE_MODEL = "bigscience/bloomz-7b1-mt"
LORA_WEIGHTS = "best_model"
tokenizer = AutoTokenizer.from_pretrained(BASE_MODEL)
model = AutoModelForCausalLM.from_pretrained(
BASE_MODEL,
torch_dtype=torch.float16, # 加载半精度
device_map={"":0}, # 指定GPU 0
)
model.eval()
# 加载LoRA权重
model = PeftModel.from_pretrained(model, LORA_WEIGHTS, torch_dtype=torch.float16)
model.half()
prompt = ""
inp = tokenizer(prompt, max_length=512, return_tensors="pt").to("cuda")
outputs = model.generate(input_ids=inp["input_ids"], max_new_tokens=256)
print(tokenizer.decode(outputs[0]))
参考资料
https://arxiv.org/pdf/2106.09685.pdf
https://zhuanlan.zhihu.com/p/615235322
https://github.com/tloen/alpaca-lora/blob/main/finetune.py
https://github.com/huggingface/peft/blob/main/examples/conditional_generation/peft_lora_seq2seq_accelerate_ds_zero3_offload.py


![[SWPUCTF] 2021新生赛之(NSSCTF)刷题记录 ②](https://img-blog.csdnimg.cn/6df5ae7c3b164244ac58384c4b661b19.png)