比赛链接:BirdCLEF 2023 | Kaggle
比赛简介
鸟类是生物多样性变化的极好指标,因为它们具有高度流动性并且具有不同的栖息地要求。因此,物种组合和鸟类数量的变化可以表明恢复项目的成败。然而,经常在大面积地区进行传统的基于观察员的鸟类生物多样性调查既昂贵又在后勤上具有挑战性。相比之下,被动声学监测(PAM)与基于机器学习的新分析工具相结合,使保护主义者能够以更高的时间分辨率对更大的空间尺度进行采样,并深入探索恢复干预措施与生物多样性之间的关系。

在本次比赛中,您将使用机器学习技能通过声音识别东非鸟类。具体来说,您将开发计算解决方案来处理连续的音频数据并通过它们的呼叫识别物种。最好的条目将能够在有限的训练数据下训练可靠的分类器。如果成功,你将帮助推进保护非洲鸟类生物多样性的持续努力,包括由肯尼亚保护组织NATURAL STATE领导的努力。
NATURAL STATE正在肯尼亚北部山周围的试点地区开展工作,以测试各种管理制度和退化状态对牧场系统中鸟类生物多样性的影响。通过使用在本次竞赛范围内开发的机器学习算法,NATURAL STATE将能够证明这种方法在衡量恢复项目的成功和该方法的成本效益方面的功效。此外,具有成本效益地监测恢复工作对生物多样性的影响的能力将使NATURAL STATE能够测试和建立一些首批以生物多样性为重点的财务机制,以将急需的投资用于恢复和保护许多人所依赖的这一景观。这些工具对于经济高效地将其扩展到项目区域之外并实现我们大规模恢复和保护地球的愿景是必要的。
由于您的创新,研究人员和保护从业人员将更容易准确地调查鸟类种群趋势。因此,他们将能够评估威胁并定期更有效地调整其保护行动。
评估方法
本场比赛的评估标准是 padded cmAP 的指标,它是基于 scikit-learn 实现的宏平均准确率的一个变体。为了支持对没有真正正例标签的物种的预测,以及减少正例标签很少的物种的影响,评分之前会在每个提交和答案中加入五行真正正例。这意味着即使是一个基本的提交也会得到一个相对较高的分数。
chatgpt来介绍一下sklearn.metrics.average_precision_score
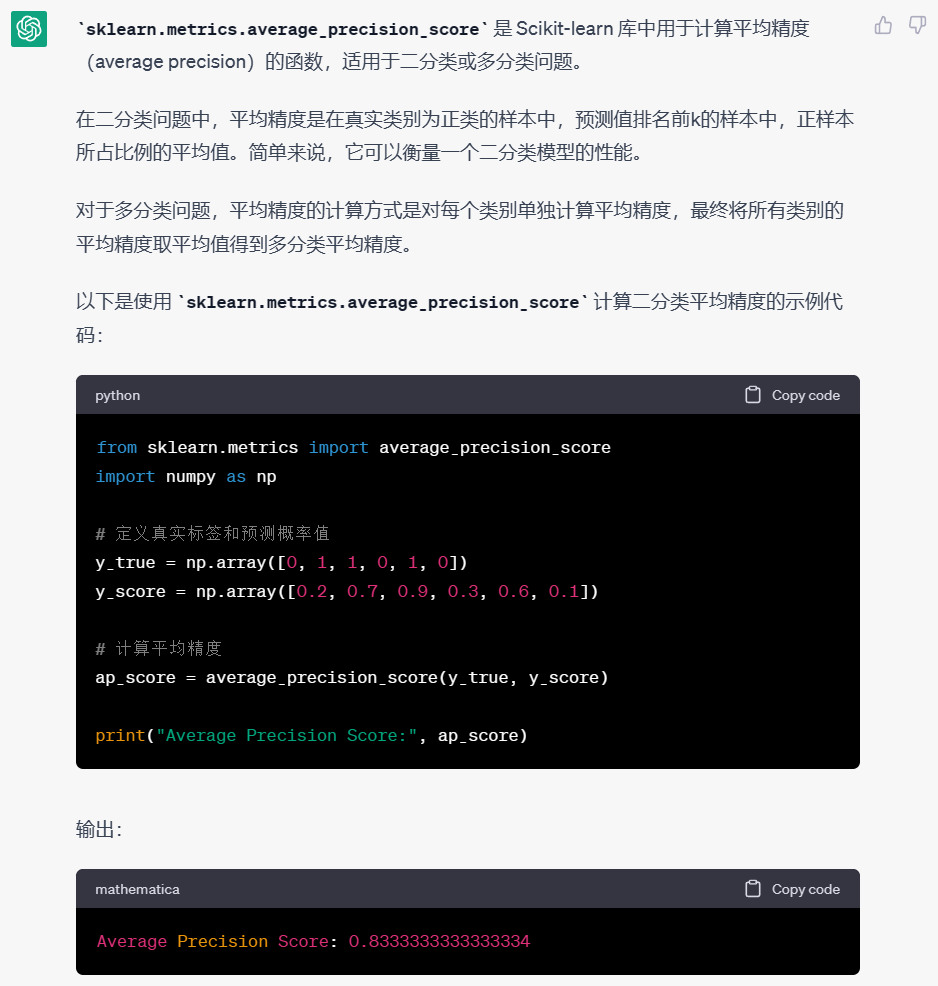

提交格式
提交格式是对每个 row_id,预测给定的鸟类物种是否存在的概率。每个鸟类物种有一列,所以每行需要提供 264 个预测。
import pandas as pd
import sklearn.metrics
def padded_cmap(solution, submission, padding_factor=5):
solution = solution.drop(['row_id'], axis=1, errors='ignore')
submission = submission.drop(['row_id'], axis=1, errors='ignore')
new_rows = []
for i in range(padding_factor):
new_rows.append([1 for i in range(len(solution.columns))])
new_rows = pd.DataFrame(new_rows)
new_rows.columns = solution.columns
padded_solution = pd.concat([solution, new_rows]).reset_index(drop=True).copy()
padded_submission = pd.concat([submission, new_rows]).reset_index(drop=True).copy()
score = sklearn.metrics.average_precision_score(
padded_solution.values,
padded_submission.values,
average='macro',
)
return score数据描述
您在本次比赛中面临的挑战是在肯尼亚制作的长录音中识别哪些鸟类在鸣叫。对于出于保护目的监测鸟类种群的科学家来说,这是一项重要任务。更准确的解决方案可以实现更全面的监控。今年,您的笔记本还必须在更受限的时间范围内完成推理。这将使在效率非常高的地面保护工作中更容易部署获胜模型。
本次比赛采用隐藏式测试。当您提交的笔记本被评分时,实际测试数据(包括样本提交)将提供给您的笔记本。
train_audio/训练数据包括 xenocanto.org 用户慷慨上传的单个鸟叫声的简短记录。这些文件在适用的情况下已缩减采样至 32 kHz,以匹配测试集音频并转换为 ogg 格式。训练数据应包含几乎所有相关文件;我们预计在 xenocanto.org 上寻找更多内容没有任何好处。
test_soundscapes/提交笔记本时,test_soundscapes目录中将填充大约 200 个用于评分的录制文件。它们长达 10 分钟,采用 ogg 音频格式。文件名是随机的。提交笔记本大约需要五分钟来加载所有测试音景。
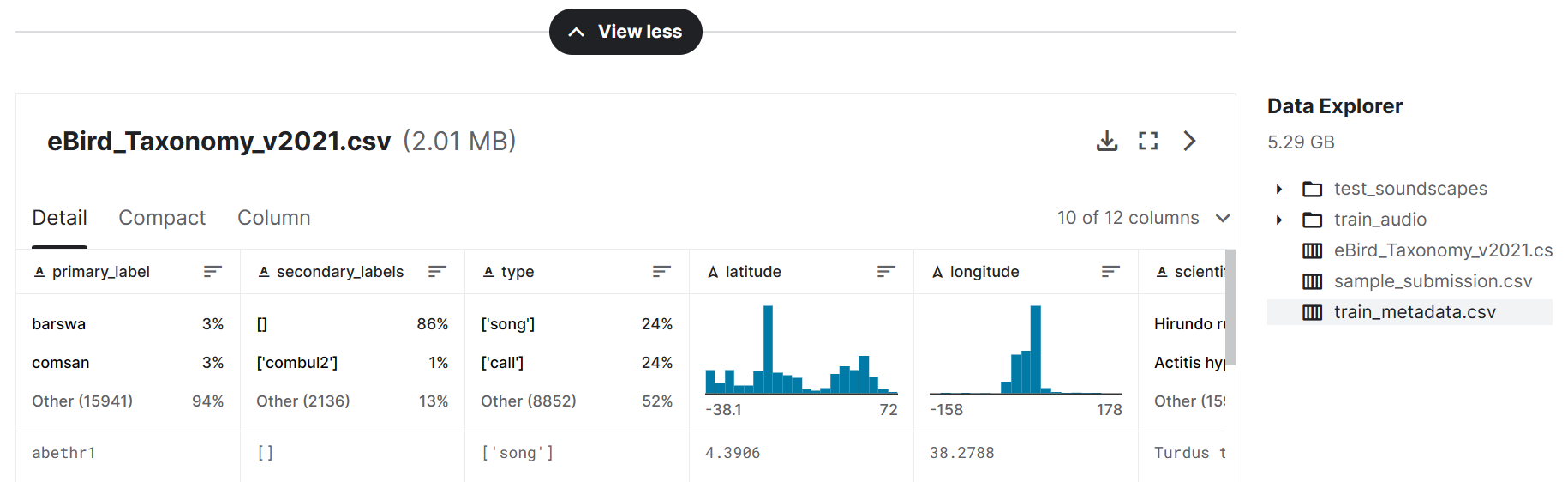
train_metadata.csv为训练数据提供了广泛的元数据。最直接相关的字段是:
primary_label- 鸟类代码。您可以通过将代码附加到 来查看有关鸟类代码的详细信息,例如美国乌鸦的代码。https://ebird.org/species/https://ebird.org/species/amecrolatitude&longitude:录制位置的坐标。某些鸟类可能具有本地称为“方言”的鸟类,因此您可能希望在训练数据中寻找地理多样性。author- 提供录音的用户。filename:关联音频文件的名称。
sample_submission.csv有效的示例提交。
row_id:用于预测的辅助信息区。[soundscape_id]_[end_time][bird_id]:有 264 个鸟类 ID 列。您需要预测每行每只鸟存在的概率。
eBird_Taxonomy_v2021.csv - 关于不同物种之间关系的数据。
提交要求

- CPU 笔记本 <= 120 分钟运行时间
- 允许免费和公开的外部数据,包括预先训练的模型