最近在网上流行的chatgpt,实在是太火了,好多人在使用,而且它的用处实在是太丰富了,能帮助我们解决很多问题,就比如说:编程,生成图片,翻译等。太丰富了。我看网上很多人都在说,它可以帮助人开发软件,在没有相关编程语音的基础上都能把软件做出来,于是我也思考了一个场景,想让他帮我实现一下浏览器插件的划词翻译。结果真的实现了,而且在浏览器上也跑起来了,真的是太兴奋了。我在想是不是以后都不需要程序员了,这个职业会不会马上就被替代掉,以下是我跟chatgpt的交流内容:
划词翻译的gitee地址
1、我想编写一个edge 扩展插件,使用这个插件主要用来翻译文本内容,使用插件的操作,1,edge 扩展在选中的段落文字下方,加入div显示,翻译的话,要翻译成中文。能提供一些示例代码吗?
然后它告诉我,我如果想写一个插件到底需要准备哪些文件,
manifest.json 文件中添加
{
"manifest_version": 2,
"name": "My Extension",
"version": "1.0",
"permissions": [
"activeTab",
"contextMenus"
],
"content_scripts": [
{
"matches": [
"<all_urls>"
],
"js": [
"content_script.js"
]
}
]
}
在 content_script.js文件中监听mousedown事件,以便在用户选定段落文字时触发。
document.addEventListener('mousedown', function(event) {
var selectionText = window.getSelection().toString();
if (selectionText) {
// 在此处添加代码以显示您的 DIV。
}
});
创建一个div元素并将其添加到文档中。您可以使用以下代码:
document.addEventListener('mousedown', function(event) {
var selectionText = window.getSelection().toString();
if (selectionText) {
var div = document.createElement('div');
div.innerHTML = '您要显示的文本。';
div.style.position = 'absolute';
div.style.top = event.pageY + 'px';
div.style.left = event.pageX + 'px';
document.body.appendChild(div);
}
});
在此示例中,我们在 mousedown 事件处理程序中创建了一个 div 元素,并将其添加到文档中。请注意,我们使用 event.pageX 和 event.pageY 属性来设置 div 元素的位置,以便该元素出现在用户点击的位置下方。
4. 样式 DIV。您可以使用 CSS 样式为 div 元素设置透明度、边框样式、字体大小等。
document.addEventListener('mousedown', function(event) {
var selectionText = window.getSelection().toString();
if (selectionText) {
var div = document.createElement('div');
div.innerHTML = '您要显示的文本。';
div.style.position = 'absolute';
div.style.top = event.pageY + 'px';
div.style.left = event.pageX + 'px';
div.style.backgroundColor = 'white';
div.style.border = '1px solid black';
div.style.padding = '5px';
div.style.fontSize = '14px';
div.style.fontFamily = 'Arial';
document.body.appendChild(div);
}
});
根据您的需求和设计,您可以通过调整 CSS 样式来自定义 div 元素的外观。
希望这些步骤对您有所帮助!
然后我复制完代码就放到我的插件包里面,使用浏览器加载一下插件,就出现了提示信息,果真可以直接使用,但是提示框我划词一下, 就出现一个,太多提示框,于是我问出了下面的问题
2、我实现了这个效果,但是当我在移动鼠标的时候又出现了div,页面上出现了好多的div提示框,能不能把之前的提示框都关掉呢,当我点击新的文本的时候
是的,您可以在创建新的提示框之前,清除先前的提示框。为此,您可以使用 document.querySelectorAll() 方法获取先前创建的所有提示框,并使用 Array.from() 方法将其转换为数组,然后使用 forEach() 方法循环遍历这些提示框,并使用 remove() 方法从文档中删除它们。
以下是更新后的代码,它添加了一些功能以清除先前创建的提示框:
document.addEventListener('mousedown', function(event) {
var selectionText = window.getSelection().toString();
if (selectionText) {
// 查找并删除先前创建的所有提示框
var oldDivList = Array.from(document.querySelectorAll('.my-extension-div'));
oldDivList.forEach(function(divElement) {
divElement.remove();
});
// 创建一个新的提示框
var div = document.createElement('div');
div.className = 'my-extension-div';
div.innerHTML = '您要显示的文本。';
div.style.position = 'absolute';
div.style.top = event.pageY + 'px';
div.style.left = event.pageX + 'px';
div.style.backgroundColor = 'white';
div.style.border = '1px solid black';
div.style.padding = '5px';
div.style.fontSize = '14px';
div.style.fontFamily = 'Arial';
document.body.appendChild(div);
}
});
在这个更新的代码中,我们首先使用 document.querySelectorAll() 方法获取所有具有 "my-extension-div" 类名的 div 元素,并将其转换为数组。然后,使用 forEach() 方法遍历该数组,并使用 remove() 方法从文档中删除该元素。
最后,我们创建了一个新的提示框,并为该元素设置了 "my-extension-div" 类名。这将使我们能够随时找到并删除该元素。
希望这个更新的代码可以帮助您解决问题!
我大概知道它的意思了,它的意思是我需要设置一下className,然后根据className找到所有的提示框,在鼠标事件触发的时候把其余的提示框删除掉,但是里面还有很多我不知道的函数,我不知道怎么拿到当前的选中的文本信息,但是我看到代码里面有一段代码,我继续问道。
3、如何获取当前选中的html信息
要获取当前选中文本的 HTML 信息,您可以使用 Range 对象。 Range 对象表示文档中的一段区域,可以包含一个或多个节点,并允许您对这些节点进行选择和编辑。
在 Edge 扩展中,您可以通过 window.getSelection() 方法获取当前选中的文本所在的节点,然后使用 getRangeAt() 方法获取包含文本的 Range 对象。最后,您可以使用 cloneContents() 方法将 Range 中包含的节点的副本作为 DocumentFragment 对象返回,并将其插入到新创建的 div 元素中,以显示为 HTML。
以下是一个示例代码,用于获取当前选中文本的 HTML 信息:
document.addEventListener('mousedown', function(event) {
var selectionText = window.getSelection().toString();
if (selectionText) {
var range = window.getSelection().getRangeAt(0);
var div = document.createElement('div');
var fragment = range.cloneContents();
div.appendChild(fragment);
document.body.appendChild(div);
}
});
在这个代码中,我们首先获取当前选中的文本,并检查是否有选中的文本。然后,我们使用 getRangeAt() 方法获取 Range 对象,并使用 cloneContents() 方法从 Range 对象中提取文本节点。接下来,我们将提取的文本节点副本插入到一个新创建的 div 元素中,并将该元素添加到文档中,以显示为 HTML。
希望这可以帮助您获取并显示当前选中文本的 HTML 信息。
好了我大概知道怎么操作了,那之后我肯定就得接入翻译api了,那我怎么接入翻译api呢,于是我找了百度的翻译接口,直接把示例扔给了chatgpt
4、把相关的百度翻译的接口给了chatgpt,如下:
接入举例
例如:将英文单词 apple 翻译成中文:
请求参数:
q=apple
from=en
to=zh
appid=2015063000000001(请替换为您的appid)
salt=1435660288(随机码)
平台分配的密钥: 12345678
生成签名sign:
Step1. 拼接字符串1:
拼接appid=2015063000000001+q=apple+salt=1435660288+密钥=12345678得到字符串1:“2015063000000001apple143566028812345678”
Step2. 计算签名:(对字符串1做MD5加密)
sign=MD5(2015063000000001apple143566028812345678),得到sign=f89f9594663708c1605f3d736d01d2d4
拼接完整请求:
http://api.fanyi.baidu.com/api/trans/vip/translate?q=apple&from=en&to=zh&appid=2015063000000001&salt=1435660288&sign=f89f9594663708c1605f3d736d01d2d4
注:也可使用 POST 方式,如 POST 方式传送,Content-Type 请指定为:application/x-www-form-urlencoded
麻烦生成一下edge扩展的代码示例
好的,以下是一个将选中的单词使用百度翻译 API 将其从英文翻译为中文的 Edge 扩展示例代码:
// 获取当前选中的文本
function getSelectedText() {
let selection = window.getSelection();
if (selection && selection.rangeCount && selection.toString()) {
return selection.toString();
}
return null;
}
// 发送翻译请求
function translate(word) {
const appid = 'YOUR_APP_ID'; // 替换成自己的 APP ID
const key = 'YOUR_KEY'; // 替换成自己的密钥
const salt = Date.now().toString();
const sign = md5(appid + word + salt + key); // 使用 md5 加密生成签名
const url = `http://api.fanyi.baidu.com/api/trans/vip/translate?q=${encodeURIComponent(word)}&from=en&to=zh&appid=${appid}&salt=${salt}&sign=${sign}`;
return fetch(url).then(response => response.json());
}
// 在页面上添加提示框
function addTooltip(text, target) {
const tooltip = document.createElement('div');
tooltip.innerHTML = text;
tooltip.style.cssText = `
position: absolute;
top: 0;
left: 0;
z-index: 99999;
padding: 0.5rem;
font-size: 1rem;
background-color: #fff;
border: 1px solid #aaa;
box-shadow: 1px 1px 1px rgba(0, 0, 0, 0.2);
`;
document.body.append(tooltip);
// 计算提示框位置
const rect = target.getBoundingClientRect();
tooltip.style.top = `${window.pageYOffset + rect.top + rect.height}px`;
tooltip.style.left = `${window.pageXOffset + rect.left + rect.width}px`;
// 添加点击事件,点击以后自动关闭提示框
tooltip.addEventListener('click', () => tooltip.remove());
}
// 添加鼠标选中事件监听器
document.addEventListener('mousedown', async (event) => {
// 如果选中文本为空,则不继续执行
const selectedText = getSelectedText();
if (!selectedText) {
return;
}
// 如果选中文本包含空格,则不继续执行
if (selectedText.includes(' ')) {
return;
}
// 发送翻译请求
const translation = await translate(selectedText);
const translationText = translation.trans_result[0].dst; // 获取翻译结果
addTooltip(translationText, event.target); // 在页面上添加提示框
});
注意,在使用百度翻译 API 提交请求之前,需要将 YOUR_APP_ID 和 YOUR_KEY 替换为您自己的百度翻译 API 的 APP ID 和密钥,否则将会返回错误的结果。另外,Edge 扩展使用的是 Content Scripts,所以要注意在 manifest.json 文件中配置好权限和注入的页面。
哇,它直接给我生成了全套的代码,真是太丰富了,我直接拿代码,覆盖了我之前写的代码,改了一下appid和key,在浏览器上实现一下,发现有错误,于是我直接把错误信息给了chatgpt
5、在浏览器上实现一下,发现有错误,于是我直接把错误信息给了chatgpt,于是我直接问:“selectedText.includes”
selectedText.includes() 是 JavaScript 字符串原型对象上的方法,用于判断字符串中是否包含某个子字符串。如果包含,则返回 true,否则返回 false。
在这个例子中,因为我们只想翻译单个英文单词,而不是短语或句子,所以我们需要判断选中的文本是否包含空格或其他分隔符。如果包含分隔符,则意味着选中的是一个短语或句子,而不是单个单词,此时我们不会发送翻译请求。
具体来说,selectedText.includes(' ') 的作用就是判断选中文本中是否包含空格,如果包含,则返回 true,否则返回 false。如果返回 true,则说明选中的文本是一个短语或句子,不是单个单词,不会发送翻译请求。
6、但是如果字符串中有空格的话,是不是也会返回true
是的,如果字符串中有空格或其他分隔符,includes() 方法也会返回 true,因为字符串中确实含有空格。因此,如果想要判断选中的文本是否为单个单词,我们需要使用更加严谨的方式来判断。
一个常用的方法是使用正则表达式,例如下面的代码:
function isWord(text) {
return /^[a-zA-Z]+$/.test(text);
}
这个函数会检查字符串 text 是否由一个或多个大小写字母组成。如果是,就说明它是一个单词,否则就不是。使用这个函数,我们就可以在代码中更加准确地判断选中的文本是否为单词:
// 添加鼠标选中事件监听器
document.addEventListener('mousedown', async (event) => {
// 如果选中文本为空或包含空格,则不继续执行
const selectedText = getSelectedText();
if (!selectedText || !isWord(selectedText)) {
return;
}
// 发送翻译请求
const translation = await translate(selectedText);
const translationText = translation.trans_result[0].dst; // 获取翻译结果
addTooltip(translationText, event.target); // 在页面上添加提示框
});
这样,当用户选中的文本不是单词时,就不会发送翻译请求。
7、然后代码中又发现了没有md5的库,怎么办?
error: md5 is not defined
这个错误通常是由于在你的 translate 函数中没有正确引入 md5 模块导致的,因为 md5 是一个方法,不是内置函数,需要先导入才能使用。
在使用 md5 之前,需要先在代码的开头导入 md5 模块。例如,在使用 md5 之前先导入(或加载)这个模块:
import md5 from 'md5';
如果你使用的是 CommonJS 模块规范,也可以使用 require 方法来导入模块,例如:
const md5 = require('md5');
想了解更多有关模块化编程的信息,可以查看 MDN 文档。
导入 md5 模块后,在你的 translate 函数中就可以使用 md5 方法了。例如:
import md55 from 'md5';
async function
8、edge 扩展中,怎么引入md5模块
在 Edge 扩展中,由于浏览器的安全策略的限制,我们不能直接使用 import 的方式引入 md5 模块。但是,在扩展中我们可以通过添加脚本文件的方式来引入第三方库。
具体来说,可以按照以下步骤来引入 md5 模块:
-
下载
md5库的 JS 文件,可以从 这里 下载,也可以将其下载到本地,然后在扩展目录中创建一个lib文件夹,将md5的 JS 文件放到该文件夹下。 -
在扩展的
manifest.json文件中添加以下内容,在content_scripts字段中的js数组中添加md5.js,这样扩展就可以在每个页面中注入md5.js脚本文件了。
"content_scripts": [
{
"matches": [
"<all_urls>"
],
"js": [
"content_script.js",
"lib/md5.js"
]
}
],
在需要使用
md5 模块的地方,可以使用全局变量
md5,这个变量引用的是
md5.js 中导出的模块。
// 在translate函数中使用md5模块
async function translate() {
// 其它代码...
const text = 'hello world';
const md5Text = md5(text); // 使用全局变量md5
// 其它代码...
}
这样就完成了在 Edge 扩展中引入 md5 模块的过程。
9、它给我了md5库的连接,我下载了一下没办法下载,于是我找到其他的md5的库下载下来就好用了,于是弄上去之后又出来新的问题,如下:Uncaught (in promise) TypeError: Failed to fetch
这个错误通常是由于 Fetch API 抛出了异常或者请求被停止或由浏览器禁止导致的。这种错误可能是由下列原因导致的:
-
网络错误:例如 DNS 查询超时,服务器连接超时或连接 reset 等,这种情况下通常会出现网络错误提示信息。如果确定是网络错误,则需要检查网络连接,尝试重新加载页面或等待一段时间再次尝试请求。
-
CORS(跨域资源共享):如果请求资源存在跨域问题,可能会导致浏览器拒绝请求。在这种情况下,服务器必须支持 CORS 以允许跨域请求。可以通过设置服务器响应头来允许跨域请求,或者使用代理来解决跨域问题。
-
证书问题:如果请求的资源需要 SSL 证书,未能正确处理证书可能导致请求失败。这种情况下可能需要检查证书是否过期以及证书是否正确安装。可以尝试更新 HTTPS 证书或安装可信证书。
-
Cookie 或 Storage 问题:如果请求的数据依赖于 Cookie 或 Storage,可能需要确保请求的网址与存储的 Cookie 或 Storage 相应相匹配。
-
请求被停止:如果页面在请求进行时被卸载、导航到其他地方或关闭浏览器,则可能导致请求被停止。为了避免这种问题,可以通过使用 async/await 或 Promise 等方式确保请求完成之前不进行导航或关闭。
综上所述,解决 Uncaught (in promise) TypeError: Failed to fetch 的错误需要根据具体情况进行排查。可以通过查看请求状态码、Network 面板以及浏览器控制台来获取更多提示信息,并根据具体情况进行相应的修复。
10、我在浏览器的控制台找到了错误原因,于是把问题又发给了chtgpt。“from origin ‘https://spring.io’ has been blocked by CORS policy: No ‘Access-Control-Allow-Origin’ header is present on the requested resource. If an opaque response serves your needs, set the request’s mode to ‘no-cors’ to fetch the resource with CORS disabled.”
这个错误信息表明请求的资源存在跨域问题并且服务器未设置跨域访问控制。跨域资源共享(CORS)是一种浏览器技术,用于解决跨域资源请求的安全性问题。CORS 要求服务器在响应头设置 Access-Control-Allow-Origin 来指定能够访问该资源的域名。如果服务器未设置该响应头,则浏览器将拒绝该请求。
要解决这个问题,可以尝试以下几种方案:
在服务器端添加
Access-Control-Allow-Origin 头来设置允许访问的来源。例如,在响应头中添加以下代码:Access-Control-Allow-Origin: https://spring.io。
如果服务器无法进行修改,则可以考虑使用 JSONP 或改用其他代理解决跨域问题。在使用 JSONP 时,浏览器会将请求封装在一个 script 标签内并向服务器发送请求,服务器返回一个 JavaScript 脚本字符串,该字符串会被浏览器自动执行。JSONP 的原理是在响应结果中返回一段 JS 代码并立即执行,该代码由响应结果中的回调函数来执行。
如果服务器未设置
Access-Control-Allow-Origin 头并需要进行修改,则可以使用代理解决跨域问题。在代理服务器中请求 API 并将结果返回到客户端,这样客户端就不会与原服务器进行跨域通信。
如果以上无法解决跨域问题,则可以考虑将网站升级到 HTTPS 协议或使用 CORS 插件或扩展程序等进行解决。
总之,解决跨域问题需要根据具体情况进行排查并采取相应措施。可以通过检查响应头、浏览器控制台以及 Network 面板获取更多提示信息。
11、这个问题我怎么问都不能解决问题,于是我上网搜了一下浏览器插件跨域问题解决,网上有些内容,于是我把搜出来东西喂给了chatgpt:如下
manifest.json
在配置文件manifest.json中开启这个权限,代码大致如下:
{
"name": "demo",
"version": "0.1.0",
"manifest_version": 3,
"icons": {
"16": "icon/icon16.png",
"48": "icon/icon48.png",
"128": "icon/icon128.png"
},·····
核心的代码其实就这一行
chrome.runtime.sendMessage(message, resolve);
借助的API也是chrome浏览器内置的API,当通过 chrome.runtime.sendMessage 将消息发送出去后,在background.js中会通过 chrome.runtime.onMessage.addListener 接收到,一旦接收到消息,那么会立刻触发跨域的接口,向后台发送请求,接口返回之后又通过 sendResponse(res) 发送到页面, 此时的页面自然也就可以获取到跨域接口的值;····
内容很多,我截取了存在了部分在这边
这是使用 Chrome 扩展工具实现跨域请求的方法。使用此方法需要先编写一个扩展工具,然后使用该工具在浏览器中调用跨域 API 接口。
在 manifest.json 配置文件中使用 host_permissions 权限以允许扩展访问跨域资源。此外,使用
chrome.runtime.onMessage.addListener() 监听浏览器发送的消息委托,当扩展工具接收到消息时,它可以发出跨域请求,然后将响应发送回消息委托方。
在 background.js 中使用 fetch() 来获取跨域资源的数据,并使用 sendResponse() 向消息委托的页面返回响应数据。
在消息委托的页面中,通过使用
chrome.runtime.sendMessage() 将消息委托给扩展工具。一旦收到消息,扩展工具就会发出跨域请求,并将响应返回给消息委托方。
需要注意的是,使用Chrome扩展工具实现跨域访问时,用户必须安装该扩展工具才能正常使用该功能,因为该功能只适用于扩展工具本身运行的浏览器。
这里提供一个完整的示例代码,展示如何使用 Chrome 扩展工具实现跨域请求。
首先,在 manifest.json 文件中添加以下配置:
{
"name": "Cross Domain Extension",
"version": "1.0",
"manifest_version": 3,
"description": "A Chrome extension to test cross domain requests",
"icons": {
"16": "icon.png",
"32": "icon.png",
"48": "icon.png",
"128": "icon.png"
},
"background": {
"service_worker": "background.js",
"type": "module"
},
"permissions": ["activeTab"],
"host_permissions": ["<all_urls>"],
"content_scripts": [
{
"matches": ["<all_urls>"],
"match_about_blank": true,
"js": ["content.js"]
}
]
}
上面的配置文件将 host_permissions 设置为 <all_urls>,这样扩展工具就可以访问所有网站了。注意,这个选项应该小心使用,因为它会导致一些安全风险。
接下来,编写 background.js,实现消息委托的逻辑:
// 在后台中接收消息
chrome.runtime.onMessage.addListener((message, sender, sendResponse) => {
if (message.type === 'get') {
fetch(message.url)
.then(response => response.json())
.then(data => sendResponse({ success: true, data }))
.catch(error => sendResponse({ success: false, error }));
}
return true;
});
在这个示例中,我们添加了一个监听器来接收由 content.js 发送至扩展工具的消息,如果消息的类型是 get,则我们使用 fetch() 向指定 URL 发送 GET 请求,并将响应发送回 content.js。
最后,编写内容脚本 content.js,将需要发送到扩展工具的消息委托至 background.js:
// 获取当前选项卡信息和当前页面 URL
chrome.tabs.query({ active: true, currentWindow: true }, tabs => {
const [currentTab] = tabs;
const url = new URL(currentTab.url);
// 向扩展工具发送消息
chrome.runtime.sendMessage(
{
type: 'get',
url: `https://api.github.com/search/repositories?q=${url.host}`
},
response => {
console.log(response);
}
);
});
在这个示例中,我们使用 chrome.tabs.query() API 获取当前选项卡的信息,并从中获取当前页面的 URL。我们将 URL 拼接到一个 Github API 查询中,然后将查询URL 和消息类型一起发送至扩展工具。
扩展工具接收到消息后,获取请求的 URL 并向该 URL 发送 GET 请求,并将响应发送回内容脚本。内容脚本接收响应并将其输出到控制台。
在上面的示例中,我们使用了 fetch() 发送请求,因此需要在 manifest.json 文件中将 "type": "module" 添加至 "background" 区块。
完成上述步骤后,在 Chrome 浏览器中打开一个网站并点击扩展工具的图标,然后查看控制台中的输出。如一切正常,你应该可以看到一个响应结果对象。
12、插件完成
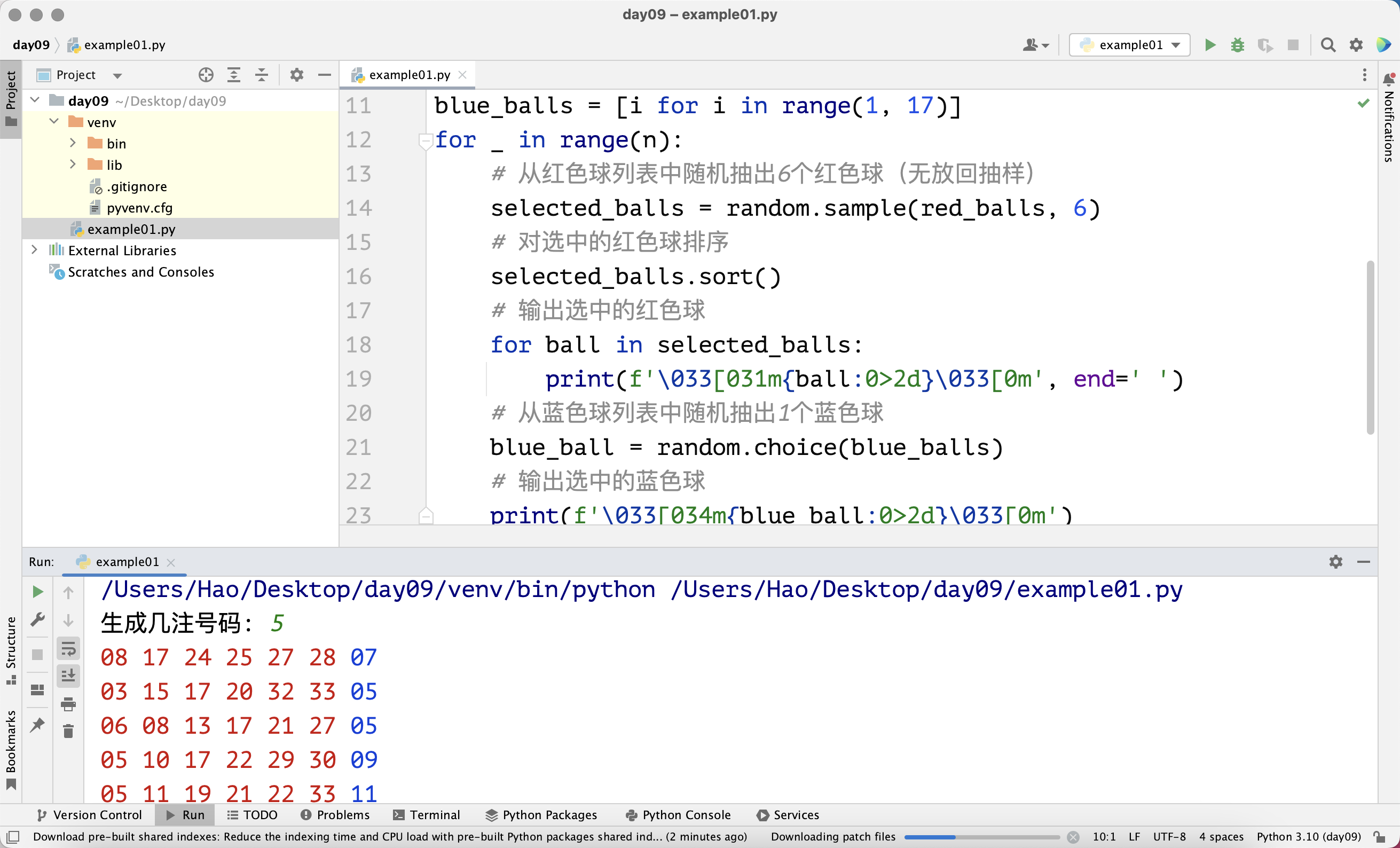
很快他给我了示例程序,于是我照着示例程序融汇到我的翻译插件里面,测试了一下,如下图:
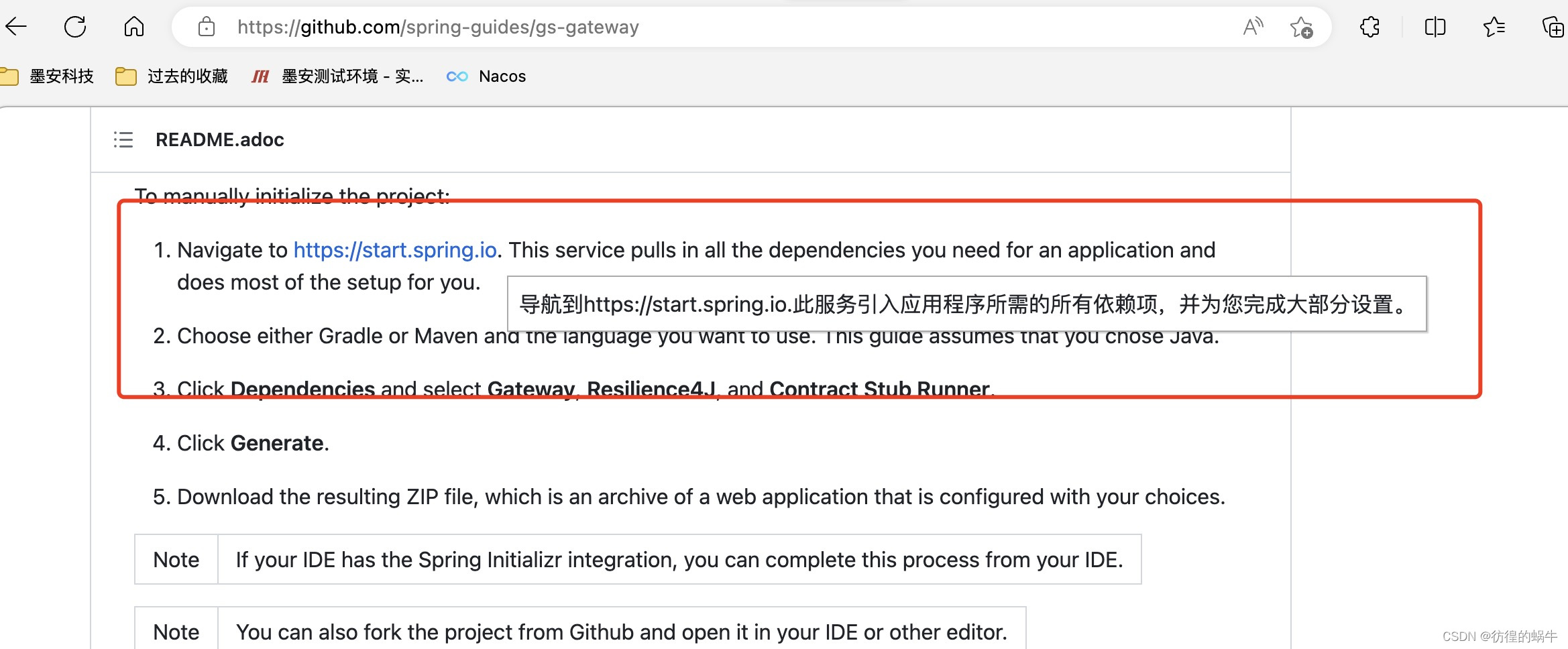
划词翻译成功,可以进行划词翻译了, 但是代码上还有很多问题需要补充。