拼多多是中国领先的社交电商平台之一,是一家以“团购+折扣”为主要运营模式的电商平台。该平台上有海量的商品,对于商家和消费者来说都具有非常大的价值,因此,拼多多商品数据的采集技术非常重要。本文将介绍拼多多商品数据的采集技术。
一、拼多多商品的数据结构
拼多多的商品数据包含了以下信息:
商品的标题:商品的名称,主要描述商品的基本属性。
商品的ID:商品的唯一标识符,用于区分不同的商品,具有唯一性。
商品的价格:商品的售价和原价,包括折扣信息和团购价等。
商品的图片:商品的图片信息,包括主图和详情图等。
商品的描述:商品的详细描述信息,包括商品的特性,规格,功能等。
商品的付款信息:商品的付款方式,包括支付宝,微信等等。
二、拼多多商品的数据采集
拼多多商品的数据采集主要有以下两种方法:
1.手动数据采集
手动数据采集指的是直接在拼多多平台上搜索并手动复制商品数据。该方法适合采集小批量的商品数据,但不适用于大规模数据采集。手动采集需要手动输入搜索词,进行筛选后再复制所需的数据,该方法需要花费大量的时间和人力成本,效率较低。
1.1自动数据采集
自动化数据采集是目前应用最广泛的数据采集技术。拼多多的数据采集可以通过爬虫来自动获取。具体的步骤如下:
(1)选择爬虫框架并安装: Python爬虫框架有很多,如scrapy,beautiful soup等。安装步骤网上有很多教程,这里不再赘述。
(2)定义爬虫的起始链接:在拼多多平台上搜索自己想要的商品,并将链接进行复制。然后在自己编写的爬虫程序中,定义起始链接为刚才复制的拼多多商品搜索链接。
(3)处理网页:使用beautiful soup等库,对网页中的商品数据进行解析,提取自己所需要的数据。
(4)存储数据:一般采用文件存储和数据库存储两种方式。文件存储采用csv格式,数据库存储则可以采用mysql等数据库。
2.封装接口进行采集拼多多商品详情数据,拼多多商品优惠券数据,拼多多商品视频数据,拼多多商品销量数据,拼多多商品列表数据代码展示:
2.1 请求方式:HTTP POST GET
2.2 公共参数:
| 名称 | 类型 | 必须 | 描述 |
|---|---|---|---|
| key | String | 是 | 调用key(必须以GET方式拼接在URL中,获取key和secret) |
| secret | String | 是 | 调用密钥 (复制v:Taobaoapi2014 ) |
| api_name | String | 是 | API接口名称(包括在请求地址中)[item_search,item_get,item_search_shop等] |
| cache | String | 否 | [yes,no]默认yes,将调用缓存的数据,速度比较快 |
| result_type | String | 否 | [json,jsonu,xml,serialize,var_export]返回数据格式,默认为json,jsonu输出的内容中文可以直接阅读 |
| lang | String | 否 | [cn,en,ru]翻译语言,默认cn简体中文 |
| version | String | 否 | API版本 |
2.3 请求参数:
请求参数:num_iid=1620002566
参数说明:num_iid:商品ID ;
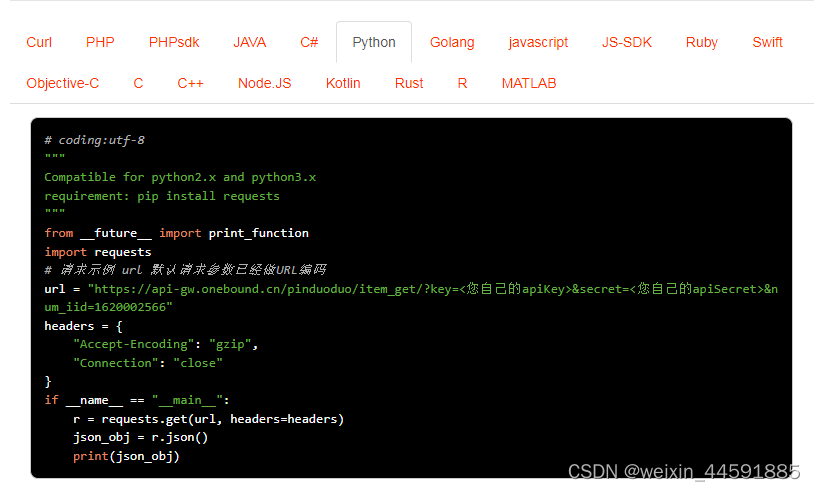
2.4 请求代码示例,支持高并发请求(CURL、PHP 、PHPsdk 、Java 、C# 、Python...)
2.5 响应示例

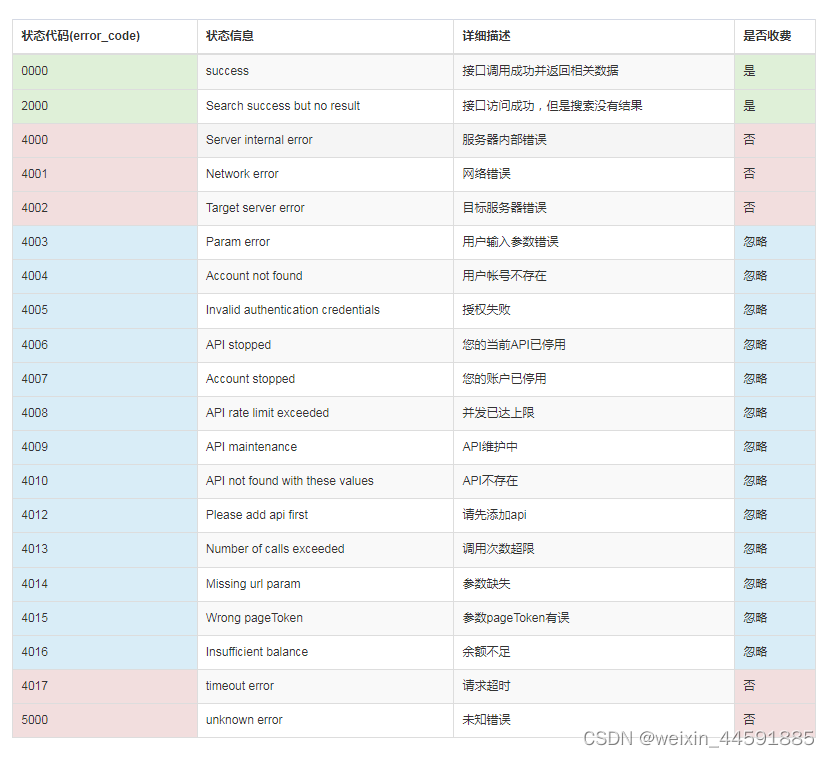
2.6错误码说明









![全网多种方法解决[rejected] master -> master (fetch first)的错误](https://img-blog.csdnimg.cn/6680473b7c4d43da931d58cf52da35d8.png)