前言
Pdf作为我们办公文件中的一种常用文件格式,很多业务中会涉及到一个功能,是将系统中的某些数据,按照要求的格式生成Pdf文件。比如常见的征信报告,合同文件等等,为此通过java代码,处理PDF格式的文件,是java程序员需要掌握的技能。
1 itextpdf操作pdf
1.1 简介
- 适合写文件,相对支持的格式比较多,图片,表格等等
1.2 pom坐标引入
<!-- https://mvnrepository.com/artifact/com.itextpdf/itextpdf -->
<dependency>
<groupId>com.itextpdf</groupId>
<artifactId>itextpdf</artifactId>
<version>5.5.13</version>
</dependency>
<!-- https://mvnrepository.com/artifact/com.itextpdf/itext-asian -->
<dependency>
<groupId>com.itextpdf</groupId>
<artifactId>itext-asian</artifactId>
<version>5.2.0</version>
</dependency>
1.3 api使用
关于PDF的读写,合并,拆分,比较常用的是生成PDF。
1.3.1 读
1.3.1.1 样例demo
新建一个word文档,内容如下,里面包含文字和图片,导出为pdf文件

1.3.1.2 测试代码
@Test
public void testRead() {
String fileName = "C:\\Users\\newhope\\Desktop\\测试pdf\\测试01.pdf";
String result = "";
FileInputStream in = null;
try {
in = new FileInputStream(fileName);
// 新建一个PDF解析器对象
PdfReader reader = new PdfReader(fileName);
reader.setAppendable(true);
// 对PDF文件进行解析,获取PDF文档页码
int size = reader.getNumberOfPages();
for (int i = 1; i < size + 1; ) {
//一页页读取PDF文本
String pageStr = PdfTextExtractor.getTextFromPage(reader, i);
result = result + pageStr + "\n" + "PDF解析第" + (i) + "页\n";
i = i + 1;
}
reader.close();
} catch (Exception e) {
System.out.println("读取PDF文件" + fileName + "生失败!" + e);
e.printStackTrace();
} finally {
if (in != null) {
try {
in.close();
} catch (IOException e1) {
e1.printStackTrace();
}
}
}
System.out.println(result);
}
代码运行结果如下,可以看到文本数据可以正常解析拿到,但是图片没有正常解析:
我是一段测试的数据
下面是测试图片
PDF解析第1页
1.3.2 写(常用)
// 页眉事件
private static class Header extends PdfPageEventHelper {
public static PdfPTable header;
public Header() {
}
public Header(PdfPTable header) {
Header.header = header;
}
@Override
public void onEndPage(PdfWriter writer, Document doc) {
// 把页眉表格定位
header.writeSelectedRows(0, -1, 30, 840, writer.getDirectContent());
}
/**
* 设置页眉
*
* @param writer
* @throws Exception
*/
public void setTableHeader(PdfWriter writer, String subject) throws Exception {
URL url = getClass().getClassLoader().getResource("picture/logo.jpg");// 获取文件的URL
PdfPTable table = new PdfPTable(2);
table.setTotalWidth(530);
PdfPCell cell = new PdfPCell();
cell.setBorder(0);
Image image01;
//image01 = Image.getInstance(PropertyUtil.getProperty("logoPath")); // 图片自己传
image01 = Image.getInstance(url); // 图片自己传
image01.scaleAbsolute(30f, 30f);
cell.addElement(image01);
cell.setBorderWidthBottom(1);
cell.setRight(100f);
table.addCell(cell);
BaseFont bf;
Font font = null;
try {
bf = BaseFont.createFont( "STSong-Light", "UniGB-UCS2-H",
BaseFont.NOT_EMBEDDED);//创建字体
font = new Font(bf,12);//使用字体
} catch (DocumentException | IOException e) {
log.error("页面创建字体异常",e);
}
Paragraph p = new Paragraph(subject, font);
p.setAlignment(1);
PdfPCell cell0 = new PdfPCell();
cell0.setBorder(0);
cell0.setBorderWidthBottom(1);
table.addCell(cell0);
Header event = new Header(table);
writer.setPageEvent(event);
}
}
@Test
public void testWrite() throws Exception {
String filename = "C:\\Users\\newhope\\Desktop\\测试pdf\\测试02.pdf";
// 创建文件
Document document = new Document(PageSize.A4);
// 创建pdf
PdfWriter writer = PdfWriter.getInstance(document, new FileOutputStream(filename));
Header header = new Header();
header.setTableHeader(writer, "");
document.open();
BaseFont baseFont = null;
Font commonFont = null;
try {
baseFont = BaseFont.createFont("STSong-Light", "UniGB-UCS2-H",
BaseFont.NOT_EMBEDDED);//创建字体
commonFont = new Font(baseFont, 10.5f);//使用字体
} catch (DocumentException | IOException e) {
log.error("pdf字体创建异常", e);
}
/*
* 标题
*/
Paragraph paragraph = new Paragraph("标题", new Font(baseFont, 16));
paragraph.setAlignment(1);
paragraph.setLeading(2);
PdfPCell pdfPCellTitle = new PdfPCell(paragraph);
pdfPCellTitle.setHorizontalAlignment(1);
pdfPCellTitle.disableBorderSide(15);
PdfPTable pdfPTableTitle = new PdfPTable(1);
pdfPTableTitle.addCell(pdfPCellTitle);
document.add(pdfPTableTitle);
//注意,这里要设置字体,否则中文会不显示
document.add(new Paragraph("这是正文,测试pdf写入", commonFont));
//写一个表格进去
// 换行
document.add(new Paragraph(" "));
// 添加表格,3列
PdfPTable table = new PdfPTable(3);
// 设置表格宽度比例为%100
table.setWidthPercentage(100);
// 设置表格上面空白宽度
table.setSpacingBefore(10f);
// 设置表格下面空白宽度
table.setSpacingAfter(10f);
// 设置表格默认为无边框
table.getDefaultCell().setBorder(0);
PdfPCell cell0 = new PdfPCell(new Paragraph("姓名",commonFont));
// 设置跨两行
cell0.setRowspan(2);
// 设置距左边的距离
cell0.setPaddingLeft(10);
// 设置高度
cell0.setFixedHeight(20);
// 设置内容水平居中显示
cell0.setHorizontalAlignment(Element.ALIGN_CENTER);
// 设置垂直居中
cell0.setVerticalAlignment(Element.ALIGN_MIDDLE);
table.addCell(cell0);
PdfPCell cellsex = new PdfPCell(new Paragraph("性别",commonFont));
// 设置跨两行
cellsex.setRowspan(2);
// 设置距左边的距离
cellsex.setPaddingLeft(10);
// 设置高度
cellsex.setFixedHeight(20);
// 设置内容水平居中显示
cellsex.setHorizontalAlignment(Element.ALIGN_CENTER);
// 设置垂直居中
cellsex.setVerticalAlignment(Element.ALIGN_MIDDLE);
table.addCell(cellsex);
PdfPCell cellage = new PdfPCell(new Paragraph("年龄",commonFont));
// 设置跨两行
cellage.setRowspan(2);
// 设置距左边的距离
cellage.setPaddingLeft(10);
// 设置高度
cellage.setFixedHeight(20);
// 设置内容水平居中显示
cellage.setHorizontalAlignment(Element.ALIGN_CENTER);
// 设置垂直居中
cellage.setVerticalAlignment(Element.ALIGN_MIDDLE);
table.addCell(cellage);
document.add(table);
//注意:通常资源关闭要 try catch 异常后,放到finally里面,否则可能会导致资源没有释放,这里是测试代码,直接关闭
document.close();
}
测试代码生成pdf样式如下:

注意:
- 通常资源关闭要放到try catch finally模块,否则前面出现异常,可能会导致资源没有释放,后面不再赘述
- 上面例子只是演示了几种常见的数据,图片,表哥,文字,怎么写到pdf里面,具体用的时候,要根据业务需求自己扩展
- pom坐标要引入itext-asian ,以及,写pdf的时候指定自己创建的字体,否则汉字可能会显示不出来
- 细心观察可以看到,上面测试方法,我们是把一块块数据拼上去的,其实有些内容是可以封装通用的方法的,这样后续拼接数据会方便很多
- 上面拼接excel代码,如果设置的列数是3列,但是后面代码没有拼到三个单元格,则生成的pdf里面不会生成对应的表格,也没有报错提示
- 在生成pdf的过程中,还有个比较繁琐的可能是调整样式,行距多少合适,宽度多少。。。这个有点像是写前端页面的感觉
1.3.3 拆分
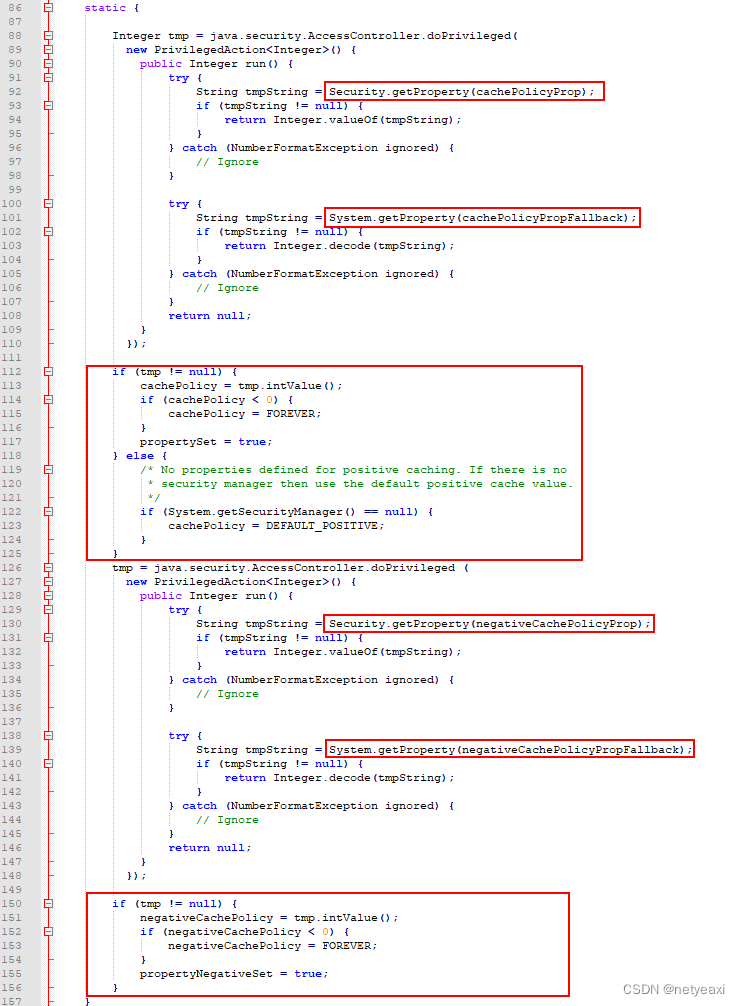
这里用一个比较大的pdf做演示,按照页码拆分,代码如下:
@Test
public void testSplit() throws Exception{
String fileName = "C:\\Users\\newhope\\Desktop\\测试pdf\\测试03.pdf";
PdfReader reader = new PdfReader(fileName);
int n = reader.getNumberOfPages();
System.out.println ("Number of pages :" + n);
int i = 0;
while ( i < n ) {
String outFile = fileName.substring(0, fileName.indexOf(".pdf"))
+"-" + String.format("%03d", i + 1) +".pdf";
System.out.println ("Writing" + outFile);
Document document = new Document(reader.getPageSizeWithRotation(i+1));
PdfCopy writer = new PdfCopy(document, new FileOutputStream(outFile));
document.open();
PdfImportedPage page = writer.getImportedPage(reader, ++i);
writer.addPage(page);
document.close();
writer.close();
}
}
1.3.4 合并
@Test
public void testMerge() throws Exception{
List<String> sourceFilePaths = Arrays.asList("C:\\Users\\newhope\\Desktop\\测试pdf\\测试01.pdf","C:\\Users\\newhope\\Desktop\\测试pdf\\测试03.pdf");
String destFilePath="C:\\Users\\newhope\\Desktop\\测试pdf输出";
Document document = null;
PdfCopy copy = null;
OutputStream os = null;
try {
// 创建合并后的新文件的目录
Path dirPath = Paths.get(destFilePath.substring(0, destFilePath.lastIndexOf(File.separator)));
Files.createDirectories(dirPath);
os = new BufferedOutputStream(new FileOutputStream(new File(destFilePath)));
document = new Document(new PdfReader(sourceFilePaths.get(0)).getPageSize(1));
copy = new PdfCopy(document, os);
document.open();
for (String sourceFilePath : sourceFilePaths) {
// 如果PDF文件不存在,则跳过
if (!new File(sourceFilePath).exists()) {
continue;
}
// 读取需要合并的PDF文件
PdfReader reader = new PdfReader(sourceFilePath);
// 获取PDF文件总页数
int n = reader.getNumberOfPages();
for (int j = 1; j <= n; j++) {
document.newPage();
PdfImportedPage page = copy.getImportedPage(reader, j);
copy.addPage(page);
}
}
} catch (Exception e) {
e.printStackTrace();
} finally {
if (copy != null) {
try {
copy.close();
} catch (Exception ex) {
/* ignore */
}
}
if (document != null) {
try {
document.close();
} catch (Exception ex) {
/* ignore */
}
}
if (os != null) {
try {
os.close();
} catch (Exception ex) {
/* ignore */
}
}
}
}
代码运行效果感兴趣可以自己本地测试
2 pdfbox操作pdf
2.1 简介
- 适合文件的拆分合并,保存为图片等
- 不适合复杂格式的pdf代码拼接处理,但是这种可以通过word转pdf实现,即定制一个word模板,代码根据占位符替换里面数据,比如姓名,金额等,最后将word转为pdf
2.2 pom坐标引入
<dependency>
<groupId>org.apache.pdfbox</groupId>
<artifactId>pdfbox</artifactId>
<version>2.0.21</version>
</dependency>
2.3 api使用
2.3.1 读
@Test
public void testRead() throws Exception {
String pdfPath = "C:\\Users\\newhope\\Desktop\\测试pdf\\测试01.pdf";
String result = readPDF(pdfPath);
System.out.println(result);
}
public String readPDF(String file) throws IOException {
String picturePath = "C:\\Users\\newhope\\Desktop\\测试pdf\\";
StringBuilder result = new StringBuilder();
FileInputStream is = null;
is = new FileInputStream(file);
PDFParser parser = new PDFParser(new RandomAccessBuffer(is));
parser.parse();
PDDocument doc = parser.getPDDocument();
PDFTextStripper textStripper = new PDFTextStripper();
for (int i = 1; i <= doc.getNumberOfPages(); i++) {
textStripper.setStartPage(i);
textStripper.setEndPage(i);
textStripper.setSortByPosition(true);//按顺序行读
String s = textStripper.getText(doc);
result.append(s);
}
//读取图片,保存到指定目录,真实业务场景可以上传到文件服务器,方便后续使用
for (int i = 1; i <= doc.getNumberOfPages(); i++) {
PDPage page = doc.getPage(i - 1);
PDResources resources = page.getResources();
Iterable<COSName> xobjects = resources.getXObjectNames();
if (xobjects != null) {
Iterator<COSName> imageIter = xobjects.iterator();
while (imageIter.hasNext()) {
COSName cosName = imageIter.next();
boolean isImageXObject = resources.isImageXObject(cosName);
if (isImageXObject) {
//获取每页资源的图片
PDImageXObject ixt = (PDImageXObject) resources.getXObject(cosName);
File outputfile = new File(picturePath + cosName.getName() + ".jpg");
ImageIO.write(ixt.getImage(), "jpg", outputfile);//可保存图片到本地
}
}
}
}
doc.close();
return result.toString();
}
代码运行结果,文字正常读取打印:
我是一段测试的数据
下面是测试图片
图片正常保存:

2.3.2 写
@Test
public void testWrite() throws Exception {
String pdfPath = "C:\\Users\\newhope\\Desktop\\测试pdf\\测试POI写.pdf";
String data="asfas中文测试dfas";
PDDocument doc = new PDDocument();
try {
PDPage page = new PDPage();
doc.addPage(page);
//PDFont font = PDType1Font.HELVETICA_OBLIQUE;
//这里注意,如果包含中文的话,要导入字体文件,否则要不写报错,要么中文写不出来
PDFont font = PDType0Font.load(doc, new File("E:\\weixinData\\WeChat Files\\wxid_gv8xbkloz0wc22\\FileStorage\\File\\2023-03\\test\\src\\main\\resources\\font\\test.ttf"));
PDPageContentStream contents = new PDPageContentStream(doc, page);
contents.beginText();
contents.setFont(font, 30);
contents.newLineAtOffset(50, 700);
contents.showText(data);
contents.endText();
contents.close();
doc.save(pdfPath);
}
finally {
doc.close();
}
}
代码运行结果如下:

注意:
- 如果文本包含中文用默认字体行不通,需要自己导入字体文件,字体文件可以从网上找,文末有网站链接
- 出现java.lang.NoSuchMethodError 问题,考虑看是不是pdfbox版本不对导致的问题
2.3.3 拆分
@Test
public void testSplit() throws Exception{
String fileName = "C:\\Users\\newhope\\Desktop\\测试pdf\\测试03.pdf";
PDDocument pdf = PDDocument.load(new File(fileName));
//1、将第一个pdf按页码全部拆开
Splitter splitter = new Splitter();
List<PDDocument> pdDocuments = splitter.split(pdf);
for (int i = 0; i < pdDocuments.size(); i++) {
PDDocument pdDocument = pdDocuments.get(i);
pdDocument.save("C:\\Users\\newhope\\Desktop\\测试pdf\\测试POI"+i +".pdf");
}
}
代码运行结果,文件正常拆分:
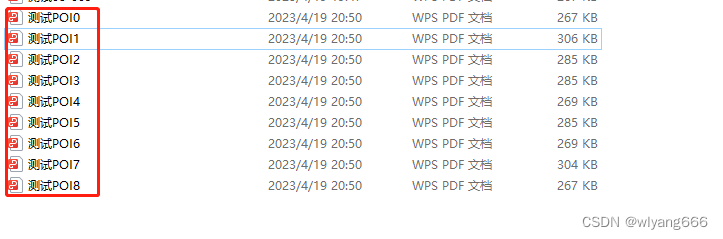
2.3.4 合并
@Test
public void testMerge() throws Exception{
List<String> sourceFilePaths = Arrays.asList("C:\\Users\\newhope\\Desktop\\测试pdf\\测试01.pdf","C:\\Users\\newhope\\Desktop\\测试pdf\\测试03.pdf");
String destFilePath="C:\\Users\\newhope\\Desktop\\测试pdf\\测试POI合并.pdf";
PDFMergerUtility pdfMerger = new PDFMergerUtility();
pdfMerger.setDestinationFileName(destFilePath);
for (String sourceFilePath : sourceFilePaths) {
pdfMerger.addSource(sourceFilePath);
}
//合并文档,这里会推荐,让你指定合并文件的方式,是在内存中,还是在临时文件中
//pdfMerger.mergeDocuments(MemoryUsageSetting.setupMainMemoryOnly());
pdfMerger.mergeDocuments();
}
代码运行结果可以看到,pdf正常合并:

参考文献:
pdfbox更详细介绍
字体网站
以上,本人菜鸟一枚,如有问题,请不吝指正