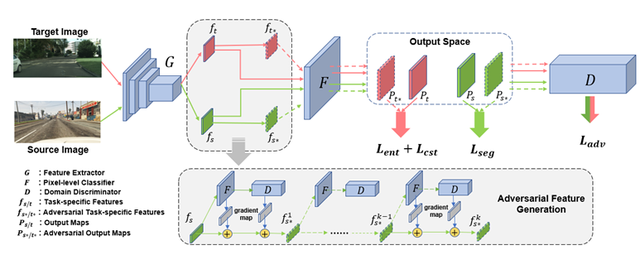
本次复习采用的是这本书,如有书写不当的地方,欢迎批评指正!

第一章

第二章
符号串的运算
-
相等:两个符号串一模一样的
-
长度:数他有几个就行了
-
连接:跟在后面直接写就行了
-
符号传串的逆:在符号的右上方写上-1就表示这个符号串的逆。

- 前缀、后缀和子串
前缀就是去掉尾部,后缀就是去掉头部。前缀和后缀都是子串,但子串不一定是前缀。
比如:ab 是 abc 的前缀和子串,c 是 abc 的后缀和子串。
- 幂运算:就是n个字符串不断进行连接操作
ω的0次幂 = ξ
ω的n次幂 = n个 ω 相连接
符号串集合运算
- 幂运算

- 闭包与正闭包
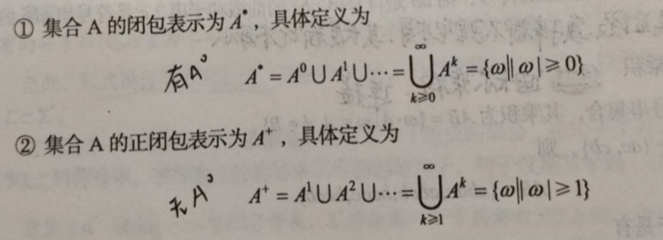
文法的相关概念
1.文法的组成
- 终结符集合 VT 就是不能再分解的字母,一般用小写字母表示
- 非终结符集合VN 就是还可以继续进行推导的字母,一般用大写字母表示
- 开始符号S
- 产生式规则P
2.句子,句型,句柄,子树,简单子树,短语,简单短语
- 句子:只包含终结符。(基本上就是全部由小写字母组成)
- 句型:推导过程中出现的所有符号串都叫做句型。只包含终结符的句型叫做句子。
- 子树:语法树的某个节点连同他向下射出的部分组成了语法树的子树。
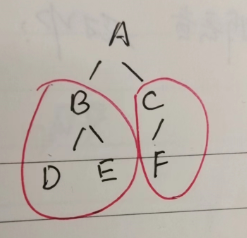
- 简单子树:高度为2的子树叫做简单子树。下面红笔画出来的这两个子树就叫做简单子树。
-
简单短语:高度为2的的子树(就是简单子树0)的叶子节点。像上面这棵树中的DE、F就是简单短语。
-
句柄:最左简单子树末端节点组成的符号串。像上面这颗树,句柄就是DE。
3.规范推导和规范归约
- 规范推导:最右推导,每次都替换最右边的。
- 规范归约:最左归约,每次都归约最左边的。
4.二义性
-
二义性:对于同一个句子存在两个不同的语法树,则称这个句子是具有二义性的。
-
二义性的解决办法:
- 修改编译算法。规定算符之间的优先级。
- 直接修改文法。保证归约的顺序(左部的符号在规则右部出现一次也可能会导致二义性)
压缩或简化文法
- 如果一个文法没有有害规则,也没有多余规则,那么就说该文法是压缩或者简化过的。
1.有害规则
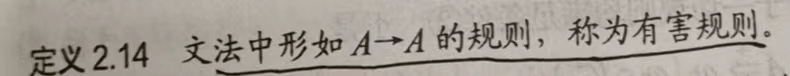
2.多余规则

3.文法等价变换
1.使开始符号不出现在产生式右部
2.使文法每个非终结符均能推导出一个终结符号串.
3.使文法的每个非终结符均出现在某个句型中
4.除特殊规则 A→B
5.消去空规则 A→ε
6.消除左递归 (扩充的BNF表示法)
- 对于第一点,使开始符号不出现在产生式右部
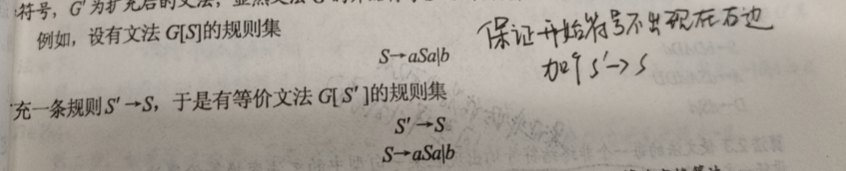
- 对于第二点,使文法每个非终结符均能推导出一个终结符号串.
就是先构造一个Vn‘,先找出能直接推出终结符的,然后保证非终结符推出句子(采用了归约的思想),这个没怎么用过,自己也说得不太清楚。
- 对于第三点,使文法的每个非终结符均出现在某个句型中
就是采用推导的思想,保证非终结符出现在句型中,这个感觉也不咋用。
- 对于第四点,除特殊规则 A→B
就是去掉中间商,先构造对应的等价文法,假如说出现不在任何句型中出现的非终结符,就删除那几个非终结符对应的规则,感觉也不咋用。
- 对于第五点,消去空规则 A→ε
就是去掉A->ε,找到产生空串的非终结符和产生式啥能推导出ε,这个也感觉没怎么用过。
- 对于第六点,消除左递归。这个就非常重要了!!!
我们先看书上的定义。

在做题过程中,直接按照书上给的公式套就行了。
具体怎么使用,可以参考下面的例题

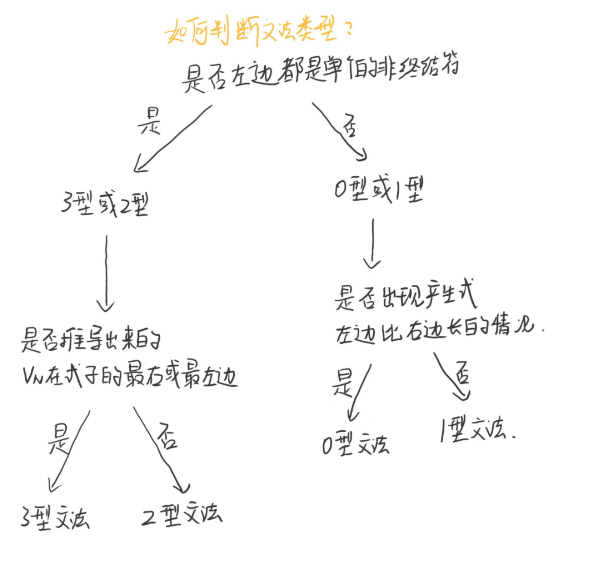
文法的分类与自动机
-
0型文法,从任意字符串推出任意字符串
-
1型文法,左边的长度一般比右边的短或者相等
-
2型文法,产生式的左边都只有一个非终结符,就像下面这样
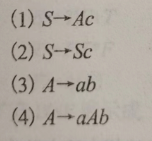
-
3型文法,左线性文法:推导出来的非终结符都放在左边
右线性文法:推导出来的非终结符都放在右边

第三章
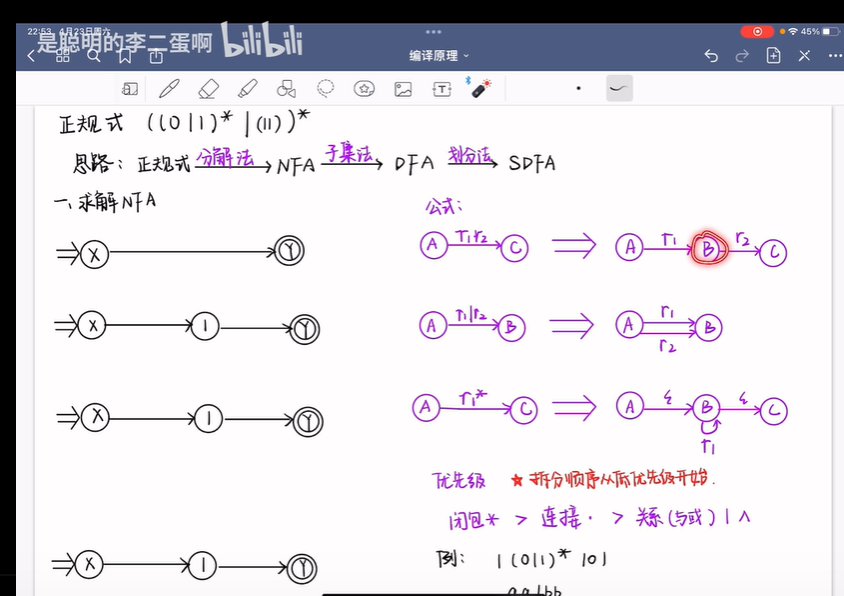
正规式到NFA的转换
NFA和DFA的区别
-
NFA是不确定有限自动机,DFA是确定有限自动机
-
NFA可以有若干个初始状态,而DFA只有一个初始状态
-
NFA有若干个后继状态,而DFA只有一个后继状态
NFA到DFA的转换
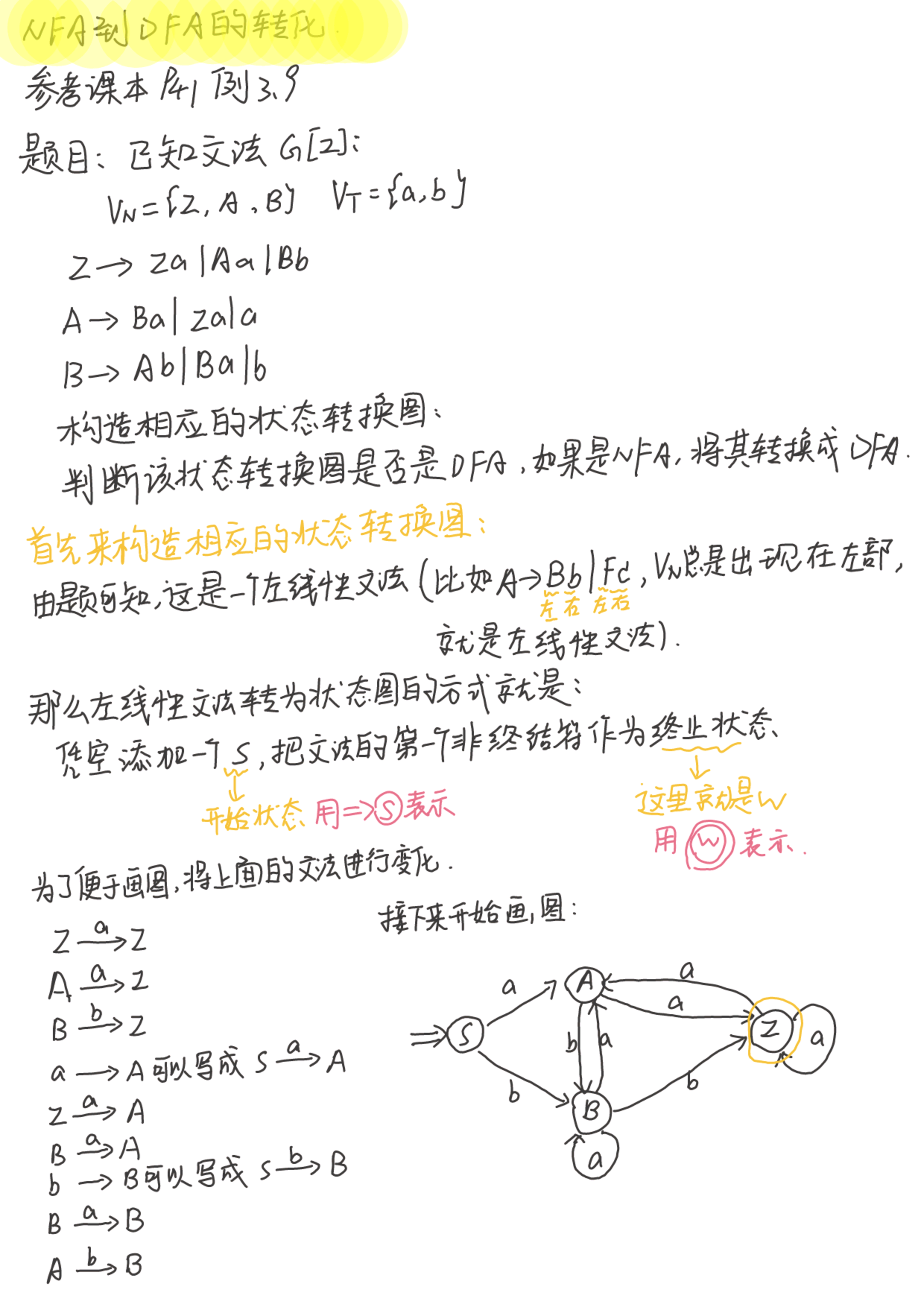
那么这个状态转换图就画好了。
那如何判断这是DFA还是NFA呢?(考试的话一般来说都是NFA,因为他后面还希望你进行NFA到DFA的转换呢)
如果正规做的话,就是画状态转换表。其实我们直接看状态图就可以看出来,去路不唯一的话就只直接可以判定为是NFA。

下面就是重头戏了,开始进行NFA到DFA的转换



以上这就是NFA到DFA的转换了
第四章
不考大题
-
词法分析的功能:读入源程序字符串,从左至右逐个扫描,并从其中识别出一系列具有独立意义的最小语法单位——单词。
-
词法分析的任务:扫描源程序、识别单词、转换并输出属性字。
-
词法分析的两种处理结构:
1.词法分析程序作为主程序
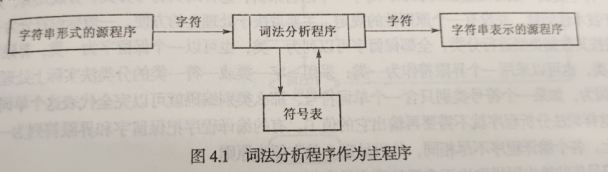
2.词法分析程序作为子程序

-
单词符号的常见种类:保留字、标识符、无符号数 、界限符
-
词法分析的状态转换图 :
第五章
三种集合(first集、follow集、select集):
- First集(符号串):就是 要求的符号串 能够推导出来的 第一个终结符
- Follow集(非终结符):又叫做向前看集,有定义可知,U的向前看集就是由所有含U的句型中紧跟在U之后的终结符或者是 # 所组成的集合。(如果U后面的符号为空,那么就把U后面的符号看成特殊符号#)
- Select集(产生式):
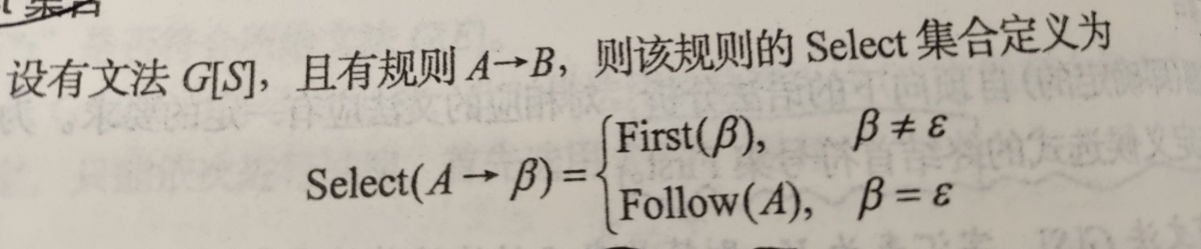
举例说明:


LL(1)文法
-
LL(1)文法就是 没有左递归(形如 A->Ab的这种就属于左递归)
没有回溯(两个产生式左部的第一个符号相同这样式的就属于回溯,比如
A->ay|ab,这就是回溯,方法就是提左公共因子,改成A->M,M->a|b就行了)
-
举例子

LL(1)分析表的构造
- LL(1)分析表的构造:
需要知道的是:C表示继续读下一个符号;
R表示重读当前符号,即不读下一个符号;
RE(β)表示用β的逆串替换栈顶符号
还有一些规则需要知道:
- 如果产生式第一个是非终结符,就写 产生式逆序/R
- 如果产生式第一个是终结符,就写 去掉那个首部终结符后 的产生式的逆序/C
- 如果产生式为空,就写 ξ/R
- [#,#] = succ
- 如果有的终结符不出现在任何规则右部的首部,那么 [VT,VT] = ξ/C
- 其他情况属于出错,就是error,在分析表中用空白表示
画LL(1)分析表之前,要先写出对应的select集,然后以此为对照
画LL(1)分析表的时候,纵轴写出现的所有符号(除了 ξ),右边写所有的终结符包括#
举个例子

第六章
简单优先方法
-
简单优先关系
#作为语句定界符,其优先级最低。

-
判断是否为简单优先文法:
一个文法是简单优先文法,需要满足以下两个条件:
- 在文法符号集中V,任意两个符号之间必须之后一种优先关系存在。
- 在文法中,两个产生式不能有相同的右部。
判断是否为简单优先文法,首先要分析确定文法中各符号之间的优先关系。
判断优先关系的话,我们需要知道以下规则:
- “ < ”关系 :如果规则的右部是 终结符+非终结符 这样的组合,那么 终结符 < 这个非终结符推导出来的第一个符号
- “ > ” 关系:如果规则的右部是 非终结符+终结符这样的组合,那么 这个非终结符推出来的最后一个符号 > 终结符
- “ = ” 关系:p—>AB,那么 A = B
举个例子

该文法满足简单优先文法的条件。所以是简单优先文法。
- 简单优先文法的分析过程是规范规约。
算符优先方法
-
算符优先分析法适用于表达式的分析。
-
什么叫做算符文法:任何一个产生式中都不含有两个非终结符相邻的情况,那么该文法是一个算符文法
-
算符优先关系矩阵的构造方法:
1.对每个非终结符构造A构造两个集合 FIRSTVT (A) 和 LASTVT (A)
FIRSTVT (A) = a, a是 A=>a…或 Ba…
LASTVT (A) = a, a是A=>…a 或 …aB
2.确定优先关系
(1)“=”关系:如果是 A->…ab… 或者是 A-> …aBb…这种样子的,那么a=b
(2)“<“关系:如果规则右边是 终结符+非终结符(这个用A来表示),那么 非终结符<FIRSTVT (A)
(3)”>“关系:如果规则右边是 非终结符(这个用A来表示)+终结符,那么 LASTVT (A) >终结符
举个例子

LR分析表
LR分析表包括两部分:分析动作表(ACTION)和状态转换表(GOTO)
在action表中,动作有四种可能:
- 归约r,比如 r3 就是用第三条规则进行归约
- 移进s,继续扫描,从下一个输入符号成为当前输入符号
- 接受acc,当输入串只#时,分析完成
- 报错erroe
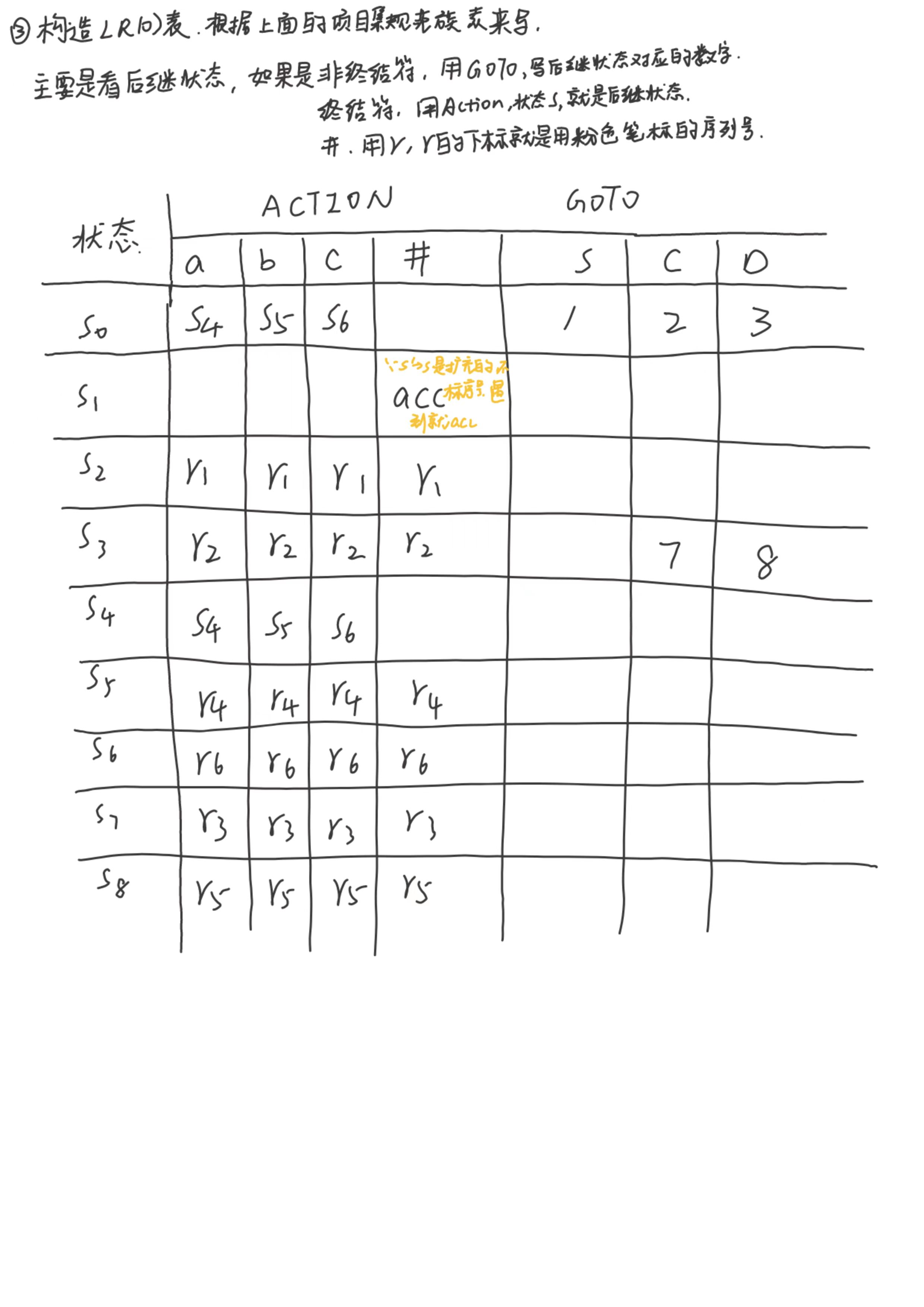
LR(0)分析表
考试一般就考LR(0)表的构造
这里我们采用课后题6.4进行参考,如下图

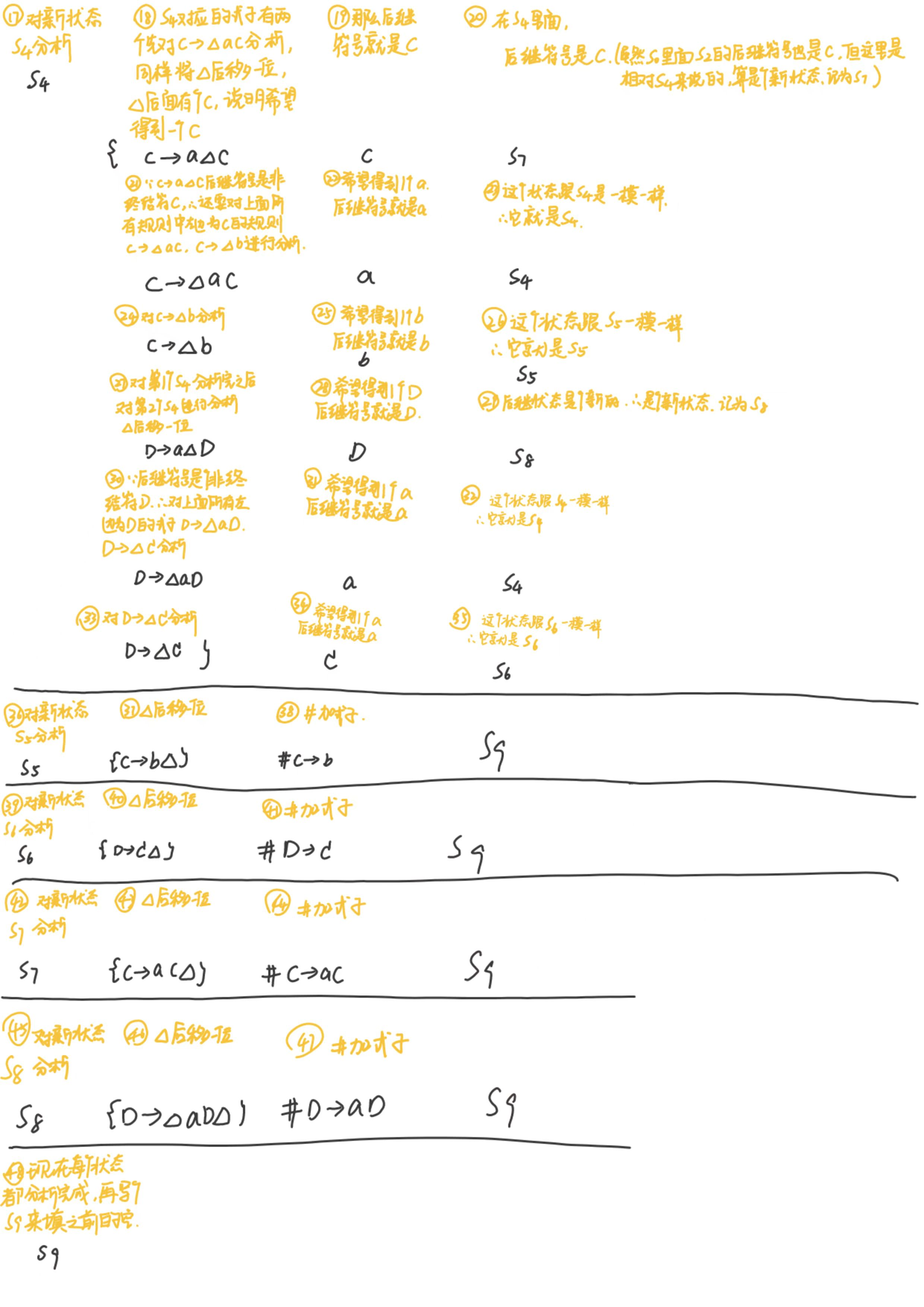
S7的出现可以参考下面这个进行理解:
- 同一项目的状态集中,若不同项目的后继符号相同,则后继状态相同
- 不同项目状态集中,若出现对应的相同项目,则后继状态也相同
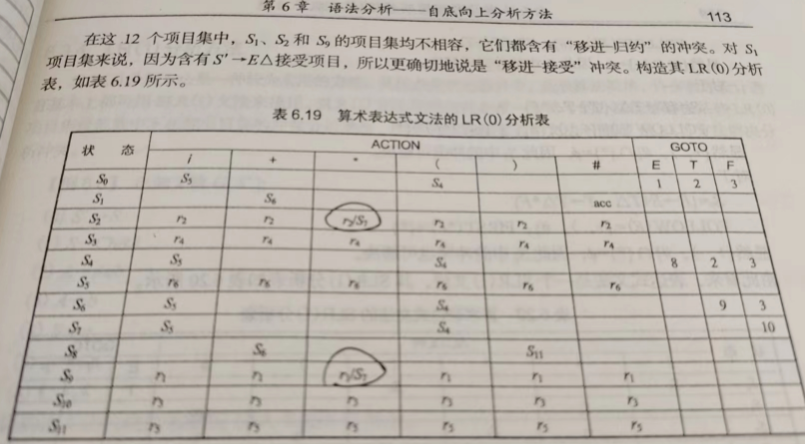
SLR(1)方法是简单的LR(0)分析方法,SLR(1)分析表中是不含有冲突动作的,如果发现LR(0)分析表中含有冲突动作(书上113页的表6.19就含有冲突动作),那么就把他改成SLR(1),去掉冲突。
SLR(1)分析表
SLR(1)和LR(0)分析表的构造方法差不多,主要区别就是构造好项目集规范族之后,进行SLR(0)表构造的时候,当后继符号是终结符时,只有这个终结符属于 Follow(规则左边)的时候,才会写r,不属于的就不写。
第七章
语义分析
-
语义分析的基本任务:
- 类型的确定:数据对象的类型
- 类型的检查:对运算及运算量的类型检查
- 确认含义:确认控制结构的含义
- 其他语义检查:不允许循环体外到体内等
-
实现语法制导翻译的方法
- 增量式文法
- 属性文法
中间代码
- 抽象语法树
- 逆波兰式
- 四元式
- 三元式
第八章
代码优化分类:

代码优化技术:
- 合并常量运算
- 删除无用赋值
- 削减运算强度
- 删除多余运算
- 外提不变表达式