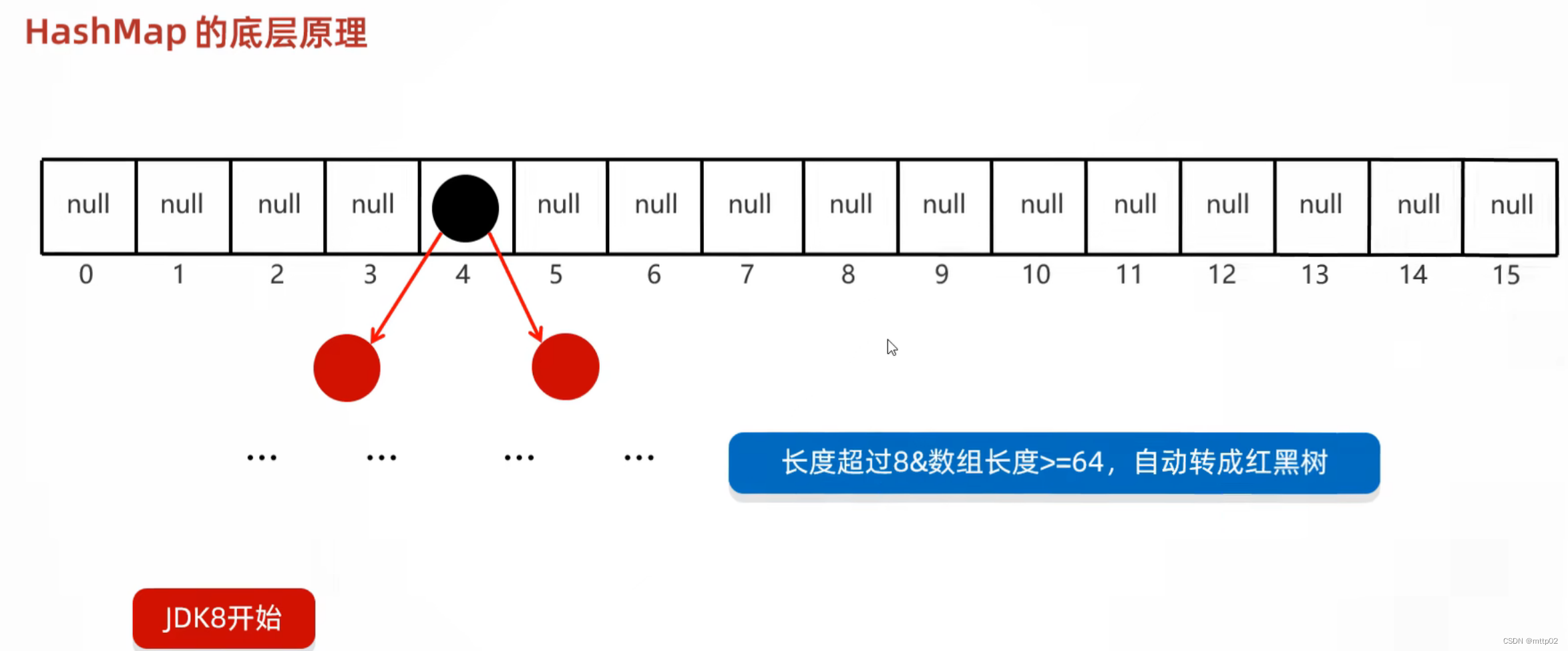
1 optimizer类实例
1.1 介绍
属性
- 【default】该实例的类型为 dict,元素为初始化时候的学习率等,具体的keys为
['lr','momentum', 'dampening', 'weight_decay', 'nesterov']- 【state】保存参数更新过程中的一些中间变量,如momentum的缓存(使用前几次的梯度进行平均)
- 【params_groups】该实例的类型为 list,可以将神经网络中需要更新的参数分组管理,list中每个元素为一组数据,包括:优化器中需要更新的参数,以及default中超参数在当前的对应数据。数据格式为
[ {'lr': **, 'momentum': **, 'dampening':**, 'weight_decay':**, 'nesterov':**, 'params':[**]} , ... ]
方法
- 【step()】进行一次梯度更新
- 【zero_grad()】清零优化器中模型参数的梯度。主要在 .step() 后使用。注意pytorch主张 张量梯度不自动清零
- 【add_param_group()】入参类型为字典,即要添加参数组,以及对该组参数需设置的超参,如未设置默认使用default中的。添加的参数组会存放在 param_group属性当中。优化器可管理多组数据,该方法在finetune模型时经常使用。
- 【state_dict()】获取优化器当前状态信息,我们去到源码可看到,该方法的返回值如下
- 【load_state_dict()】加载状态信息。这两个方法用于模型断点的一个继续训练,所以我们在训练时,隔一段时间应保存一次该信息。
1.2 例子
这里使用个小例子来说明优化器的使用:
import torch import torch.nn as nn import torch.optim as optim def geneWeight(): weight = torch.randn((2,2),requires_grad=True) weight.grad = torch.ones((2,2)) return weight torch.manual_seed(0) a = geneWeight() b = geneWeight() optimizer = optim.SGD([a], lr=0.1) optimizer.add_param_group({'params': [b], 'weight_decay': 0.005}) optimizer.step() optimizer.zero_grad()
可有以下分析
1 【
optimizer的属性】在实例化后进行debug,可看到【default、param_groups、state】
2
optimizer.add_param_group()运行之后的optimizer的内容如下,可以看到【.add_param_group()】的操作将新的参数组添加到优化器中
- 【optimizer.param_groups中的参数】与【变量(在工程中就是网络模型中的参数)】的关系:
打印两者的id,可以看到是完全一致的,说明optimize.param_groups中的参数存的是网络中参数的引用,这样操作也是为了节省内存
3【
optimizer.step()和optimizer.zero_grad()】
- 使用debug模式,在该
.step()命令运行前后分别打印变量的data和grad,可以看到权重进行了更新,对于SGD优化器的更新公式为【weight = weight - lr * grad】- 在
.zero_grad()命令前后运行分别打印参数信息,可以看到梯度置零- 可以看到,权重的更新和梯度的置零是分开操作的。当资源有限的情况下,就可以多次进行梯度计算(这里涉及到loss.backward)求梯度均值,再进行权重更新 和 梯度置零,这就是 梯度累计操作。这样在资源有限的情况下,约等于增大了前向传播的batch。
4【
.state_dict()和.load_state_dict()】
这两种方法,是用于保存和加载优化器的一个状态信息,经常用于训练中间断掉后的继续训练。
在第一次运行保存结果时的 optimizer,和第二次运行加载模型后的optimizer,可查看两次的优化器当中的 state_dict()的内容,这里不截图展示。import torch import torch.nn as nn import torch.optim as optim import os def geneWeight(): weight = torch.randn((2,2),requires_grad=True) weight.grad = torch.ones((2,2)) return weight torch.manual_seed(0) a = geneWeight() b = geneWeight() optimizer = optim.SGD([a], lr=0.1) optimizer.add_param_group({'params': [b]}) ckpt = "optimizer_state_dict.pt" pretrained = True if pretrained and os.path.exit(ckpt): state_dict = torch.load(ckpt) optimizer.load_state_dict(state_dict) for i in range(100): optimizer.step() torch.save(optimizer.state_dict(), ckpt)





2 常用优化器的计算
损失函数:深度学习模型通过引入损失函数,用来计算目标预测的错误程度。根据损失函数计算得到的误差结果,需要对模型参数(即权重和偏差)进行很小的更改,以期减少预测错误。
优化器:使损失函数最小化的方式更改可训练参数,损失函数指导优化器朝正确的方向移动。
优化器的发展历程:SGD -> SGDM -> NAG —>AdaGrad -> AdaDelta -> Adam -> Nadam–>…
从AdaGrad之后提出的为 自适应学习率的优化算法。其思想:经常更新的参数,需要学习速度慢一些,偶尔更新的参数,需要学习率大一些。
2.1 SGD
【BGD (Batch gradient descent) 批量梯度下降法】:每次的梯度的更新 使用所有的样本。每一次的梯度更新都使用所有样本,更新100次遍历所有数据100次
- 优点:每次迭代都计算了全部的样本,获取到的是全局最优解
- 缺点:
1)要对实际数据同时计算梯度,就会非常的耗时;
2)同事实际使用中数据量都很大,无法进行一次完成所有数据的迭代。
【SGD(Stochastic gradientdescent)随机梯度下降法】:每次的梯度的更新 使用一个样本。
- 优点:速度快
- 缺点:
1)噪声大,波动大;
2)非常容易陷入局部最优解;
3)结果具有随机性,因为可能只使用到部分的样本,就已经迭代到局部最优解了
【MBGD(Mini-batch gradient descent)小批量梯度下降】:每次的梯度的更新 使用batch个样本。
- 优点:
1)相较SGD收敛更稳定;
2)另一方面可以充分地利用深度学习库中高度优化的矩阵操作来进行更有效的梯度计算。- 缺点:
1)SGD的学习受 学习率影响,如果lr偏大,lossfunction 会在极小值处不停地震荡;lr偏小,收敛速度就会变慢。
这种情况一般解决方法,训练开始使用较大lr,随着迭代过程逐步降低lr,这样我们需要多尝试 lr降低策略,直到找到最优的)
2)对于非凸函数,容易陷入局部最优解。因为在鞍点周围的所有维度的梯度都约等于0,就很容易困在这里
但在实际的论文或工程中,所说的使用优化器SGD,其实指代的MBGD。这样强调的重点是参数更新的计算方式,而不是batch数量。所以在本博客接下来的表述中,SGD就指代MBGD。
SGD的表达式为: θ t = θ t − 1 − l r ∗ ▽ t J ( θ t ) \theta^{t}=\theta^{t-1}-lr*\bigtriangledown _{t}J(\theta^{t}) θt=θt−1−lr∗▽tJ(θt)
2.2 SGD+Momentum
为了优化SGD的问题,提出了SGDM(使用动量的随机梯度下降)。
动量方法是为了加速学习(加速梯度下降),特别的是处理高曲率、小但一致的梯度,或带噪声的梯度。动量累积了之前梯度指数级衰减的移动平均,并继续沿该方向移动。
这里约等于是对动量进行了加权平均。
具体的数学表达式如下: v t = γ v t − 1 + l r ∗ ▽ J ( θ t ) v^{t} = \gamma v^{t-1} + lr*\bigtriangledown J(\theta^{t}) vt=γvt−1+lr∗▽J(θt) θ t = θ t − 1 − v t \theta^{t}=\theta^{t-1}-v^{t} θt=θt−1−vt
其中, g t g^t gt为本次计算的梯度, l r lr lr 为学习率, θ \theta θ为当前的参数。
γ \gamma γ为动量因子,通常被设置为0.9~0.99之间。
【SGDM】好处:
- 减小震荡,加速收敛: 在前后两次梯度方向改变时,momentum能够降低参数更新速度,从而减少震荡;在两次梯度方向相近时,momentum可以加速参数更新, 从而加速收敛
- 离开鞍点,离开局部最优: 如果运行到了鞍点,不会立马停下来,即使当前的方向为水平,因为会借用上一时刻的动量,从而离开鞍点,离开局部最优值。
在pytorch中,SGDM的公式调整为 v t = γ v t − 1 + ▽ J ( θ t ) v^{t} = \gamma v^{t-1} + \bigtriangledown J(\theta^{t}) vt=γvt−1+▽J(θt) θ t = θ t − 1 − l r ∗ v t \theta^{t}= \theta^{t-1}-lr*v^{t} θt=θt−1−lr∗vt
这里图示简单示意SGDM是如何减小震荡的。横轴为权重参数,纵轴为该操作的输出,我们想由起始点开始优化迭代,直至目标输出target。
- 使用SGD的收敛曲线 (图一),进行了7次的梯度更新后,到达target。使用SGDM的收敛曲线 (图二),进行4次的梯度更新后,到达target。
对与某一次的迭代,若上次和本次的梯度方向相反(夹角大于90),则会减弱本次的梯度,使其减小震荡,加速收敛 (图三);若上次和本次的梯度方向相近(夹角小于90度),动量项产生一个加速的作用,从而加速收敛(图略)。最后给出个动图模拟两者的收敛
2.3 NAG
牛顿加速梯度动量优化方法(NAG, Nesterov accelerated gradient):沿着上一步的速度方向先走一小步,再看当前的梯度然后再走一步。简化的理解是:
- SGD:在点B时,直接沿着点B的梯度进行更新即可
- SGDM:在点B时,先沿着动量项的方向更新到B’,然后在按照点B的梯度方向更新。
- NAG:在点B时,先沿着动量项的方向更新到 B’,然后计算B’ 位置的梯度,再沿着 B’ 的梯度方向进行更新。具体公式为 θ ′ = θ t − 1 − γ v t − 1 \theta^{'}=\theta^{t-1}-\gamma v_{t-1} θ′=θt−1−γvt−1 v t = γ v t − 1 + l r ∗ ▽ J ( θ ′ ) v_{t}=\gamma v_{t-1}+lr*\bigtriangledown J(\theta^{'}) vt=γvt−1+lr∗▽J(θ′) θ t = θ t − 1 − v t \theta^{t}=\theta^{t-1}-v_t θt=θt−1−vt
在pytorch内,对需要训练的参数只维护一组参数的,而且是自动求导。这也就意味着,我们每次的梯度更新是需要走到 θ ′ \theta^{'} θ′,下一次的backward才能在 θ ′ \theta^{'} θ′处求导。虽然最后得到的是“多跨了一步动量”的参数,但是由于到最后靠近极值点的时候动量已经很小了,所以有一点误差也并无大碍。
经推导,上面可修改为 v t = γ v t − 1 + ▽ J ( θ t − 1 ′ ) v_t=\gamma v_{t-1} + \bigtriangledown J(\theta^{'}_{t-1}) vt=γvt−1+▽J(θt−1′) θ t ′ = θ t − 1 ′ − l r ∗ ( ▽ J ( θ t − 1 ′ ) + γ v t ) \theta^{'}_{t} = \theta^{'}_{t-1} - lr * (\bigtriangledown J(\theta^{'}_{t-1}) + \gamma v_{t}) θt′=θt−1′−lr∗(▽J(θt−1′)+γvt)
2.4 AdaGrad
二阶动量:可以度量历史更新频率。使⽤⼀个小批量随机梯度 g t g_t gt按元素平⽅的累加变量 的所有历史累计值 n t n_t nt。 可以解释为以往所有梯度值的平方和,越大表示经常跟新,越小表示不经常更新。
n 0 = g 0 2 n_0=g^{2}_0 n0=g02
n 1 = g 0 2 + g 1 2 n_1=g^{2}_0+g^{2}_1 n1=g02+g12
n 2 = g 0 2 + g 1 2 + g 2 2 n_2=g^{2}_0+g^{2}_1+g^{2}_2 n2=g02+g12+g22
AdaGrad 的操作为:根据梯度的情况自适应的调整学习率,从而避免统⼀的学习率难以适应所有维度的问题。在第t次时,有公式: n t = n t − 1 + g t 2 n_{t}=n_{t-1}+g^{2}_{t} nt=nt−1+gt2 Δ θ t = − l r n t + ε ∗ g t \Delta \theta_{t}=-\frac{lr}{\sqrt{n_{t}+\varepsilon }}*g_{t} Δθt=−nt+εlr∗gt
特点:
- n t n_t nt单调递增, l r ′ lr^{'} lr′单调递减。
- 前期 n t n_t nt较小的时候,学习率较大,能够放大梯度。
后期 n t n_t nt 较大的时候,学习率较小,能够缩小梯度
中后期,分母上梯度平方的累加会越来越大,使gradient→0,使得训练提前结束。
2.5 RMSProp算法 / Adadelta算法
两者都是为了解决 AdaGrad 学习率下降过快的问题,提出了 n t n_t nt的计算使用加权的方式,只关注过去一段时间内的变化。
- 对于RMSProp,更新的梯度为 n t = γ n t − 1 + ( 1 − γ ) g t 2 n_{t}=\gamma n_{t-1}+(1-\gamma)g^{2}_{t} nt=γnt−1+(1−γ)gt2 Δ θ t = − l r n t + ε ∗ g t \Delta \theta_{t}=-\frac{lr}{\sqrt{n_{t}+\varepsilon }}*g_{t} Δθt=−nt+εlr∗gt
- 对于Adadelta,没有学习率这个超参数。它会维护一个新的变量 Δ x t \Delta x_{t} Δxt,初始为0,用其来带替学习率的设置。
n t = γ n t − 1 + ( 1 − γ ) g t 2 n_{t}=\gamma n_{t-1}+(1-\gamma)g^{2}_{t} nt=γnt−1+(1−γ)gt2 Δ θ t = − Δ x i − 1 + ε n t + ε ∗ g t \Delta \theta_{t}=-\frac{\sqrt{\Delta x_{i-1}+\varepsilon }}{\sqrt{n_{t}+\varepsilon }}*g_{t} Δθt=−nt+εΔxi−1+ε∗gt Δ x i = ρ Δ x i − 1 + ( 1 − ρ ) g t 2 \Delta x_{i}=\rho \Delta x_{i-1}+(1-\rho )g^{2}_{t} Δxi=ρΔxi−1+(1−ρ)gt2
2.6 Adam
Adam(Adaptive Moment Estimation)自适应矩估计。adam–> SGDM + RMSProp,也就是结合了动量加权、自适应学习率的系数加权(梯度的平方)。公式为 v t = β 1 v t − 1 + ( 1 − β 1 ) g t v_t=\beta_{1}v_{t-1} + (1-\beta_1)g_t vt=β1vt−1+(1−β1)gt n t = β 2 n t − 1 + ( 1 − β 2 ) g t 2 n_t=\beta_2n_{t-1} + (1-\beta_2)g^2_t nt=β2nt−1+(1−β2)gt2作者发现一阶和二阶值初始训练时很小,接近为0,所以作者重新计算了个偏差进行校正,降低偏差对训练初期的影响。训练前期时, 1 / ( 1 − β t ) 1/(1-\beta^t) 1/(1−βt)起到校正作用,训练后期,该项约定于1,不起作用。 v ^ t = v t 1 − β 1 t \hat{v}_t=\frac{v_t}{1-\beta^t_1} v^t=1−β1tvt n ^ t = n t 1 − β 2 t \hat{n}_t=\frac{n_t}{1-\beta^t_2} n^t=1−β2tnt 最终的梯度更新为 θ t + 1 = θ t − l r n ^ t + ε v ^ t \theta_{t+1}=\theta_t-\frac{lr}{\sqrt{\hat{n}_t+\varepsilon}}\hat{v}_t θt+1=θt−n^t+εlrv^t其中 β 1 t \beta^t_1 β1t、 β 2 t \beta^t_2 β2t为 β \beta β的t次方。超参通常选择 β 1 = 0.9 \beta_1=0.9 β1=0.9、 β 2 = 0.999 \beta_2=0.999 β2=0.999、 ε = 1 0 8 \varepsilon=10^8 ε=108
adam中 1 / ( 1 − β t ) 1/(1-\beta^t) 1/(1−βt)的参数的推导:
n 1 = ( 1 − β 2 ) g 1 2 n_1=(1-\beta_2)g^2_1 n1=(1−β2)g12
n 2 = β 2 v 1 + ( 1 − β ) g 2 2 n_2=\beta_2 v_1+(1-\beta)g^2_2 n2=β2v1+(1−β)g22
= β 2 ( 1 − β 2 ) g 1 2 + ( 1 − β 2 ) g 2 2 =\beta_2(1-\beta_2)g^2_1+(1-\beta_2)g^2_2 =β2(1−β2)g12+(1−β2)g22
= ( 1 − β 2 ) ( β 2 g 1 2 + g 2 2 ) =(1-\beta_2)(\beta_2g^2_1+g^2_2) =(1−β2)(β2g12+g22)
= ( 1 − β 2 ) ( β 2 2 − 1 g 1 2 + β 2 2 − 2 g 2 2 ) =(1-\beta_2)(\beta^{2-1}_2g^2_1+\beta^{2-2}_2g^2_2) =(1−β2)(β22−1g12+β22−2g22)
= ( 1 − β 2 ) ∑ i = 1 2 β 2 2 − i g 2 2 =(1-\beta_2)\sum^2_{i=1}\beta^{2-i}_2g^2_2 =(1−β2)∑i=12β22−ig22
n t = ( 1 − β 2 ) ∑ i = 1 t β 2 t − 1 g i 2 n_t=(1-\beta_2)\sum^t_{i=1}\beta^{t-1}_2 g^2_i nt=(1−β2)∑i=1tβ2t−1gi2
E ( n t ) = ( 1 − β 2 ) E ( ∑ i = 1 t β 2 t − i g i 2 ) + ξ E(n_t)=(1-\beta_2) E(\sum^{t}_{i=1}\beta^{t-i}_2 g^2_i)+\xi E(nt)=(1−β2)E(∑i=1tβ2t−igi2)+ξ
= ( 1 − β 2 ) ( 1 + β 2 1 + β 2 2 + . . . + β 2 t − 1 ) E ( g i 2 ) + ξ =(1-\beta_2)(1+\beta^1_2+\beta^2_2+...+\beta^{t-1}_2)E(g^2_i)+\xi =(1−β2)(1+β21+β22+...+β2t−1)E(gi2)+ξ
= ( 1 − β 2 ) ( 1 − β 2 t 1 − β 2 ) E ( g i 2 ) + ξ =(1-\beta_2)(\frac{1-\beta^t_2}{1-\beta_2})E(g^2_i)+\xi =(1−β2)(1−β21−β2t)E(gi2)+ξ
= ( 1 − β 2 t ) E ( g i 2 ) + ξ =(1-\beta^t_2)E(g^2_i)+\xi =(1−β2t)E(gi2)+ξ
我们实际需要的是梯度的二阶矩估计 E ( g i 2 ) E(g^2_i) E(gi2),但当前是对 v t v_t vt求期望 E ( v t ) E(v_t) E(vt),因此要得到 E ( g i 2 ) E(g^2_i) E(gi2),就需要除以前面的系数。
公式推导是OK的,但这里的个人理解还是有点不明确。只需要把握住:重新计算了个偏差进行校正,可以降低偏差对训练初期的影响。