deepflow是什么
DeepFlow 是云杉网络 (opens new window)开源的一款高度自动化的可观测性平台,是为云原生应用开发者建设可观测性能力而量身打造的全栈、全链路、高性能数据引擎。DeepFlow 使用 eBPF、WASM、OpenTelemetry 等新技术,创新的实现了 AutoTracing、AutoMetrics、AutoTagging、SmartEncoding 等核心机制,帮助开发者提升埋点插码的自动化水平,降低可观测性平台的运维复杂度。利用 DeepFlow 的可编程能力和开放接口,开发者可以快速将其融入到自己的可观测性技术栈中。
解决两大痛点
建设可观测性已经成为云原生应用开发者的必要工作,然而现有的解决方案正悄无声息的消耗着开发者越来越多的时间。Epsagon 的一项调查 (opens new window)表明,应用开发者有高达30%的时间花在可观测性能力建设上,另有 20% 的时间花在代码 Debug 上,而 Debug 花费的大部分时间又恰好是可观测性建设不足导致。
可观测性建设的痛点包括两个方面:
埋点插码难
开发者需要考虑为每一种语言、每一种框架进行埋点和插码。一些公司的业务开发团队很幸运,会有类似 IDP(Internal Developer Platform)的团队负责整个公司的可观测性能力建设,提供埋点和插码的 SDK。但大部分语言缺乏类似 JVM 的字节码注入机制,IDP 团队每一次的 SDK 升级都需要业务开发团队同步发版、上线。
开发者需要考虑在微服务之间如何传递追踪上下文。同样需要为每一种语言、每一种框架进行埋点和插码,另一方面像 MQTT 3.X、MySQL、Redis 等缺乏 Header Option 字段的协议经常成为追踪的噩梦。即使应用协议都使用 HTTP,也可能由于调用链中特殊的 RPC 框架、特殊的编程语言导致追踪上下文丢失。
开发者需要为每一个指标、追踪、日志数据注入大量的属性标签,以便于后续能够对观测数据进行灵活的过滤、分组及关联。然而这些标签已经存在于 K8s apiserver、服务注册中心、应用协议 Header 中,开发者不得不重复这份工作将他们搬迁到观测数据中。
平台运维难
开发者需要考虑如何避免指标数据中携带高基标签,有些时候甚至因为后端 TSDB(Time Series Database)性能的不足无奈将高基 Tag 字段转换为 Metrics,甚至丢弃。
开发者需要考虑限制观测数据的猖獗增长,在复杂的采样策略之间权衡选择以降低数据量,但通常会在某次问题排查时发现数据不全而无法进行。
开发者需要考虑如何维护复杂的可观测平台,他们通常有着负载均衡、消息队列依赖。随着复杂度的增长,可观测性平台本身的可观测性能力同样也成为问题。
六大主要特性
全栈:DeepFlow 使用 AF_PACKET、BPF、eBPF 技术实现的 AutoMetrics 机制,可以自动采集任何应用的 RED(Request、Error、Delay)性能指标,精细至每一次应用调用,覆盖从应用到基础设施的所有软件技术栈。在云原生环境中,DeepFlow 的 AutoTagging 机制自动发现服务、实例、API的属性信息,自动为每个观测数据注入丰富的标签,从而消除数据孤岛,并释放数据的下钻能力。
全链路:DeepFlow 使用 eBPF 技术创新的实现了 AutoTracing 机制,在云原生环境中自动追踪任意微服务、基础设施服务的分布式调用链。在此基础上,通过与 OpenTelemetry 的数据集成,DeepFlow 将 eBPF Event 与 OTel Span 自动关联,实现完整的全栈、全链路追踪,让追踪无盲点。
高性能:DeepFlow 创新的 SmartEncoding 标签注入机制,能够将标签数据的存储性能提升 10 倍,从此告别高基标签和数据采样焦虑。DeepFlow 使用 Rust 实现 Agent,拥有极致处理性能的同时保证内存安全。DeepFlow 使用 Golang 实现 Server,重写了 Golang 的 map、pool 基础库,数据查询和内存申请均有近 10 倍的性能提升。
可编程:DeepFlow 目前支持了对 HTTP、HTTPS、Dubbo、gRPC、ProtobufRPC、SOFARPC、MySQL、PostgreSQL、Redis、Kafka、MQTT、DNS协议的解析,并将保持迭代增加更多的应用协议支持。除此之外,DeepFlow 计划基于 WASM技术提供了可编程接口,让开发者可以快速具备对私有协议的解析能力,并可用于构建特定场景的业务分析能力,例如 5GC 信令分析、金融交易分析、车机通信分析等。
开放接口:DeepFlow 拥抱开源社区,支持接收广泛的可观测数据源,并利用 AutoTagging 和 SmartEncoding 提供高性能、统一的标签注入能力。DeepFlow 支持插件式的数据库接口,开发者可自由增加和替换最合适的数据库。DeepFlow 向上为所有观测数据提供统一的标准 SQL 查询能力,便于使用者快速集成到自己的可观测性平台中,也提供了在此基础上继续开发方言 QL 的可能性。
易于维护:DeepFlow 仅由 Agent、Server 两个组件构成,将复杂度隐藏在进程内部,将维护难度降低至极致。DeepFlow Server 集群可对多资源池、异构资源池、跨 Region/AZ 资源池中的 Agent 进行统一管理,且无需依赖任何外部组件即可实现水平扩展与负载均衡。
#helm repo add deepflow https://deepflowio.github.io/deepflow
#helm repo update
#helm pull deepflow/deepflow
下载的当前版本为:deepflow-6.2.601.tgz
解压下载的tar包,修改里面的文件,server-deployment.yaml与app-deployment.yaml
#tar -zxf deepflow-6.2.601.tg
#cd ./deepflow/templates
(我使用helm-v3.2.4 直接安装会报错)所以把两文件的以下内容删除
checksum/config: {{ include (print $.Template.BasePath "/configmap.yaml") . | sha256sum }
checksum/customConfig: {{ sha256sum (print (tpl (toYaml .Values.configmap) $)) }
指定storageClass部署
#helm install deepflow --namespace=deepflow --set global.storageClass=default-nfs ./
如图:
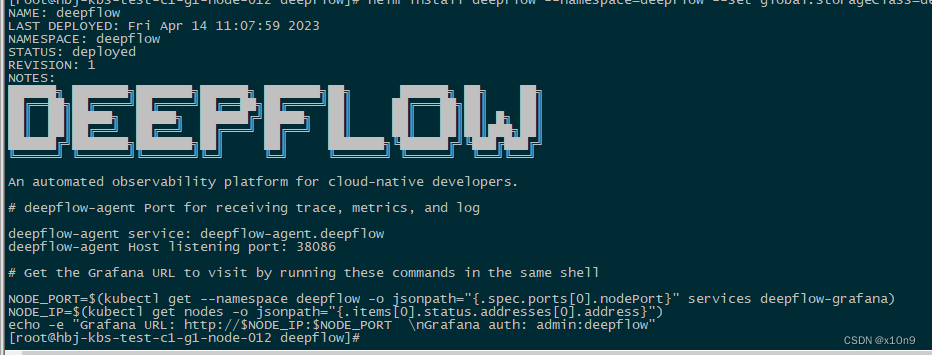
等待POD正常
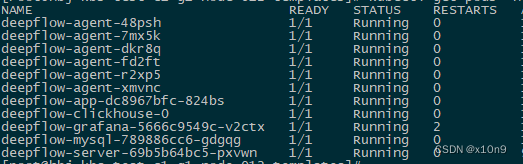
配置deepflow-agent污点容忍:
kubectl edit daemonsets.apps deepflow-agent -n deepflow
添加:
tolerations:
- effect: NoSchedule
operator: Exists
登陆grafana,密码为deepflow
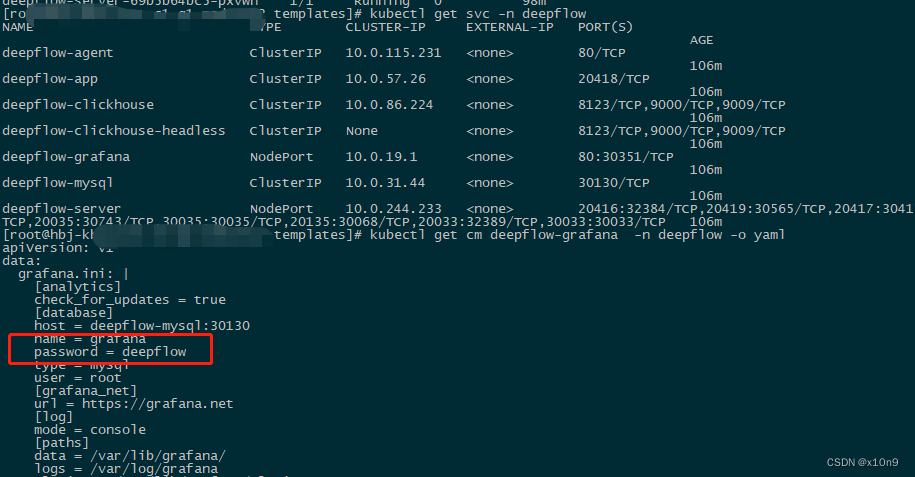
至此,部署完成
测试demo:
deepflow.io/docs/zh/auto-tracing/spring-boot-demo/
云主机部署deepflow-agent
运行权限及内核要求
deepflow-agent 的 eBPF 能力对内核版本的要求:
X86 体系架构:Linux Kernel 4.14+
例外:使用 uprobe 采集 openssl 库的 TLS 应用数据要求 Linux Kernel 4.17+
在内核 Linux 4.14 下一个 tracepoint 不能被多个 eBPF program attach(即:不能同时运行两个或多个 agent),Linux 4.15+ 不存在此问题
ARM64 体系架构:CentOS8 Linux Kernel 4.18,或社区 Linux Kernel 5.8+
当内核版本无法满足要求时,受影响的功能有:
通过 eBPF uprobe 获取 HTTP2、HTTPS 应用数据
通过 eBPF 实现 AutoTracing
DeepFlow Server 必须运行在 K8s 之上
#curl -O https://deepflow-ce.oss-cn-beijing.aliyuncs.com/rpm/agent/stable/linux/$(arch | sed 's|x86_64|amd64|' | sed 's|aarch64|arm64|')/deepflow-agent-rpm.zip
#unzip deepflow-agent-rpm.zip
#yum -y localinstall ./x86_64/deepflow-agent-*.rpm
修改/etc/deepflow-agent.yaml 添加k8s node IP
controller-ips:
- ip
#systemctl restart deepflow-agent
之前agent 会跟NODE IP 的30035端口通信