1.概述
MovieLens其实是一个推荐系统和虚拟社区网站,它由美国 Minnesota 大学计算机科学与工程学院的GroupLens项目组创办,是一个非商业性质的、以研究为目的的实验性站点。GroupLens研究组根据MovieLens网站提供的数据制作了MovieLens数据集合,这个数据集合里面包含了多个电影评分数据集,分别具有不同的用途。本文均用MovieLens数据集来代替整个集合。MoveieLens数据集可以说是推荐系统领域最为经典的数据集之一,其地位类似计算机视觉领域里的MNIST数据集。
2. MovieLens
MoveLens是一个数据集合,其中根据创建时间、数据集大小等分为了若干个子数据集。每个数据集的格式、大小、用途均有所差异。本文以MovieLens 1M Dataset为例,具体介绍下此数据集,其它MovieLens数据集也大都类似,本文使用的数据集下载链接为ml-1m.zip。
2.1 数据集概览
ml-1m.zip文件解压之后,可以得到4个文件,分别是:
- movies.dat
- ratings.dat
- user.dat
- README
1M数据集有rating.dat、movies.dat、users.data三份数据集。ratings是6040位用户对3900部电影的评分数据(共计1000209)。

2.2 ratings.dat数据文件
rating.dat文件存放的是用户对电影的评分信息,该文件中每条记录形式:
UserID::MovieID::Rating::Timestamp,即用户id、电影id、该用户对此电影的评分、时间戳。
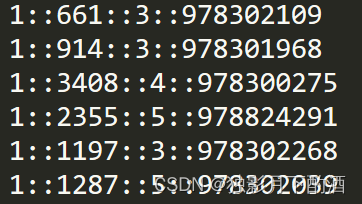
- - 用户id:从1~6040, 代表了6040个MovieLens用户
- - 电影id: 从1~3952, 代表了3952部电影
- - rating: 从1-5的整数, 代表了用户对电影的评级,最高5颗星,不允许半颗星存在
- - Timestamp:以秒为单位的时间戳
注意: 每个用户至少会对20部电影进行评级。
2.3 users.dat数据文件
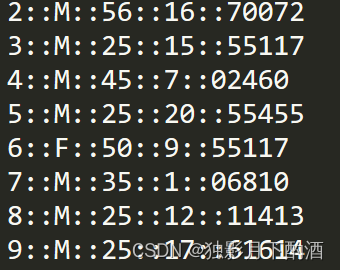
users.dat文件存放的是用户的相关信息,包括性别、年龄、职业,该文件中每条记录形式:
UserID::Gender::Age::Occupation::Zip-code,即用户id、性别、年龄、职业、Zip编码
-
-用户id:从1~6040, 代表了6040个MovieLens用户
-
- 性别(gender):M代表男性,F代表女性
-
-年龄(Age)分成了7组
* 1: "Under 18" * 18: "18-24" * 25: "25-34" * 35: "35-44" * 45: "45-49" * 50: "50-55" * 56: "56+" -
- 职业(occupation)分成了21种类别
* 0: "other" or not specified * 1: "academic/educator" * 2: "artist" * 3: "clerical/admin" * 4: "college/grad student" * 5: "customer service" * 6: "doctor/health care" * 7: "executive/managerial" * 8: "farmer" * 9: "homemaker" * 10: "K-12 student" * 11: "lawyer" * 12: "programmer" * 13: "retired" * 14: "sales/marketing" * 15: "scientist" * 16: "self-employed" * 17: "technician/engineer" * 18: "tradesman/craftsman" * 19: "unemployed" * 20: "writer"- Zip-code:邮政编码
2.4 movies.dat数据文件
movies.dat文件存放的是电影的相关信息,该文件中每条记录形式:
MovieID::Title::Genres ,即电影id、电影标题、电影类型

-
-MovieID :从1到3952,代表了3952部电影
-
-Title :电影名称,由IMDB提供,包括了发行年份
-
-Genres :电影题材由竖线分开, 包括动作喜剧等18种电影类型
* Action * Adventure * Animation * Children's * Comedy * Crime * Documentary * Drama * Fantasy * Film-Noir * Horror * Musical * Mystery * Romance * Sci-Fi * Thriller * War * Western
3.数据处理
3.1 转化DataFrame对象
通过pandas.read_csv将各表转化为pandas 的DataFrame对象。
engine参数有C和Python,C引擎速度更快,而Python引擎目前功能更完整。
# 用户基本信息
unames = ['user_id', 'gender', 'age', 'occupation', 'zip']
user_df = pd.read_csv('./ml-1m/users.dat',
sep='::',
header=None,
names=unames,
engine='python')
# 电影信息
mnames = ['movie_id', 'title', 'genres']
movies_df = pd.read_csv('./ml-1m/movies.dat',
sep='::',
header=None,
names=mnames,
engine='python',
encoding='ISO-8859-1')
# 评分信息
rnames = ['user_id', 'movie_id', 'imdbId', 'timestamp']
ratings_df = pd.read_csv('./ml-1m/ratings.dat',
sep='::',
header=None,
engine='python',
names=rnames)

3.2 查看数据集基本信息
通过dataframe.info()方法查看不同数据集的基本信息
========users_info===================
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 6040 entries, 0 to 6039
Data columns (total 5 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 user_id 6040 non-null int64
1 gender 6040 non-null object
2 age 6040 non-null int64
3 occupation 6040 non-null int64
4 zip 6040 non-null object
dtypes: int64(3), object(2)
memory usage: 236.1+ KB
None
======movies_info=================
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 3883 entries, 0 to 3882
Data columns (total 3 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 movie_id 3883 non-null int64
1 title 3883 non-null object
2 genres 3883 non-null object
dtypes: int64(1), object(2)
memory usage: 91.1+ KB
None
======ratings_info=================
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 1000209 entries, 0 to 1000208
Data columns (total 4 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 user_id 1000209 non-null int64
1 movie_id 1000209 non-null int64
2 imdbId 1000209 non-null int64
3 timestamp 1000209 non-null int64
dtypes: int64(4)
memory usage: 30.5 MB
None
3.3 去掉 movies.dat数据文件 title中的年份
通过正则表达式去掉 title 中的年份
import re
patter = re.compile(r'^(.*)\((\d+)\)$')
title = {val:patter.match(val).group(1) for i,val in enumerate(set(movies_df['title']))}
movies_df['title'] = movies_df['title'].map(title)
movies_df.head()
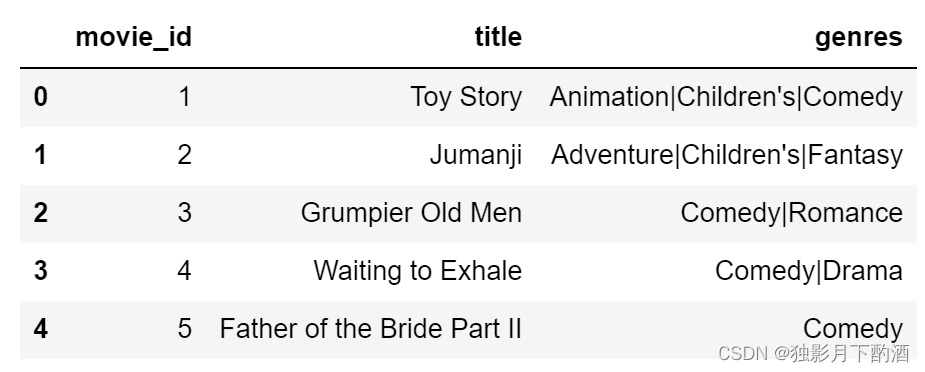
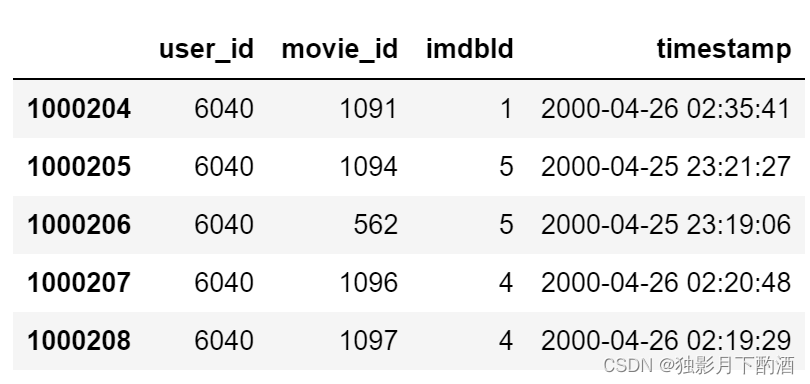
3.4 将ratings.dat文件中的时间戳转换为具体时间
通过 Pandas 中的 pd.to_datetime 函数将 timestamp 转换成具体时间
ratings_df['timestamp'] = pd.to_datetime(ratings_df['timestamp'],unit='s')
ratings_df.head()
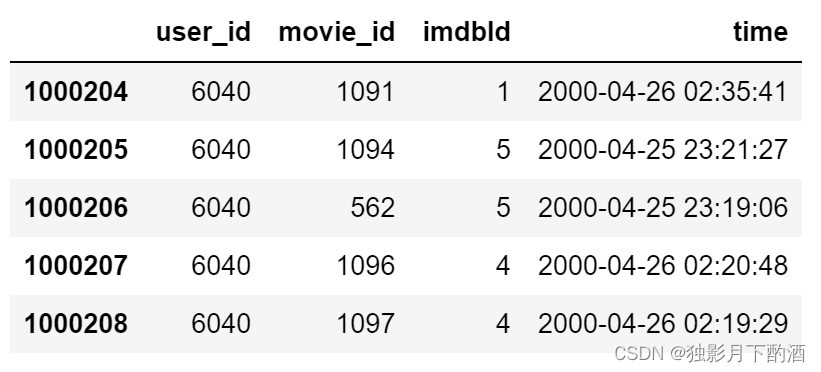
3.5 更改DataFrame列名
通过 pandas.DataFrame.rename 函数更改列名,具体代码如下:
ratings_df.rename(columns={'timestamp':'time'},inplace=True)
ratings_df.tail()
3.6 将时间格式变更为‘年-月-日’
- 1.使用 Pandas 中的 to_datetime 函数将 date 列从 object 格式转化为 datetime 格式
-
- 通过 strftime(‘%Y%m%d’) 取出年月日,把这个函数用 apply lambda 应用到 ratings_df[‘timestamp’] 的这一列
import datetime
date_df = pd.DataFrame({'time':ratings_df['time']})
data_df['date']=pd.to_datetime(date_df['time'])
ratings_df = date_df['date'].apply(lambda x:x.strftime('%Y-%m-%d'))
ratingd_df.tail()

3.7 合并数据
pandas.merge 将所有数据都合并到一个表中。merge有四种连接方式(默认为inner)
DataFrame.merge(right, how='inner', on=None, left_on=None, right_on=None, left_index=False, right_index=False, sort=False, suffixes=('_x', '_y'), copy=None, indicator=False, validate=None)
- 内连接(inner),取交集
- 外连接(outer),取并集,并用NaN填充;
- 左连接(left),左侧DataFrame取全部,右侧DataFrame取部分;
- 右连接(right),右侧DataFrame取全部,左侧DataFrame取部分;
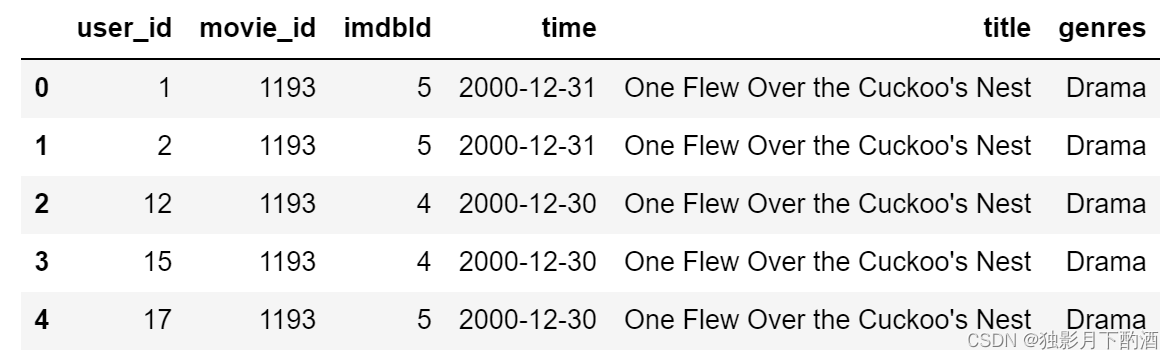
将movies_df与ratings_df合并成movies_rating_df数据集(两个数据集合并)
# 子数据合并
movies_ratings_df = pd.merge(ratings_df,movies_df,on='movie_id')
movies_ratings_df.head()
将movies_df、ratings_df与user_df合并成movies_rating_user_df数据集(多个数据集合并)
movies_ratings_user_df = pd.merge(pd.merge(ratings_df,movies_df),user_df)
movies_ratings_user_df.head()

4.数据分析
4.1 统计变量
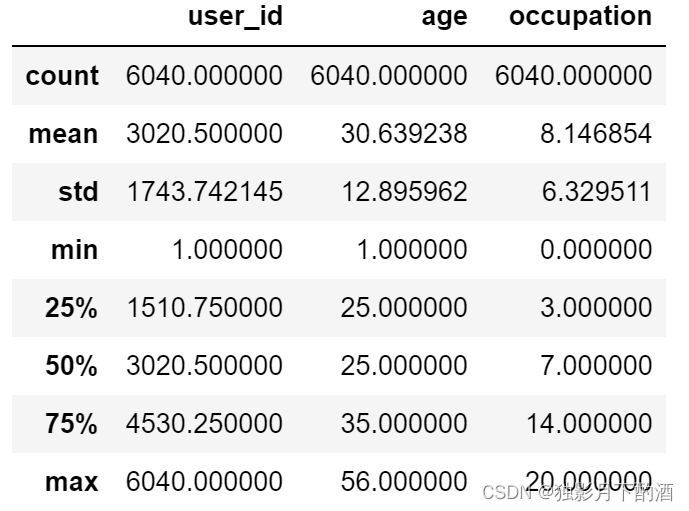
Pandas 中提供 describe 函数来统计变量,查看 user_df 的变量统计情况。
| 变量 | 描述 |
|---|---|
| count | 数量统计,此列有效值的数量 |
| std | 标准差 |
| min | 最小值 |
| 25% | 四分之一分位数 |
| 50% | 二分之一分位数 |
| 75% | 四分之三分位数 |
| max | 最大值 |
| mean | 均值 |
user_df.describe()
4.2 分组统计
Pandas 中使用 groupby 函数进行分组统计,groupby 分组实际上就是将原有的 DataFrame 按照 groupby 的字段进行划分,groupby 之后可以添加计数(count)、求和(sum)、求均值(mean)等操作。
DataFrame.groupby(by=None(分组标准), axis=0(行), level=None, as_index=True(对于聚合输出,返回具有组标签作为索引的对象), sort=True, group_keys=True, observed=False, dropna=True)
4.2.1 统计评分最多的5部电影
首先根据电影名称(title)进行分组,然后使用 size 函数计算每组样本的个数,最后采用降序的方式输出前 5 条观测值。
top_5_ratings_movies_df = movies_ratings_df.groupby('title').size().sort_values(ascending=False)[:5]
top_5_ratings_movies_df

4.2.2 统计电影评分的均值(按照用户分组)
# 按照用户id统计看过电影评分的均值
movie_ratings_by_user_mean_df= movies_ratings_df.groupby('user_id',as_index=False)['imdbId'].mean()
movie_ratings_by_user_mean_df.head()

movie_ratings_by_user_mean_df.info()
"""
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 6040 entries, 0 to 6039
Data columns (total 2 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 user_id 6040 non-null int64
1 imdbId 6040 non-null float64
dtypes: float64(1), int64(1)
memory usage: 94.5 KB
"""
4.2.3 统计每部电影评分的均值(按照电影分组)
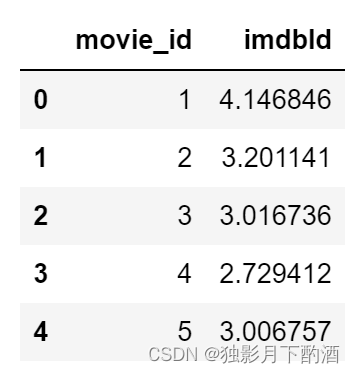
# 按照电影id统计每一部电影评分的均值
every_movie_ratings_mean_df= movies_ratings_df.groupby('movie_id',as_index=False)['imdbId'].mean()
every_movie_ratings_mean_df.head()
every_movie_ratings_mean_df.info()
"""
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 3706 entries, 0 to 3705
Data columns (total 2 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 movie_id 3706 non-null int64
1 imdbId 3706 non-null float64
dtypes: float64(1), int64(1)
memory usage: 58.0 KB
"""
4.2.4 分组聚合统计
Pandas 提供 aggregate 函数实现聚合操作,可简写为 agg,可以与 groupby 一起使用,作用是将分组后的对象使给定的计算方法重新取值,支持按照字段分别给定不同的统计方法。
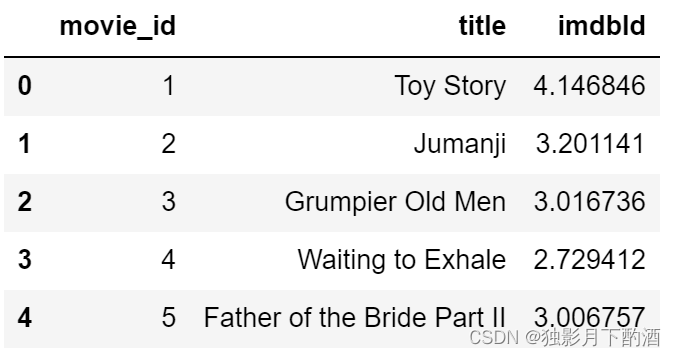
按照 movie_id 和 title 进行分组,并计算评分均值,取前 5 个数据。
# 按照 movie_id 和 title 进行分组,并计算评分均值,取前 5 个数据。
import numpy as np
movies_ratings_by_movie_title_df = movies_ratings_df.groupby(['movie_id','title'],as_index=False)['imdbId'].aggregate(np.mean)
movies_ratings_by_movie_title_df.head()
4.2.5 统计每部电影评分的均值(按照性别)
数据透视表 pivot_table 是一种类似 groupby 的操作方法,常见于 EXCEL 中,数据透视表按列输入数据,输出时,不断细分数据形成多个维度累计信息的二维数据表。
DataFrame.pivot_table(values=None, index=None, columns=None, aggfunc='mean', fill_value=None, margins=False, dropna=True, margins_name='All', observed=False, sort=True)
- values : 对目标数据进行筛选,默认是全部数据,可通过 values 参数设置我们想要展示的数据列。
- index : 行索引,必要参数
- columns :透视表的列索引,非必要参数,同 index 使用方式一样
- aggfunc :对数据聚合时进行的函数操作,默认是求平均值,也可以 sum、count 等
- fill_value : 对于空值进行填充
- margins :额外列,默认对行列求和
- dropna : 默认开启去重
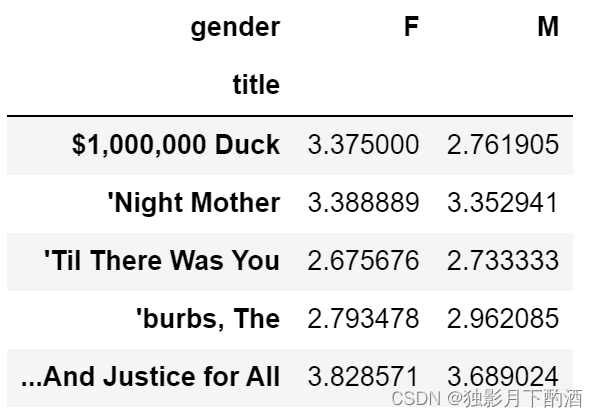
# 根据性别获取相同电影的评分均值
mean_rating = movies_ratings_user_df.pivot_table('imdbId',index='title',columns='gender',aggfunc='mean')
mean_rating.head()
5.总结
- 1M数据集有rating.dat、movies.dat、users.data三份数据集。ratings是6040位用户对3900部电影的评分数据(共计1000209)
- rating.dat文件存放的是用户对电影的评分信息,UserID::MovieID::Rating::Timestamp
- users.dat文件存放的是用户的相关信息,UserID::Gender::Age::Occupation::Zip-code
- movies.dat文件存放的是电影的相关信息,MovieID::Title::Genres
本文仅仅作为个人学习记录,不作为商业用途,谢谢理解。
参考:
1.https://cloud.tencent.com/developer/article/1474293
2.https://www.jianshu.com/p/a59ff0dc22a3