排序的方式
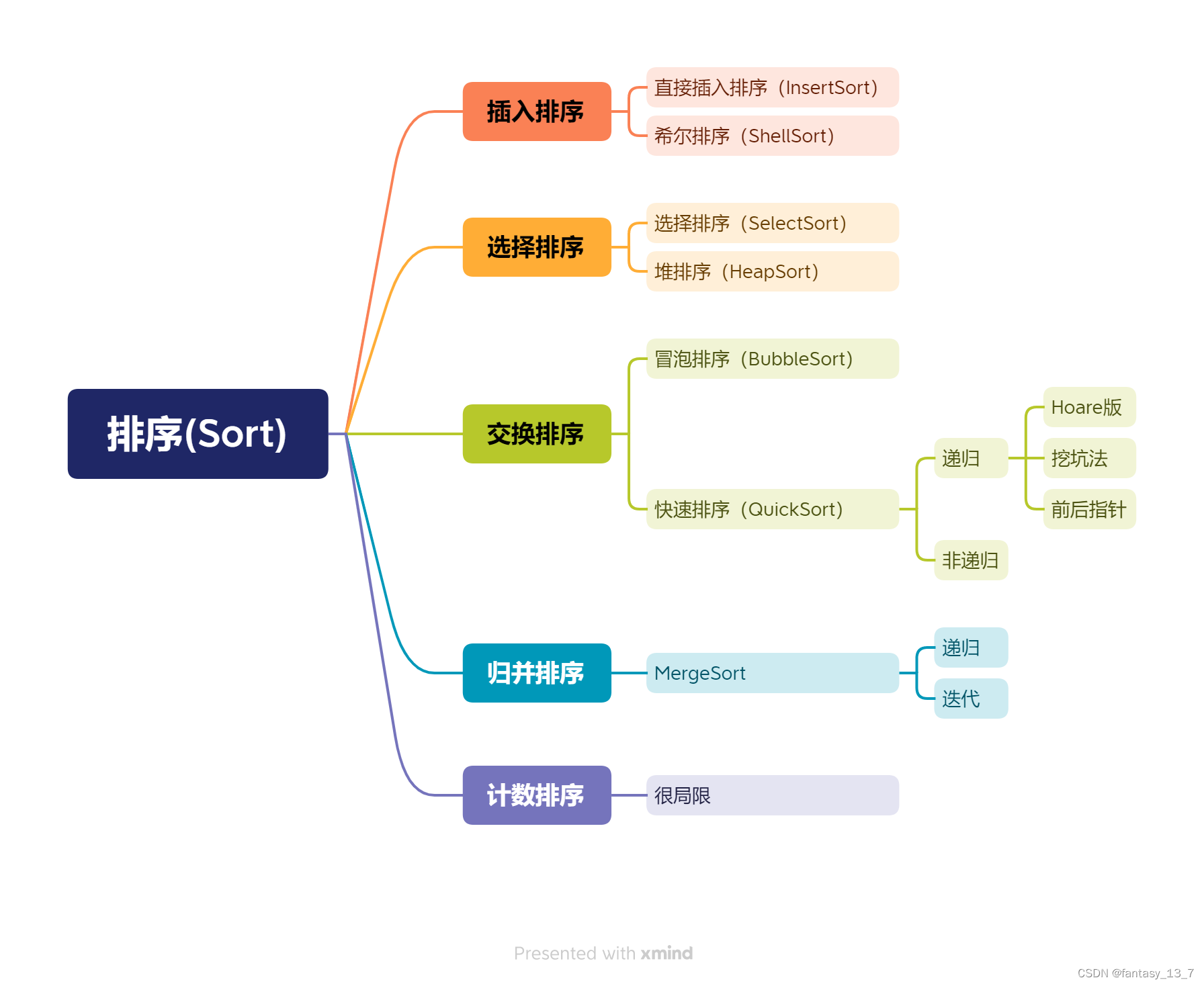
排序的稳定性
-
什么是排序的稳定性?
不改变相同数据的相对顺序 -
排序的稳定性有什么意义?
- 假定一个场景:
一组成绩:100,88,98,98,78,100(按交卷顺序排列,先交在前)
先需要对这组数据按降序排列,如果分数相同,先交卷的排在前面。
- 假定一个场景:
在以上这种场景下,选择具有稳定性的排序方式就很有必要。
排序方式分析比较汇总
| 排序方式 | 时间复杂度 | 空间复杂度 | 稳定性 |
|---|---|---|---|
| Insert | O(N2) | O(1) | √ |
| Shell | O(N1.3) | O(1) | ×(预排序相同数可能分到不同组) |
| Select | O(N2) | O(1) | ×(9,9,4,4)(swap(4,9)后4和4的相对顺序改变) |
| Heap | O(N*logN) | O(1) | × |
| Bubble | O(N2) | O(1) | √ |
| Quick | O(N*logN)(大量重复数据:N2) | O(logN)(递归调用栈帧) | ×(最后相遇那下交换会打乱) |
| Merge | O(N*logN) | O(N+ | √ |
| Count | O(N+range) | O(range) | × |
912.排序数组 - 力扣(LeetCode)
👉题目链接
/**
* Note: The returned array must be malloced, assume caller calls free().
*/
//栈
// 支持动态增长的栈
typedef int STDataType;
typedef struct Stack
{
STDataType* _a;
int _top; // 栈顶
int _capacity; // 容量
}Stack;
// 初始化栈
void StackInit(Stack* ps)
{
STDataType* tmp = (STDataType*)malloc(4 * sizeof(STDataType));
if (!tmp)
{
perror("malloc fail");
exit(-1);
}
ps->_a = tmp;
ps->_top = 0;
ps->_capacity = 4;
}
// 入栈
void StackPush(Stack* ps, STDataType data)
{
assert(ps);
if (ps->_capacity == ps->_top)
{
STDataType* tmp = (STDataType*)realloc(ps->_a, 2 * ps->_capacity * sizeof(STDataType));
if (!tmp)
{
perror("realloc fail");
exit(-1);
}
ps->_a = tmp;
ps->_capacity *= 2;
}
ps->_a[ps->_top] = data;
ps->_top++;
}
// 出栈
void StackPop(Stack* ps)
{
assert(ps);
assert(!StackEmpty(ps));
assert(ps->_top);
ps->_top--;
}
// 获取栈顶元素
STDataType StackTop(Stack* ps)
{
assert(ps);
assert(ps->_top);
return ps->_a[ps->_top - 1];
}
// 获取栈中有效元素个数
int StackSize(Stack* ps)
{
assert(ps);
return ps->_top;
}
// 检测栈是否为空,如果为空返回非零结果,如果不为空返回0
int StackEmpty(Stack* ps)
{
assert(ps);
return ps->_top == 0;
}
// 销毁栈
void StackDestroy(Stack* ps)
{
assert(ps);
free(ps->_a);
ps->_capacity = ps->_top = 0;
ps->_a = NULL;
}
//插入排序
void InsertSort(int* a, int n)
{
assert(a);
for (int i = 1; i < n; i++)
{
int tmp = a[i];
int end = i - 1;
while (end >= 0)
{
if (a[end] <= tmp)
{
break;
}
//a[end + 1] = a[end--];???为什么错误
a[end + 1] = a[end];
end--;
}
a[end + 1] = tmp;
}
}
// 希尔排序
void ShellSort(int* a, int n)
{
assert(a);
int gap = n / 2;
while (gap)
{
for (int i = 1; i < n; i++)
{
int tmp = a[i];
int end = i - gap;
while (end >= 0)
{
if (a[end] <= tmp)
{
break;
}
a[end + gap] = a[end];
end -= gap;
}
a[end + gap] = tmp;
}
gap /= 2;
}
}
void Swap(int* x, int* y)
{
assert(x && y);
int tmp = *x;
*x = *y;
*y = tmp;
}
// 选择排序
void SelectSort(int* a, int n)
{
assert(a);
int begin = 0, end = n - 1;
while (begin < end)
{
int mini = begin, maxi = end;
//[begin+1,end-1]
for (int j = begin; j <= end; j++)
{
if (a[j] < a[mini])
mini = j;
if (a[j] > a[maxi])
maxi = j;
}
//swap之前 min==a[mini] max==a[maxi]
Swap(&a[begin], &a[mini]);
//swap之后:begin → min ; mini → original-a[begin]
//if(original-a[begin] → max)则会影响 a[maxi] =? max
if (begin == maxi)//如果原本begin指向的数是max,则swap之后这个数已经被交换到了mini所指向的位置
maxi = mini;
Swap(&a[end], &a[maxi]);
++begin;
--end;
}
}
// 堆排序
void AdjustDwon(int* a, int n, int root)
{
assert(a);
int parent = root;
int child = parent * 2 + 1;
while (child < n)
{
if ((child + 1) < n && a[child + 1] > a[child])
++child;
if (a[parent] < a[child])
Swap(&a[parent], &a[child]);
else
break;
parent = child;
child = parent * 2 + 1;
}
}
void HeapSort(int* a, int n)
{
assert(a);
//建大堆
for (int parent = (n - 1 - 1) / 2; parent >= 0; parent--)
{
AdjustDwon(a, n, parent);
}
int end = n - 1;
while (end)
{
Swap(&a[0], &a[end]);
AdjustDwon(a, end, 0);
end--;
}
}
// 冒泡排序
void BubbleSort(int* a, int n)
{
assert(a);
for (int j = 0; j < n; j++)
{
for (int i = 0; i < n - j - 1; i++)
{
if (a[i] > a[i + 1])
Swap(&a[i], &a[i + 1]);
}
}
}
// 快速排序递归实现
// 三数取中
int GetMidIndex(int* a, int left, int right)
{
int begin = left, end = right;
int middle = (left + right) / 2;
if (a[begin] < a[end])
{
if (a[middle] < a[begin])
return begin;
else if (a[middle] > a[end])
return end;
else
return middle;
}
else
{
if (a[middle] < a[end])
return end;
else if (a[middle] > a[begin])
return begin;
else
return middle;
}
}
// 快速排序hoare版本
int hoareSort1(int* a, int left, int right)
{
assert(a);
if (left >= right)
return;
// if ((right - left + 1) < 5)
// {
// InsertSort(a + left, right - left + 1);
// }
else
{
int key = left, begin = left, end = right;
int mid = GetMidIndex(a, left, right);
Swap(&a[mid], &a[key]);
while (left < right)
{
while (left < right && a[right] >= a[key])
{
--right;
}
while (left < right && a[left] <= a[key])
{
++left;
}
Swap(&a[left], &a[right]);
}
Swap(&a[key], &a[right]);//left==right
//[begin,left-1] [right+1,end]
hoareSort1(a, begin, left - 1);
hoareSort1(a, right + 1, end);
}
return right;
}
// 快速排序挖坑法
int HoleSort2(int* a, int left, int right)
{
if (left >= right)
return;
int key = a[left];
int hole = left, begin = left, end = right;
while (left < right)
{
while (left < right && a[right] >= key)
{
--right;
}
a[hole] = a[right];
hole = right;
while (left < right && a[left] <= key)
{
++left;
}
a[hole] = a[left];
hole = left;
}
a[right] = key;
//[begin,left-1] [right+1,end]
HoleSort2(a, begin, left - 1);
HoleSort2(a, right + 1, end);
return right;
}
// 快速排序前后指针法
int PointSort3(int* a, int left, int right)
{
assert(a);
if (left >= right)
return;
int keyi = left;
int prev = left, cur = left;
while (cur <= right)
{
if (a[cur] < a[keyi] && cur != prev)
Swap(&a[++prev], &a[cur]);
++cur;
}
Swap(&a[keyi], &a[prev]);
//[left,prev-1][prev+1,right]
PointSort3(a, left, prev - 1);
PointSort3(a, prev + 1, right);
return prev;
}
// 快速排序 非递归实现
void QuickSort(int* a, int left, int right)
{
assert(a);
Stack st;
StackInit(&st);
StackPush(&st, left);
StackPush(&st, right);
while (!StackEmpty(&st))
{
int end = StackTop(&st);
StackPop(&st);
int begin = StackTop(&st);
StackPop(&st);
int keyi = hoareSort1(a, begin, end);
//[begin,keyi-1] keyi [keyi+1,end]
if (keyi + 1 < end)
{
StackPush(&st, keyi + 1);
StackPush(&st, end);
}
if (begin < keyi - 1)
{
StackPush(&st, begin);
StackPush(&st, keyi - 1);
}
}
StackDestroy(&st);
}
// 归并排序递归实现
void _MergeSort(int* a, int left, int right, int* tmp)
{
assert(a && tmp);
if (left == right)
return;
int middle = (left + right) / 2;
//[left, middle] [middle+1,right]
//[begin1,end1] [begin2,end2]
int begin1 = left, end1 = middle, begin2 = middle + 1, end2 = right;
//递归分解
_MergeSort(a, begin1, end1, tmp);
_MergeSort(a, begin2, end2, tmp);
//merge
int i = begin1;
while (begin1 <= end1 && begin2 <= end2)
{
if (a[begin1] <= a[begin2])
{
tmp[i++] = a[begin1++];
}
else
{
tmp[i++] = a[begin2++];
}
}
while (begin1 <= end1)
{
tmp[i++] = a[begin1++];
}
while (begin2 <= end2)
{
tmp[i++] = a[begin2++];
}
memcpy(a + left, tmp + left, sizeof(int) * (right - left + 1));
}
void MergeSort(int* a, int n)
{
assert(a);
int* tmp = (int*)malloc(sizeof(int) * n);
if (!tmp)
{
perror("malloc fail");
exit(-1);
}
_MergeSort(a, 0, n - 1, tmp);
free(tmp);
tmp = NULL;
}
// 归并排序非递归实现
void MergeSortNonR(int* a, int n)
{
assert(a);
int* tmp = (int*)malloc(sizeof(int) * n);
if (!tmp)
{
perror("malloc fail");
exit(-1);
}
int range = 1;
while (range < n)
{
for (int i = 0; i < n; i += 2 * range)
{
int begin1 = i, end1 = i + range - 1;
int begin2 = i + range, end2 = i + 2 * range - 1;
int j = begin1;
//越界
//end1越界
if (end1 >= n)
{
end1 = n - 1;
begin2 = end2 + 1;//begin2 > end2;
}
else if (begin2 == n)
{
begin2 = end2 + 1;//begin2 > end2;
}
else if (end2 >= n)
{
end2 = n - 1;
}
//merge
while (begin1 <= end1 && begin2 <= end2)
{
if (a[begin1] <= a[begin2])
{
tmp[j++] = a[begin1++];
}
else
{
tmp[j++] = a[begin2++];
}
}
while (begin1 <= end1)
{
tmp[j++] = a[begin1++];
}
while (begin2 <= end2)
{
tmp[j++] = a[begin2++];
}
}
memcpy(a, tmp, sizeof(int)*n);
range *= 2;
}
free(tmp);
tmp = NULL;
}
// 计数排序
void CountSort(int* a, int n)
{
assert(a);
int min = a[0], max = a[0];
for (size_t i = 0; i < n; i++)
{
if (a[i] > max)
max = a[i];
if (a[i] < min)
min = a[i];
}
int size = max - min + 1;
int* tmp = (int*)calloc(size, sizeof(int));
if (!tmp)
{
perror("calloc fail");
exit(-1);
}
//计数
for (size_t i = 0; i < n; i++)
{
++tmp[*(a + i) - min];
}
int j = 0;
for (size_t i = 0; i < size; i++)
{
while (tmp[i]--)
{
a[j++] = i + min;
}
}
free(tmp);
tmp = NULL;
}
int* sortArray(int* nums, int numsSize, int* returnSize){
*returnSize=numsSize;
//InsertSort(nums,numsSize);//超出时间限制
//ShellSort(nums,numsSize);
//SelectSort(nums,numsSize);//超出时间限制
//HeapSort(nums,numsSize);
//BubbleSort(nums,numsSize);//超出时间限制
//hoareSort1(nums,0,numsSize-1);//对于大量重复数据,超出时间限制
//HoleSort2(nums,0,numsSize-1);//超出时间限制
//PointSort3(nums,0,numsSize-1);//对于大量有序数据,超出时间限制
//QuickSort(nums,0,numsSize-1);//对于大量重复数据,超出时间限制
//MergeSort(nums,numsSize);
//MergeSortNonR(nums,numsSize);
//CountSort(nums,numsSize);
return nums;
}







![Java[集合] Map 和 Set](https://img-blog.csdnimg.cn/img_convert/afe7b802905647c8b277717aadc5b76a.jpeg)



