表详情:
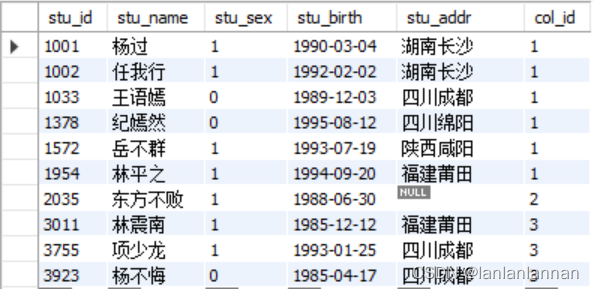
学生表:
学院表:

学生选课记录表:

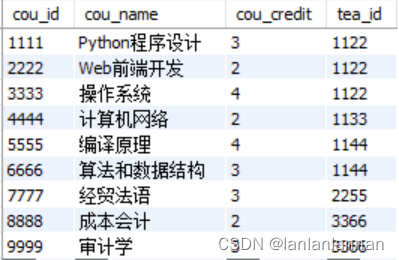
课程表:
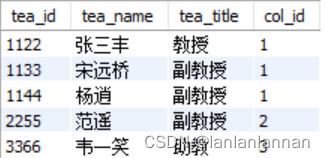
教师表:
查询:
1. 查全表
-- 01. 查询所有学生的所有信息
-- 方法一:会更复杂,进行了两次查询,第一次查询这个表的列,第二次根据查到的列再查每列的数据
select * from teachers;
-- 方法二:直接查询该实体所有属性
select stu_id
, stu_name
, stu_sex
, stu_birth
, stu_addr
, col_id
from students;
2. 投影(select)和别名(alias / as)
-- 02. 查询学生的学号、姓名和籍贯(投影和别名) - 别名:alias
select stu_id as 学号
, stu_name as 姓名
, stu_addr as 籍贯
from students;
-- 03. 查询所有课程的名称及学分(投影和别名)
select cou_name as 名称
, cou_credit as 学分
from courses;
3. 数据筛选(where 加 and / or 加 分支 加 比较符)
-- 04. 查询所有女学生的姓名和出生日期(数据筛选)
select stu_name
, stu_birth
from students
where stu_sex = 0;
-- 05. 查询籍贯为“四川成都”的女学生的姓名和出生日期(数据筛选)
select stu_name
, stu_birth
from students
where stu_sex = 0 and stu_addr = '四川成都';
-- 06. 查询籍贯为“四川成都”或者性别是女的学生(数据筛选)
select stu_name
, stu_birth
from students
where stu_sex = 0 or stu_addr = '四川成都';
-- 07. 查询所有80后学生的姓名、性别和出生日期(数据筛选)
select stu_name
, stu_sex
, stu_birth
from students
where stu_birth >= '1980-1-1' and stu_birth <= '1989-12-31';
select stu_name
, stu_sex
, stu_birth
from students
where stu_birth between '1980-1-1' and '1989-12-31';
-- 将01改为男女
-- MySQL方言
select stu_name as 姓名
, if(stu_sex,'男','女') as 性别
, stu_birth as 出生日期
from students
where stu_birth between '1980-1-1' and '1989-12-31';
-- 标准SQL
select stu_name as 姓名
, case stu_sex when 1 then '男' when 0 then '女' else '未知' end as 性别
from students
where stu_birth between '1980-1-1' and '1989-12-31';
-- 08. 查询学分大于2分的课程名称和学分(数据筛选)
select cou_name
, cou_credit
from courses
where cou_credit > 2;
-- 09. 查询学分是奇数的课程的名称和学分(数据筛选)
select cou_name
, cou_credit
from courses
where cou_credit%2 <> 0;
-- 10. 查询选择选了1111的课程考试成绩在90分以上的学生学号(数据筛选)
select stu_id
from records
where cou_id = 1111 and score > 90;
-- 11. 查询名字叫“杨过”的学生的姓名和性别
select stu_name
, stu_sex
from students
where stu_name = '杨过';
4.模糊查询(通配符和正则)
-- 12. 查询姓“杨”的学生姓名和性别(模糊查询)
-- wild card - 通配符 - % - 零个或任意多个字符
select stu_name
, stu_sex
from students
where stu_name like '杨%';
-- 13. 查询姓“杨”名字两个字的学生姓名和性别(模糊查询)
-- wild card - 通配符 - _ - 精确匹配一个字符
select stu_name
, stu_sex
from students
where stu_name like '杨_';
-- 14. 查询姓“杨”名字三个字的学生姓名和性别(模糊查询)
select stu_name
, stu_sex
from students
where stu_name like '杨__';
-- 15. 查询名字中有“不”字或“嫣”字的学生的姓名(模糊查询)
select stu_name
from students
where stu_name like '%不%' or stu_name like '%嫣%';
select stu_name
from students
where stu_name regexp '[\\u4e00-\\u9fa5]*?[不嫣][\\u4e00-\\u9fa5]*?';
select stu_name
from students
where stu_name like '%不%'
union
select stu_name
from students
where stu_name like '%嫣%';
-- 16. 查询姓“杨”或姓“林”名字三个字的学生的姓名(正则表达式模糊查询)
select stu_name
from students
where stu_name regexp '[杨林][\\u4e00-\\u9fa5]{2}';
5. 空值和去重(三值逻辑和trim)
-- 17. 查询没有录入籍贯的学生姓名(空值处理)
-- 三值逻辑 - true / false / unknown
select stu_name
from students
where stu_addr is null;
-- 如果遇到空字符串
-- trim - 修剪字符串左右两端指定的字符(默认修建空格)
update students set stu_addr = ' ' where stu_id = 3011;
select stu_name
from students
where stu_addr is null or trim(stu_addr) = '';
-- 18. 查询录入了籍贯的学生姓名(空值处理)
select stu_name
from students
where stu_addr is not null and trim(both ' ' from stu_addr) <> '';
-- 19. 查询学生选课的所有日期(去重)
select distinct sel_date
from records ;
-- 20. 查询学生的籍贯(空值处理和去重)
select distinct stu_addr
from students
where stu_addr is not null and trim(stu_addr) <> '';
6. 排序
-- 21. 查询男学生的姓名和生日按年龄从大到小排列(排序)
-- 排序 asc (默认)升序 desc 降序
select stu_name
, stu_birth
from students
where stu_sex = 1
order by stu_birth asc, stu_id desc;
7. 日期函数和数值函数
-- 查询现在的日期时间
-- select current_timestamp(); 2023-04-12 09:15:58
-- select now(); 2023-04-12 09:14:16
-- select curdate(); 2023-04-12
-- select curtime(); 09:15:24
-- 日期差
-- datediff(大日期,小日期) 两个日期相差的天数
-- timestampdiff(单位,小日期,大日期)
-- 22. 将上面查询中的生日换算成年龄(日期函数、数值函数)
select stu_name as 姓名
, datediff(curdate(),stu_birth) div 365 as 年龄
from students
where stu_sex = 1
order by stu_birth asc;
select stu_name as 姓名
, timestampdiff(year,stu_birth,curdate()) as 年龄
from students
where stu_sex = 1
order by stu_birth desc;
8. 聚合函数(最大/方差/平均…coalesce)
-- 有多条数据 最后只给出一条数据
-- 规约 reduce / aggregate 聚合
-- python中的规约: filter / map / reduce (max/min/sum/avg/count)
总体方差:
σ
2
=
1
N
∑
i
=
1
N
(
x
i
−
μ
)
2
\sigma^{2} = \frac{1}{N} \sum_{i=1}^{N} (x_{i} - \mu)^{2}
σ2=N1i=1∑N(xi−μ)2
总体标准差:
σ
=
1
N
∑
i
=
1
N
(
x
i
−
μ
)
2
\sigma = \sqrt{\frac{1}{N} \sum_{i=1}^{N} (x_{i} - \mu)^{2}}
σ=N1i=1∑N(xi−μ)2
样本方差:
s
2
=
1
n
−
1
∑
i
=
1
n
(
x
i
−
x
ˉ
)
2
s^{2} = \frac{1}{n - 1} \sum_{i=1}^{n} (x_{i} - \bar{x})^{2}
s2=n−11i=1∑n(xi−xˉ)2
样本标准差:
s
=
1
n
−
1
∑
i
=
1
n
(
x
i
−
x
ˉ
)
2
s = \sqrt{\frac{1}{n - 1} \sum_{i=1}^{n} (x_{i} - \bar{x})^{2}}
s=n−11i=1∑n(xi−xˉ)2
markdown写数学公式:
https://www.zybuluo.com/codeep/note/163962
-- SQL聚合函数:
-- max / min / avg / sum / count
-- stddev_pop(总体标准差)
-- stddev_samp(样本标准差)
-- var_pop(总体方差)
-- var_samp(样本方差)
-- 23. 查询年龄最大的学生的出生日期(聚合函数)
select min(stu_birth)
from students;
-- 24. 查询年龄最小的学生的出生日期(聚合函数)
select max(stu_birth)
from students;
-- 25. 查询编号为1111的课程考试成绩的最高分(聚合函数)
select max(score)
from records
where cou_id = 1111;
-- 26. 查询学号为1001的学生考试成绩的最低分(聚合函数)
select min(score)
from records
where cou_id = 1111;
-- 27. 查询学号为1001的学生考试成绩的平均分和标准差(聚合函数)
select avg(score)
, stddev_pop(score)
, var_pop(score)
from records
where stu_id = 1001;
-- 28. 查询学号为1001的学生考试成绩的平均分,如果有null值,null值算0分(聚合函数)
-- ifnull 是MySQL的方言
select avg(ifnull(score,0))
from records
where stu_id = 1001;
-- 标准SQL的函数 coalesce(值1,值2,值3,...) 返回第一个非空的值
select avg(coalesce(score,0))
from records
where stu_id = 1001;
-- count(*) 返回所有的行数
select sum(score) / count(*)
from records
where stu_id = 1001;
9. 分组和聚合函数(having/rollup/取整)
-- 29. 查询男女学生的人数(分组和聚合函数)
select case stu_sex when 1 then '男' else '女' end as 性别
, count(*) as 人数
from students
group by stu_sex;
-- 30. 查询每个学院学生人数(分组和聚合函数)
-- with rollup 总计 rollup维度上卷
select col_id as 学院
, count(*) as 学生人数
from students
group by col_id
with rollup;
-- 31. 查询每个学院男女学生人数(分组和聚合函数)
select col_id as 学院
, stu_sex as 性别
, count(*) as 学生人数
from students
group by col_id, stu_sex
with rollup;
-- 32. 查询选课学生的学号和平均成绩(分组和聚合函数)
-- round() 保留几位小数, ceil向大取整, floor向小取整
select stu_id
, round(avg(score),1)
, ceil(avg(score))
, floor(avg(score))
from records
group by stu_id;
-- 33. 查询平均成绩大于等于90分的学生的学号和平均成绩(分组和聚合函数)
-- 分组之前的筛选数据用where子句;分组之后的筛选数据用having子句
select stu_id
, round(avg(score),1)
from records
group by stu_id
having avg(score) >= 90;
-- 34. 查询所有课程成绩大于80分的同学的学号(分组和聚合函数)
select stu_id
from records
group by stu_id
having min(score) > 80;
10. 嵌套查询(定义变量/any/all)
-- 35. 查询年龄最大的学生的姓名(嵌套查询)
-- 嵌套查询:把一个查询结果作为另外一个查询的一部分来使用,也称为子查询。
select min(stu_birth)
from students;
select stu_name
from students
where stu_birth = '1985-04-17';
-- 定义变量:
-- 赋值方法1:用户自定义变量前面要有@,给变量赋值前面要加set
set @min_birth = (select min(stu_birth) from students);
-- 赋值方法2:海象运算符
select @min_birth := (select min(stu_birth) from students);
select stu_name
from students
where stu_birth = @min_birth;
-- 一步到位
select stu_name
from students
where stu_birth = (select min(stu_birth)
from students);
-- 36. 查询选了两门以上的课程的学生姓名(嵌套查询/分组/数据筛选)
-- 符合要求的学号
select stu_id
from records
group by stu_id
having count(score) > 2;
-- 通过学号查名字
select stu_name
from students
where stu_id in (select stu_id
from records
group by stu_id
having count(*) > 2);
-- any 用any后的任意一个值和前面做对比
-- all 前面和后面的所有相等
select stu_name
from students
where stu_id = any (select stu_id
from records
group by stu_id
having count(*) > 2);
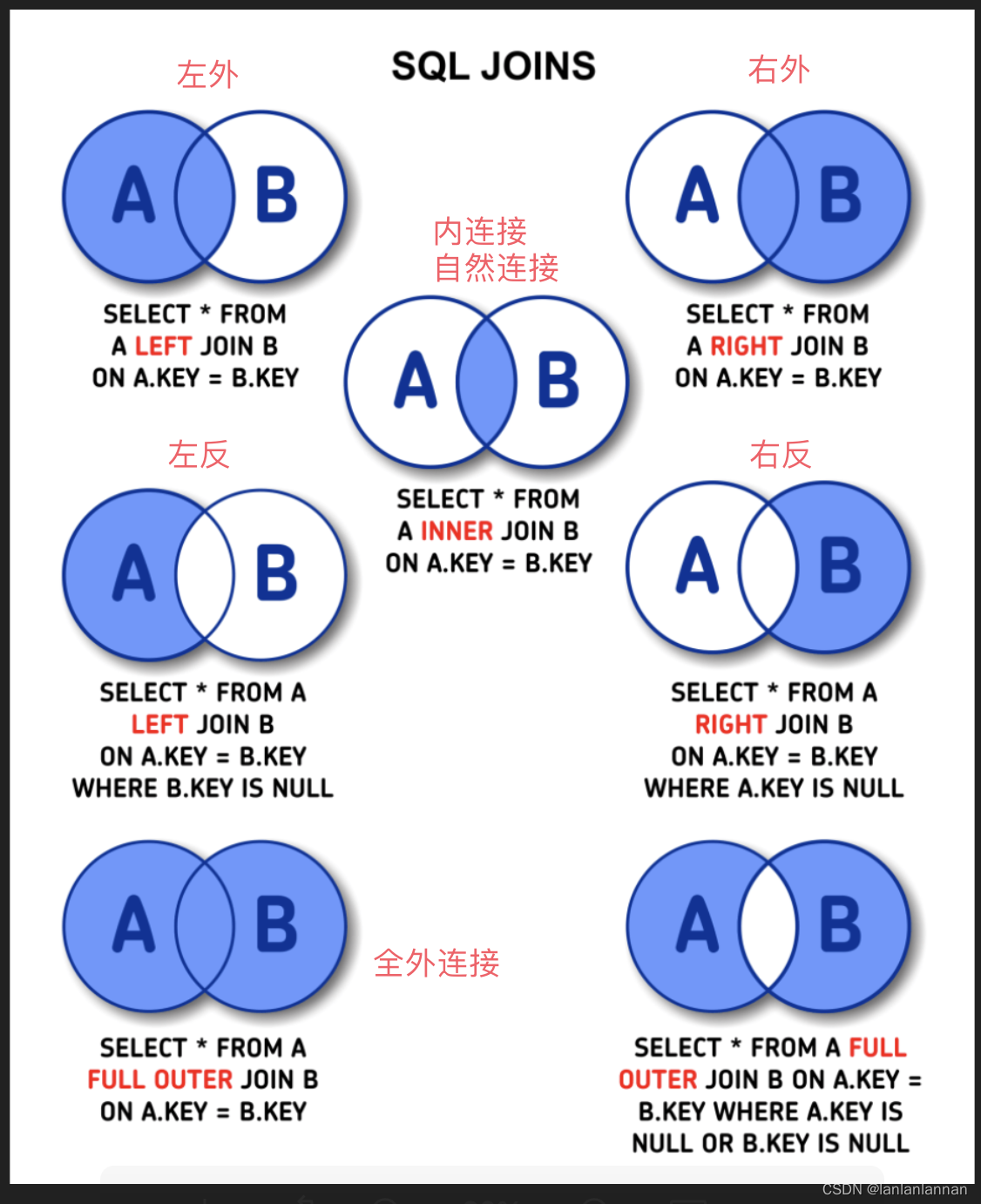
11. 连接查询(交叉连接/内连接/自然连接删除线格式 )
-- 37. 查询学生的姓名、生日和所在学院名称(连接查询)
-- from后面写多个表,是from后面表的笛卡尔积
-- 方法1:笛卡尔积
select stu_name
, stu_birth
, col_name
, students.col_id
, colleges.col_id
from students,colleges
where students.col_id = colleges.col_id;
-- 方法2:cross join交叉连接
select stu_name
, stu_birth
, col_name
, students.col_id
, colleges.col_id
from students cross join colleges
where students.col_id = colleges.col_id;
-- 方法3:内连接
select stu_name
, stu_birth
, col_name
from students inner join colleges
where students.col_id = colleges.col_id;
-- 方法4:自然连接
-- 自然连接会根据两张表的同名列进行匹配
-- 自然连接没有同名列,同名列都合成一个列了
select stu_name
, stu_birth
, col_name
from students natural join colleges;
-- 38. 查询学生姓名、课程名称以及成绩(连接查询)
-- 笛卡尔积
select stu_name
, cou_name
, score
from students, records, courses
where students.stu_id = records.stu_id and records.cou_id = courses.cou_id;
-- 自然连接
select stu_name
, cou_name
, score
from students natural join records natural join courses
where score is not null;
12. 分页查询
-- 39. 上面的查询结果按课程和成绩排序取前5条数据(分页查询)
-- limit和offset是方言
select stu_name
, cou_name
, score
from students natural join records natural join courses
where score is not null
order by cou_id asc, score desc
limit 5;
-- 40. 上面的查询结果按课程和成绩排序取第6-10条数据(分页查询)
select stu_name
, cou_name
, score
from students natural join records natural join courses
where score is not null
order by cou_id asc, score desc
limit 5
offset 5;
-- 41. 上面的查询结果按课程和成绩排序取第11-15条数据(分页查询)
select stu_name
, cou_name
, score
from students natural join records natural join courses
where score is not null
order by cou_id asc, score desc
limit 5
offset 10;
13. 嵌套和连接查询
-- 42. 查询选课学生的姓名和平均成绩(嵌套查询和连接查询)
select stu_name
, avg_score
from students
natural join (select stu_id
, round(avg(score),1) as avg_score
from records
group by stu_id) as temp;
-- 43. 查询学生的姓名和选课的数量(嵌套查询和连接查询)
select stu_name
, total1
, total2
from students
natural join (select stu_id
, count(*) as total1
, count(score) as total2
from records
group by stu_id) as temp;
14. 外连接
-- 外连接
-- 左外连接(left outer join / left join):左表(写到join左边的表)取到所有的数据,不满足连表条件的地方填空值。
-- 右外连接(right outer join / right join):右表(写到join右边的表)取到所有的数据,不满足连表条件的地方填空值。
-- 全外连接(full outer join / full join):左右两张表都要取到所有的数据,不满足连表条件的地方填空值。(MySQL不支持)
-- 可以通过左外连接union右外连接
-- 44. 查询每个学生的姓名和选课数量(左外连接和嵌套查询)
-- 选课表里没有她们的数据 自然连接和内连接不好用
select stu_name
, total1
, total2
from students
left join (select stu_id
, count(*) as total1
, count(score) as total2
from records
group by stu_id) as temp
on students.stu_id = temp.stu_id;
-- 45. 查询没有选课的学生的姓名(左外连接和数据筛选)
-- 查是哪几个没有选课(用空值填的)
select stu_name
, rec_id
from students left join records
on students.stu_id = records.stu_id;
-- 通过空值查没选课的名字
select stu_name
from students left join records
on students.stu_id = records.stu_id
where rec_id is null;
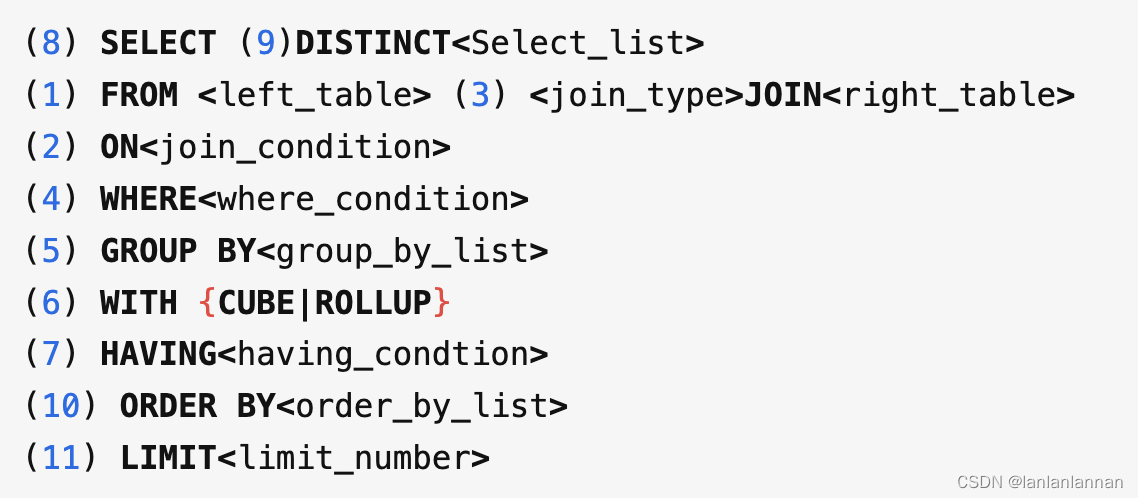
SQL执行顺序

![Java[集合] Map 和 Set](https://img-blog.csdnimg.cn/img_convert/afe7b802905647c8b277717aadc5b76a.jpeg)






![[ 高并发]Java高并发编程系列第二篇--线程同步](https://img-blog.csdnimg.cn/img_convert/c6b8f3f7c738d69fbd794ae6997f7a30.png)



![迭代器设计模式(Iterator Design Pattern)[论点:概念、组成角色、相关图示、示例代码、框架中的运用、适用场景]](https://img-blog.csdnimg.cn/20e2f2a9584e413cb950f50070dc8213.png)