文章目录
- 1 卷积层
- 1.1 torch.nn.Conv2d相关参数
- 1.2 填充:padding
- 1.3 步长:stride
- 2 最大池化层
- 3 手写数字识别
该专栏内容为对该视频的学习记录:【《PyTorch深度学习实践》完结合集】
专栏的全部代码、数据集和课件全放在个人GitHub了,欢迎自取。
1 卷积层
CNN卷积神经网络中的卷积层是其中最为关键的层之一。卷积层利用滤波器(也称为卷积核)在输入数据上进行卷积操作,通过提取局部特征来识别图像中的模式。
卷积层的输入通常是一个多通道(channel)的二维图像,每个通道表示图像的一种特征。卷积核是一个小的二维矩阵,可以看作是卷积层所学习的一种滤波器,它在输入数据上进行滑动窗口操作,将每个窗口与卷积核进行点积运算,得到一个新的特征图。
卷积层通常有多个滤波器,每个滤波器可以学习不同的特征,因此卷积层的输出是多个特征图的叠加,每个特征图对应一个滤波器。这些特征图可以通过非线性激活函数(如ReLU)进行激活,以增强模型的表达能力。
卷积层还有一些重要的参数,例如步长stride、填充padding等,这些参数可以控制卷积核的移动步长和边缘填充方式,以适应不同的输入数据和模型需求。
在深度学习中,卷积层是图像识别、目标检测、语音识别等任务中非常重要的组件之一,因为它可以有效地提取输入数据中的局部特征,从而实现对输入数据的有效表示和分类。
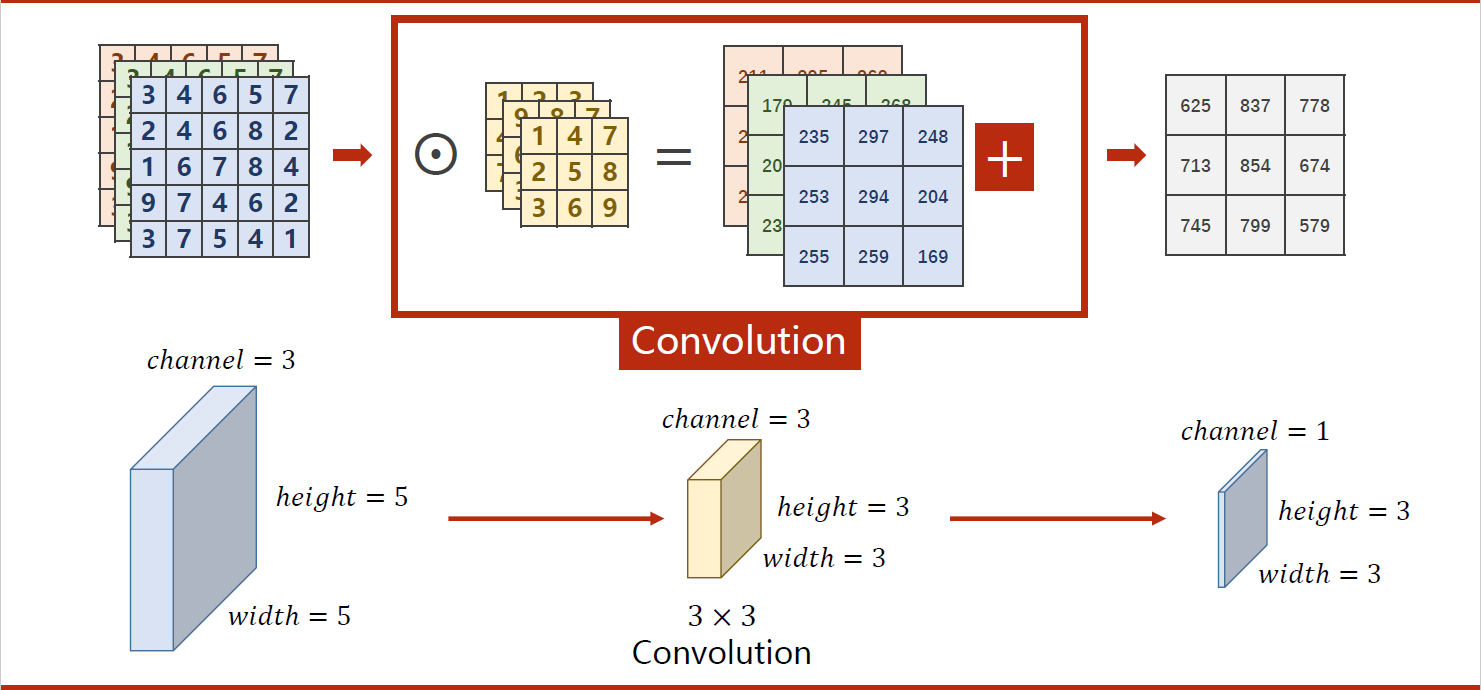
下图是一个简单的卷积操作:
1.1 torch.nn.Conv2d相关参数
卷积层的形状与输入输出之间有密切的关系。卷积层的形状通常由以下几个参数决定:
- 输入数据的形状:输入数据的形状通常是一个多通道的二维图像,其维度通常表示为(通道数n,高度,宽度)或(高度,宽度,通道数)。
- 卷积核的形状:卷积核的形状通常是一个小的二维矩阵,其维度通常表示为(输出通道数m,输入通道数n,卷积核高度,卷积核宽度)。
- 填充方式:填充方式可以控制输入数据在卷积操作之前是否需要在边缘进行填充,以保持输出特征图的大小不变。常见的填充方式包括"VALID"和"SAME",分别表示不进行填充和进行全零填充。
- 步长:步长可以控制卷积核在输入数据上的滑动步长,以控制输出特征图的大小和形状。
根据上述参数,卷积层的输出形状可以通过以下公式计算:
-
(输入高度−卷积核高度+2∗填充高度)/步长+1
-
(输入宽度−卷积核宽度+2∗填充宽度)/步长+1
-
输出通道数m=卷积核数量m
因此,我们可以通过调整卷积核的形状、填充方式、步长等参数,来控制卷积层的输出形状和大小,以适应不同的输入数据和模型需求。
以下图为例,输入数据为n×w×h,卷积层中有m个卷积核,要进行卷积计算,卷积核中的通道数必须与输入数据的通道数n相等,一个卷积核会对应输出数据的一个通道,这里有m个卷积核,所以输出数据的通道数为m。

一般把卷积层表示为四维张量,即:输出数据通道数m(卷积核个数)× 输入数据通道数n(每个卷积核的通道数)× 卷积核宽度 × 卷积核高度。

下面这段代码使用PyTorch库构建了一个简单的卷积神经网络模型,包括一个卷积层和一个输入数据。以下是代码的具体解释:
import torch:导入PyTorch库。in_channels, out_channels, kernel_size = 5, 10, 3:定义输入通道数、输出通道数和卷积核大小,分别赋值为5、10和3。width, height = 100, 100:定义输入数据的宽度和高度,分别赋值为100。batch_size = 1:定义批量大小为1。input = torch.randn(batch_size, in_channels, width, height):生成一个大小为1×5×100×100的输入数据,其中每个元素是从均值为0,方差为1的正态分布中随机采样得到的。conv = torch.nn.Conv2d(in_channels, out_channels, kernel_size):定义一个卷积层,其中输入通道数为5,输出通道数为10,卷积核大小为3×3。output = conv(input):对输入数据进行卷积运算,输出结果的大小为1×10×98×98。print(input.shape):打印输入数据的大小,即1×5×100×100。print(output.shape):打印卷积层输出的大小,即1×10×98×98。print(conv.weight.shape):打印卷积层的权重参数大小,其中10个卷积核的形状为5×3×3,即每个卷积核都有5个通道,大小为3×3。
import torch
in_channels, out_channels, kernel_size = 5, 10, 3
width, height = 100, 100
batch_size = 1
input = torch.randn(batch_size, in_channels, width, height) #输入数据,1*5*100*100,随机数,均值为0,方差为1,正态分布
conv = torch.nn.Conv2d(in_channels, out_channels, kernel_size) #卷积层,输入通道数5,输出通道数10,卷积核大小3*3
output = conv(input) #进行卷积运算
print(input.shape)
print(output.shape)
print(conv.weight.shape) #10个卷积核,每个卷积核的形状为5*3*3
torch.Size([1, 5, 100, 100])
torch.Size([1, 10, 98, 98])
torch.Size([10, 5, 3, 3])
1.2 填充:padding
以下图为例,为了使输出数据的形状和输入数据一样也为 5 × 5 ,而我们的卷积核形状为 3 × 3 的,这时可以在输入数据中外围填充一圈0,即可达到目的。一般地,为了使输出数据形状不变,可以用卷积核的形状除以2,取整,设置为padding参数值。例如这里3除以2,取整为1,padding就设置为1。

通过设置参数padding=1(即在输入数据外填充1圈0),使输出的结果为1 * 1 * 5 * 5,与输入的形状一致:
import torch
input = [3, 4, 6, 5, 7,
2, 4, 6, 8, 2,
1, 6, 7, 8, 4,
9, 7, 4, 6, 2,
3, 7, 5, 4, 1]
input = torch.tensor(input, dtype=torch.float).view(1, 1, 5, 5)
conv_layer = torch.nn.Conv2d(1, 1, kernel_size=3, padding=1, bias=False) #padding=1,卷积核大小3*3,输入通道数1,输出通道数1
kernel = torch.tensor([1, 2, 3, 4, 5, 6, 7, 8, 9], dtype=torch.float).view(1, 1, 3, 3)
conv_layer.weight.data = kernel.data #卷积核的值
output = conv_layer(input)
print(output)
tensor([[[[ 91., 168., 224., 215., 127.],
[114., 211., 295., 262., 149.],
[192., 259., 282., 214., 122.],
[194., 251., 253., 169., 86.],
[ 96., 112., 110., 68., 31.]]]], grad_fn=<ConvolutionBackward0>)
1.3 步长:stride
卷积层的步长(stride)是指卷积核在进行卷积操作时每次移动的步长大小。具体来说,步长决定了卷积核在水平和垂直方向上每次移动的像素数。
如果步长为1,则卷积核每次只向右移动一个像素,这也是最常见的步长设置。如果步长大于1,则卷积核每次向右移动的像素数会相应增加,这会导致输出特征图的尺寸变小,因为每个卷积核的感受野(receptive field)覆盖的像素数减少。
步长的选择需要根据具体的应用场景和网络结构进行调整。如果希望输出特征图的尺寸更小,可以选择较大的步长;如果希望输出特征图的尺寸与输入特征图相同,则可以选择步长为1。

import torch
input = [3, 4, 6, 5, 7,
2, 4, 6, 8, 2,
1, 6, 7, 8, 4,
9, 7, 4, 6, 2,
3, 7, 5, 4, 1]
input = torch.tensor(input, dtype=torch.float).view(1, 1, 5, 5)
conv_layer = torch.nn.Conv2d(1, 1, kernel_size=3, stride=2, bias=False) #stride=2,卷积核大小3*3,输入通道数1,输出通道数1
kernel = torch.tensor([1, 2, 3, 4, 5, 6, 7, 8, 9], dtype=torch.float).view(1, 1, 3, 3)
conv_layer.weight.data = kernel.data #卷积核的值
output = conv_layer(input)
print(output)
tensor([[[[211., 262.],
[251., 169.]]]], grad_fn=<ConvolutionBackward0>)
2 最大池化层
最大池化层是卷积神经网络中常用的一种池化层,用于对输入特征图进行降采样,从而减小特征图的尺寸和参数数量,同时保留特征图中的主要特征。
最大池化层的操作非常简单:对于每个池化窗口,它会输出窗口内的最大值作为窗口的输出。因此,最大池化层没有任何需要学习的参数,只需要指定池化窗口的大小和步长。
在最大池化层中,池化窗口通常采用2×2大小,步长为2,这种池化方式也被称为2倍下采样。例如,在一个2×2的池化窗口中,选取4个输入值中的最大值作为池化窗口的输出值。最大池化层可以有效地减少输入特征图的尺寸和参数数量,从而加速网络的训练和推理过程,并且在一定程度上可以降低过拟合的风险。

import torch
input = [3, 4, 6, 5,
2, 4, 6, 8,
1, 6, 7, 5,
9, 7, 4, 6]
input = torch.tensor(input, dtype=torch.float).view(1, 1, 4, 4)
maxpooling_layer = torch.nn.MaxPool2d(kernel_size=2) #池化层,池化核大小2*2,步长默认为池化核大小
output = maxpooling_layer(input)
print(output)
tensor([[[[4., 8.],
[9., 7.]]]])
3 手写数字识别
过程:

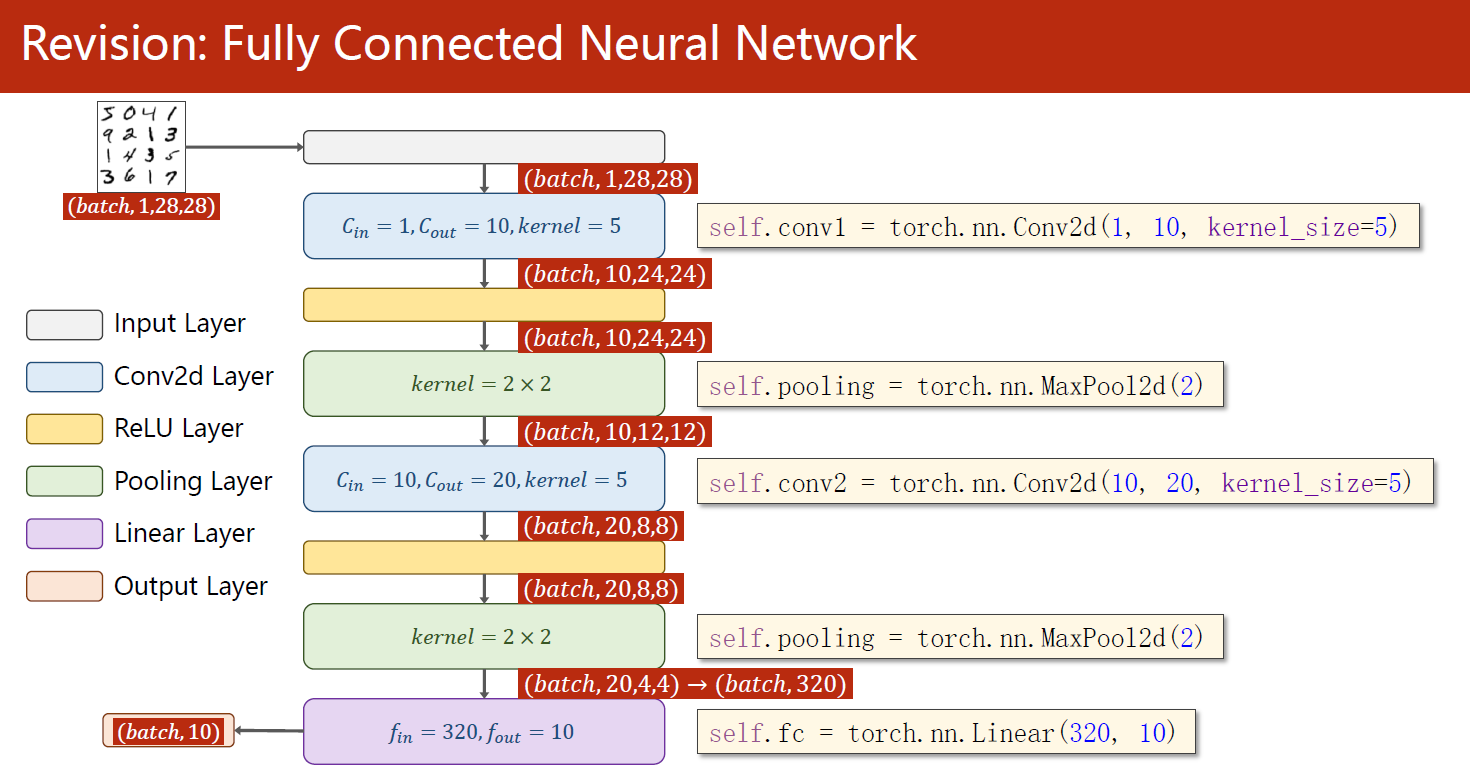
下面是一个使用PyTorch实现的简单的卷积神经网络,包含了数据集的准备、模型的设计、损失函数和优化器的构建以及训练和测试的过程。
该模型采用了两个卷积层和一个全连接层,每个卷积层后接一个最大池化层。其中第一个卷积层的输入通道为1,输出通道为10,卷积核大小为 5 x 5;第二个卷积层的输入通道为10,输出通道为20,卷积核大小仍为 5 x 5;两个池化层的窗口大小均为 2 x 2;全连接层的输入大小为320,输出大小为10,表示10个类别的概率分布。
模型的训练采用了SGD优化器,学习率为0.01,动量为0.5,损失函数为交叉熵损失函数。在训练过程中,每隔300个batch打印一次平均loss,并在每个epoch结束后进行一次测试,计算模型在测试集上的准确率。训练过程一共进行了10个epoch。
import torch
import torch.nn.functional as F
from torchvision import transforms
from torchvision import datasets
from torch.utils.data import DataLoader
import matplotlib.pyplot as plt
# 1、准备数据集
batch_size = 64
transform = transforms.Compose([ # 一系列的操作,Compose将其组合在一起
transforms.ToTensor(), # 将图片转换为Tensor
transforms.Normalize((0.1307,), (0.3081,)) # 标准化到[0,1],均值和方差
])
train_dataset = datasets.MNIST(root='../P6 逻辑斯谛回归/data',
train=True,
download=False, # 在P6 逻辑斯谛回归中我已下载,这里直接读取即可
transform=transform)
test_dataset = datasets.MNIST(root='../P6 逻辑斯谛回归/data',
train=False,
download=False,
transform=transform)
train_loader = DataLoader(dataset=train_dataset,
batch_size=batch_size,
shuffle=True)
test_loader = DataLoader(dataset=test_dataset,
batch_size=batch_size,
shuffle=False) # 测试集设置为False,方便观察结果
# 2、设计模型
class Net(torch.nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = torch.nn.Conv2d(1, 10, kernel_size=5) # 第一个卷积层
self.conv2 = torch.nn.Conv2d(10, 20, kernel_size=5) # 第二个卷积层
self.mp = torch.nn.MaxPool2d(2) # 池化层
self.l1 = torch.nn.Linear(320, 10) # 全连接层
def forward(self, x):
# Flatten data from (n, 1, 28, 28) to (n, 784)
batch_size = x.size(0) #获取batch_size,这里的batch_size=64
x = F.relu(self.mp(self.conv1(x))) # 第一个卷积层+池化层+激活函数
x = F.relu(self.mp(self.conv2(x))) # 第二个卷积层+池化层+激活函数
x = x.view(batch_size, -1) # 将数据展平,方便全连接层处理
x = self.l1(x) # 全连接层
return x
model = Net()
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu") # 判断是否有GPU加速
model.to(device) # 将模型放到GPU上
# 3、构建损失和优化器
criterion = torch.nn.CrossEntropyLoss() # 交叉熵损失函数
optimizer = torch.optim.SGD(model.parameters(), lr=0.01, momentum=0.5) # 优化器,lr为学习率,momentum为动量
# 4、训练和测试
def train(epoch):
running_loss = 0.0
for batch_idx, data in enumerate(train_loader, 0):
inputs, labels = data
inputs, labels = inputs.to(device), labels.to(device) # 将数据放到GPU上
optimizer.zero_grad() # 梯度清零
# forward + backward + update
outputs = model(inputs) # outputs并不是概率,而是线性层的输出,但其大小顺序与概率分布相同
loss = criterion(outputs, labels)
loss.backward() # 反向传播
optimizer.step() # 更新参数
running_loss += loss.item()
if batch_idx % 300 == 299: # 每300个batch打印一次平均loss
print('[%d, %5d] loss: %.3f' % (epoch + 1, batch_idx + 1, running_loss / 300))
running_loss = 0.0
def test():
correct = 0
total = 0
with torch.no_grad(): # 测试过程中不需要计算梯度
for data in test_loader:
images, labels = data
images, labels = images.to(device), labels.to(device) # 将数据放到GPU上
outputs = model(images)
_, predicted = torch.max(outputs.data, dim=1) # 返回每一行中最大值的那个元素,以及其索引
total += labels.size(0) # labels的size为[64],即64个样本
correct += (predicted == labels).sum().item() # 统计预测正确的样本个数
accuracy = 100 * correct / total
accuracy_list.append(accuracy)
print('Accuracy on test set: %d %%' % accuracy)
if __name__ == '__main__':
accuracy_list = []
for epoch in range(10):
train(epoch)
test()
plt.plot(accuracy_list)
plt.xlabel('epoch')
plt.ylabel('accuracy')
plt.grid()
plt.show()
运行结果:
[1, 300] loss: 0.577
[1, 600] loss: 0.192
[1, 900] loss: 0.127
Accuracy on test set: 97 %
[2, 300] loss: 0.113
[2, 600] loss: 0.094
[2, 900] loss: 0.087
Accuracy on test set: 97 %
[3, 300] loss: 0.084
[3, 600] loss: 0.077
[3, 900] loss: 0.068
Accuracy on test set: 97 %
[4, 300] loss: 0.066
[4, 600] loss: 0.062
[4, 900] loss: 0.061
Accuracy on test set: 98 %
[5, 300] loss: 0.052
[5, 600] loss: 0.055
[5, 900] loss: 0.057
Accuracy on test set: 98 %
[6, 300] loss: 0.050
[6, 600] loss: 0.051
[6, 900] loss: 0.048
Accuracy on test set: 98 %
[7, 300] loss: 0.045
[7, 600] loss: 0.046
[7, 900] loss: 0.045
Accuracy on test set: 98 %
[8, 300] loss: 0.040
[8, 600] loss: 0.043
[8, 900] loss: 0.042
Accuracy on test set: 98 %
[9, 300] loss: 0.035
[9, 600] loss: 0.041
[9, 900] loss: 0.040
Accuracy on test set: 98 %
[10, 300] loss: 0.038
[10, 600] loss: 0.033
[10, 900] loss: 0.038
Accuracy on test set: 98 %
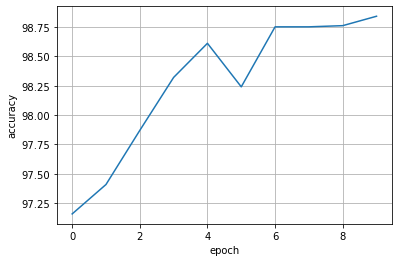
由于好奇增大epoch会怎么样,但我电脑没有GPU,就白嫖Kaggle的GPU跑了一下,把epoch增加到20,结果如下,可以跑到99%的准确率:


这个模型的训练和测试过程,可以考虑以下几个方面的改进:
- 数据增强:可以通过增加数据的随机变换(如旋转、缩放、平移等)来扩充训练集,从而增加模型的鲁棒性和泛化能力。
- 学习率调度:可以采用学习率调度策略(如StepLR、ReduceLROnPlateau等)来动态地调整学习率,从而使模型更容易收敛和避免过拟合。
- 权重初始化:可以采用不同的权重初始化方法(如Xavier、He等)来改善模型的收敛速度和效果。
- 正则化:可以通过L1/L2正则化、Dropout等方法来减轻过拟合的问题。
- 模型结构:可以尝试改变模型的层数、卷积核大小、池化层大小等超参数,从而提高模型的表现。
- 批归一化:可以在卷积层和全连接层之间添加批归一化层,从而加速模型收敛和提高泛化能力。
- 损失函数:可以采用不同的损失函数(如Focal Loss、Dice Loss等)来改善模型在不平衡数据集上的表现。
需要注意的是,每一种改进方式都需要根据具体情况进行选择和调整,同时还需要进行充分的实验验证,以确定其有效性和可行性。