🍎作者:阿润菜菜
📖专栏:Linux系统编程
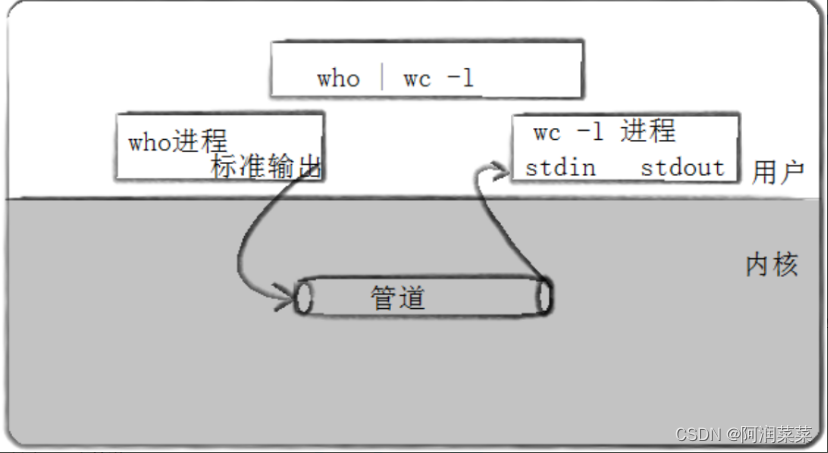
一、什么是管道通信
1. 管道通信是一种在进程间传递数据的方法
其实管道通信是Unix中最古老的进程间通信的形式了:
-
管道通信是一种进程间通信的方式,它可以让一个进程的输出作为另一个进程的输入,实现数据的传输、资源的共享、事件的通知和进程的控制。
-
管道通信分为两种类型:匿名管道和命名管道。
-
匿名管道是只能在父子进程间使用的,它通过pipe()函数创建,并返回两个文件描述符,一个用于读,一个用于写。
-
命名管道是可以在任意进程间使用的,它通过mkfifo()或mknod()函数创建一个特殊的文件,然后通过open()函数打开,并返回一个文件描述符,用于读或写。
-
管道通信的特点是面向字节流、占用内存空间、只能单向传输、有固定的大小和缓冲区等。
2.看看接口:匿名管道和命名管道
pipe()函数是用来创建一个匿名管道的,它的原型是:
#include <unistd.h>
int pipe(int pipefd[2]); // 返回值:若成功返回0,失败返回-1
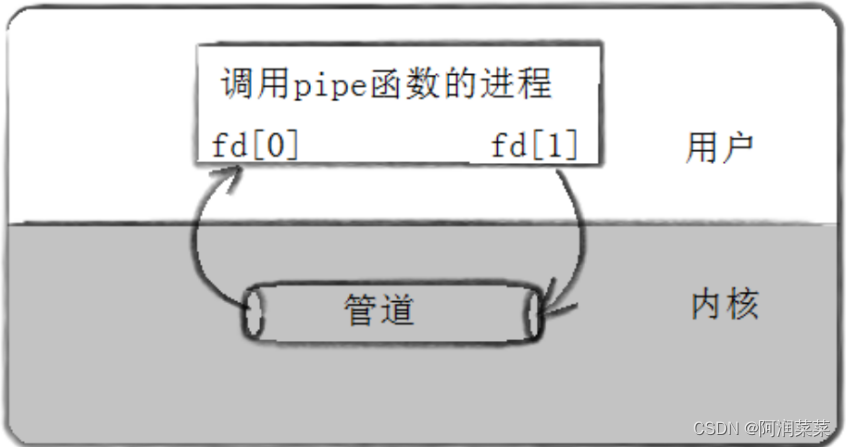
pipe()函数会返回两个文件描述符,pipefd[0]用于读取管道中的数据,pipefd[1]用于向管道中写入数据。匿名管道只能在具有亲缘关系的进程间通信,通常是父子进程或兄弟进程。
mkfifo()函数是用来创建一个命名管道的,它的原型是:
#include <sys/types.h>
#include <sys/stat.h>
int mkfifo(const char *pathname, mode_t mode); // 返回值:成功返回0,出错返回-1
mkfifo()函数会在文件系统中创建一个特殊的文件,该文件用于提供FIFO功能,即命名管道。命名管道可以在无关的进程间通信,只要知道它的路径名。命名管道需要用open()函数打开,并返回一个文件描述符,用于读或写。
pipe()函数和mkfifo()函数的区别主要有以下几点:
- pipe()函数创建的管道是匿名的,只能在有亲缘关系的进程间通信;mkfifo()函数创建的管道是有名字的,可以在任意进程间通信。
- pipe()函数创建的管道是在内存中的,不占用磁盘空间;mkfifo()函数创建的管道是在文件系统中的,占用磁盘空间。
- pipe()函数创建并打开了管道,返回两个文件描述符;mkfifo()函数只创建了管道,需要用open()函数打开,并返回一个文件描述符。
- pipe()函数创建的管道默认是阻塞的,即读写操作会等待对方进程;mkfifo()函数创建的管道可以指定非阻塞标志(O_NONBLOCK),即读写操作会立即返回成功或失败。
3. 管道通信的本质是什么?
管道通信的本质是利用内核提供的一块缓存区来实现不同进程间的数据传输、资源共享、事件通知和进程控制。
管道通信分为匿名管道和命名管道,它们都是一种特殊的文件,可以用普通的文件I/O函数进行操作。
1.匿名管道是通过pipe()函数创建并返回两个文件描述符,一个用于读,一个用于写。匿名管道只能在具有亲缘关系的进程间通信,通常是父子进程或兄弟进程。
2.命名管道是通过mkfifo()函数或mknod()函数创建一个特殊的文件,并通过open()函数打开并返回一个文件描述符,用于读或写。命名管道可以在任意进程间通信,只要知道它的路径名。
3.无论是匿名管道还是命名管道,它们都使用了环形缓冲区来存储数据。环形缓冲区是由16个内存页成的,每个内存页有一个pipe_buffer对象来管理。环形缓冲区有一个读指针和一个写指针来记录读写操作的位置。
4.当向管道写入数据时,从写指针指向的位置开始写入,并且将写指针向前移动。而从管道读取数据时,从读指针开始读入,并且将读指针向前移动。当对没有数据可读的管道进行读操作,或者对没有空闲空间的管道进行写操作时,会阻塞当前进程,除非设置了非阻塞标志(O_NONBLOCK)。
二、管道通信的实现和深入理解
1.如何创建和使用匿名管道
一般步骤如下:
- 在父进程中,使用pipe()函数创建一个匿名管道,该函数会返回两个文件描述符,一个用于读,一个用于写。
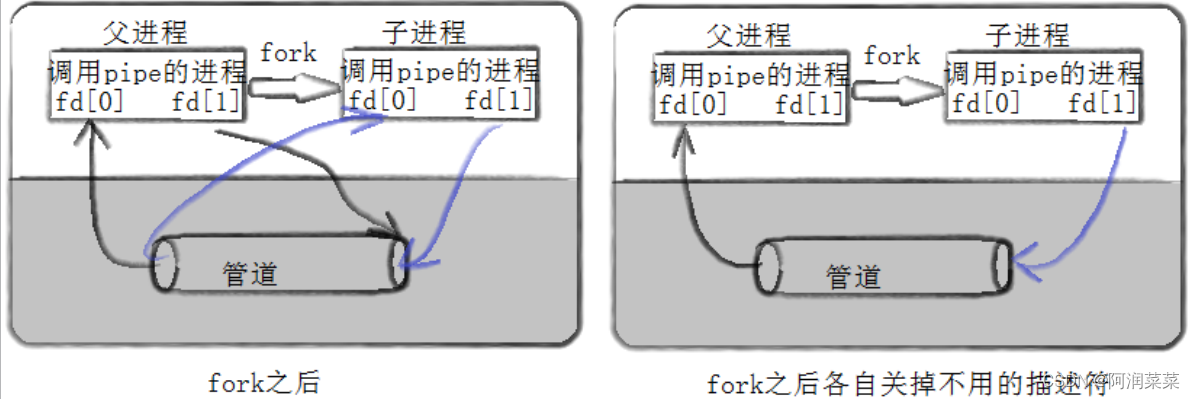
- 在父进程中,使用fork()函数创建一个子进程,子进程会继承父进程的文件描述符,从而可以访问同一个管道。
- 在父进程或子进程中,根据需要关闭不使用的管道端,比如父进程只写,子进程只读。
- 在父进程或子进程中,使用普通的文件I/O函数(如write()、read()、printf()、scanf()等)来向管道写入或读取数据。
- 在父进程或子进程中,使用close()函数关闭管道端。
一个示例代码:
// 父进程向子进程发送字符串
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <string.h>
#define STRING "hello world!"
#define BUFSIZ 1024
int main()
{
int pipefd[2]; // 管道文件描述符
char buf[BUFSIZ]; // 缓冲区
char *msg = STRING; // 消息
// 创建匿名管道
if (pipe(pipefd) == -1)
{
perror("pipe()");
exit(1);
}
// 创建子进程
pid_t pid = fork();
if (pid == 0) // 子进程
{
close(pipefd[1]); // 关闭管道写端
if (read(pipefd[0], buf, BUFSIZ) < 0) // 从管道读端读取数据
{
perror("read()");
exit(1);
}
printf("%s\n", buf); // 打印数据
exit(0);
}
else // 父进程
{
close(pipefd[0]); // 关闭管道读端
if (write(pipefd[1], msg, strlen(msg)) < 0) // 向管道写端写入数据
{
perror("write()");
exit(1);
}
wait(NULL); // 等待子进程结束
//wait(NULL)函数会暂停当前进程的执行,直到有一个子进程终止或发生信号
}
return 0;
}
小问题
必须在创建子进程之前创建匿名管道才能实现父子进程通信吗?为什么?
必须的!
必须在创建子进程之前创建匿名管道的原因有以下几点:
- 匿名管道是通过 pipe 系统调用来创建的,该系统调用会返回两个文件描述符,分别表示管道的读端和写端。
- 子进程会继承父进程打开的文件描述符,包括管道的读端和写端。这样,父子进程就可以通过共享的文件描述符来访问同一个管道。
- 如果在创建子进程之后再创建匿名管道,那么父子进程就无法共享文件描述符,也就无法通过同一个管道进行通信。
2.如何创建和使用命名管道
一般步骤如下:
- 在任意进程中,使用mkfifo()函数或mknod()函数创建一个特殊的文件,该文件用于提供命名管道的功能,需要指定一个路径名和一个权限模式。
- 在任意进程中,使用open()函数打开该文件,并返回一个文件描述符,用于读或写。可以指定非阻塞标志(O_NONBLOCK),以避免在没有对方进程时阻塞。
- 在任意进程中,使用普通的文件I/O函数(如write()、read()、printf()、scanf()等)来向管道写入或读取数据。
- 在任意进程中,使用close()函数关闭管道端。
这里再次理解一下进程阻塞:
代码:
// 服务器进程向客户端进程发送字符串
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#define FIFO_NAME "testfifo" // 命名管道路径名
#define STRING "hello world!" // 消息
int main()
{
int pipefd; // 管道文件描述符
char *msg = STRING; // 消息
// 创建命名管道
if (mkfifo(FIFO_NAME, 0666) == -1)
{
perror("mkfifo()");
exit(1);
}
// 打开命名管道
pipefd = open(FIFO_NAME, O_WRONLY);
if (pipefd == -1)
{
perror("open()");
exit(1);
}
// 向命名管道写入数据
if (write(pipefd, msg, strlen(msg)) < 0)
{
perror("write()");
exit(1);
}
// 关闭命名管道
close(pipefd);
return 0;
}
3.命名管道实现server&client通信
命名管道通信的大概原理如下:
- 命名管道由mkfifo()系统调用或者mkfifo命令创建,它在文件系统中有一个路径名和一个inode节点,可以被不同的进程打开和读写。
- 命名管道通信是以连接的方式进行的,服务器创建一个命名管道对象,然后在此对象上等待连接请求,一旦客户端连接过来,则两者都可以通过命名管道读或者写数据。
- 命名管道通信是阻塞式的,即当一个进程试图从空管道读取数据时,它会被阻塞,直到有数据可读;当一个进程试图向满管道写入数据时,它也会被阻塞,直到有空间可写。
- 命名管道通信是面向字节流的,数据在管道中先进先出(FIFO)。当一个进程向管道写入数据时,数据会被存放在内核缓冲区中,直到另一个进程从管道读取数据或者缓冲区满为止。
大志原理代码示例如下: 具体看我的代码仓库中的代码示例
- 服务器端代码:
#include <stdio.h>
#include <stdlib.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#include <unistd.h>
#define MAX 1024
int main()
{
if (mkfifo("./fifo", 0644) < 0) //创建命名管道,并判断是否创建成功
{
perror("mkfifo error!\n");
return 1;
}
int fd = open("./fifo", O_RDONLY); //让./fifo以只读方式打开
if (fd < 0)
{
perror("read error!\n");
return 2;
}
char buf[MAX];
while (1)
{
buf[0] = 0;
printf("Please wait...\n");
ssize_t s = read(fd, buf, sizeof(buf) - 1); //从管道中读取数据
if (s > 0) //读取成功
{
buf[s - 1] = 0;
printf("client# %s\n", buf);
}
else if (s == 0)
{
printf("client quit,server quit too!\n");
break;
}
else
{
perror("read");
}
}
close(fd); //关闭读端
return 0;
}
- 客户端代码:
#include <stdio.h>
#include <string.h>
#include <sys/types.h>
#include <sys/stat.h>
#include <fcntl.h>
#define MAX 1024
int main()
{
int fd = open("./fifo", O_WRONLY); //把./fifo文件以只写方式打开
if (fd < 0)
{
perror("read");
return 1;
}
char buf[MAX];
while (1)
{
buf[0] = 0;
printf("Please Enter:> ");
scanf("%s", buf);
write(fd, buf, strlen(buf)); //往管道里面写入数据
}
4 再次理解管道通信!
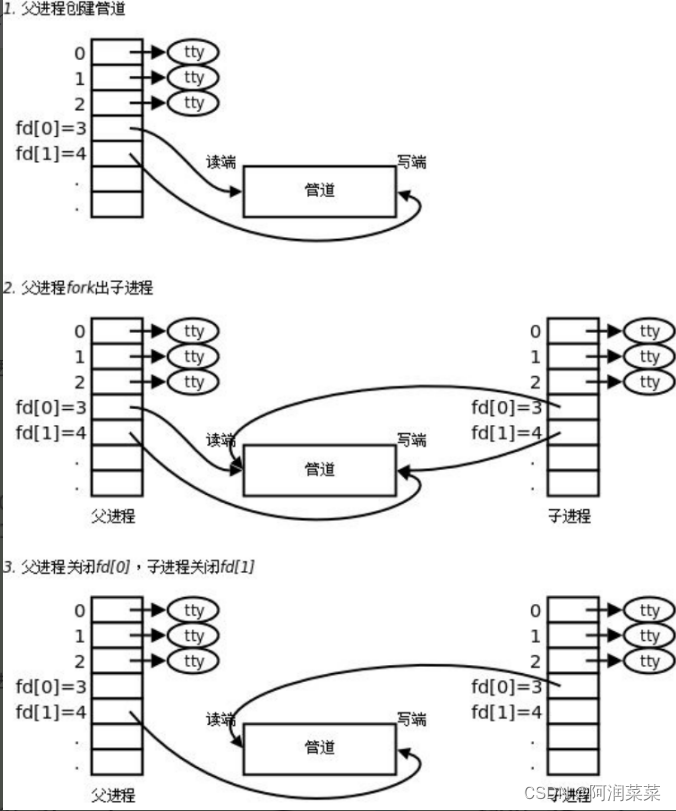
站在文件描述符角度去深度理解管道
-
我们知道文件描述符是一个数字,用来表示进程打开的文件。每个进程都有一个文件描述符表,用来存储文件描述符和对应的文件指针。
-
管道是一种利用内核缓冲区实现进程间通信的方法,它可以让一个进程的输出作为另一个进程的输入,实现数据的单向传输。
-
管道由pipe()系统调用创建,返回两个文件描述符,分别代表管道的读端和写端。通常,一个进程创建管道后,再fork出一个子进程,然后父子进程分别关闭不需要的管道端,建立通信连接
站在内核角度看看管道本质
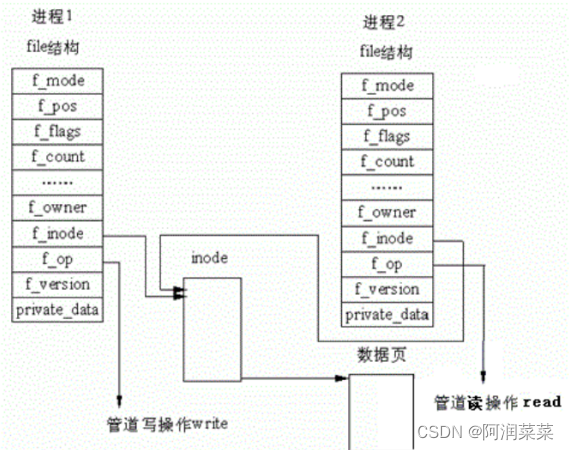
Again:管道通信是一种利用内核缓冲区实现进程间通信的方法,它可以让一个进程的输出作为另一个进程的输入,实现数据的单向传输。
所以,看待管道,就如同看待文件一样!管道的使用和文件一致,迎合了“Linux一切皆文件思想”!
5. 管道通信特点或者说工作机制
- 管道通信是半双工的,有固定的读端和写端。
- 管道通信是先进先出的,数据被进程从管道读出后,在管道中该数据就不存在了。
- 管道通信是基于文件操作的,需要使用文件描述符来管理管道的读写。
- 管道通信是阻塞式的,当进程去读取空管道或者写入满管道时,进程会阻塞。
- 管道通信分为匿名管道和命名管道,匿名管道只能用于具有亲缘关系的进程间通信,命名管道可以用于任何进程间通信。
- 一般而言,进程退出,管道释放,所以管道的生命周期随进程
一般而言,内核会对管道操作进行同步与互斥 - 管道通信是面向字节流的,数据在管道中先进先出(FIFO)。当一个进程向管道写入数据时,数据会被存放在内核缓冲区中,直到另一个进程从管道读取数据或者缓冲区满为止。
三、管道通信的优化和问题
管道通信的优点有以下几点:
- 管道通信是简单易用的,只需要使用系统调用 pipe 或 mkfifo 就可以创建一个管道文件,然后使用文件操作函数来读写数据。
- 管道通信是安全的,匿名管道只能用于具有亲缘关系的进程间通信,命名管道可以通过文件权限来控制访问。
- 管道通信是面向字节流的,不需要事先约定数据的格式,也不需要考虑字节序的问题。
管道通信的缺点有以下几点:
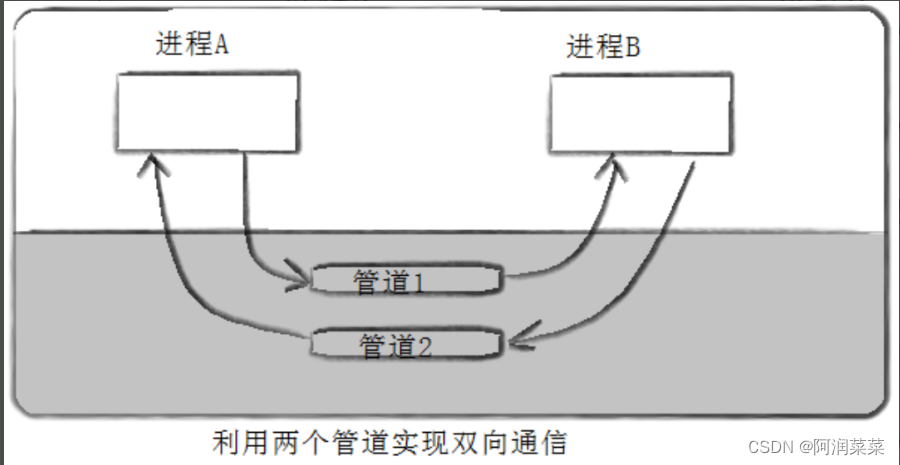
- 管道通信是单向的,如果要实现双向通信,需要创建两个管道。
- 管道通信是阻塞式的,如果读端没有数据可读或者写端没有空间可写,进程会被阻塞。
- 管道通信是缓冲区有限的,如果写入数据过多而读出数据过少,会导致缓冲区满而无法继续写入。
- 管道通信是不可靠的,如果读端或者写端被关闭,另一端可能会收到错误的信号或者返回值。
改进管道通信性能和效率的方法有以下几点:
- 使用双向管道,可以实现两个进程之间的双向通信,而不需要创建两个单向管道。双向管道可以通过 socketpair 系统调用来创建,返回两个文件描述符,分别表示管道的两端。
- 使用非阻塞模式,可以避免进程在读写管道时被阻塞,提高并发性能。非阻塞模式可以通过 fcntl 系统调用来设置文件描述符的 O_NONBLOCK 标志。
- 使用自定义协议,可以根据通信的需求和场景,设计合适的数据格式和交互方式,提高数据传输的效率和可靠性。自定义协议可以包括数据包的长度、类型、校验码等信息。
- 调整管道缓冲区的大小,可以根据数据量的大小和频率,选择合适的缓冲区大小,避免缓冲区溢出或者空闲浪费。管道缓冲区的大小可以通过 fcntl 系统调用来设置 F_SETPIPE_SZ 标志,并且可以通过 /proc/sys/fs/pipe-max-size 来修改最大容量。