堆排序
demo
从第一个父节点开始,每一个都调换自己和所有子孙节点的上下层次调换,形成最大堆。然后进行堆分支调整
class Solution {
public int[] sortArray(int[] nums) {
maxHeap(nums);
sort(nums);
return nums;
}
public static void maxHeap(int[] nums){
int limit = nums.length-1;
System.out.println(limit<<1+1);
for(int i=limit>>1;i>=0;i--){
changeForRoot(i,limit,nums);
}
}
public static void sort(int[] nums){
int limit = nums.length-1;
while(limit>0){
swap(nums,0,limit);
limit--;
changeForRoot(0,limit,nums);
}
}
public static void changeForRoot(int root,int limit,int[] nums) {
for (int i = root; ((i << 1) + 1) <= limit; ) {
int lChild = (i << 1) + 1;
int rChild = (i << 1) + 2;
int change = i;
if (lChild <= limit && nums[lChild] > nums[change]) {
change = lChild;
}
if (rChild <= limit && nums[rChild] > nums[change]) {
change = rChild;
}
if(i==change){
break;
}
swap(nums, i, change);
i = change;
}
}
public static void swap(int[] nums,int a,int b){
int tmp = nums[a];
nums[a] = nums[b];
nums[b] = tmp;
}
}
易错点
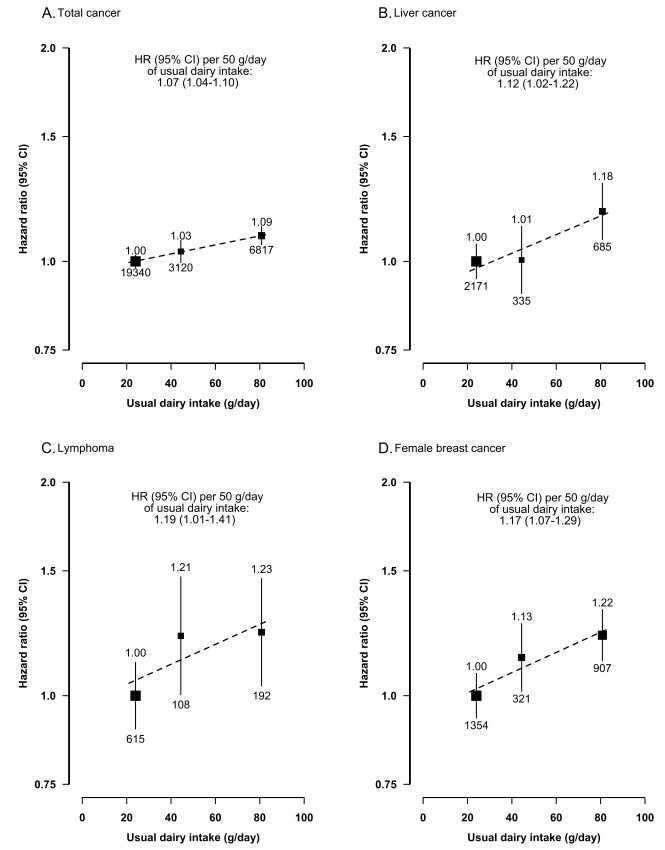
1 需要明白堆排序是一个O(nlogn)的算法,不要把第一次O(n)的堆遍历调整当成调整节点的方法,否则会变为O(n²)
2 第一次排序,每一个点都要和自己的子节点比较,然后比较之后,如果有顺序调整,还需要继续和孙节点进行比较,这个递归过程就是调整节点的步骤,复杂度为O(logn),因为进行了n次,所以总复杂度为O(nlogn)
归并排序
demo
class Solution {
private int[] arr;
public int[] sortArray(int[] nums) {
arr = new int[nums.length];
int rPoint = nums.length-1;
split(nums,0,rPoint);
return nums;
}
public void split(int[] nums,int left,int right) {
if(left>=right){
return;
}
int mid = (right-left)/2+left;
split(nums,left,mid);
split(nums,mid+1,right);
merge(nums,left,mid,right);
}
public void merge(int[] nums,int left,int mid,int right){
int point = left;
int l = left;
int r = mid+1;
while(l<=mid&&r<=right){
arr[point] = nums[l]<=nums[r]?nums[l++]:nums[r++];
point++;
}
while(l<=mid){
arr[point++] = nums[l++];
}
while(r<=right){
arr[point++] = nums[r++];
}
for(int i=left;i<=right;i++){
nums[i] = arr[i];
}
}
private void swap(int[] nums, int i, int j) {
int temp = nums[i];
nums[i] = nums[j];
nums[j] = temp;
}
}
易错点
一开始博主忘了底层算法,结果底层在冒泡和插入考虑,最终敲定插入然后就超时了,需要记得底层算法是双指针算法,由于最后一次合并过程必定需要一个O(n)空间,所以不如一开始就一直初始化这样大的空间。
快速排序
demo
class Solution {
public int[] sortArray(int[] nums) {
split(nums,0,nums.length-1);
System.out.println();
return nums;
}
private void split(int[] nums,int left,int right){
if(left>=right) return;
int pivot = sort(nums,left,right);
split(nums,left,pivot);
split(nums,pivot+1,right);
}
private int sort(int[] nums,int left,int right){
setPivot(nums,left,right);
int change = left;
int val = nums[right];
for(int i=left;i<right;i++){
if(nums[i]<val){
swap(nums,change,i);
change++;
}
}
swap(nums,right,change);
return change;
}
private void setPivot(int[] nums,int left,int right){
int pivot = left+(int)((right-left+1)*Math.random());
swap(nums,right,pivot);
}
private void swap(int[] nums, int i, int j) {
int temp = nums[i];
nums[i] = nums[j];
nums[j] = temp;
}
}
易错点
以下两个点很容易发现,但容易卡或者失去bug free
1 底层交换时,如果小于pivot,就提到change,然后change++,一开始博主想的是小于pivot,change右移,大于pivot,change++,脑子短路了
2 随机计算时要注意+1
总结
小数据选插入
大数据,对象选归并,因为稳定,如果是基础类型的话有结构选归并,无结构选快速
在Arrays.sort中插入和其它排序选择的转折点为47
为什么不用堆排,这个博客总结得很好,https://blog.csdn.net/csdnwxhw/article/details/119037375
1是因为堆本身就有一定的上下顺序,所以每次调整都大概率从尾到顶,而且父子节点有2倍索引差距,很容易造成随机读取,io消耗大




线程基础,线程控制,线程的互斥与同步](https://img-blog.csdnimg.cn/img_convert/842573432068f52a64d1099f4ff0ac74.png)
![[附源码]计算机毕业设计springboot春晓学堂管理系统](https://img-blog.csdnimg.cn/6ecb3927aa704a85aed3b61cbe4cef10.png)