来源: 新智源 微信号:AI-era
Meta的LLaMA模型开源,让文本大模型迎来了Stable Diffustion时刻。谁都没想
谁能想到,一次意外的LLaMA泄漏,竟点燃了开源LLM领域最大的创新火花。
一系列表现出色的ChatGPT开源替代品——「羊驼家族」,随后眼花缭乱地登场。

开源和基于 API 的分发之间的摩擦,是生成式AI生态系统中最迫在眉睫的矛盾之一。
在文本到图像领域,Stable Diffusion的发布清楚地表明,对于基础模型来说,开源是一种可行的分发机制。
然而,在大语言模型领域却并非如此,这个领域最大的突破,比如GPT-4、Claude和Cohere等模型,都只能通过API获得。
这些模型的开源替代品没有表现出相同水平的性能,特别是在遵循人类指令能力上。然而,一场意想不到的泄露,让这种状况彻底发生了改变。
LLaMA的「史诗级」泄漏
几周前,Meta AI推出了大语言模型LLaMA 。

LLaMA 有不同的版本,包括7B、13B、33B和65B的参数,虽然它比GPT-3小,但在许多任务上,它都能和GPT-3的性能相媲美。
LLaMA 起初并未开源,但在发布一周后,这个模型忽然在4chan上泄露了,引发了数千次下载。

这个事件,可以被称为「史诗级泄漏」了,因为它成为了大语言模型领域层出不穷的创新来源。
短短几周内,基于它构建的LLM代理的创新,已经呈爆炸式增长。
Alpaca、Vicuna、Koala、ChatLLaMA 、FreedomGPT、ColossalChat…… 让我们来回顾一下,这场「羊驼家族」的大爆炸,是如何诞生的。
Alpaca
在三月中旬,斯坦福发布的大模型Alpaca火了。

Alpaca是由Meta的LLaMA 7B微调而来的全新模型,仅用了52k数据,性能约等于GPT-3.5。
关键是训练成本奇低,不到600美元。
斯坦福研究者对GPT-3.5(text-davinci-003)和Alpaca 7B进行了比较,发现这两个模型的性能非常相似。Alpaca在与GPT-3.5的比较中,获胜次数为90对89。
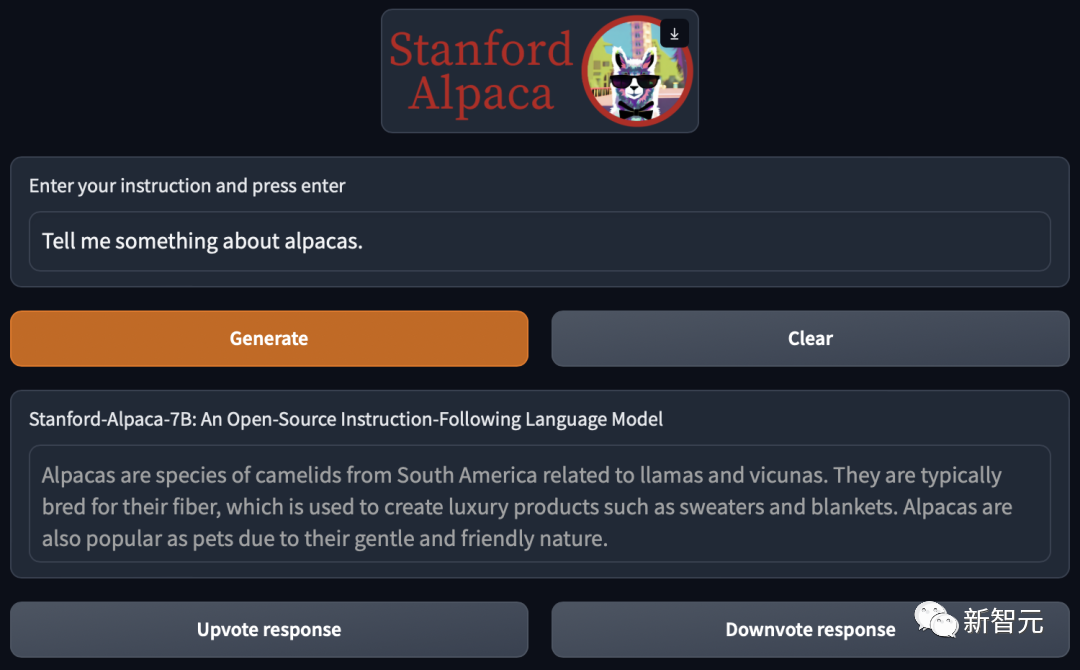
对于斯坦福的团队来说,想要在预算内训练一个高质量的指令遵循模型,就必须面临2个重要的挑战:要有一个强大的预训练语言模型,以及一个高质量的指令遵循数据。
恰恰,提供给学术研究人员使用的LLaMA模型搞定了第一个问题。
对于第二个挑战,「Self-Instruct: Aligning Language Model with Self Generated Instructions」论文给了很好的启发,即使用现有的强语言模型来自动生成指令数据。
LLaMA模型最大的弱点,就是缺乏指令微调。OpenAI最大的创新之一就是将指令调优用在了GPT-3上。
对此,斯坦福使用了现有的大语言模型,来自动生成遵循指令演示。
现在,Alpaca直接被网友们奉为「文本大模型的Stable Diffusion」。

Vicuna
3月底,来自UC伯克利、卡内基梅隆大学、斯坦福大学和加州大学圣地亚哥分校的研究人员开源了Vicuna,这是一个与GPT-4性能相匹配的LLaMA微调版本。

130亿参数的Vicuna,通过在ShareGPT收集的用户共享对话上对LLaMA进行微调训练而来,训练成本近300美元。
结果显示Vicuna-13B在超过90%的情况下,实现了与ChatGPT和Bard相匹敌的能力。
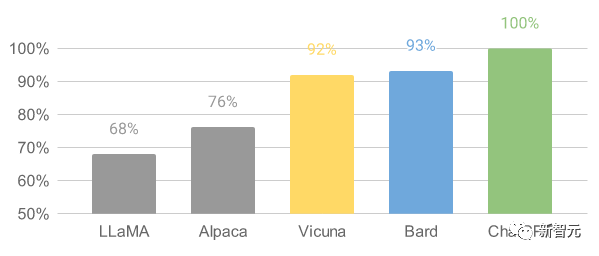

对于Vicuna-13B训练流程,具体如下:
首先,研究人员从ChatGPT对话分享网站ShareGPT上,收集了大约70K对话。
接下来,研究人员优化了Alpaca提供的训练脚本,使模型能够更好地处理多轮对话和长序列。之后利用PyTorch FSDP在8个A100 GPU上进行了一天的训练。
在模型的质量评估方面,研究人员创建了80个不同的问题,并用GPT-4对模型输出进行了评价。
为了比较不同的模型,研究人员将每个模型的输出组合成一个单独的提示,然后让GPT-4评估哪个模型给出的回答更好。
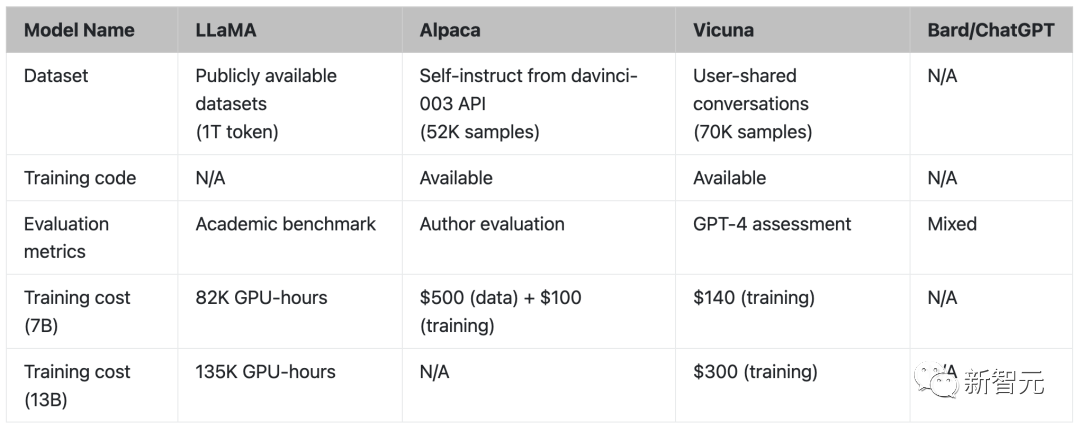
LLaMA、Alpaca、Vicuna和ChatGPT的对比
Koala
最近,UC伯克利 AI Research Institute(BAIR)又发布了一个新模型「考拉」(Koala),相比之前使用OpenAI的GPT数据进行指令微调,Koala的不同之处在于使用网络获取的高质量数据进行训练。

研究结果表明,Koala可以有效地回答各种用户的查询,生成的回答往往比Alpaca更受欢迎,至少在一半的情况下与ChatGPT的效果不相上下。
研究人员希望这次实验的结果可以进一步推动围绕大型闭源模型相对于小型公共模型的相对性能的讨论,特别是结果表明,对于那些能在本地运行的小模型,如果认真地收集训练数据,也可以取得大模型的性能。

事实上,在此之前斯坦福大学发布的Alpaca模型,根据OpenAI的GPT模型对LLaMA的数据进行微调的实验结果已经表明,正确的数据可以显著改善规模更小的开源模型。
这也是伯克利的研究人员开发和发布Koala模型的初衷,希望为这个讨论结果再提供了一个实验证明。
Koala对从网上获取的免费交互数据进行了微调,并且特别关注包括与ChatGPT 等高性能闭源模型交互的数据。
研究人员并没有追求尽可能多的抓取网络数据来最大化数据量,而是专注于收集一个小型的高质量数据集,包括ChatGPT蒸馏数据、开源数据等。
ChatLLaMA
Nebuly开源了ChatLLaMA ,这是一个使用让我们使用自己的数据创建对话助手的框架。

ChatLLaMA让我们使用自己的数据和尽可能少的计算量,来创建超个性化的类似ChatGPT的助手。
假设在未来,我们不再依赖一个「统治所有人」的大型助手,每个人都可以创建自己的个性化版本类ChatGPT助手,它们可以支持人类的各种需求。
不过,创建这种个性化助手需要在许多方面做出努力:数据集创建,使用RLHF进行高效训练,以及推理优化。
这个库的目的是,通过抽象计算优化和收集大量数据所需的工作,让开发人员高枕无忧。

ChatLLaMA旨在帮助开发人员处理各种用例,所有用例都与RLHF训练和优化推理有关。以下是一些用例参考:
-
为垂直特定任务(法律、医疗、游戏、学术研究等)创建类似ChatGPT的个性化助手;
-
想在本地硬件基础设施上使用有限的数据,训练一个高效的类似ChatGPT的助手;
-
想创建自己的个性化版本类ChatGPT助手,同时避免成本失控;
-
想了解哪种模型架构(LLaMA、OPT、GPTJ等)最符合我在硬件、计算预算和性能方面的要求;
-
想让助理与我的个人/公司价值观、文化、品牌和宣言保持一致。
FreedomGPT
FreedomGPT使用Electron 和 React构建,它是一个桌面应用程序,允许用户在他们的本地机器上运行LLaMA。

FreedomGPT的特色,从它的名字上就可见一斑——它回答的问题不受任何审查或安全过滤。
这个程序由AI风险投资公司Age of AI开发。
FreedomGPT 建立在 Alpaca 之上。FreedomGPT使用Alpaca的显著特征,因为与其他模型相比,Alpaca相对更易于访问和定制。
ChatGPT遵循OpenAI的使用政策,限制仇恨、自残、威胁、暴力、性方面的内容。
与ChatGPT不同,FreedomGPT回答问题时没有偏见或偏袒,并且会毫不犹豫地回答有争议或争论性的话题。

FreedomGPT甚至还回答了「如何在家制造炸弹」,而OpenAI专门从GPT-4中删除了这一点。
FreedomGPT很独特,因为它克服了审查限制,在没有任何保障的情况下迎合有争议的话题。它的标志是自由女神像,因为这个独特而大胆的大语言模型象征了自由。

FreedomGPT甚至可以在不需要联网的情况下,就能在计算机上本地运行。
此外,开源版本将很快发布,使用户和组织可以完全定制。
ColossalChat
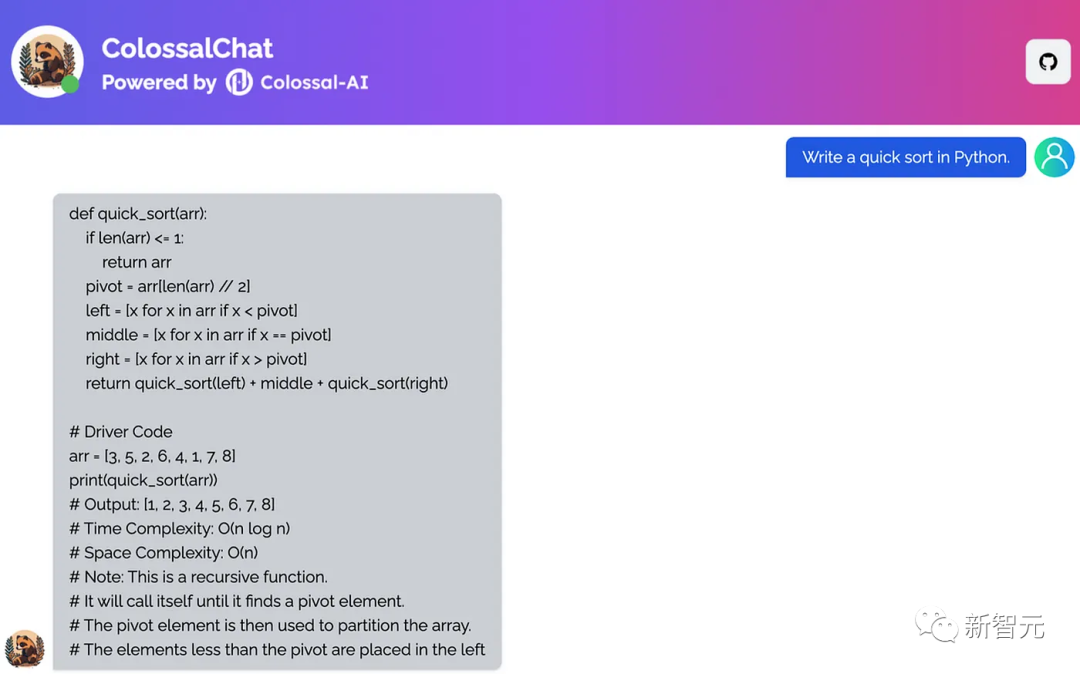
UC伯克利提出的ColossalChat只需要不到100亿个参数就可以达到中英文双语能力,效果与ChatGPT和GPT-3.5相当。
此外,基于LLaMA模型的ColossalChat,还复刻了完整的RLHF过程,是目前最接近ChatGPT原始技术路线的开源项目。

中英双语训练数据集
ColossalChat发布了一个双语数据集,其中包含大约100,000个中英文问答对。
该数据集是从社交媒体平台上的真实问题场景中收集和清理的,作为种子数据集,使用self-instruct进行扩展,标注成本约为900美元。
与其他self-instruct方法生成的数据集相比,该数据集包含更真实和多样化的种子数据,涵盖更广泛的主题。
该数据集适用于微调和RLHF训练。在提供优质数据的情况下,ColossalChat可以实现更好的对话交互,同时也支持中文。
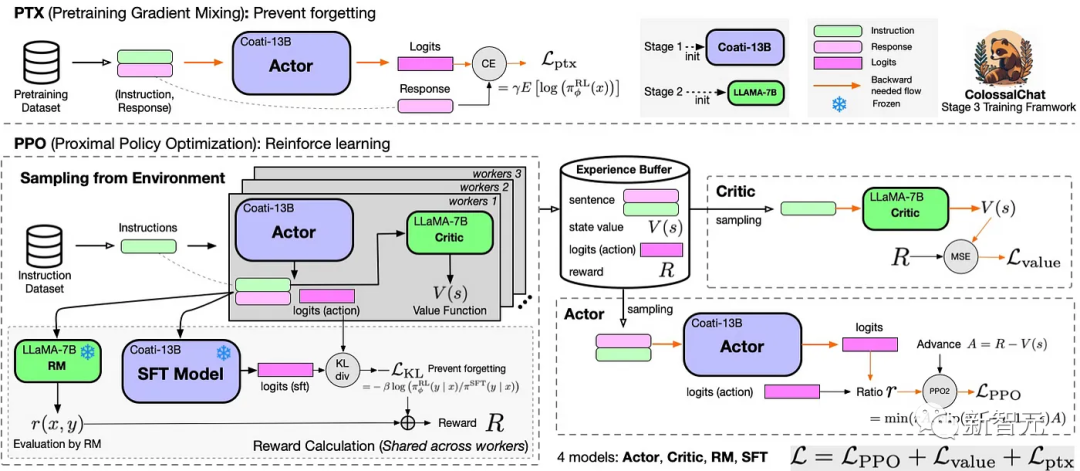
完整的RLHF管线
RLHF的算法复刻共有三个阶段:
在RLHF-Stage1中,使用上述双语数据集进行监督指令微调以微调模型。
在RLHF-Stage2中,通过对同一提示的不同输出手动排序来训练奖励模型分配相应的分数,然后监督奖励模型的训练。
在RLHF-Stage3中,使用了强化学习算法,这是训练过程中最复杂的部分。
相信很快,就会有更多项目发布。
谁也没想到,这场LLaMA的意外泄露,竟点燃了开源LLM领域最大的创新火花。
参考资料:
https://thesequence.substack.com/p/the-LLaMA%20%20-effect-how-an-accidental


![[Java·算法·中等]LeetCode105. 从前序与中序遍历序列构造二叉树](https://img-blog.csdnimg.cn/5ae7df0d63844a55a074057c0594a226.png)