ObjectBox: From Centers to Boxes for Anchor-Free Object Detection
论文地址:https://arxiv.org/pdf/2207.06985.pdf
官方代码:https://github.com/MohsenZand/ObjectBox
基于中心点的无锚点目标检测方法是一种目标检测方法,其思路是将目标看作是由中心点和边界框组成的,通过预测目标中心点和边界框的偏移量来实现目标检测,而不需要使用传统目标检测方法中使用的锚点(anchor)。
传统的目标检测方法通常使用锚点来预测目标框的位置和大小,锚点是一组预设的框,覆盖了不同尺度和长宽比的目标,模型通过锚点和目标框之间的重叠程度来确定目标框的位置和大小。但是锚点的设计和选择通常需要大量的手动调整和实验,而且对各种尺度和长宽比的目标不够灵活。
基于中心点的无锚点目标检测方法则采用了一种不需要锚点的方法,模型首先预测出每个像素点是否包含目标中心点,然后根据中心点预测出目标边界框的位置和大小。具体来说,模型包括两个分支:中心预测分支和边界框预测分支。中心预测分支用于预测每个像素点是否包含目标中心点,边界框预测分支则用于预测目标边界框的位置和大小。
相比于传统的锚点方法,基于中心点的无锚点目标检测方法具有更加灵活、更加高效和更加准确等优点,近年来在目标检测领域得到了广泛的研究和应用
"ObjectBox: From Centers to Boxes for Anchor-Free Object Detection"是一篇发表在2021年的论文,提出了一种基于中心点的无锚点目标检测方法,即ObjectBox。
传统的目标检测方法通常使用锚框(anchor)来预测目标框的位置和大小,但是锚框的设计和选择通常需要大量的手动调整和实验,而且对各种尺度和长宽比的目标不够灵活。ObjectBox则采用了一种不需要锚框的方法,通过预测目标中心点和边界框的偏移量来实现目标检测。
ObjectBox的主要思路是将目标看作是由中心点和边界框组成的,其中中心点表示目标的位置,边界框表示目标的大小和形状。模型首先预测出每个像素点是否包含目标中心点,然后根据中心点预测出目标边界框的位置和大小。具体来说,ObjectBox模型包括两个分支:中心预测分支和边界框预测分支。中心预测分支用于预测每个像素点是否包含目标中心点,边界框预测分支则用于预测目标边界框的位置和大小。
相比于传统的锚框方法,ObjectBox具有以下优点:
更加灵活:ObjectBox不需要预定义锚框,可以自适应地检测各种尺度和长宽比的目标。
更加高效:ObjectBox的中心预测分支可以减少不必要的计算,从而提高检测速度。
更加准确:ObjectBox可以更准确地定位目标,从而提高检测精度。
实验证明,ObjectBox在多个目标检测数据集上的表现都优于传统的锚框方法,具有很好的应用前景。
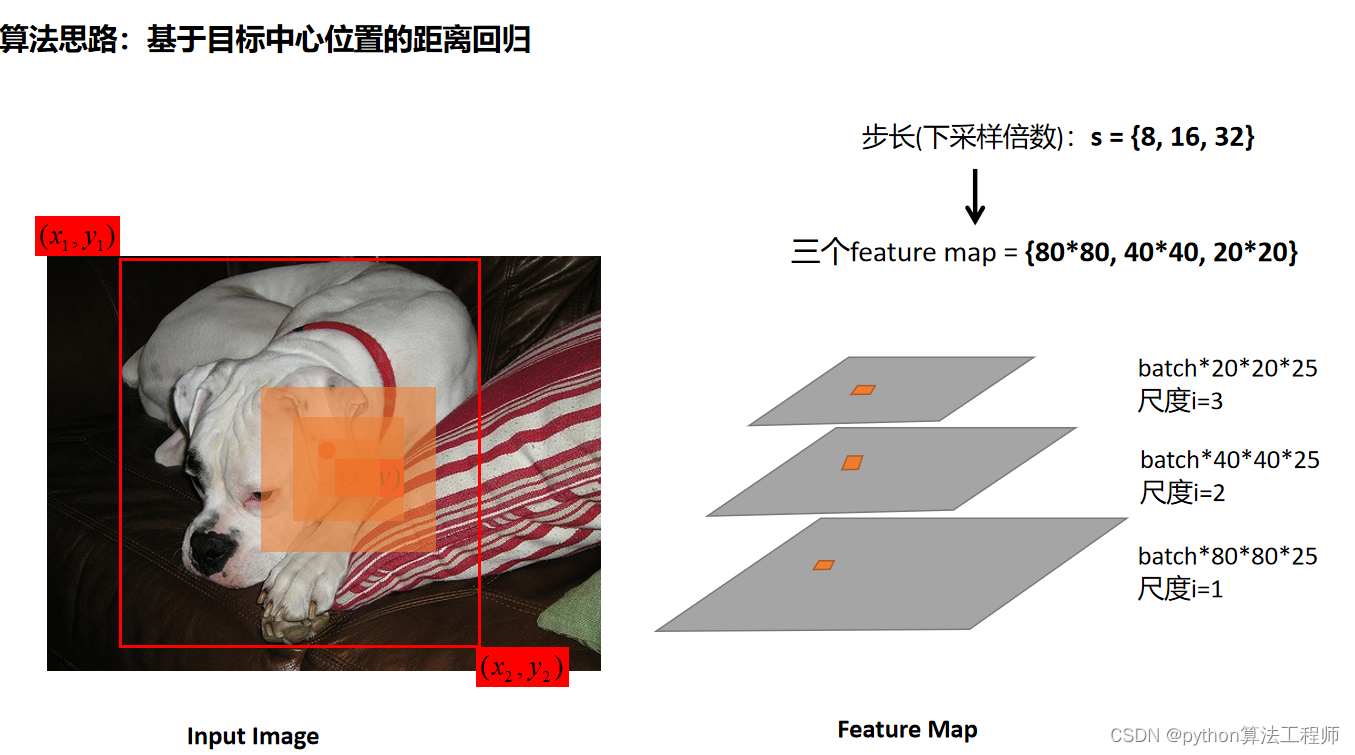
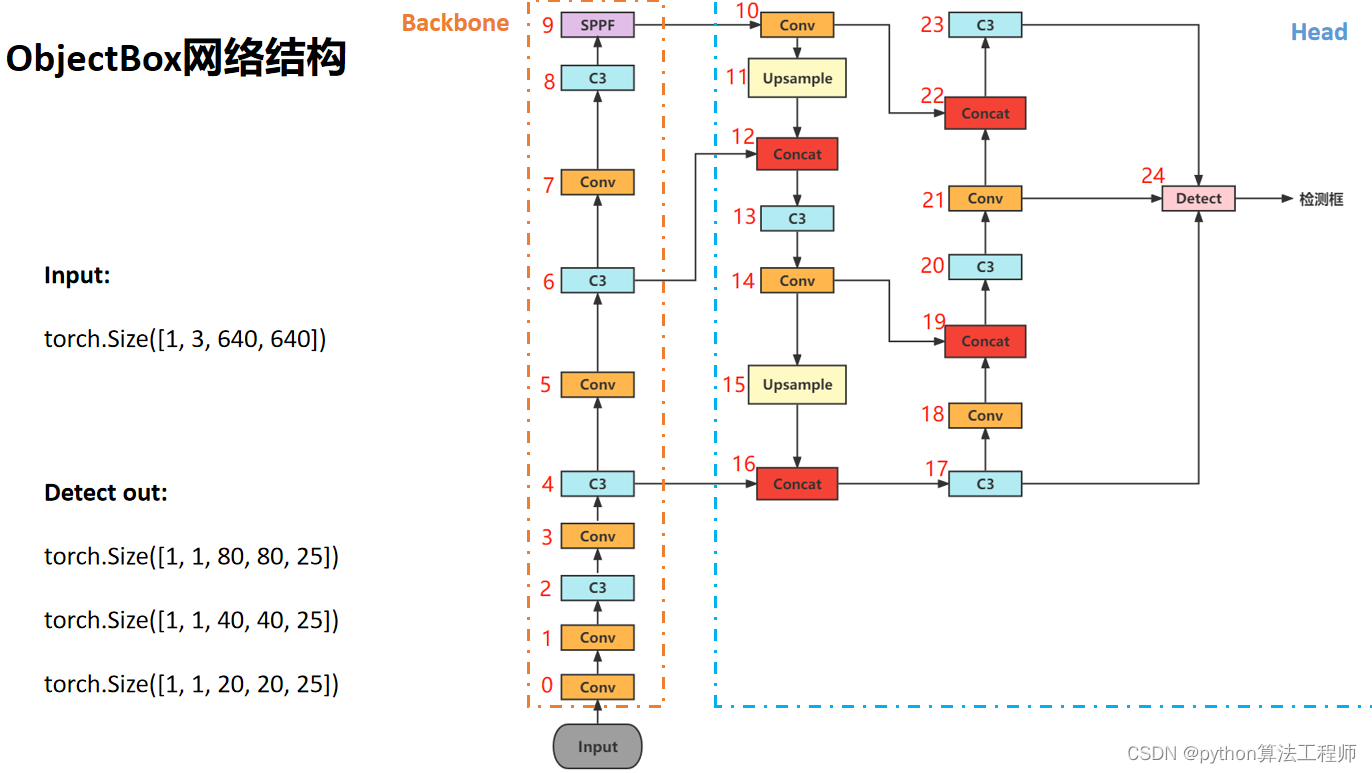 ObjectBox是一种基于中心点的无锚点目标检测方法,其算法思路如下:
ObjectBox是一种基于中心点的无锚点目标检测方法,其算法思路如下:
- 输入:给定一张图像,需要检测其中的目标。目标的类别和数量是不确定的。
- 特征提取:首先使用卷积神经网络(CNN)对输入图像进行特征提取,生成图像特征图。
- 中心预测分支:在特征图上,使用一个卷积层和一个sigmoid激活函数,生成一个与特征图大小相同的2维矩阵,表示每个像素点是否包含目标中心点的概率。这个矩阵被称为中心热图(center
heatmap)。 - 边界框预测分支:在特征图上,使用一个卷积层和一个线性激活函数,生成一个与特征图大小相同的4维张量,表示每个像素点对应的目标边界框的位置和大小偏移量(通常是相对于中心点的偏移量)。这个张量被称为边界框回归(bbox regression)张量。
- 检测:根据中心热图,找出所有的目标中心点,并结合边界框回归张量,计算出每个目标的边界框位置和大小。
- 后处理:对检测结果进行后处理,包括非极大值抑制(NMS)和分类器阈值等处理,以提高检测精度和减少误检率。
ObjectBox算法的主要优点是不需要预定义锚点,可以自适应地检测各种尺度和长宽比的目标,从而更加灵活、高效和准确。
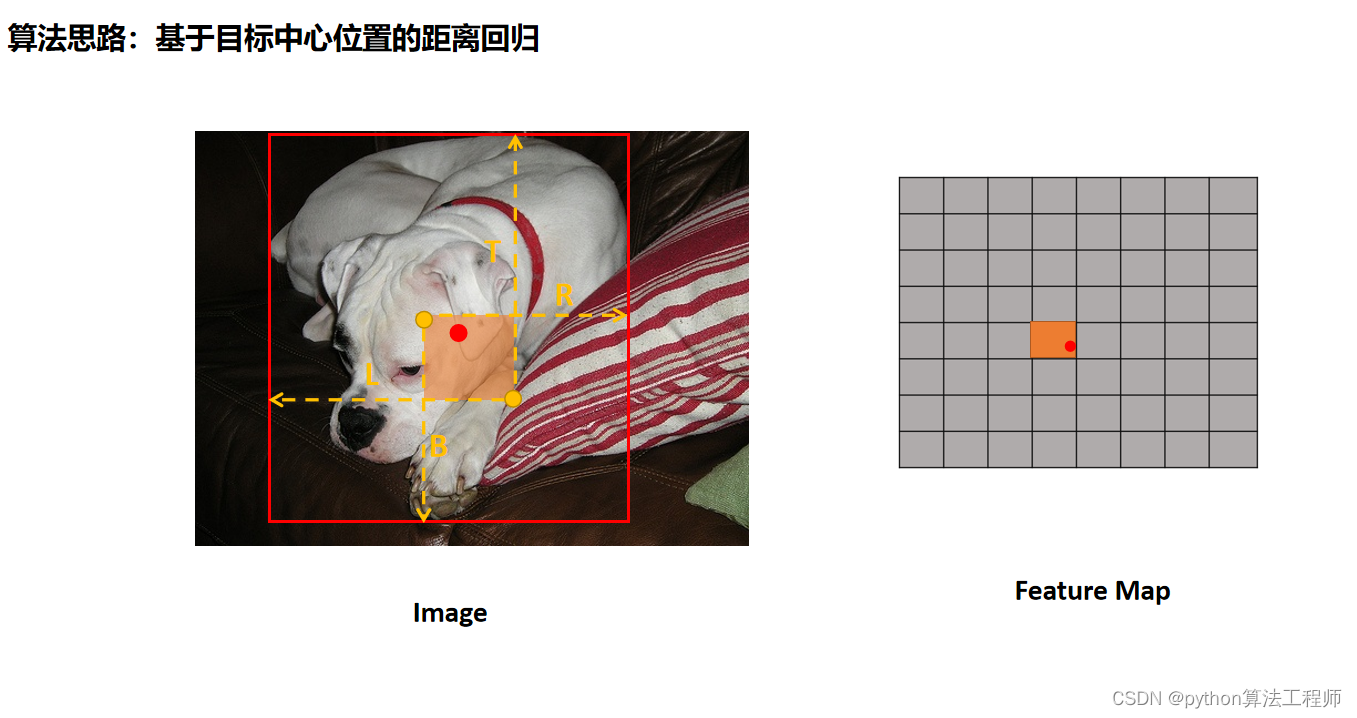
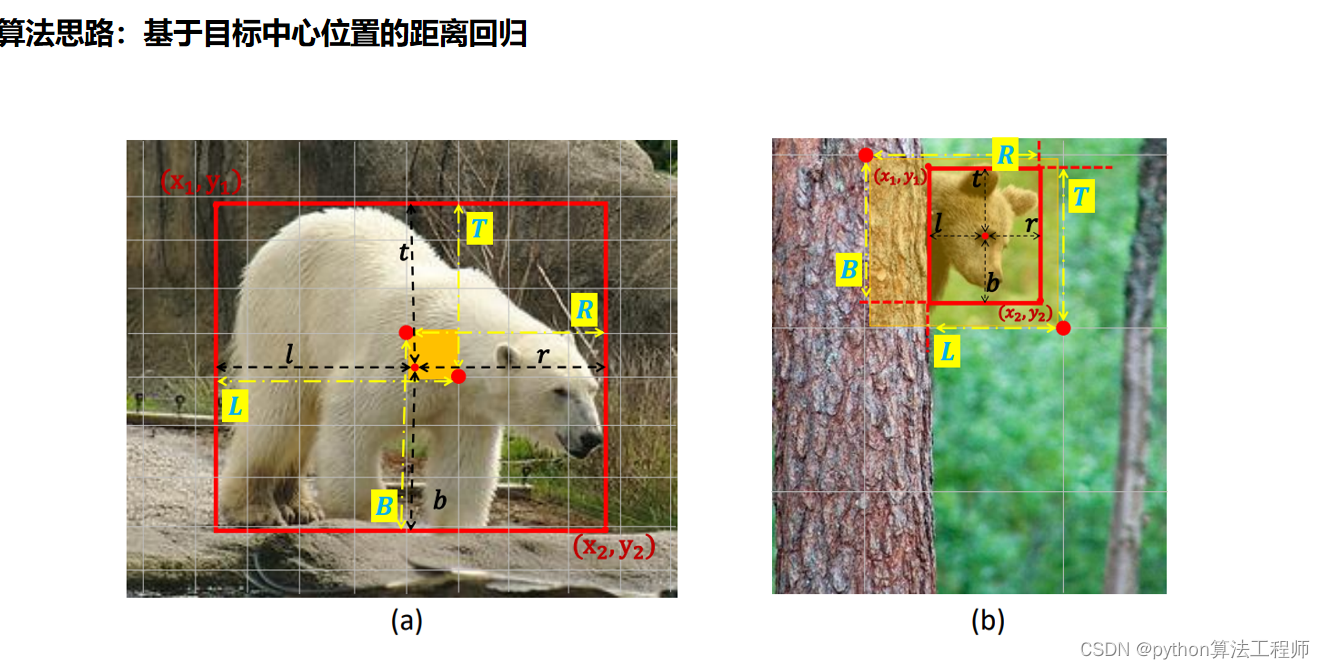
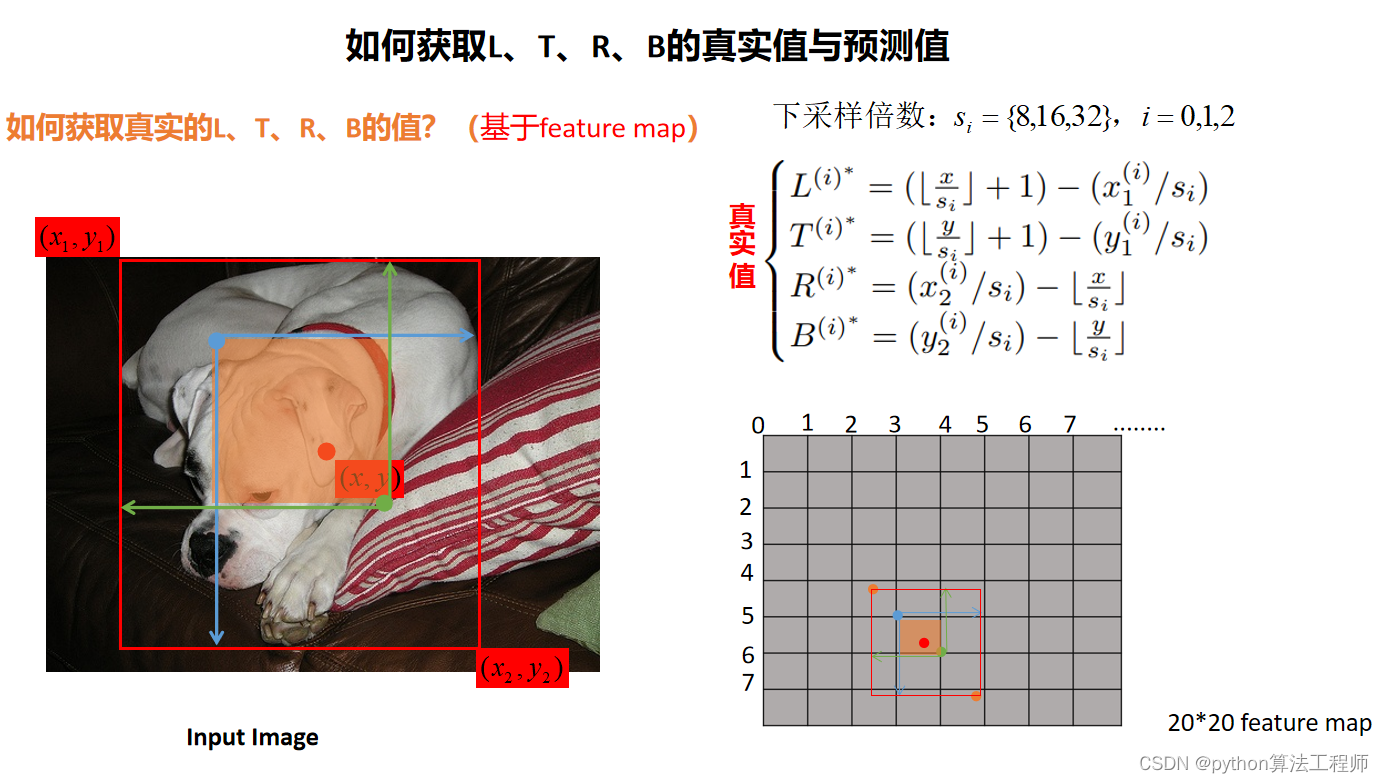
 在ObjectBox算法中,L、T、R分别表示目标边界框的左、上、右三个边界的位置,其真实值和预测值可以通过以下方式获取:
在ObjectBox算法中,L、T、R分别表示目标边界框的左、上、右三个边界的位置,其真实值和预测值可以通过以下方式获取:
- 真实值:对于每个目标,在训练时可以通过标注框(ground truth
box)来获取其真实的边界框位置和大小信息。标注框通常由左上角和右下角两个点的坐标表示,可以通过计算其左、上、右、下四个边界的位置来得到L、T、R、B的真实值。 - 预测值:在预测时,模型输出的边界框回归张量表示的是相对于中心点的位置和大小偏移量,需要结合中心点的位置和图像特征图的尺度等信息才能计算出绝对位置。具体来说,可以先在中心热图中找到中心点的位置,然后根据边界框回归张量计算得到目标边界框的位置和大小。最终可以得到目标边界框的左、上、右三个边界的位置,即L、T、R的预测值。
需要注意的是,在进行边界框回归时,需要对预测的位置和大小偏移量进行限制,以避免越界或生成不合理的边界框。同时,在进行后处理时,还需要对预测的边界框进行NMS等处理,以进一步提高检测精度和减少误检率。
 在训练目标检测模型时,正负样本的分配是非常关键的一步,通常采用的方法有两种:基于锚点的方式和基于中心点的方式。
在训练目标检测模型时,正负样本的分配是非常关键的一步,通常采用的方法有两种:基于锚点的方式和基于中心点的方式。
基于锚点的正负样本分配方法是将锚点与真实目标框进行匹配,根据匹配程度分配正负样本。具体来说,对于每个锚点,可以计算它与所有真实目标框的IoU值,将IoU值最大的目标框与该锚点进行匹配。匹配成功的锚点被标记为正样本,如果IoU值小于一定阈值则被标记为负样本。该方法的优点是简单、快速,但是需要手动设置锚点的尺度和长宽比,不够灵活。
基于中心点的正负样本分配方法不需要使用锚点,而是以中心点为基础,根据中心点的位置和目标的大小,动态地生成正样本和负样本。具体来说,将每个目标的中心点作为正样本,计算与其IoU值大于一定阈值的边界框作为正样本,与其IoU值小于一定阈值的边界框作为负样本。这种方法的优点是不需要手动设置锚点,可以适应各种尺度和长宽比的目标,但是在计算时需要对中心点和边界框的位置和大小进行限制,以避免生成不合理的框。
无论是哪种方法,都需要注意正负样本的平衡,通常采用的方法是在训练时采用随机采样的方式,使得正负样本的比例接近1:1,以避免过度拟合或欠拟合。同时,还可以采用多尺度训练、数据增强等方法,以进一步提高模型的性能和鲁棒性
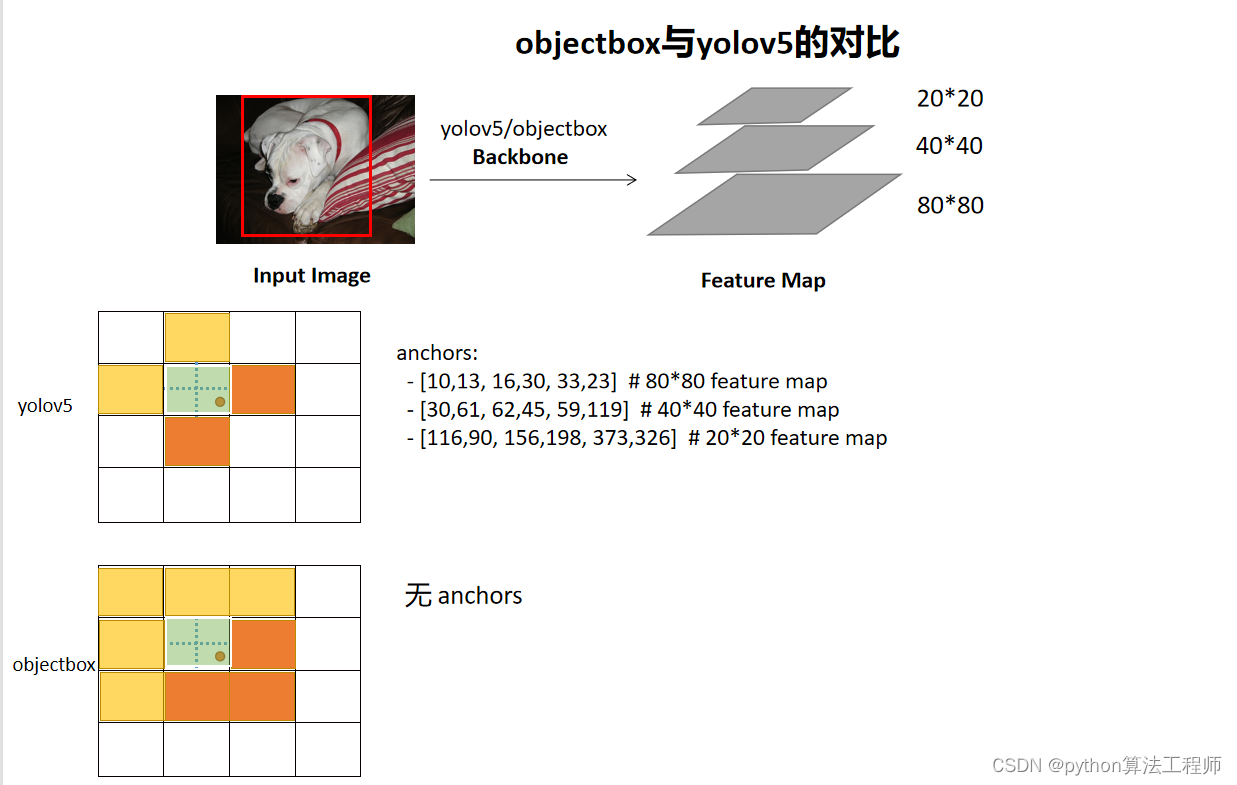
 ObjectBox和YOLOv5都是目标检测领域比较流行的算法,它们在目标检测的实现、性能和特点上都存在一些差异。
ObjectBox和YOLOv5都是目标检测领域比较流行的算法,它们在目标检测的实现、性能和特点上都存在一些差异。
实现方式:
ObjectBox采用了无锚点的方式进行目标检测,不需要预定义锚点,可以自适应地检测各种尺度和长宽比的目标。而YOLOv5采用了锚点的方式进行目标检测,需要手动设置不同尺度和长宽比的锚点。
模型结构:
ObjectBox使用了中心热图和边界框回归张量来预测目标中心点和边界框,而YOLOv5则采用了卷积神经网络直接预测目标的中心点和边界框。
后处理方式:
ObjectBox在预测时使用了非极大值抑制(NMS)和类别置信度阈值等方法进行后处理,以减少误检率和提高检测精度。而YOLOv5则使用了类别置信度和框置信度的加权和来对检测结果进行筛选和排序。
性能表现:
ObjectBox在一些标准数据集上取得了较好的结果,比如COCO数据集上的mAP指标可以达到54.6%,相比于一些其他的目标检测算法有一定优势。而YOLOv5在速度和精度上表现都比较优秀,速度可以达到140 FPS,同时精度也比较高。
总的来说,ObjectBox和YOLOv5都是目标检测领域比较流行的算法,它们在实现方式、性能和特点上都有所不同,具体选择哪种算法应根据具体场景和需求来进行评估和选择。
 ObjectBox是一种基于中心点的目标检测算法,其损失函数包括中心点热图损失和边界框损失两部分。
ObjectBox是一种基于中心点的目标检测算法,其损失函数包括中心点热图损失和边界框损失两部分。
中心点热图损失:
中心点热图损失用于预测目标的中心点位置。对于每个目标,算法会将其中心点位置映射到热图上,并用高斯分布来进行编码。具体地,对于每个目标,中心点热图损失可以通过以下公式计算:
L c e n t = 1 N ∑ i = 1 N ∑ j = 1 H × W × K ( y i , j c e n t log ( p i , j c e n t ) + ( 1 − y i , j c e n t ) log ( 1 − p i , j c e n t ) ) L_{cent} = \frac{1}{N}\sum_{i=1}^{N}\sum_{j=1}^{H\times W\times K}(y_{i,j}^{cent}\log(p_{i,j}^{cent}) + (1-y_{i,j}^{cent})\log(1-p_{i,j}^{cent})) Lcent=N1∑i=1N∑j=1H×W×K(yi,jcentlog(pi,jcent)+(1−yi,jcent)log(1−pi,jcent))
其中, N N N是样本数量, H H H和 W W W是热图的高度和宽度, K K K是一个常数, y i , j c e n t y_{i,j}^{cent} yi,jcent和 p i , j c e n t p_{i,j}^{cent} pi,jcent分别是第 i i i个样本的第 j j j个位置的真实值和预测值。
边界框损失:
边界框损失用于预测目标的边界框位置。对于每个目标,算法会预测其左上角和右下角的坐标,并用平方根误差(Smooth L1 Loss)来计算损失。具体地,对于每个目标,边界框损失可以通过以下公式计算:
L b o x = 1 N ∑ i = 1 N ∑ j = 1 H × W × K [ y i , j o b j ( α L i , j b o x + β L i , j s i z e ) ] L_{box} = \frac{1}{N}\sum_{i=1}^{N}\sum_{j=1}^{H\times W\times K}[y_{i,j}^{obj}(\alpha L_{i,j}^{box} + \beta L_{i,j}^{size})] Lbox=N1∑i=1N∑j=1H×W×K[yi,jobj(αLi,jbox+βLi,jsize)]
其中, y i , j o b j y_{i,j}^{obj} yi,jobj是第 i i i个样本的第 j j j个位置是否包含目标的标志位, L i , j b o x L_{i,j}^{box} Li,jbox和 L i , j s i z e L_{i,j}^{size} Li,jsize分别是预测的边界框位置和大小与真实值之间的平方根误差, α \alpha α和 β \beta β是常数。
最终的损失函数可以通过将中心点热图损失和边界框损失加权和来计算。
L = L c e n t + λ L b o x L = L_{cent} + \lambda L_{box} L=Lcent+λLbox
其中,
λ
\lambda
λ是一个常数,用于平衡两部分损失。在训练过程中,可以使用反向传播算法来计算梯度,并使用优化器来更新模型参数。
 SDIoU(Soft D-IoU)是一种用于边界框回归的损失函数,它可以更好地反映目标之间的重叠情况,从而提高目标检测的精度。
SDIoU(Soft D-IoU)是一种用于边界框回归的损失函数,它可以更好地反映目标之间的重叠情况,从而提高目标检测的精度。
SDIoU损失函数由两部分组成:D-IoU和Soft-IoU。其中,D-IoU是传统的IoU(Intersection over Union)损失,用于衡量预测框和真实框之间的重叠程度;Soft-IoU是一种平滑版本的IoU,用于衡量预测框和其他真实框之间的重叠程度。
具体地,SDIoU损失可以通过以下公式计算:
L S D I o U = 1 − I o U + 1 4 π 2 ∑ k = 1 K e − ( d k 2 / σ ) N k L_{SDIoU} = 1 - IoU + \frac{1}{4\pi^2}\sum_{k=1}^{K}\frac{e^{-(d_k^2/\sigma)}}{N_k} LSDIoU=1−IoU+4π21∑k=1KNke−(dk2/σ)
其中, I o U IoU IoU是预测框和真实框之间的IoU, d k d_k dk是预测框和第 k k k个真实框之间的距离, σ \sigma σ是一个常数, N k N_k Nk是第 k k k个真实框内部的像素数。
D-IoU可以通过以下公式计算:
D − I o U = 1 − I o U D-IoU = 1 - IoU D−IoU=1−IoU
其中, I o U IoU IoU是预测框和真实框之间的IoU。
Soft-IoU可以通过以下公式计算:
S o f t − I o U = 1 4 π 2 ∑ k = 1 K e − ( d k 2 / σ ) N k Soft-IoU = \frac{1}{4\pi^2}\sum_{k=1}^{K}\frac{e^{-(d_k^2/\sigma)}}{N_k} Soft−IoU=4π21∑k=1KNke−(dk2/σ)
其中, d k d_k dk是预测框和第 k k k个真实框之间的距离, σ \sigma σ是一个常数, N k N_k Nk是第 k k k个真实框内部的像素数。
最终的SDIoU损失函数可以通过将D-IoU和Soft-IoU加权和来计算:
L S D I o U = α D − I o U + ( 1 − α ) S o f t − I o U L_{SDIoU} = \alpha D-IoU + (1-\alpha)Soft-IoU LSDIoU=αD−IoU+(1−α)Soft−IoU
其中,
α
\alpha
α是一个常数,用于平衡两部分损失。在训练过程中,可以使用反向传播算法来计算梯度,并使用优化器来更新模型参数。