论文: https://arxiv.org/abs/2207.02696
论文: https://arxiv.org/abs/2207.02696
Github: https://github.com/WongKinYiu/yolov7
YOLOV7的一些理解
- 1.摘要
- 2.创新点
- 3.具体工作
- 3.1.网络结构优化
- 3.2.辅助头训练
- 3.3.标签分配策略
- 3.4.重参数结构
- 3.5.其它
1.摘要
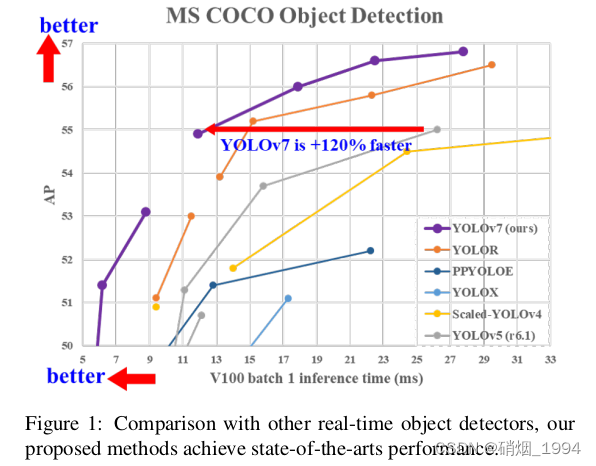
Yolov7是Yolov4团队的作品,受到了yolo原作者的认可,论文发布后就引起了较大的关注;Yolov7通过一系列优化和技巧的组合,截止至论文发布时间[2022年7月],在5FPS到160FPS的范围内,无论是速度或是精度,都超过了已知的检测器,并且在GPU V100上进行测试, 精度为56.8% AP的模型可达到30 FPS(batch=1)以上的检测速率,与此同时,这是目前唯一一款在如此高精度下仍能超过30FPS的检测器。
2.创新点
- 高效的网络结构 : 修改网络组件,引入ELAN结构
- 动态标签分配策略 : 结合yolov5的跨网格匹配策略及yolox的动态网格策略SimOTA
- 提出了一些Bag-of-Freebies方法:不增加推理时间的前提下,提高检测精度
- 辅助头训练策略
- 模型重参数化
3.具体工作
3.1.网络结构优化
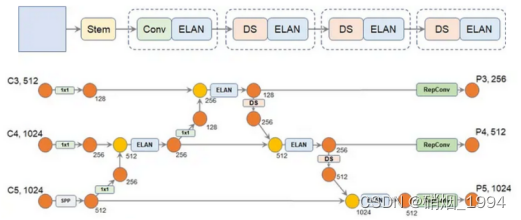
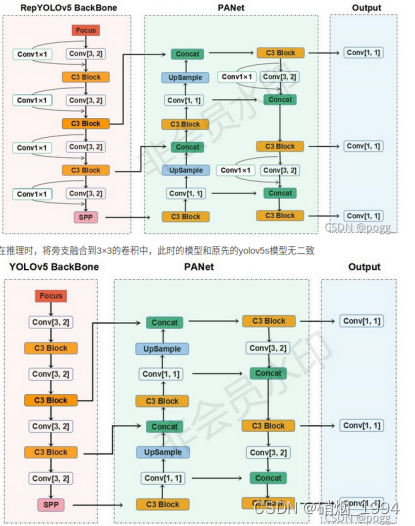
yolov7整体的网络架构还是延用yolov5,只是对部分组件进行了修改或替换;
Modify-1: 3层conv代替stem模块,实现两倍下采样
- Conv仍然是:卷积 + BN + SiLU三件套

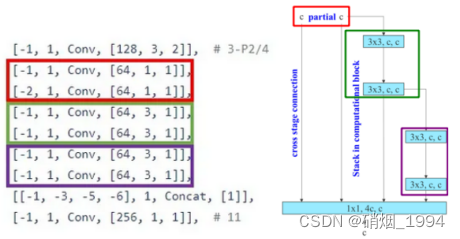
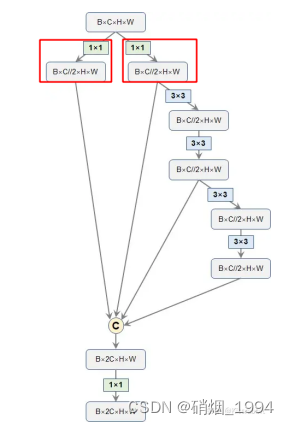
Modify-2: 引入ELAN模块代替CSP模块
- ELAN的这种结构的一个优势就是每个branch的操作中,输入通道都是和输出通道保持一致的[网络设计的一个高效准则]
- 仅仅是最开始的两个1x1卷积是有通道变化的
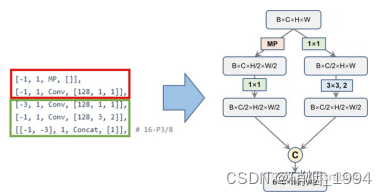
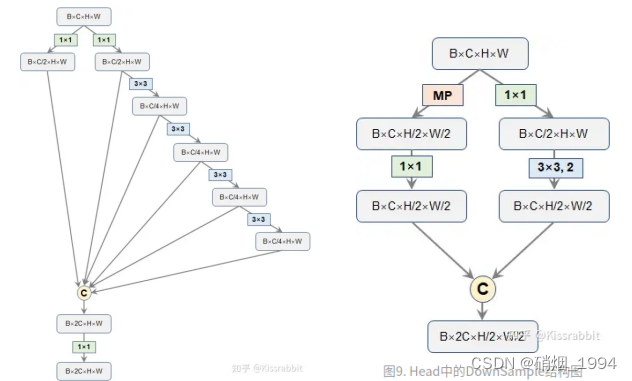
Modify-3: 下采样模块(Maxpling + Conv)
- 下采样的实现目前主要两种方法: 最大池化、步长为2的卷积,而yolov7下采样模块秉持着”大人全都要”的原则,同时包含两者;
- 左边的分支主要采用maxpooling(MP)来实现空间降采样,并紧跟一个1x1卷积压缩通道;
- 右边先用1x1卷积压缩通道,再用步长为2的3x3卷积完成降采样
- 最后,将两个分支的结果合并,通道一个通道数等于输入通道数,但空间分辨率缩小2倍的特征图
Modify-4: Neck部分仍然延用PANFPN的结构,区别在于
- ELAN代替CSP(ELAN结构相对于Backbone中更复杂)
- 下采样模块采用Maxpling + Conv(结构相对于Backbone输出的通道数增加)
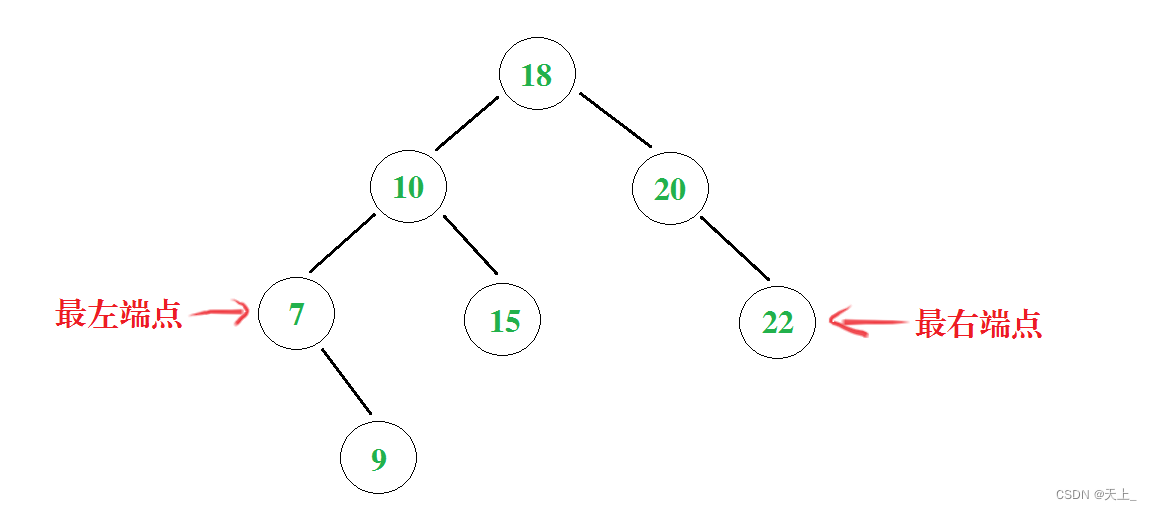
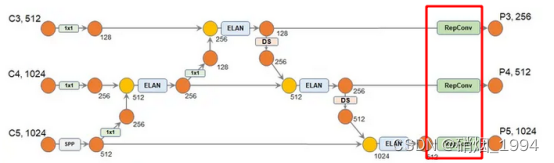
整体网络结构
- DS 为下采样模块
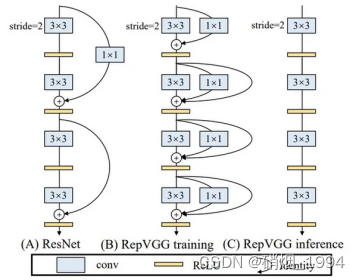
3.2.辅助头训练
深度监督是深度网络训练中常用的一种技术。 其主要思想是在网络的中间层增加辅助头部,并结合辅助损失作为浅层网络权重的指导;即使对于ResNet和densenet这样通常收敛良好的架构,深度监督仍然可以显著提高模型在许多任务上的性能;在yolov7中,我们称负责最终输出的头部为引导头(Lead head),称辅助训练的头部为辅助头(Aux head)。
关于辅助头位置问题
- 由于网络结构中引入了特征金字塔结构,因此可以将辅助头放置于金字塔的中间层是一个比较好的选择;
关于辅助头标签分配问题
- 常规处理方法:将辅助头和引导头分开,**利用各自的预测结果和GT来执行标签分配,**如下图©所示
- yolov7中则是以引导头预测结果为指导,生成粗到细的层次标签,分别用于辅助头和引导头学习,如下图(d)(e)所示

- Lead head指导的标签分配器(如上图d)
- 基于导向头的预测结果和GT进行计算,通过优化过程生成软标签
- 软标签在训练时将同时用于辅助头和导向头
- 导向头单独计算损失,辅助头将导向头匹配得到的正样本作为自己的正样本,并计算损失,最终相加(不同占比)
- 粗到细的导向头指导的标签分配器(如上图e)
- 使用导向头的预测和GT来生成软标签,但是它是生成两类标签,如coarse label和fine label
- fine标签和图d的软标签生成过程相同,coarse标签通过放宽对正样本的约束,允许更多的网格被视作正样本
- 对于辅助头更加倾向于优化模型的召回率,而导向头则是在高召回率的结果中挑选高精度的结果
- 导向头单独计算损失,辅助头将导向头匹配得到的正样本(粗匹配)作为自己的正样本,并计算损失,最终相加(占比不同)
- 注意:额外添加的粗标签样本不能和精细样本具有相同的loss权重,否则会损害检测器,因此需要对权重加以调整
- 两点关于是否带辅助头训练的区别
- loss函数和不带辅助头相同,但辅助头的加权系数不能过大(辅助头和主导头按照0.25:1的比例),否则会导致主导头出来的结果精度变低
- 匹配策略和上面的不带辅助头的区别在于:
- 主导头中每个网格与GT匹配上后,附加周边最近两个网格,而辅助头附加4个网格
- 主导头中将top10个样本iou求和取整,而辅助头中取top20
- 实验结果
- 引入辅助头比不加辅助头性能要好;
- 由粗到细的标签策略效果最好
3.3.标签分配策略
yolov7的标签分配策略(筛选正样本),主要是集成yolov5和yolov7两者的精华,同时对Coarse to fine的深层监督方式引入不同标签
- 使用yolov5跨网络匹配策略分配初步正样本
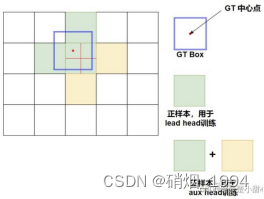
- yolov5中目标的匹配不再是基于iou,而是长宽比: anchor的长宽/GT的长宽小于设定的阈值,即为正样本;
- 除了引入目标中心点所在网格的anchor,还会引入中心点网格上下左右四个网格的anchor,参与正样本的匹配,大大增加正样本数量
- 其中,距离中心点较近的两个网格匹配的样本将用于引导头的训练,距离较远的两个网格会额外引入用于辅助头的训练[yolov5本身没有辅助头的操作,只会引入最近的两个网格]
- 如下图所示,红点为目标中心点所在位置,上下左右四个网格也会用于样本匹配;其中左、上网格距离中心点较近,将用于引导头的训练,右、下网格距离中心点较远,只会在辅助头训练的时候引入
- 使用yolov7动态网格匹配策略进一步筛选得到最终正样本
- 使用每个GT的预测样本确定它需要分配到的正样本数(Dynamic k)
- 计算第一步筛选得到的初步正样本iou
- 并对Top10的样本进行iou求和取整,确定为当前GT的Dynamic k(最小为1)
- 对于辅助头的训练Top取前20[粗标签]

- 计算每个样本对每个GT的Reg + Cls loss(Loss aware)
- 为每个GT取loss最小的前dynamic k个样本作为最终正样本
- 去掉同一个样本被分配到多个GT的正样本的情况
- 同样是基于loss筛选
- 使用每个GT的预测样本确定它需要分配到的正样本数(Dynamic k)
3.4.重参数结构
- 背景:来源于Repvgg
- 多分支结构:能够学到更丰富的特征,模型具有更高的精度
- 单分支结构:速度快,对硬件的支持更好,具有推理效率
- 结构重参数化:整合以上优势,在训练时采用多分支结构,推理时通过结构重参数化将模型转换为单分支结构,实现较高的推理效率
- 几点理解:
- 结构和参数是一一对应
- 通过参数的等价转换实现结构的等价转换,即变换结构参数将结构从一个结构转换到另一个结构
- 训练和推理进行解耦
- tensorrt部署加速技巧中—Conv、BN、Relu三个层融合(大部分情况是conv和bn融合)采用的就是这个技术
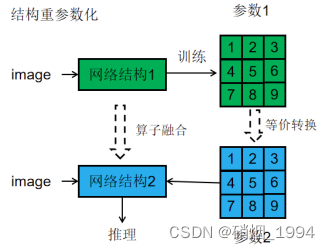
- Repvgg的结构实现
- 借鉴于resnet网络,使用identity和1*1分支构造训练时的RepVGG
- 通过结构从新参数化,合并两个旁路分支,最终形成直筒结构
- 参数/结构等效转换的具体实现
1.恒等映射分支可以被看做卷积核为1*1的单位1卷积- 经过这一步后变成了1个3 * 3卷积,2个1*1卷积
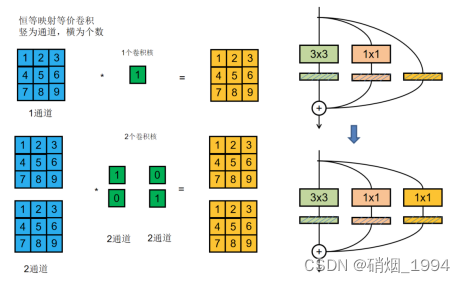
- 整合BN,再将1 * 1卷积核边缘补0成3 * 3卷积核
- 将 conv+bn 转换成一个带 bias 的 conv
- 1 * 1卷积核边缘补0转换为3 * 3卷积核
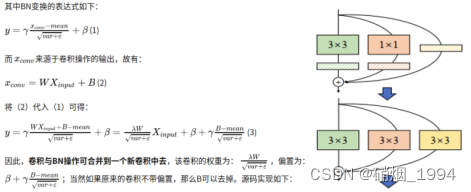
- 将三个卷积以中心点为基准相加,将 3 个卷积合并为 1 个
- 将2个1x1 kernels(边缘补 0)和1个3x3 kernels相加,就能得到最终的3x3 kernel
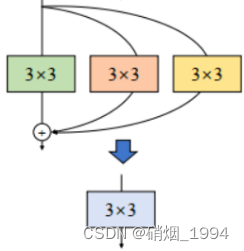
- 完整过程如下
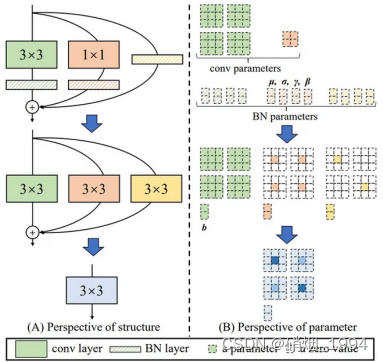
- 经过这一步后变成了1个3 * 3卷积,2个1*1卷积
- Yolo中的研究和应用
- 作者使用梯度传播路径来分析不同的重参化模块应该和哪些网络搭配使用
- 通过分析RepConv与不同架构的组合以及产生的性能,作者发现RepConv中的identity破坏了ResNet中的残差结构和DenseNet中的跨层连接,这为不同的特征图提供了梯度的多样性
- 基于上述原因,作者使用没有identity连接的RepConv结构
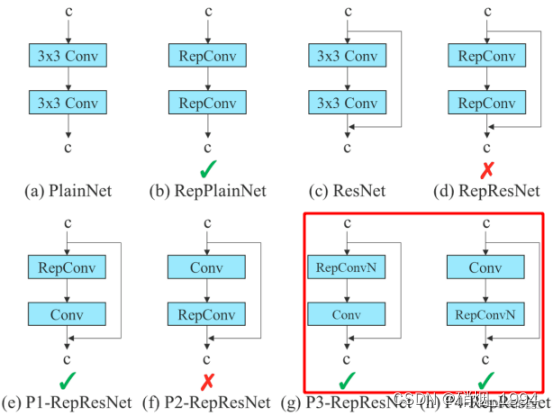
- V7中其实使用repconv并不多,只有在neck最后的时候用过一次
- 对于yolo系列的算法其实可以考虑将常规的conv代替为repconv
3.5.其它
- 组合缩放调整网络结构
- BN合并到Conv
- EMA