系列文章目录
spark第一章:环境安装
spark第二章:sparkcore实例
spark第三章:工程化代码
spark第四章:SparkSQL基本操作
spark第五章:SparkSQL实例
spark第六章:SparkStreaming基本操作
spark第七章:SparkStreaming实例
spark第八章:Pyspark
文章目录
- 系列文章目录
- 前言
- 一、环境准备
- 1.安装Python3
- 2.安装Pyspark
- 3.测试环境
- 4.提交py任务
- 二、编写代码
- 1.安装库
- 2.core操作
- 3.SQL操作
- 4.Streaming操作
- 在这里插入图片描述
- 总结
前言
之前我们用scala完成了spark内容的学习,现在我们用Pyspark来进行spark集群操作.
一、环境准备
1.安装Python3
用Pyspark编写文件,自然要用Python的环境,centos7中可以用以下命令安装.
yum install python3
pyspark建议使用Python3.7及以上版本,但是centos7的默认源里边只有3.6,不过做最基本的练习还是够了.
2.安装Pyspark
用pip命令安装.
pip install pyspark==3.2.3
建议版本和自己的spark版本一致
3.测试环境
我这里用的是本地环境测试,没有打开全部集群.

这里就可以写代码了,但是咱们就不再这里写了.
4.提交py任务
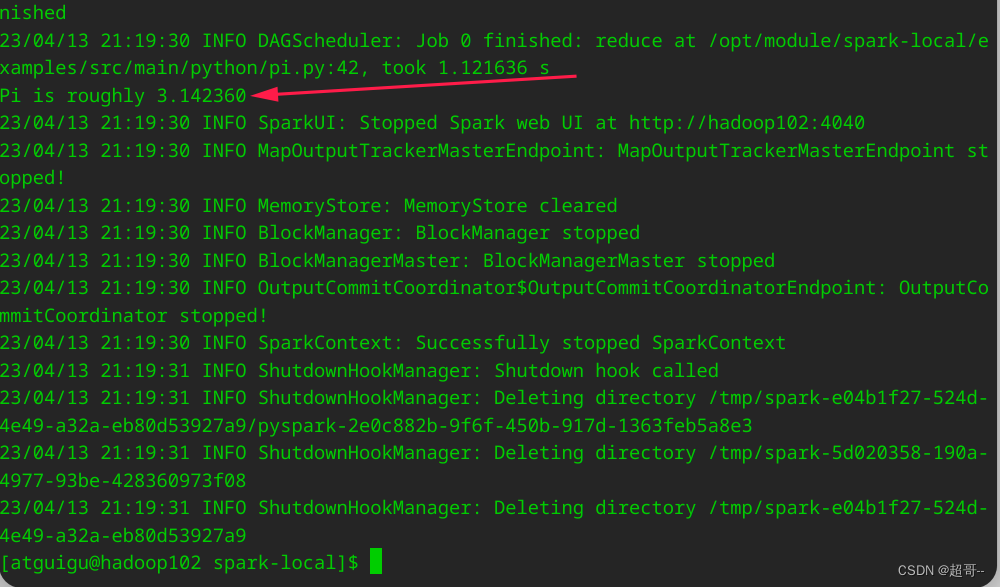
这里我们用官方给的案例进行测试,如果没有问题,我们就可以开始学习了.
./bin/spark-submit examples/src/main/python/pi.py 10
二、编写代码
1.安装库
由于咱们在本地编写和测试文件,所以本地也需要Pyspark,但是不需要spark环境.
pip install pyspark==3.2.3
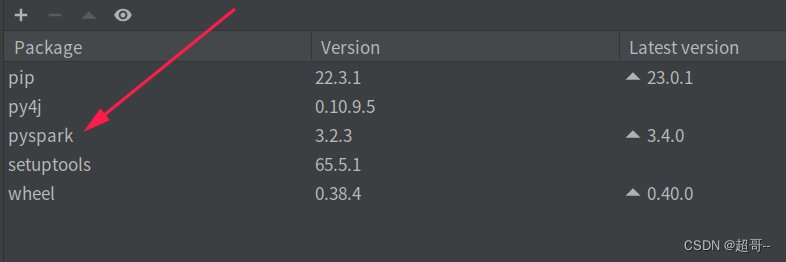
一个全新的虚拟环境
2.core操作
01_WC.py
from pyspark import SparkContext, SparkConf
if __name__ == '__main__':
# 1.创建sparkContext对象
conf = SparkConf().setMaster("local[*]").setAppName("WC")
sc = SparkContext(conf=conf)
# 2.读取文本数据
rdd_init = sc.textFile("/home/atguigu/bigdatas/datas/wc.txt")
# 3.数据切割
flat_map = rdd_init.flatMap(lambda line: line.split(" "))
# 4.数据格式转化
rdd_map = flat_map.map(lambda word: (word, 1))
# 5数据分组求和
res = rdd_map.reduceByKey(lambda a,b:a+b)
# 6.打印输出
print(res.collect())
# 7.关闭输出
sc.stop()
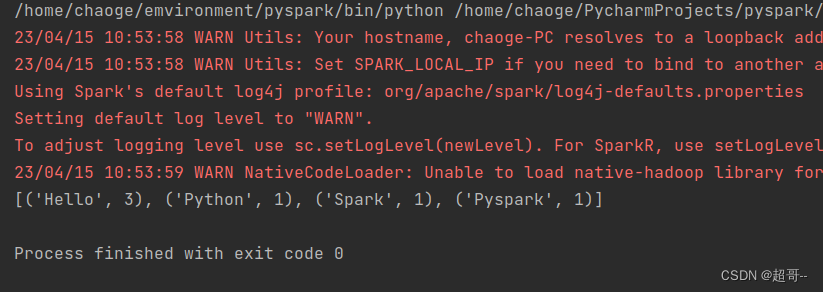
从HDFS中读取文件.
from pyspark import SparkContext, SparkConf
import os
# 模拟集群用户
os.environ["HADOOP_USER_NAME"] = "atguigu"
if __name__ == '__main__':
# 1.创建sparkContext对象
conf = SparkConf().setMaster("local[*]").setAppName("WC")
sc = SparkContext(conf=conf)
# 2.读取文本数据
rdd_init = sc.textFile("hdfs://192.168.10.102/wc.txt")
# 3.数据切割
flat_map = rdd_init.flatMap(lambda line: line.split(" "))
# 4.数据格式转化
rdd_map = flat_map.map(lambda word: (word, 1))
# 5数据分组求和
res = rdd_map.reduceByKey(lambda a, b: a + b)
# 6.输出到HDFS
res.saveAsTextFile("hdfs://192.168.10.102/output1")
# 7.关闭输出
sc.stop()
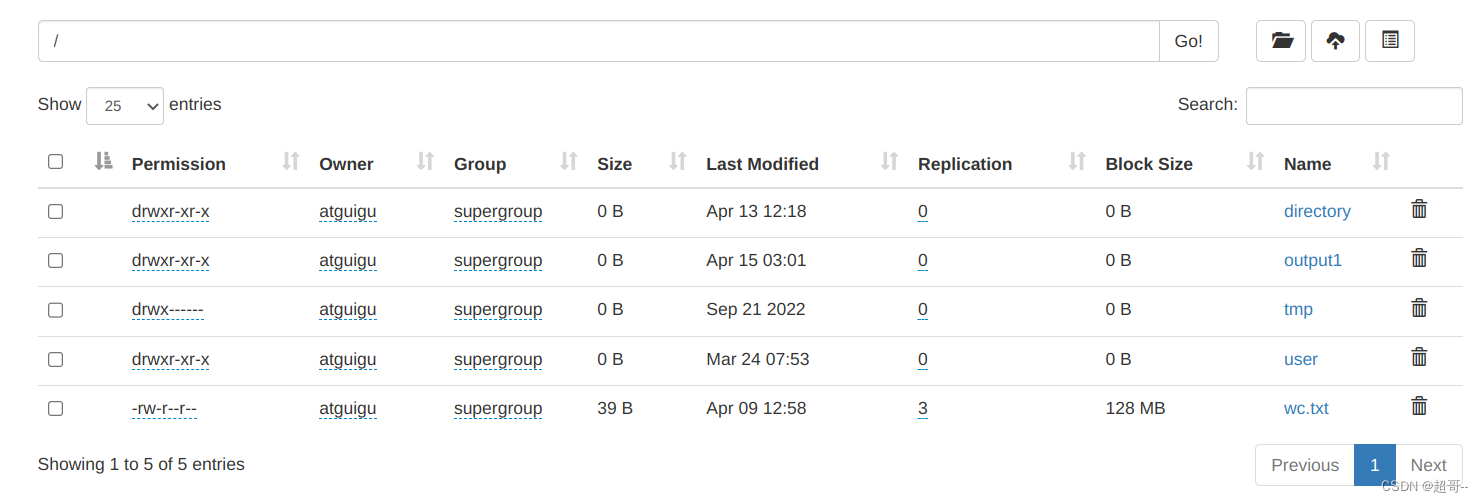
3.SQL操作
01_WC.py
from pyspark import SparkContext, SparkConf
import os
from pyspark.sql import SparkSession
os.environ["HADOOP_USER_NAME"] = "atguigu"
if __name__ == '__main__':
# SparkSQL对象创建
spark = SparkSession.builder.master("local[*]").appName("WC").getOrCreate()
df = spark.read.format("text").load("datas/wc.txt")
df.createTempView("t1")
spark.sql("""
select * from t1
""").show()

成功打印表,可以使用.
02_udf.py
自定义函数
import os
from pyspark.sql import SparkSession
from pyspark.sql.types import *
import pyspark.sql.functions as F
os.environ["HADOOP_USER_NAME"] = "atguigu"
if __name__ == '__main__':
spark = SparkSession.builder.master("local[*]").appName("WC").getOrCreate()
df_init = spark.createDataFrame([(1, "张三", "北京"), (2, "李四", "上海"), (3, "王五", "深圳"), ],
schema="id integer,name String,address String")
df_init.createTempView("t1")
# 自定义函数
def strJoin(str):
return "name is " + str
# 注册自定义函数
strJoin_2 = spark.udf.register("strJoin_1", strJoin, StringType())
# 使用函数
# 方式1
# SQL使用
# spark.sql("""
# select id,strJoin_1(name),address from t1
# """).show()
# DSL使用
# df_init.select(df_init["id"],strJoin_2(df_init["name"]),df_init["address"]).show()
# 方式2
strJoin_3 = F.udf(strJoin, StringType())
# 简写
@F.udf(returnType=StringType())
def strJoin_udf(str):
return "name is " + str
# DSL使用
# df_init.select(df_init["id"],strJoin_3(df_init["name"]),df_init["address"]).show()
df_init.select(df_init["id"],strJoin_udf(df_init["name"]),df_init["address"]).show()
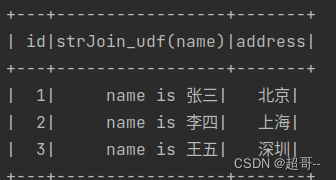
02_udf1.py
import os
from pyspark.sql import SparkSession
from pyspark.sql.types import *
import pyspark.sql.functions as F
os.environ["HADOOP_USER_NAME"] = "atguigu"
if __name__ == '__main__':
spark = SparkSession.builder.master("local[*]").appName("WC").getOrCreate()
df_init = spark.createDataFrame([(1, "张三 北京"), (2, "李四 上海"), (3, "王五 深圳"), ],
schema="id integer,nameANDaddress String")
df_init.createTempView("t1")
def str_split_udf(nameANDaddress: str):
arr = nameANDaddress.split(" ")
return [arr[0], arr[1]]
schema = StructType().add("nn", StringType()).add("ar", StringType())
str_split_udf_D = spark.udf.register("str_split_udf", str_split_udf, returnType=schema)
# spark.sql("select id,str_split_udf(nameANDaddress).nn ,str_split_udf(nameANDaddress).ar from t1").show()
df_init.select("id",str_split_udf_D("nameANDaddress")["nn"]).show()
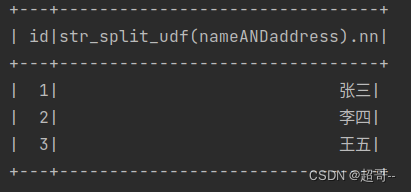
连接hive
这里要先修改一下hive-site.xml文件
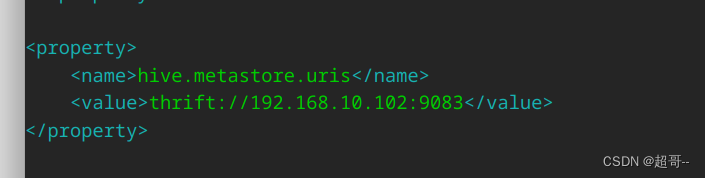
增加远程连接接口,如果集群需要连接hive,将这个文件扔到spark的conf目录.
03_hive.py
from pyspark.sql import SparkSession
if __name__ == '__main__':
spark = SparkSession.builder.appName("hive")\
.config("hive.metastore.uris", "thrift://192.168.10.102:9083")\
.config("spark.sql.warehouse.dir", "hdfs://192.168.10.102:8020/usr/hive/warehouse")\
.enableHiveSupport()\
.getOrCreate()
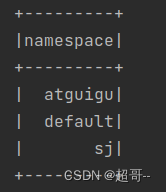
spark.sql("show databases").show()
然后启动hive,运行程序.
4.Streaming操作
01_WC.py
from pyspark import SparkConf, SparkContext
from pyspark.streaming import StreamingContext
if __name__ == '__main__':
# 1.创建sparkContext对象
conf = SparkConf().setMaster("local[*]").setAppName("WC")
sc = SparkContext(conf=conf)
ssc = StreamingContext(sc, 5)
lines = ssc.socketTextStream("127.0.0.1", 9999)
result = lines.flatMap(lambda line: line.split(" ")) \
.map(lambda word: (word, 1)) \
.reduceByKey(lambda a, b: a + b)
result.pprint()
ssc.start()
ssc.awaitTermination()

总结
由于咱们之前用scala做过很多案例,所以这利用Python就不写了,只完成最基本的操作即可.