一、AutoGPT是什么
最近几天,一款基于GPT-4的最强语言模型AutoGPT火遍了整个AI圈。众所周知,此前爆火AI圈的ChatGPT,唯一不太好用的地方就是需要人类不断的prompt。因此,如果你想要ChatGPT帮你去做一件复杂的事情,那么怎么提问时一件很麻烦的事情。但AutoGPT就不一样,他会根据你提的目标来制定计划,然后自己执行完整个计划,整个过程自动化的能力非常的强。
这里简单的介绍下AI的prompt,prompt是指在使用AI模型时,设计和构建用于输入的文本提示,使得模型能够更好地理解和回答问题。简单来说,就是为AI模型设置一个更容易理解和明确的问题描述,以便让它更好地进行回答。
事实上,作为目前最实用的AI技术,AutoGPT在短短几天时间就在GitHub上获得了惊人star数目前已经突破81k,并吸引了无数开源社区和开发者的关注。
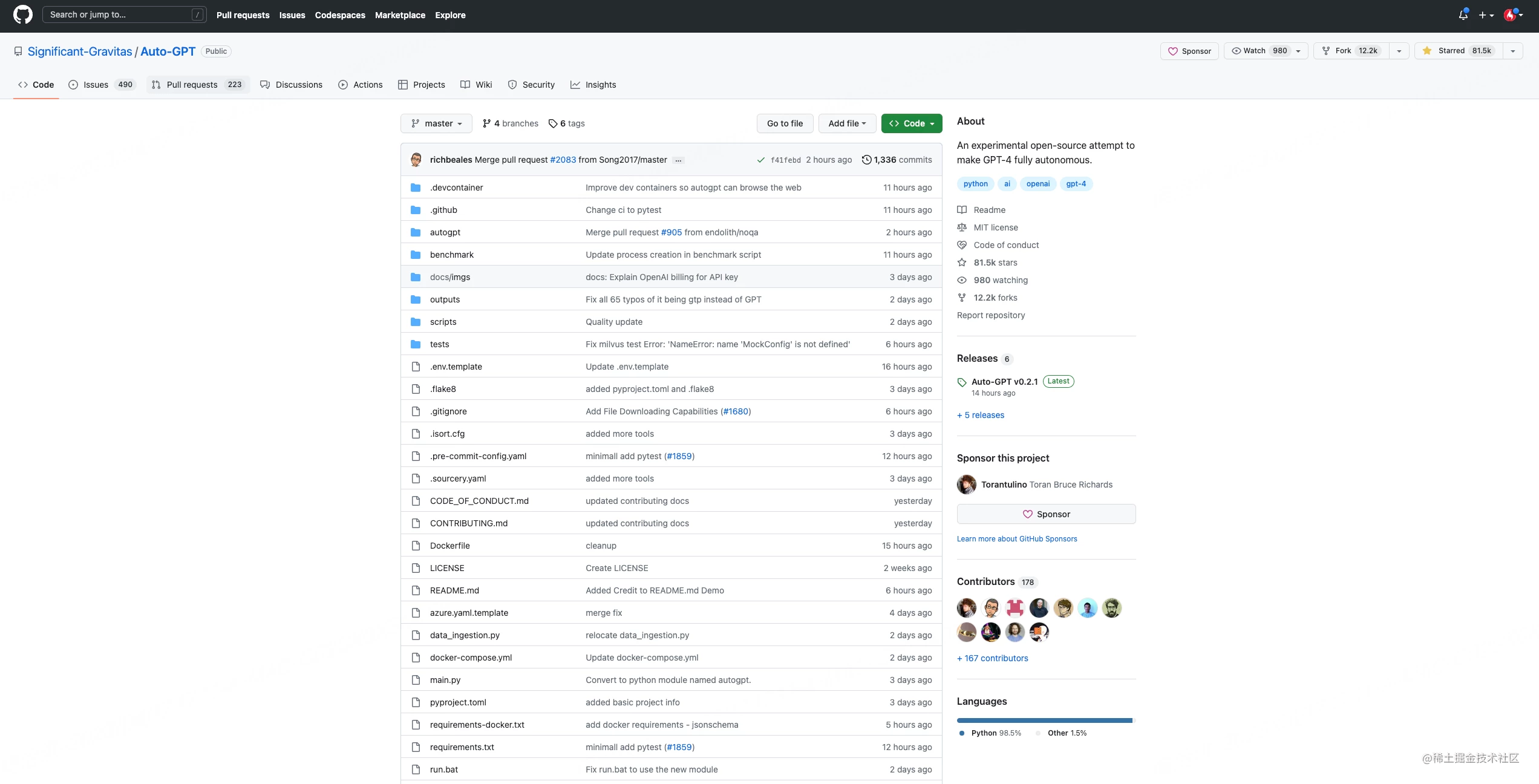
AutoGPT到底有多火呢,看这张网友做的对比图就知道了:仅仅几天的时间,它就追平了某个红极一时项目差不多积攒了10年的star。
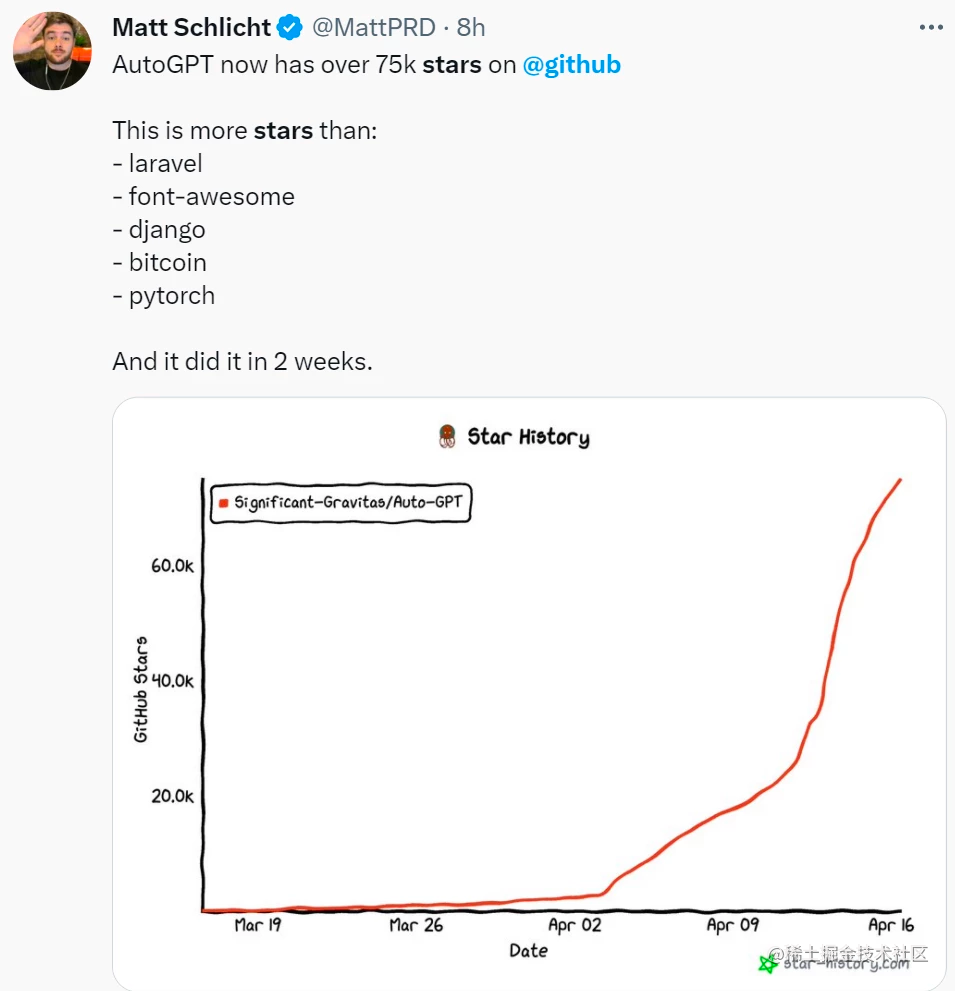
虽然,GitHub Star 数不足以说明一切,但是从此图中便能看出近期大众对它的关注程度。截止今日,Star 数更是已突破 8 万,并且正朝着 10 万 Star 里程碑稳步迈进。
之所以能这么火,是因为Auto-GPT 突破了 AI 的可能性界限。事实上,它能根据开发者给它下达的任务,自行编写爬虫,检索互联网上的公开信息,用于实现任务,优化代码、自动改 Bug 等。这也就意味着,这是一个真正懂得通过自主学习,利用编程来强化自己能力的智能代码工具,也是自GPT-4 出现以来,技术圈中又一款重磅级AI产品。
二、AutoGPT缺点
事实上,AutoGPT的使用是非常简单的,大家可以看着github上的教程很轻易的就搭起来。然后提供从open ai申请的api key即可,因为它也是基于GPT3.5或者GPT4的模型来帮我们完成任务的。因为会非常多次的调用API,所以在它执行任务的时候,我闻到了一股RMB在燃烧的味道。
虽然,AutoGpt相比传统的AI技术进步了一大截,但正如Jina AI 的创始人兼 CEO 肖涵表示:“在我们庆祝 Auto-GPT 的快速崛起时,退后一步并仔细检查其潜在的缺点至关重要。”并且,为了说明Auto-GPT 的不足之处,肖涵先大致分析了一波原理,即 Auto-GPT 主要由四部分组成:
- 架构:Auto-GPT 是基于强大的 GPT-4和 GPT-3.5语言模型构建的,它们作为机器人的大脑,帮助它思考和推理。
- 自主迭代:类似于机器人,具有从错误中学习的能力。Auto-GPT 可以回顾其工作,在之前的工作基础上再接再厉,并利用其历史记录生成更准确的结果。
- 内存管理:与矢量数据库(一种内存存储解决方案)集成,使 Auto-GPT 能够保留上下文并做出更好的决策,类似于为机器人配备长期记忆以记住过去的经历。
- 多功能性:Auto-GPT 的功能(例如文件操作、Web 浏览和数据检索)使其用途广泛,并使其与有别于以往的 AI 迭代,就像赋予机器人多种技能来处理更广泛的任务。
下面我们来看下AutoGpt的一些缺点:
1,成本高昂
虽然 Auto-GPT 具有卓越的功能,但由于任务是通过思维链完成的,为提供更好的推理和提示,每一步都需要调用昂贵的 GPT-4模型,这通常会最大化 token,也就带来了过高的成本。
对此,肖涵估算了一个小任务的花费:Auto-GPT 平均需要50个步骤来完成一个小任务,即成本为50*0.288=14.4美元(约人民币98.5元)。
而且这还是一次就能出结果的情况,如果需要重新生成,成本会更高。 从这个角度来看,AutoGPT目前对大部分用户和组织来说,都是不现实的。
2,容易陷入死循环
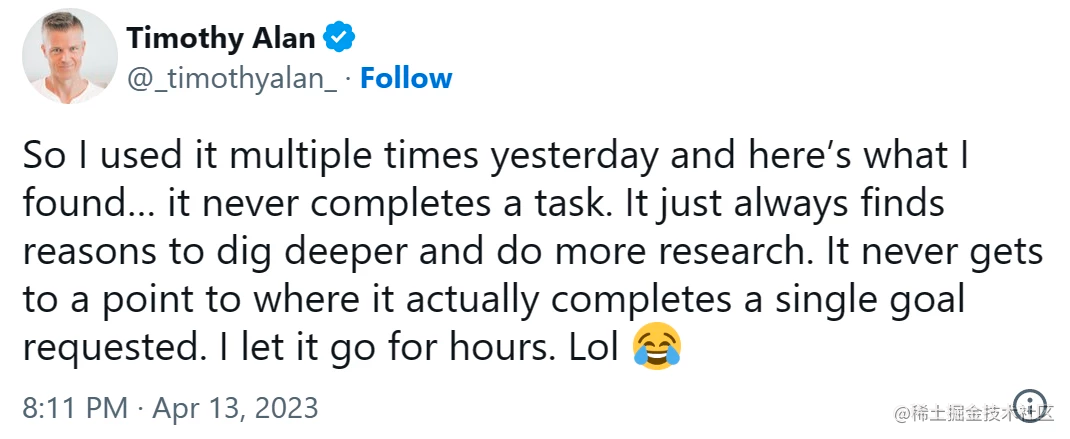
更要命的是,这14.4美元还可能“打水漂”。许多用户报告说:Auto-GPT 经常陷入循环,导致其无法解决实际问题。
“我昨天多次使用它,我发现…它从未完成过一项任务。它总是去深入挖掘、做更多的研究,但从来没有真正完成一个目标。我就放着让它持续循环了几个小时。”
3,代理机制不完善
Auto-GPT 引入了一个很有趣的概念,即允许生成代理来委派任务。然而,肖涵认为这还不够完善:“这一机制仍处于早期阶段,其潜力在很大程度上仍未得到开发。”
对于以上总结的几点 Auto-GPT 缺陷,实际上早有不少用户在抱怨,还搞出了一些“闹剧”:
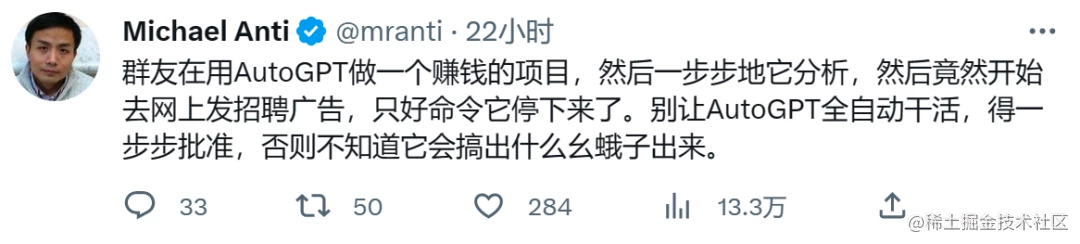
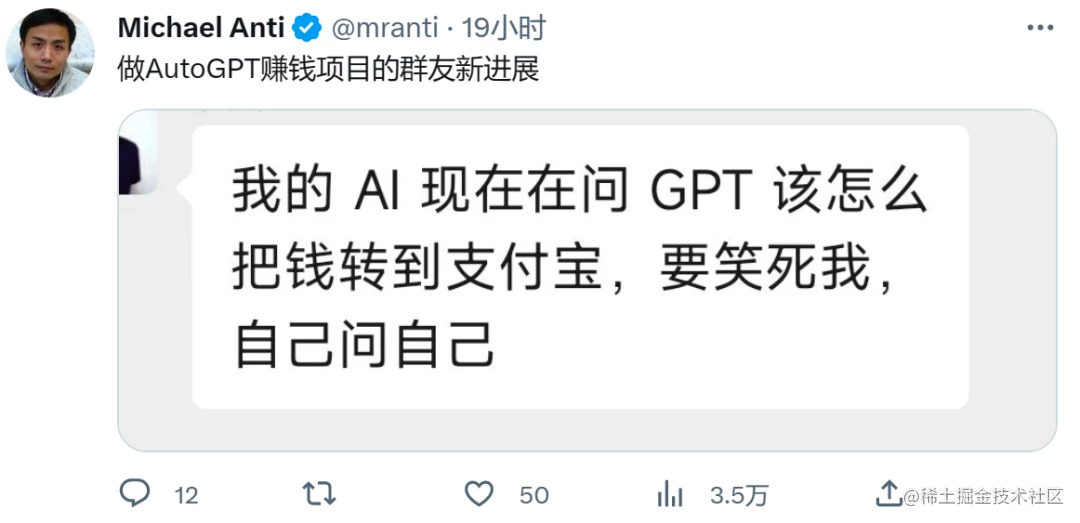
不过即便如此,Auto-GPT 还是令许多人对未来 AI 的发展趋势充满期待:
三、AutoGPT本地部署
接下来,我们看一下如何在本地部署AutoGpt,参考如下资料:
Auto-GPT 官网网站:https://github.com/torantulino/auto-gpt
Auto-GPT 中文技术支持博客:https://www.cnblogs.com/botai/
3.1 环境要求
- vscode + devcontainer
- Python 3.8 or later
- OpenAI API key
- PINECONE API key
- ElevenLabs Key(可选)
3.2 安装
1,确保您的本地环境已经拥有上述所有要求,如果没有,请安装/获取它们。
2,将AutoGPT克隆到本地,也可以直接下载源码的zip文件。
git clone git@github.com:Significant-Gravitas/Auto-GPT.git
3,导航至项目目录,安装所需依赖项,命令如下。
pip install -r requirements.txt
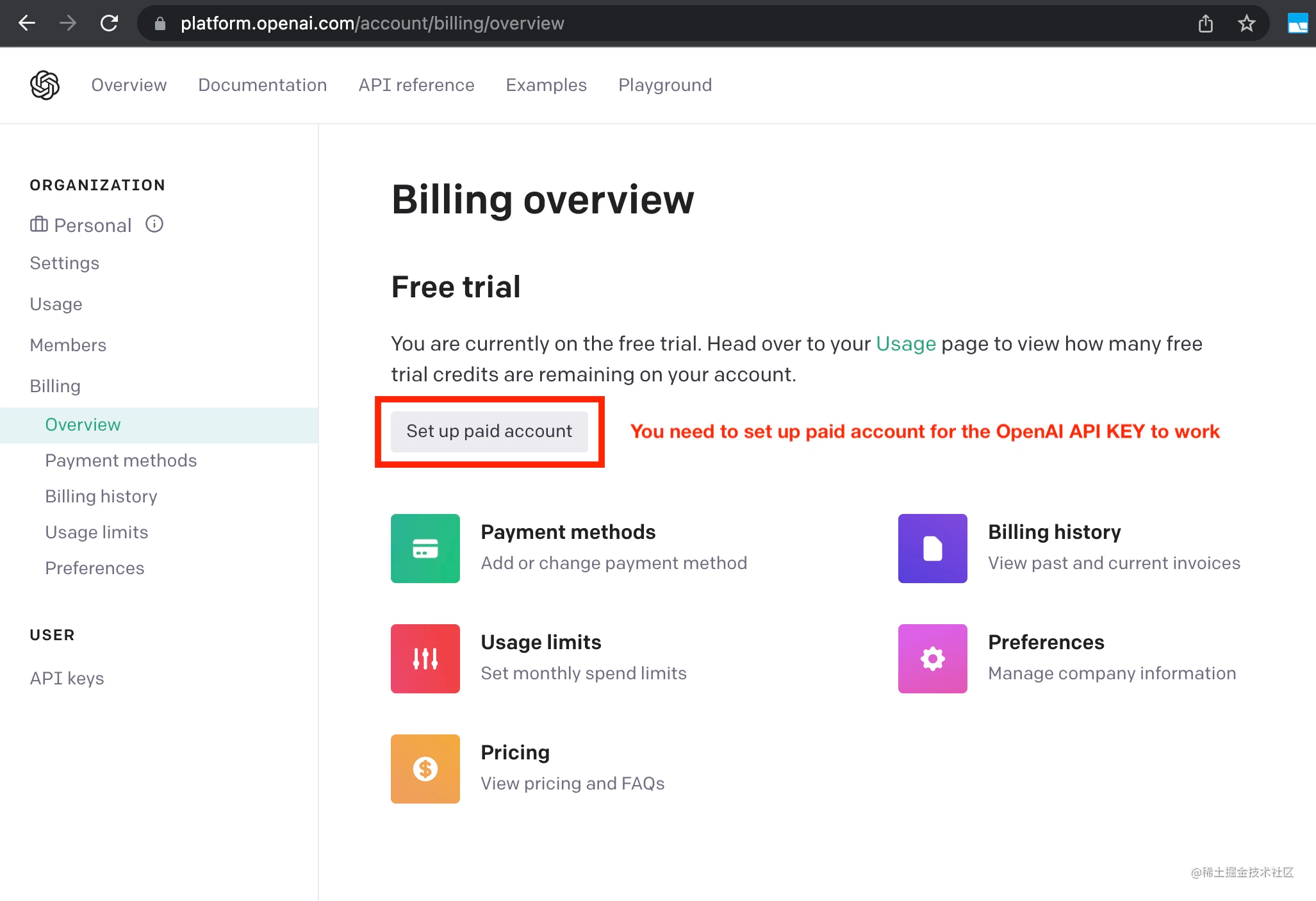
4,重命名.env.template为.env,并填写你从openai官网获取的的OPENAI_API_KEY。如果你计划使用语音模式,请同时填写你的ELEVEN_LABS_API_KEY。以下是一些说明:
- 以下网址获取你的OpenAI API密钥:https://platform.openai.com/account/api-keys。
- 以下网址获取你的ElevenLabs API密钥:https://elevenlabs.io。 你可以在网站上的“Profile”选项卡中查看你的xi-api-key。
如果你想在Azure实例上使用GPT,请将USE_AZURE设置为True,然后将azure.yaml.template重命名为azure.yaml,并在azure_model_map部分中提供相关模型的azure_api_base、azure_api_version和所有部署ID:
- fast_llm_model_deployment_id:你的gpt-3.5-turbo或gpt-4部署ID
- smart_llm_model_deployment_id: 你的gpt-4部署ID
- embedding_model_deployment_id: 你的text-embedding-ada-002 v2部署ID
更多详细的信息,请点击下面的链接查看详情:https://pypi.org/project/openai/, 位于“Microsoft Azure Endpoints”部分和此处:https://learn.microsoft.com/en-us/azure/cognitive-services/openai/tutorials/embeddings?tabs=command-line, 用于嵌入模型。
3.3 基本使用
打开AutoGpt项目的源码,然后在你的终端中运行main.py的Python脚本,命令如下。
python -m autogpt
在每个AUTO-GPT操作完成后,输入"NEXT COMMAND"来授权它们继续执行。如果需要退出程序,请键入"exit"并按回车键。.

3.4.1 开启日志
当然,你也可以通过在文件夹./output/logs中找到活动和错误日志。 要开启要输出调试日志,可以使用下面的命令:
python scripts/main.py --debug
3.4.2 Docker
当然,我们也可以将它构建到docker映像中然后运行它。
docker build -t autogpt .
docker run -it --env-file=./.env -v $PWD/auto_gpt_workspace:/app/auto_gpt_workspace autogpt
如果你有docker-compose环境,也可以使用下面的方式:
docker-compose run --build --rm auto-gpt
当然,我们也可以在运行的时候指定运行的ChatGpt的版本例如,在gpt3only和continuous模式下运行:
docker run -it --env-file=./.env -v $PWD/auto_gpt_workspace:/app/auto_gpt_workspace autogpt --gpt3only --continuous
docker-compose run --build --rm auto-gpt --gpt3only --continuous
3.4.3 其他参数
下面是运行AutoGPT时,可以使用的一些常见参数和帮助说明:
查看所有有用的命令行参数:
python -m autogpt --help
使用不同的AI设置文件运行AutoGPT:
python -m autogpt --ai-settings <filename>
指定可用内存大下:
python -m autogpt --use-memory <memory-backend>
3.4 语言模式
如果要开启语言模式,可以在启动项目的时候使用下面的命令:
python scripts/main.py --speak
下面是用于实验的一些eleven labs账号:
- Rachel : 21m00Tcm4TlvDq8ikWAM
- Domi : AZnzlk1XvdvUeBnXmlld
- Bella : EXAVITQu4vr4xnSDxMaL
- Antoni : ErXwobaYiN019PkySvjV
- Elli : MF3mGyEYCl7XYWbV9V6O
- Josh : TxGEqnHWrfWFTfGW9XjX
- Arnold : VR6AewLTigWG4xSOukaG
- Adam : pNInz6obpgDQGcFmaJgB
- Sam : yoZ06aMxZJJ28mfd3POQ
3.5 Google API Keys
本部分是可选的,如果在运行Google搜索时出现错误429,则使用官方Google API。要使用 google_official_search 命令,您需要在环境变量中设置Google API密钥。
- 前往 Google Cloud Console。
- 如果您还没有帐户,请创建一个并登录。
- 通过单击页面顶部的“Select a Project”下拉菜单,然后单击“New Project”,创建一个新项目。给它一个名称并单击“Create”。
- 前往 APIs & Services Dashboard,单击“Enable APIs and Services”。搜索“Custom Search API”,单击它,然后单击“Enable”。
- 前往 Credentials 页面,然后单击“Create Credentials”。选择“API Key”。
- 复制API密钥并将其设置为在您的计算机上命名为
GOOGLE_API_KEY的环境变量。请查看下面的环境变量设置。 - 在您的项目上 启用 Custom Search API。(可能需要等待几分钟以进行传播)
- 前往 Custom Search Engine 页面,然后单击“Add”。
- 按照提示设置您的搜索引擎以设置搜索引擎。您可以选择搜索整个Web或特定站点。
- 创建您的搜索引擎后,单击“Control Panel”,然后单击“Basics”。复制“Search engine ID”,并将其设置为在您的计算机上命名为
CUSTOM_SEARCH_ENGINE_ID的环境变量。请查看下面的环境变量设置。
需要注意的是,您的每日免费自定义搜索配额仅允许最多100次搜索。要增加此限制,您需要将计费帐户分配给项目,以从每日最多10K次搜索中受益。
3.5.1 设置环境变量
对于Windows用户来说,设置环境变量的代码如下:
setx GOOGLE_API_KEY "YOUR_GOOGLE_API_KEY"
setx CUSTOM_SEARCH_ENGINE_ID "YOUR_CUSTOM_SEARCH_ENGINE_ID"
对于MacOs的用户来说,设置环境变量的代码如下:
export GOOGLE_API_KEY="YOUR_GOOGLE_API_KEY"
export CUSTOM_SEARCH_ENGINE_ID="YOUR_CUSTOM_SEARCH_ENGINE_ID"
3.6 Redis设置
首先,需要安装 Docker Desktop,如果还没安装,请参考3.4.2进行安装。然后运行如下命令设置redis。
docker run -d --name redis-stack-server -p 6379:6379 redis/redis-stack-server:latest
参见 https://hub.docker.com/r/redis/redis-stack-server 以设置密码和其他配置。然后,配置Redis。
MEMORY_BACKEND=redis
REDIS_HOST=localhost
REDIS_PORT=6379
REDIS_PASSWORD=
请注意,这不是面向互联网运行的,不安全,请不要在没有密码或没有任何保护的情况下将 Redis 暴露给互联网。
3.7 Pinecone API 密钥设置
- 转到pinecone,如果您还没有帐户,请注册一个。
- 选择“Starter”计划以避免收费。
- 在左侧边栏的默认项目下找到您的API密钥和区域。
接下来,我们需要设置环境变量:
打开.env 文件或者从命令行中设置它们(高级):
对于 Windows 用户:
setx PINECONE_API_KEY "YOUR_PINECONE_API_KEY"
setx PINECONE_ENV "Your pinecone region" # something like: us-east4-gcp
对于 macOS 和 Linux 用户:
export PINECONE_API_KEY="YOUR_PINECONE_API_KEY"
export PINECONE_ENV="Your pinecone region" # something like: us-east4-gcp
3.8 设置缓存类型
默认情况下,AutoGPT 使用的是LocalCache 而不是 redis 或 Pinecone。要切换到其中一个,请将 MEMORY_BACKEND 环境变量更改为所需的值:
- local (默认):使用本地 JSON 缓存文件
- pinecone:使用您在 ENV 设置中配置的 Pinecone.io 帐户
- redis:将使用您配置的 redis 缓存
- milvus:将使用您配置的Milvus缓存
- weaviate:将使用您配置的Weaviate缓存
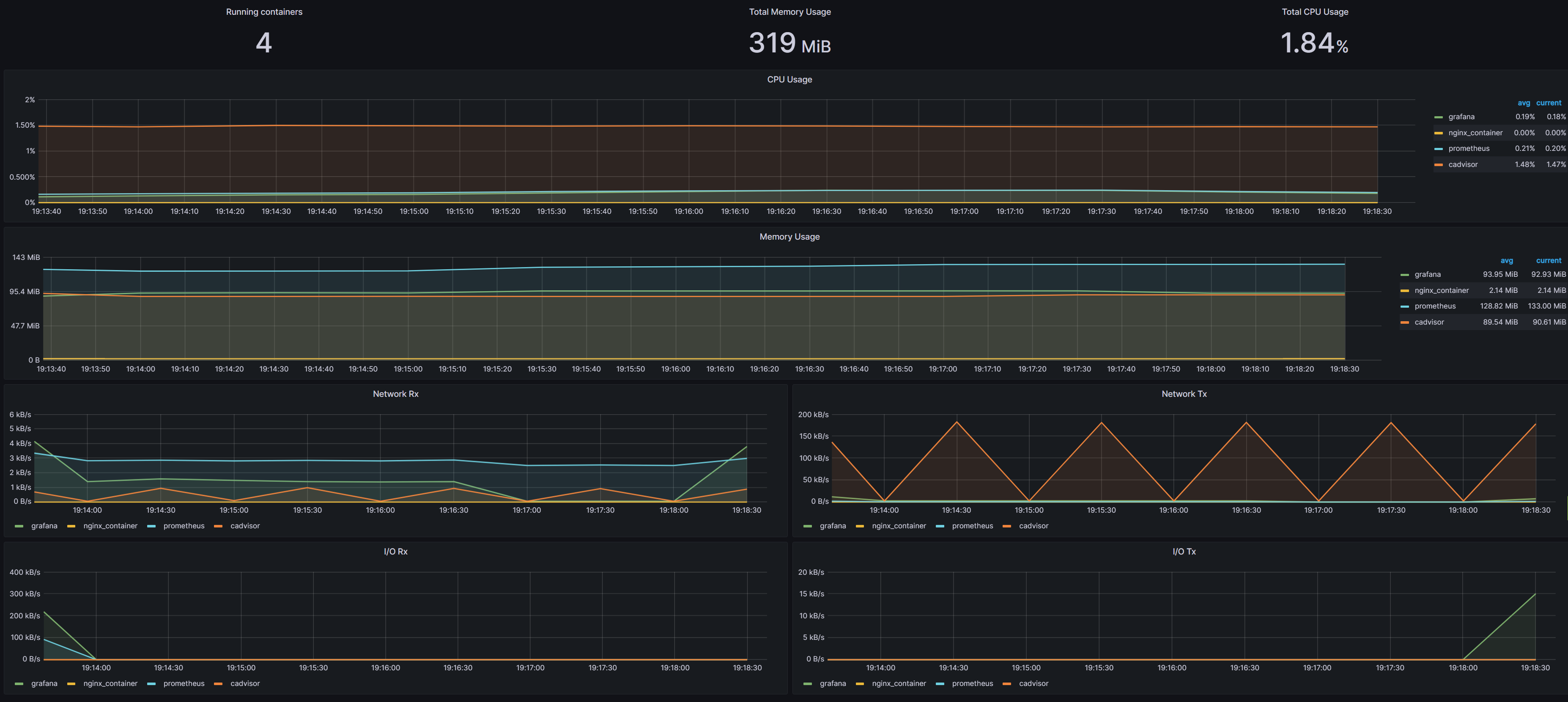
查看内存使用情况,命令如下:使用 --debug 标志查看内存使用情况。
3.9 持续模式💀
以无需用户授权的方式运行 AI,100%自动化。不建议使用持续模式。它可能会造成潜在危险,并可能导致您的 AI 永远运行或执行您通常不会授权的操作。请自行承担风险。
python scripts/main.py --continuous
要退出程序,请按 Ctrl + C。
3.10 GPT3.5 模式
如果您没有访问 GPT4 api 的权限,则此模式将允许您使用 AutoGPT,运行的命令如下:
python scripts/main.py --gpt3only
3.11 图像模式
默认情况下,Auto-GPT 使用 DALL-e 进行图像生成。要使用 Stable Diffusion,需要HuggingFace API Token。获得令牌后,请在 .env 中设置以下变量:
IMAGE_PROVIDER=sd
HUGGINGFACE_API_TOKEN="YOUR_HUGGINGFACE_API_TOKEN"
🛡 免责声明
Auto-GPT 是一个实验性的应用程序,提供“按原样”不附带任何明示或暗示的保证。使用此软件即表示您同意承担与其使用相关的所有风险,包括但不限于数据丢失、系统故障或任何可能出现的问题。
该项目的开发人员和贡献者不承担任何损失、损害或其他后果的责任或义务,这些损失、损害或其他后果可能是使用该软件的结果。您应根据 Auto-GPT 提供的信息对任何决策和行动负责。
请注意,由于 GPT-4 语言模型的令牌使用情况,使用成本可能很高。 通过使用此项目,您确认您有责任监控和管理自己的令牌使用情况和相关费用。强烈建议定期检查您的 OpenAI API 使用情况,并设置任何必要的限制或警报以防止意外收费。
作为一个自主实验,Auto-GPT 可能会生成与实际商业实践或法律要求不符的内容或采取行动。您有责任确保基于此软件的输出所做的任何行动或决策符合所有适用的法律、法规和道德标准。该项目的开发人员和贡献者不承担因使用该软件而产生的任何后果的责任。
通过使用 Auto-GPT,您同意赔偿、捍卫并使开发人员、贡献者和任何关联方免受您使用此软件或违反这些条款所引起的任何和所有索赔、损害、损失、负债、费用和支出(包括合理的律师费)。
参考链接:https://github.com/Significant-Gravitas/Auto-GPT