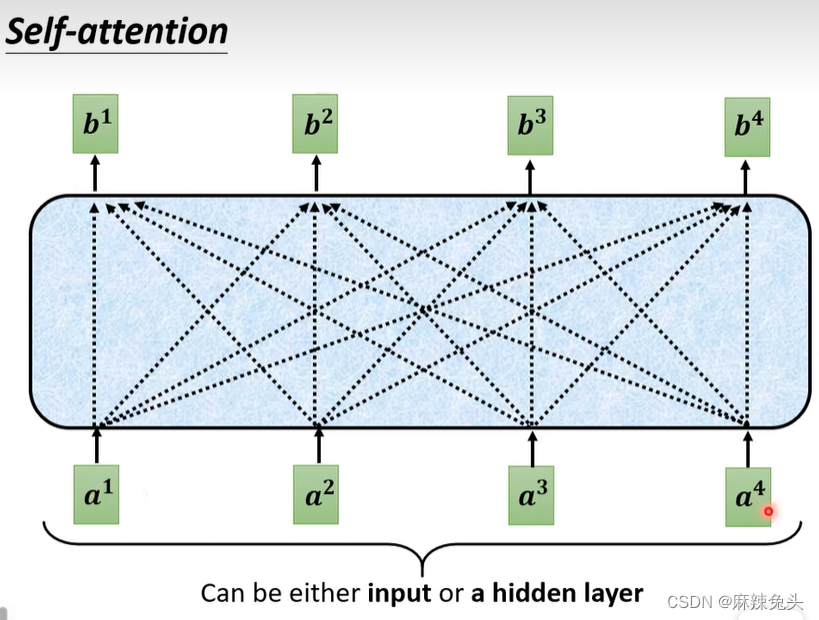
self-attention想要解决的问题
复杂的输入
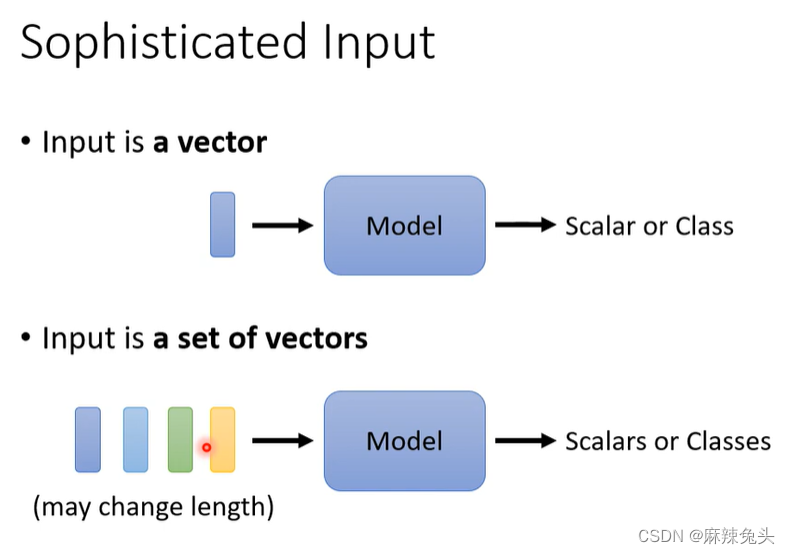
每次输入的length不同时,即Vector Set大小不同,该如何处理?
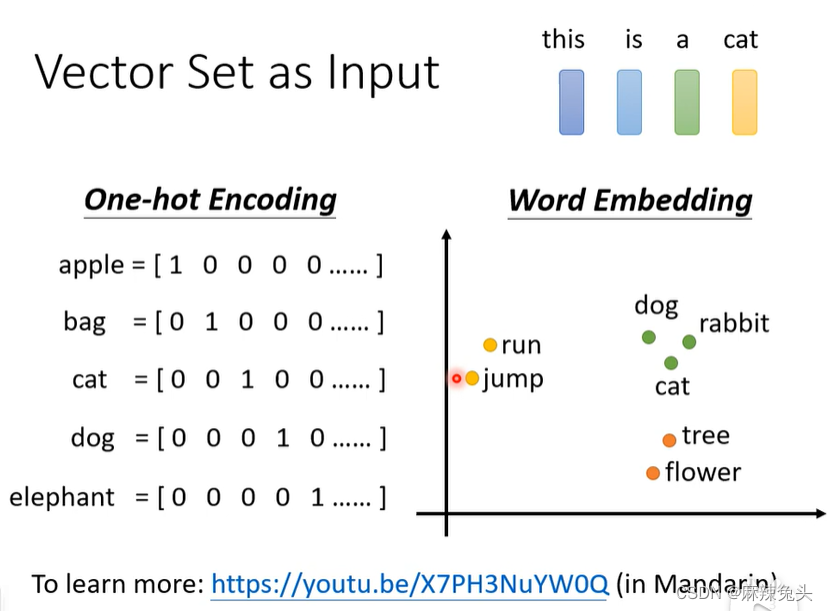
one-hot encoding,缺点:所有的词汇之间没有语义资讯。
word embedding,会给每一个词汇一个向量,一个句子则是一排长度不一
的向量,具有语义资讯。
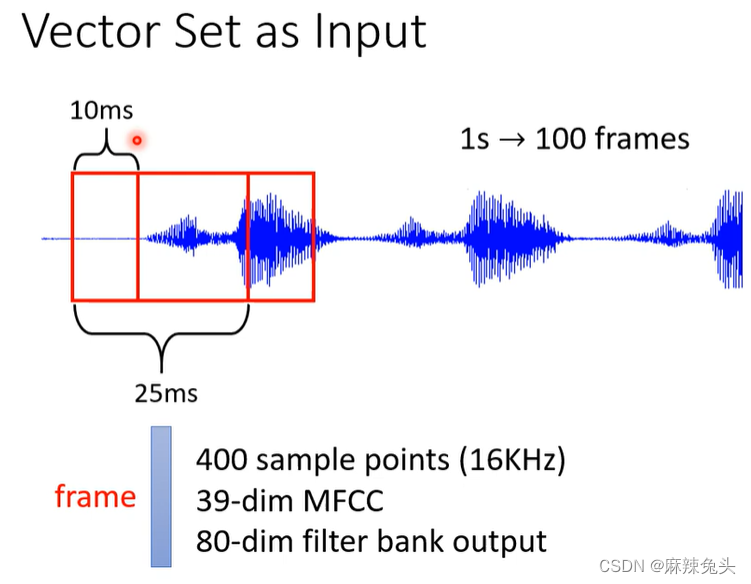
1min便有6000个frame
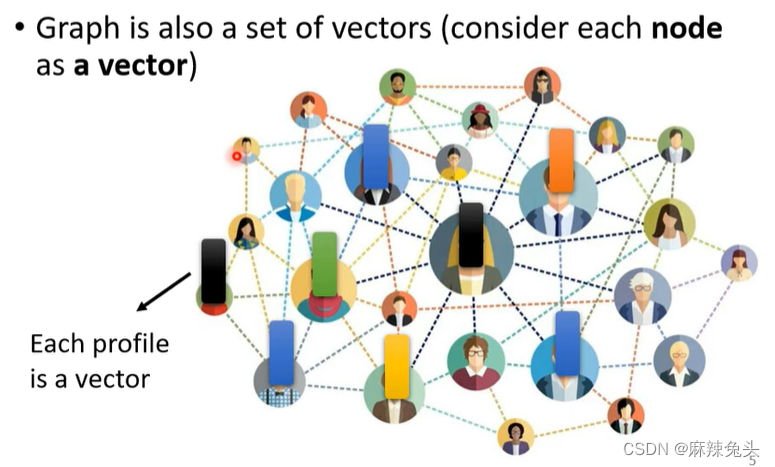

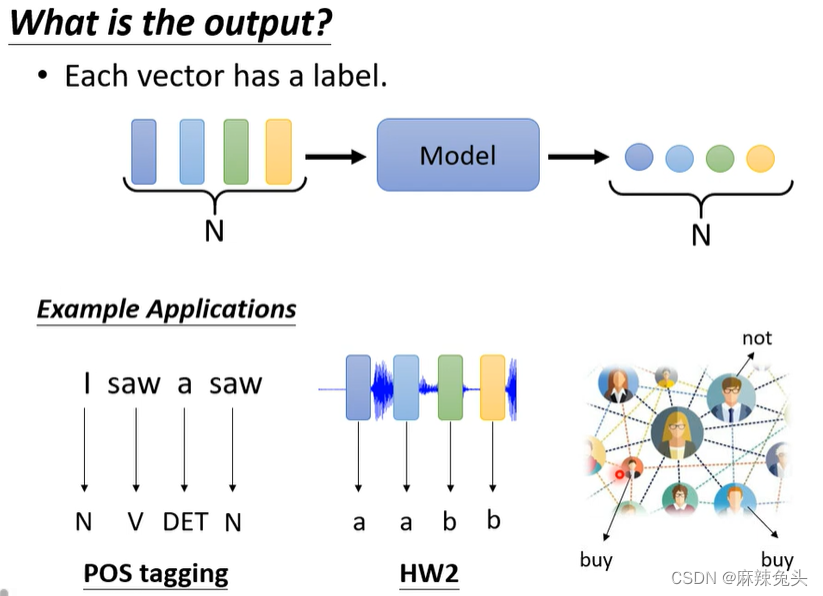
输出是什么?
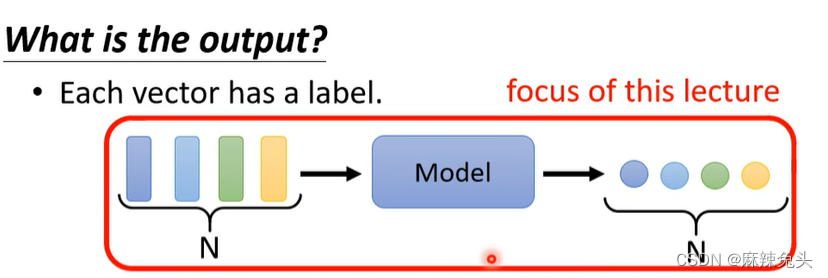
(1)Each vector has a label
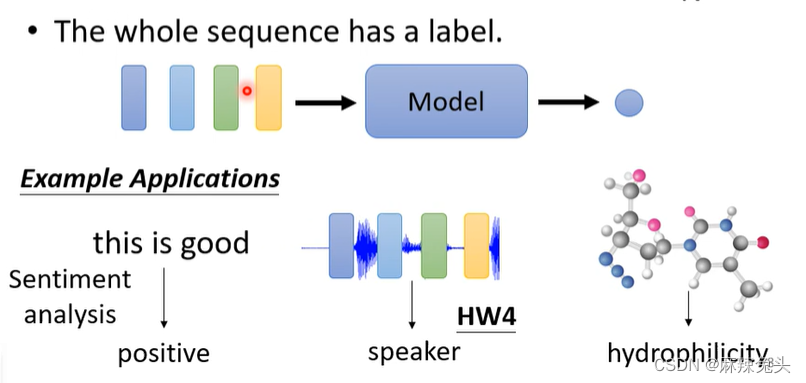
(2)The whole sequence has a label
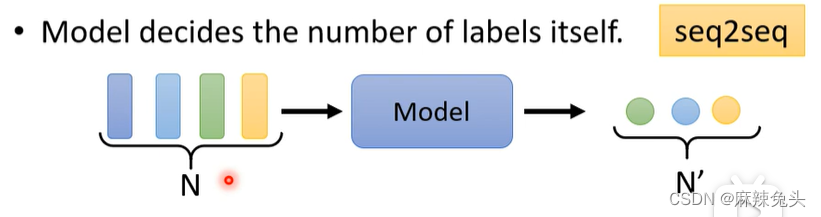
(3)Model decides the number of labels itself
Sequence Labeling
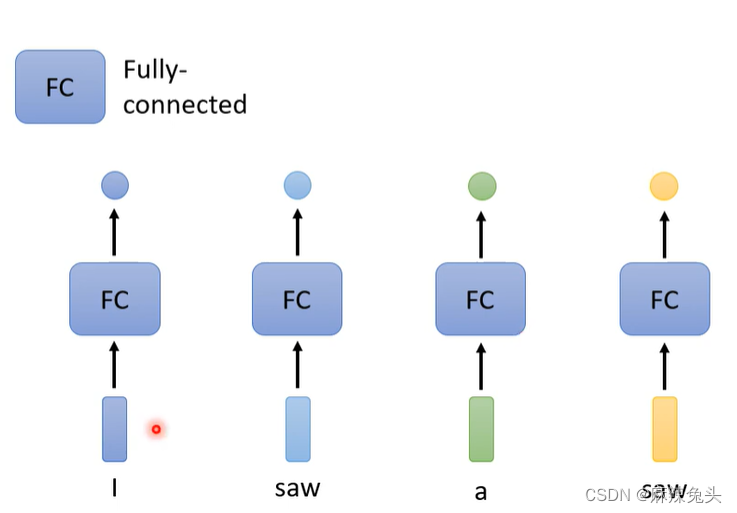
使用fc缺点:假设是词性标记,则无法正确识别。
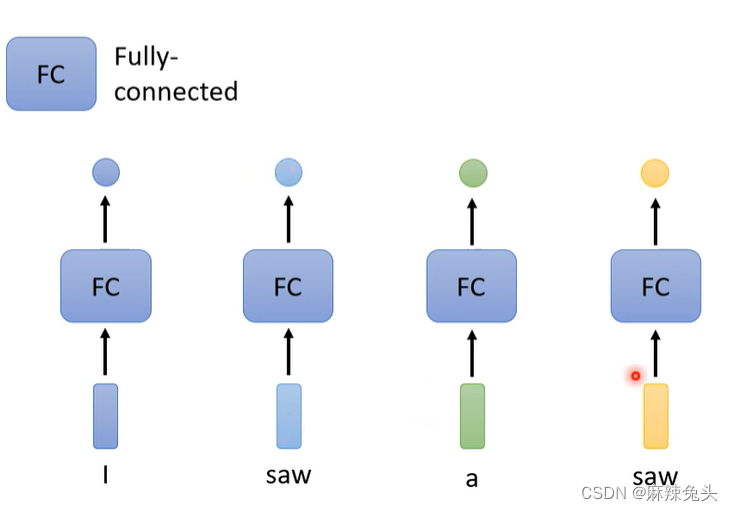
It is possible to consider the context?
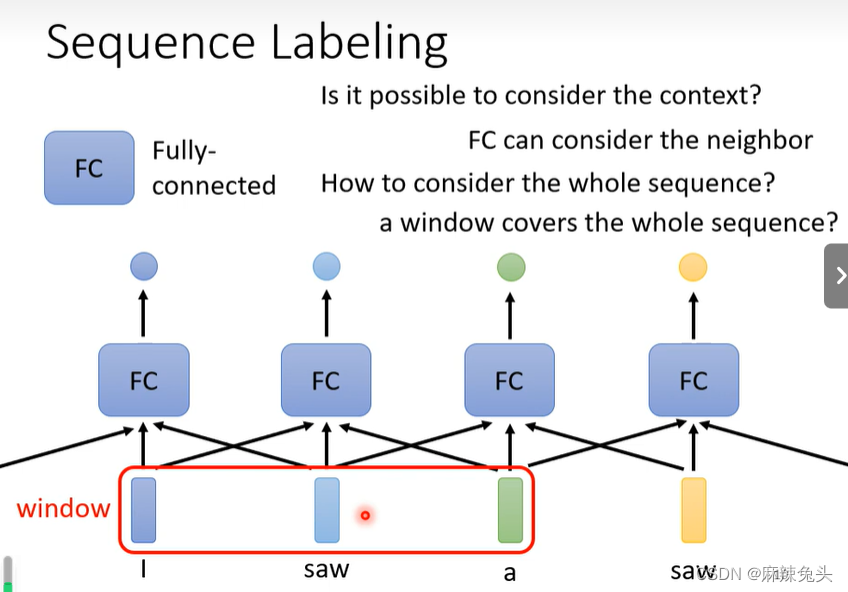
a window covers the whole sequence?
sequence长度有长有短,首先我们需要统计训练资料,查看一下最长的sequence有多长,然后开一个window(大于最长的sequence),这就会导致fc所需参数多,运算量大,容易overfitting。
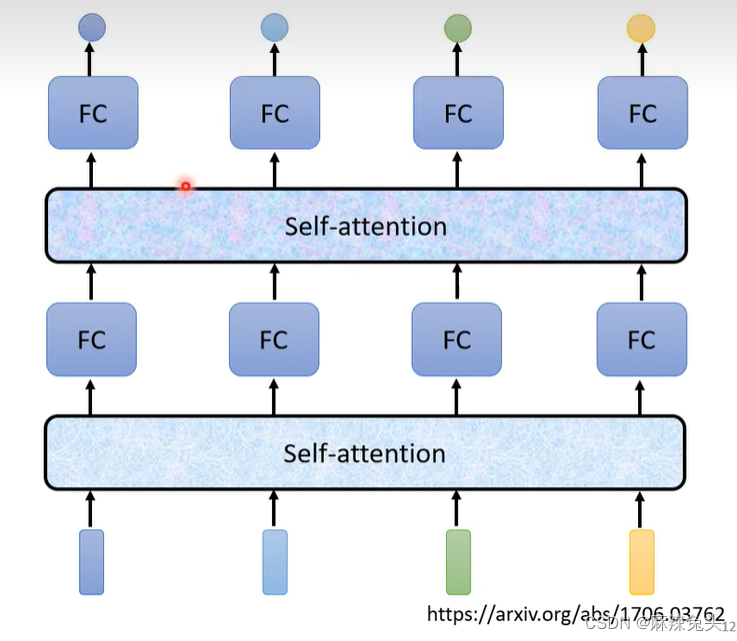
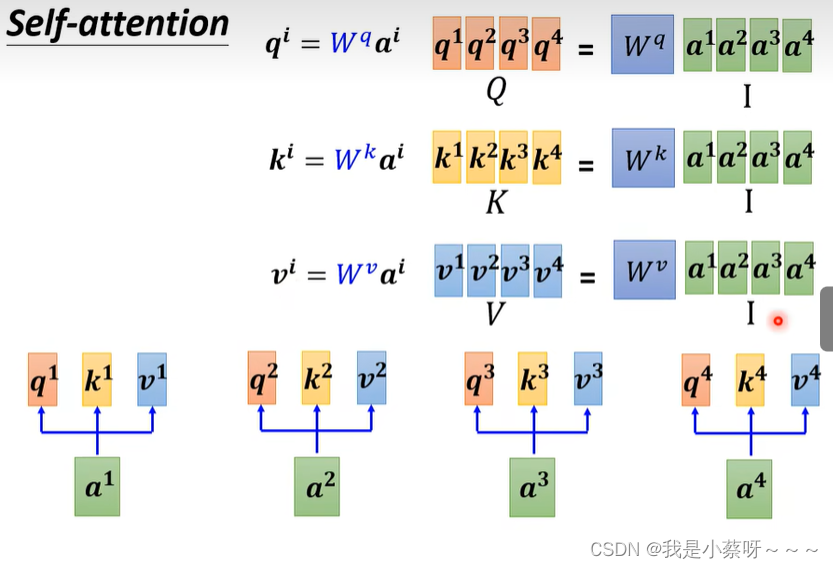
所以使用self-attention:
知名paper:Attention is all you need.
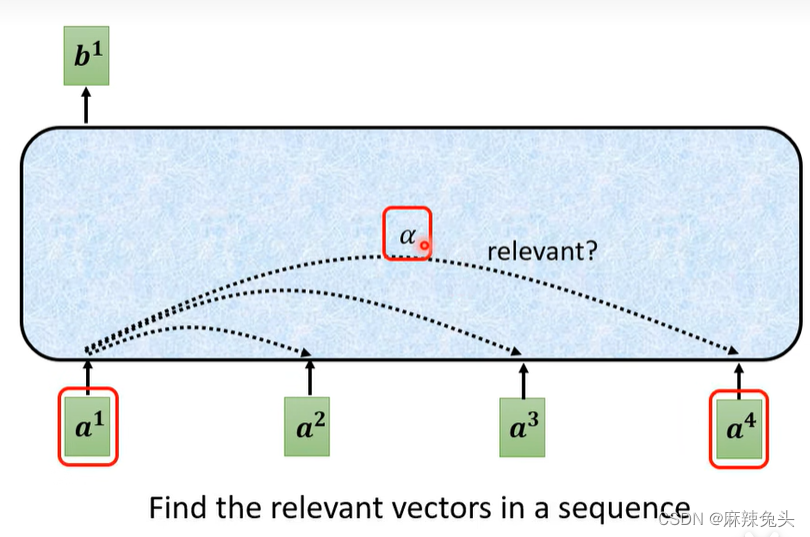
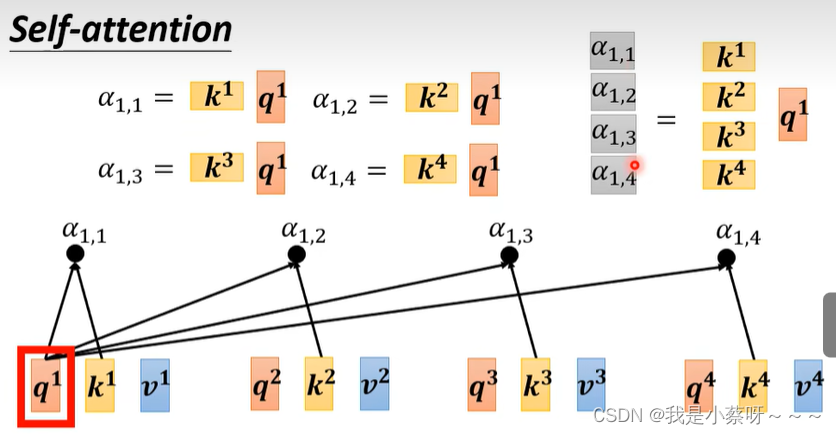
如何计算‘阿尔法’数值:
(1)Dot-product——常用
(2)Additive
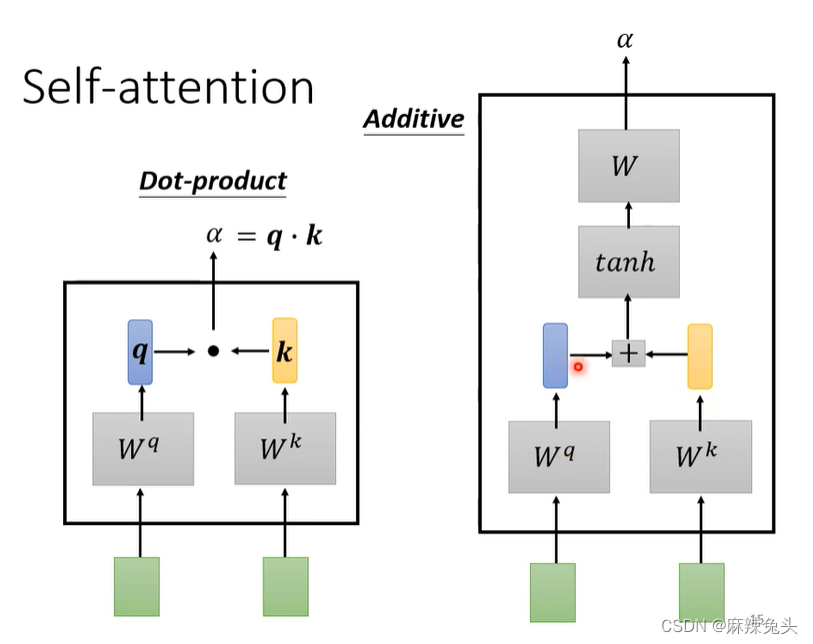
Dot-product
w先随机生成,后通过梯度下降训练得出。
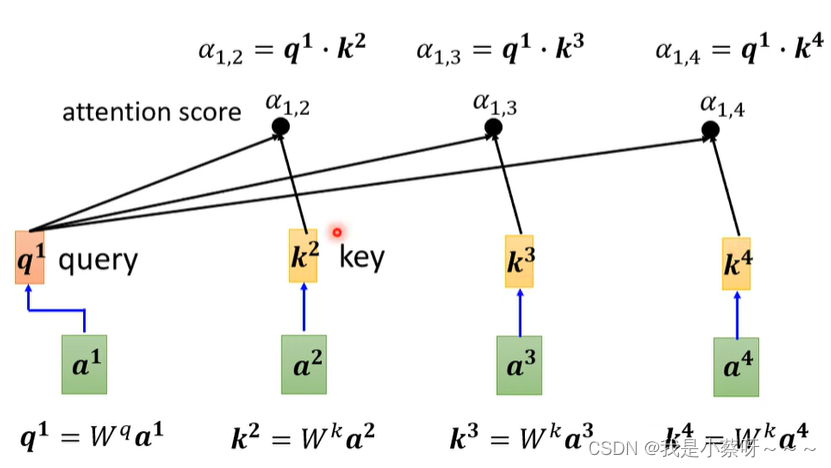
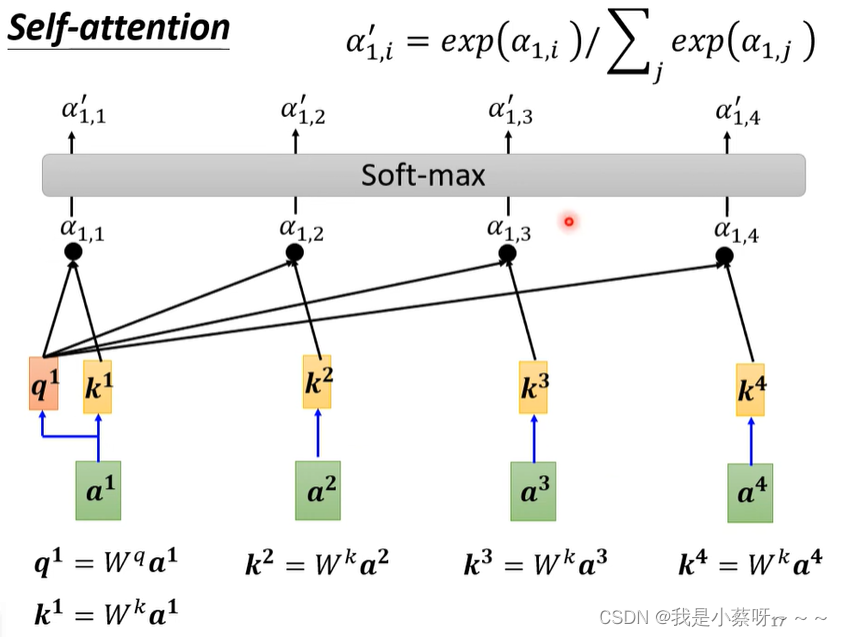
为什么要用soft-max?
不一定用soft-max,只是比较常见,也可以用别的。
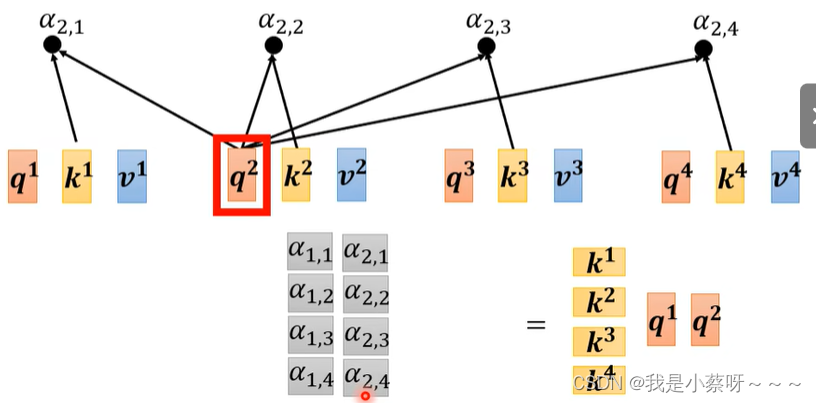
得到a’后,我们可以知道哪些向量与a1是最有关系的,然后我们开始根据attention score来抽取重要资讯:
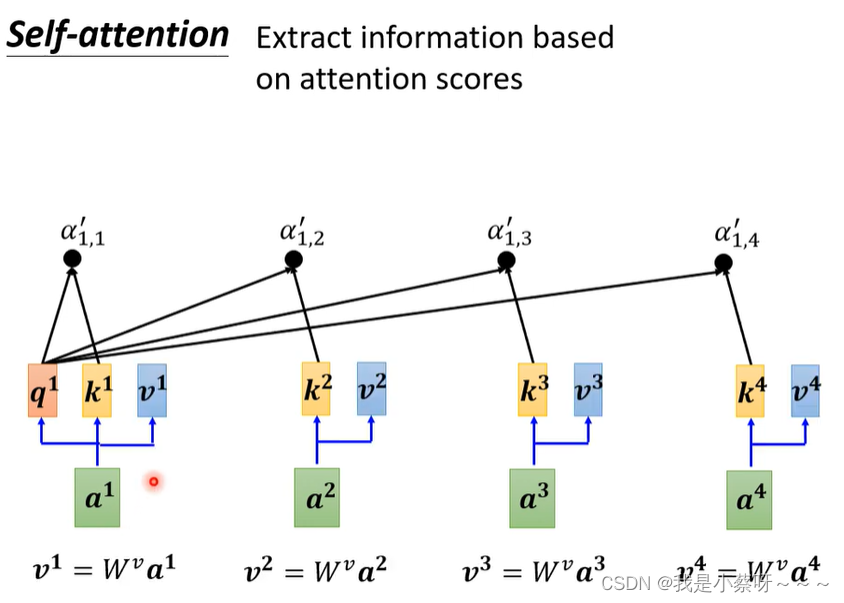
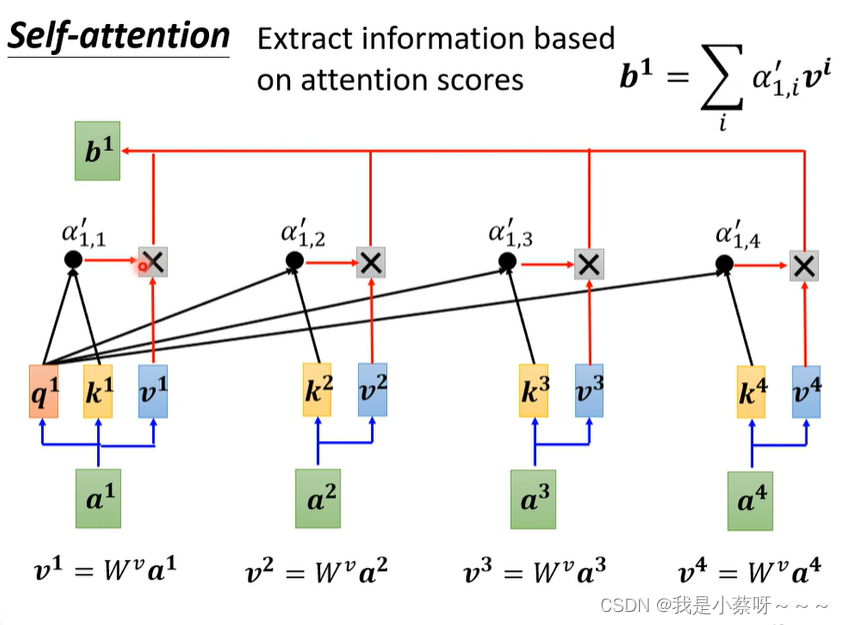
b1-b4是可以并行计算得到
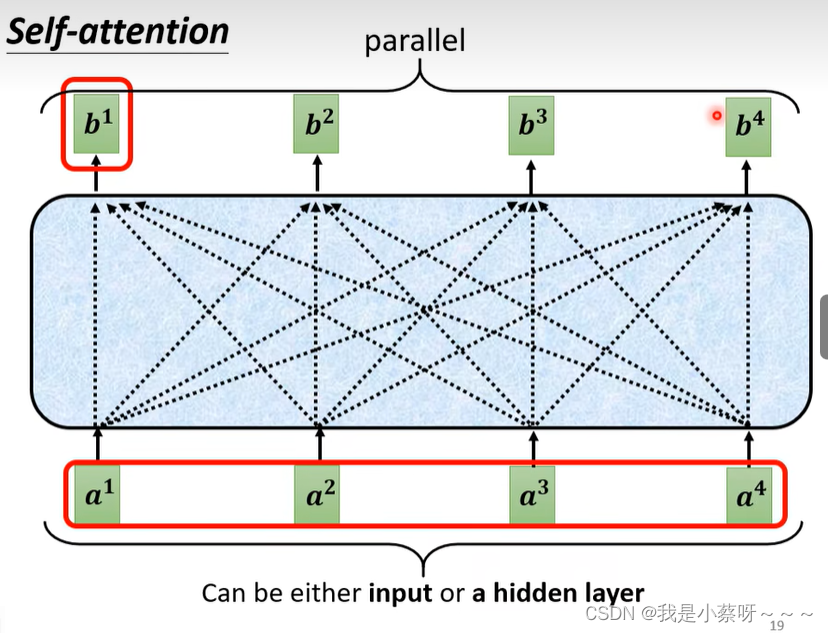
softmax可以使用其他

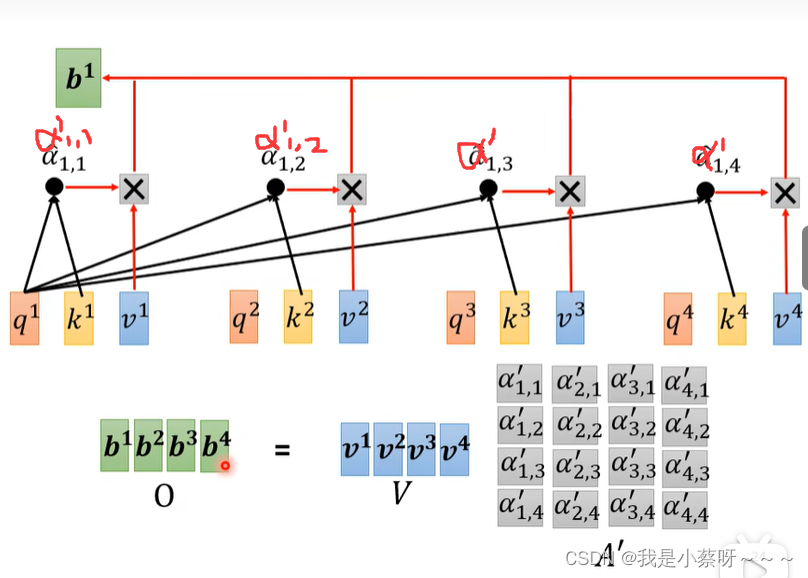
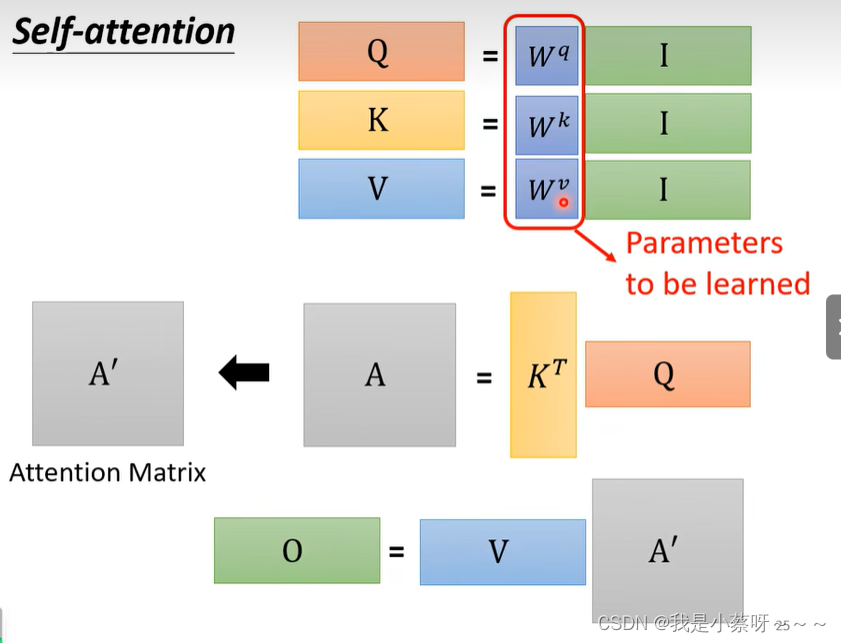
从I——>O就是做了self-attention
self-attention layer中唯一需要学习的参数是W
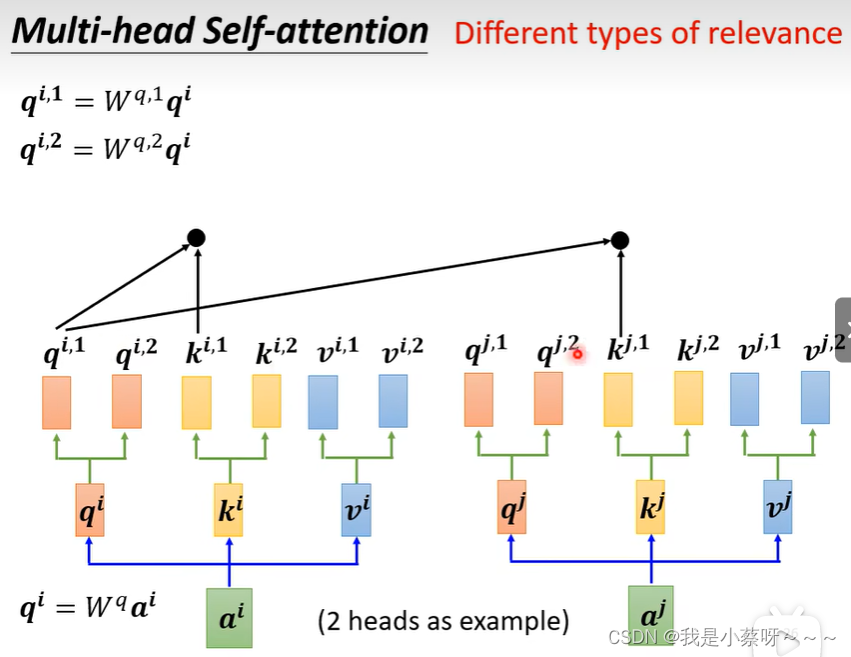
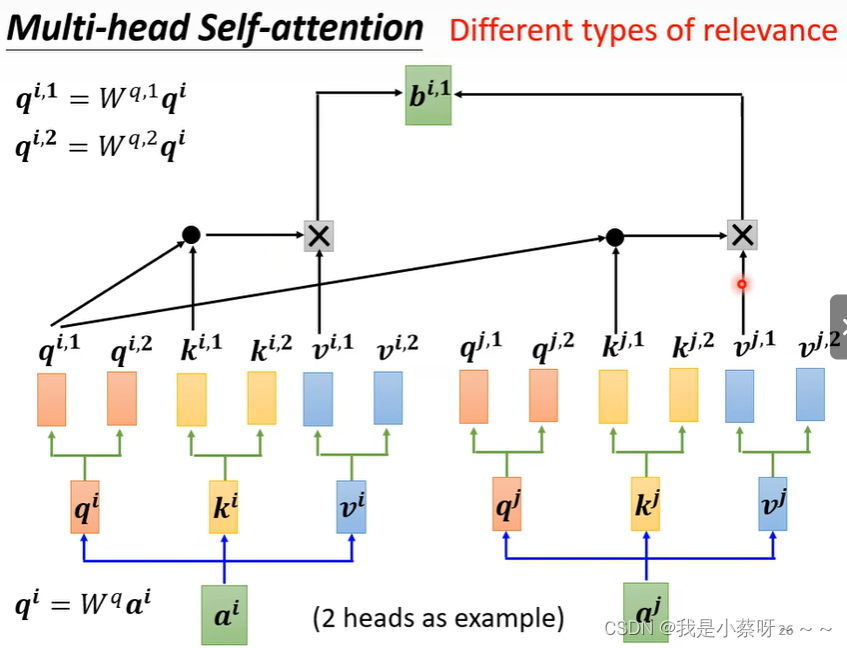
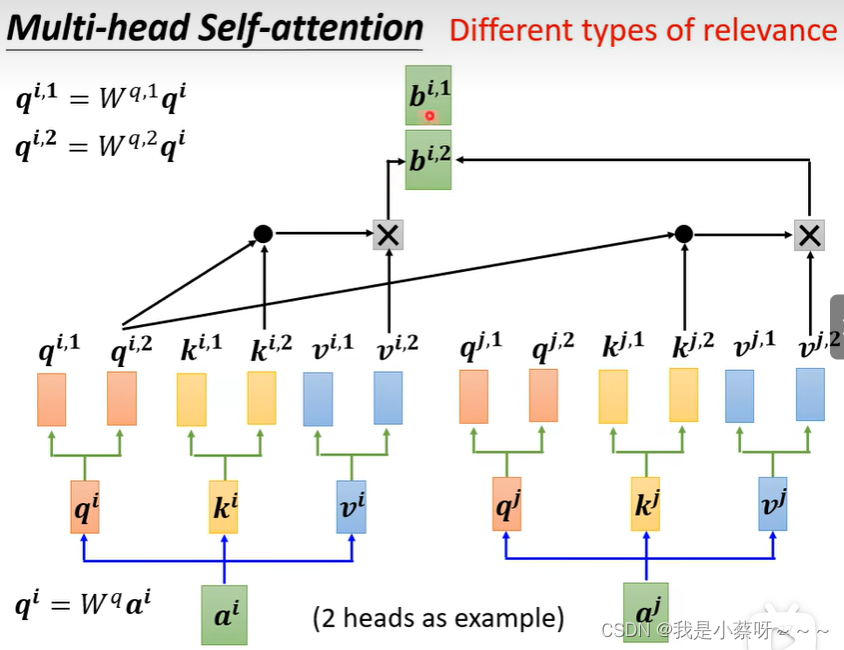
Multi-head Self-attention多头注意力机制
翻译、语音辨识用multi-head往往可以得到比较好的结果,至于多少个head也是需要调参的。

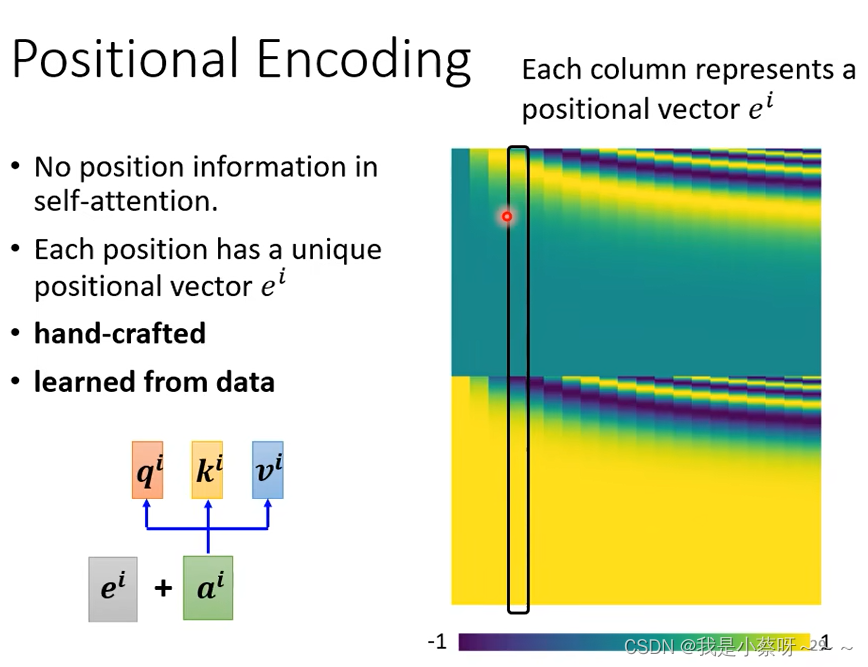
self-attention layer少了一个很重要的资讯——位置资讯,如果需要可以加入positional encoding。(这个问题尚待研究)
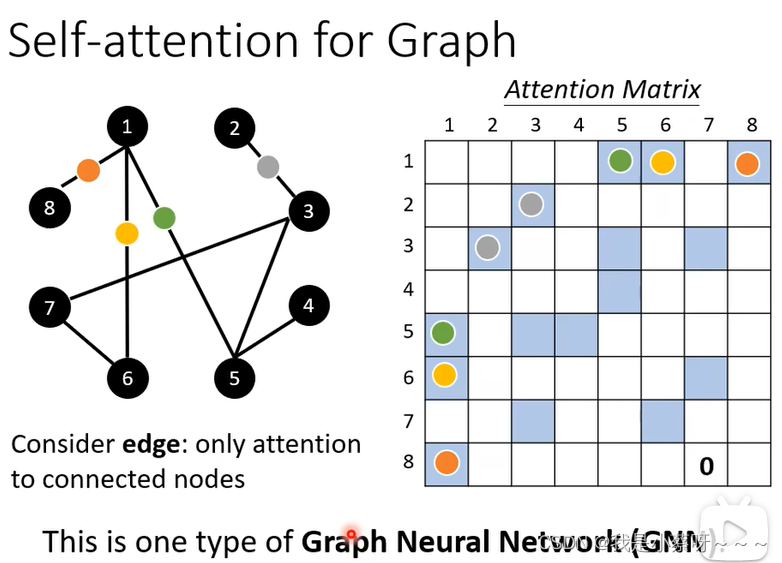
self-attention的应用

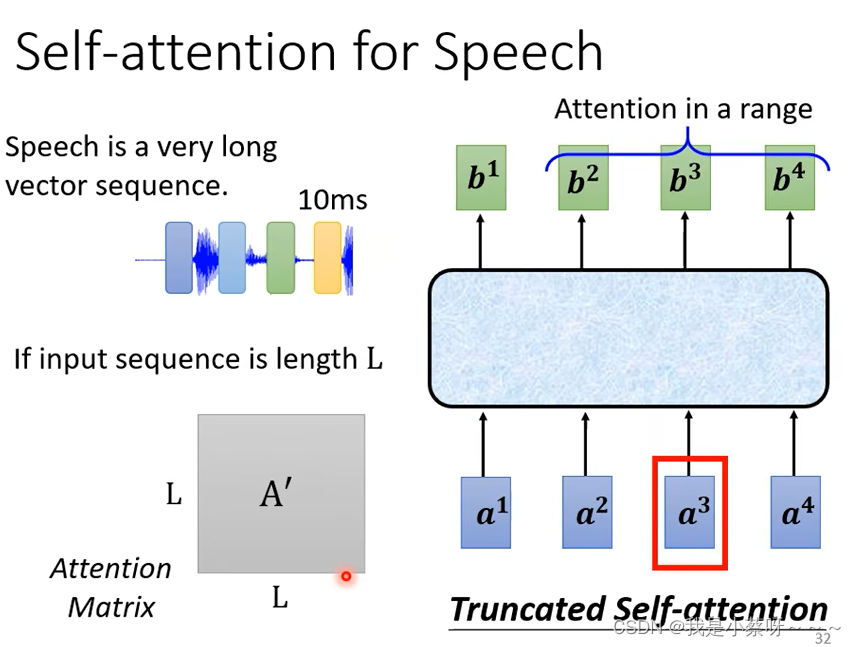
使用self-attention 处理语音时,会产生很长的向量,即attention matrix太大,不容易训练,因此使用truncated self-attention,看一部分(自己设定)而不去看整句话。
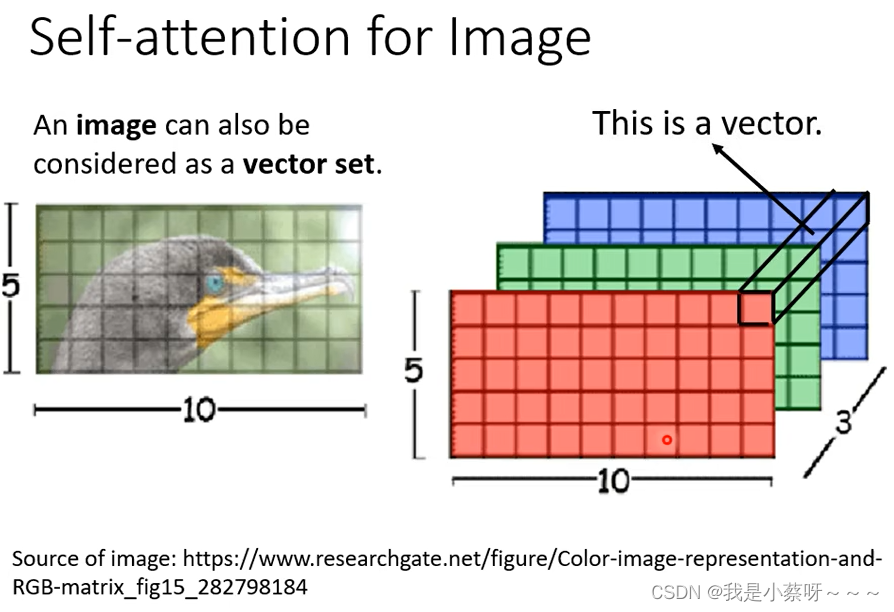
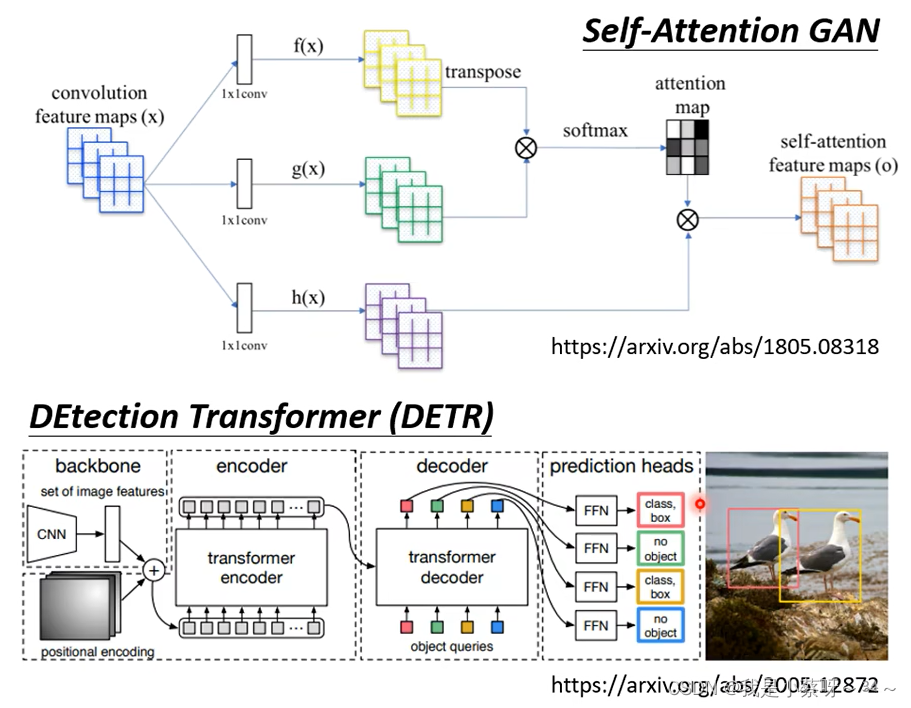
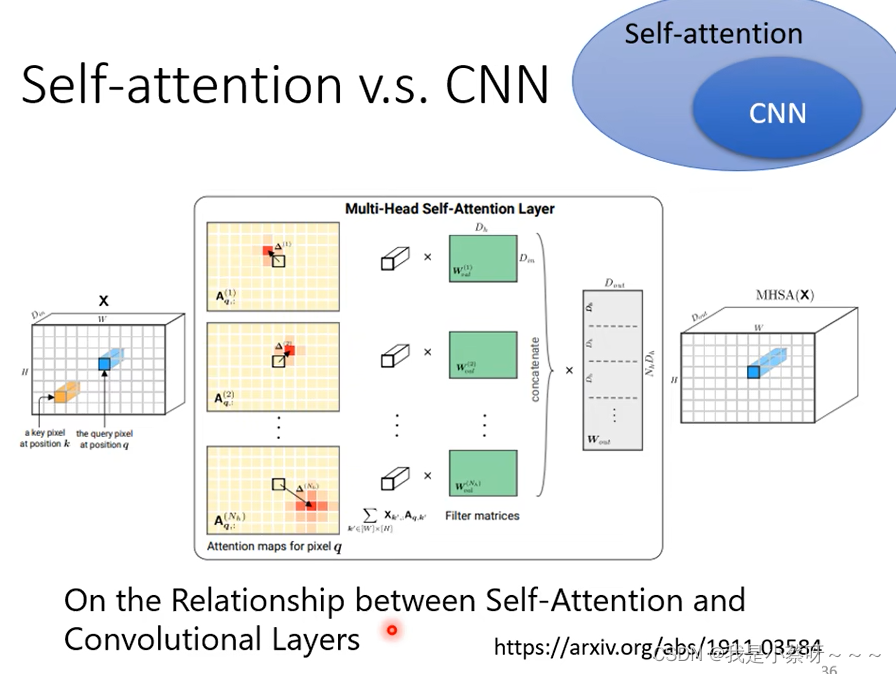
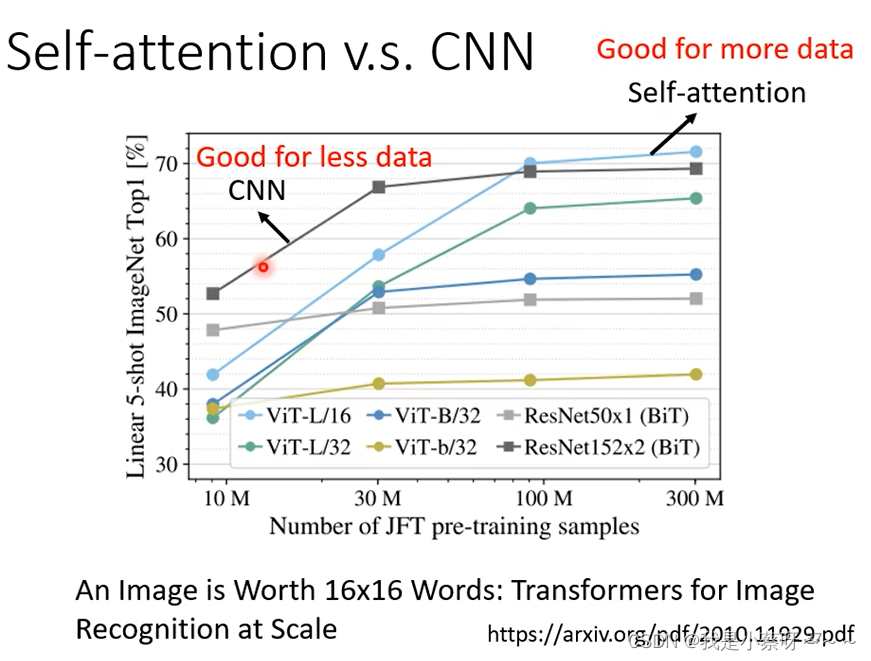
Self -attention 和 CNN的关系
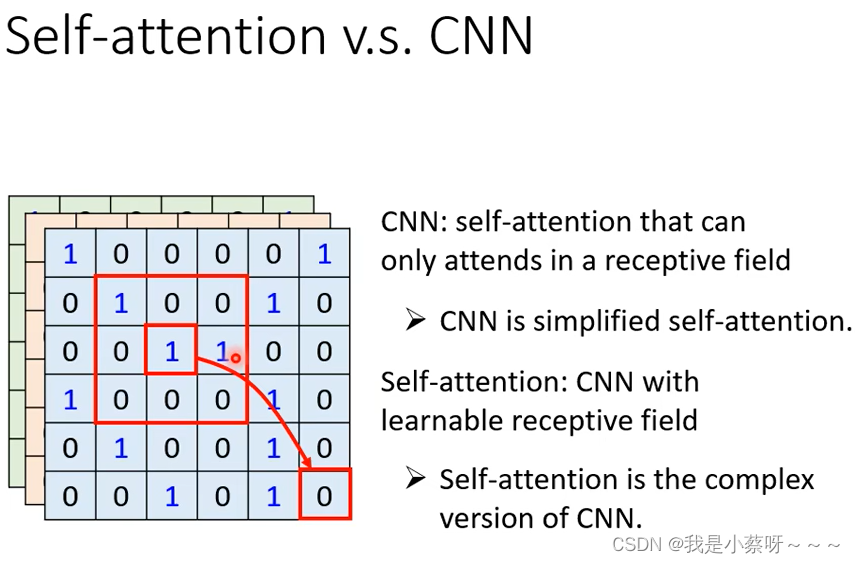
self-attention中的receptive field是机器自己学出来的,自己决定需要考虑哪些信息。
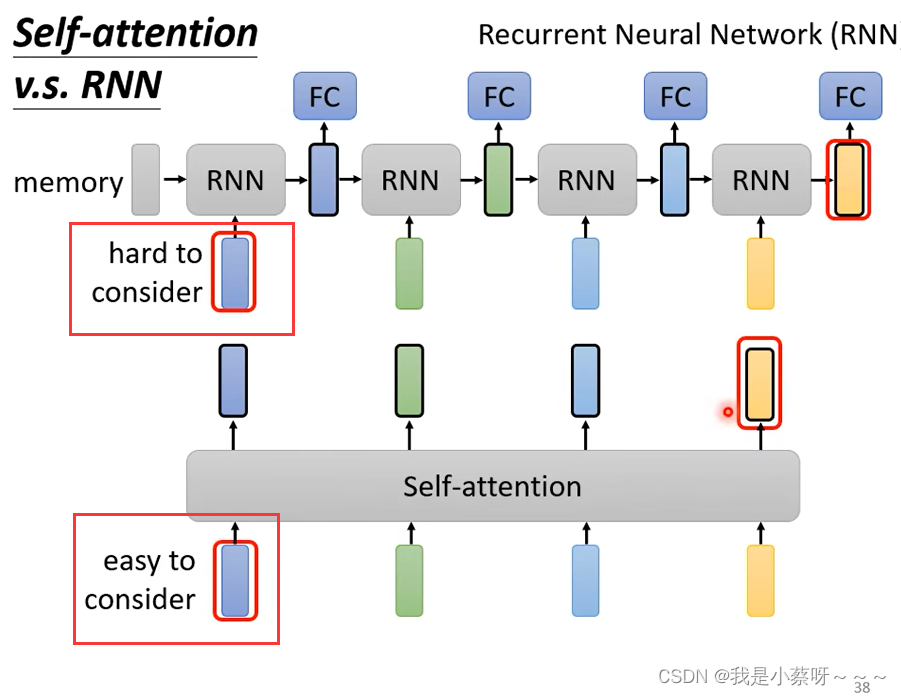
Self-attention VS RNN
(1)self-attention考虑的范围较广
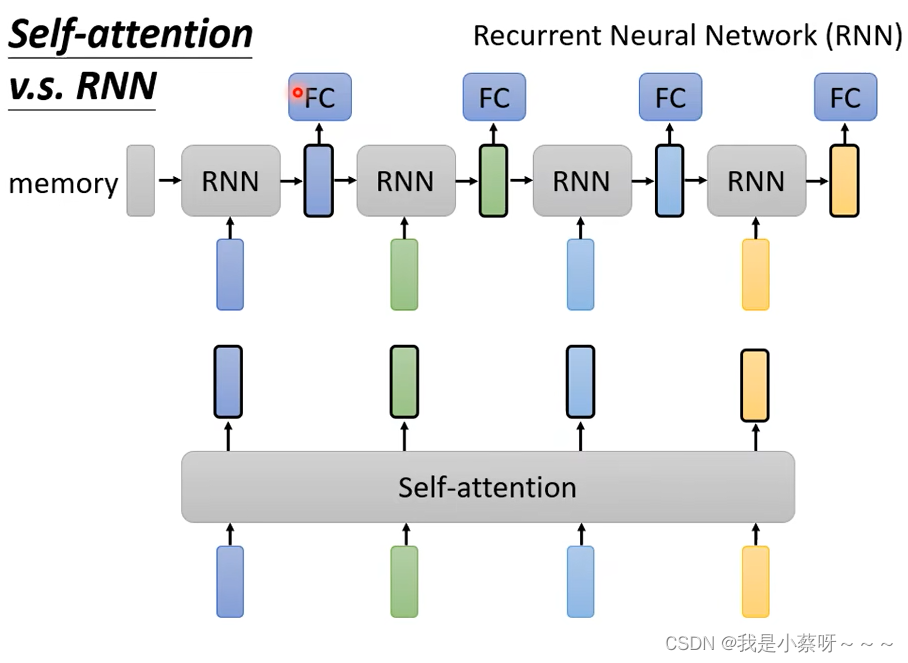
(2)倘若RNN要考虑最右边黄色vector要考虑最左边蓝色vector,则它需要将蓝色vector存到Memory中,然后不能忘掉一路带到最右边。
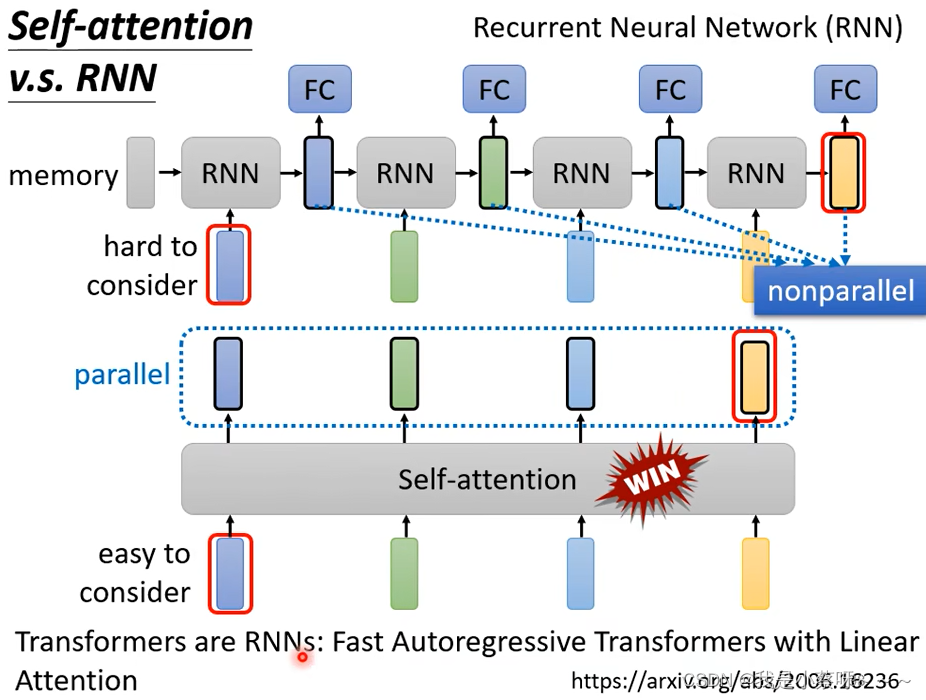
(3)RNN:nonparallel

![[附源码]SSM计算机毕业设计小说网站的设计与实现1JAVA](https://img-blog.csdnimg.cn/85d210796dd94afea3ed69cb7f26b79a.png)



![[附源码]计算机毕业设计Springboot电影推荐网站](https://img-blog.csdnimg.cn/8026578bb9134949b53c2d715edb08e5.png)