目录
先上测试代码:
上依赖:
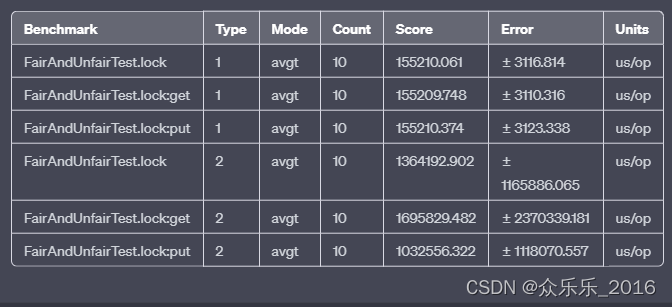
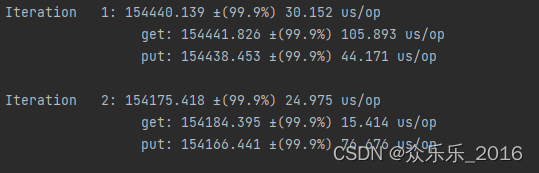
输出结果:(注意不要debug运行,直接运行代码,否则报错)
源码-公平锁的 lock 方法:
源码-非公平锁的lock方法:
总结 非公平锁和公平锁的两处不同:
注解的说明:
先上测试代码:
package cn.net.cdsz.ccb.test;
import org.openjdk.jmh.annotations.*;
import org.openjdk.jmh.runner.Runner;
import org.openjdk.jmh.runner.RunnerException;
import org.openjdk.jmh.runner.options.Options;
import org.openjdk.jmh.runner.options.OptionsBuilder;
import java.util.concurrent.TimeUnit;
import java.util.concurrent.locks.Lock;
import java.util.concurrent.locks.ReentrantLock;
@BenchmarkMode(Mode.AverageTime)
@OutputTimeUnit(TimeUnit.MICROSECONDS)
@Measurement(iterations = 10)
@Warmup(iterations = 5)
@State(Scope.Group)
public class FairAndUnfairTest {
@Param({"1", "2"})
private int type;
private static Lock lock;
@Setup
public void setup() {
switch (type) {
case 1:
lock = new ReentrantLock(true);
break;
case 2:
//默认就是非公平锁
lock = new ReentrantLock(false);
break;
default:
throw new IllegalArgumentException("illegal lock type.");
}
}
@Benchmark
@GroupThreads(5)
@Group("lock")
public void put() {
lock.lock();
try {
Thread.sleep(10);
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
lock.unlock();
}
}
private int randomIntValue() {
return (int) Math.ceil(Math.random() * 600000);
}
@Benchmark
@GroupThreads(5)
@Group("lock")
public Integer get() {
lock.lock();
try {
Thread.sleep(10);
return randomIntValue();
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
lock.unlock();
}
return 0;
}
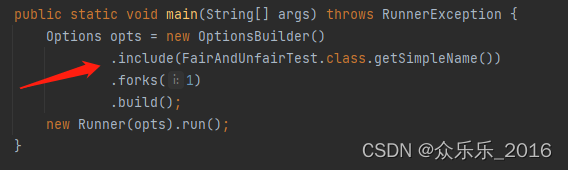
public static void main(String[] args) throws RunnerException {
Options opts = new OptionsBuilder()
.include(FairAndUnfairTest.class.getSimpleName())
.forks(1)
.build();
new Runner(opts).run();
}
}
上依赖:
<dependency>
<groupId>org.openjdk.jmh</groupId>
<artifactId>jmh-core</artifactId>
<version>1.36</version>
</dependency>
<dependency>
<groupId>org.openjdk.jmh</groupId>
<artifactId>jmh-generator-annprocess</artifactId>
<version>1.36</version>
<scope>provided</scope>
</dependency>输出结果:(注意不要debug运行,直接运行代码,否则报错)
源码-公平锁的 lock 方法:
static final class FairSync extends Sync {
final void lock() {
acquire(1);
}
// AbstractQueuedSynchronizer.acquire(int arg)
public final void acquire(int arg) {
if (!tryAcquire(arg) &&
acquireQueued(addWaiter(Node.EXCLUSIVE), arg))
selfInterrupt();
}
protected final boolean tryAcquire(int acquires) {
final Thread current = Thread.currentThread();
int c = getState();
if (c == 0) {
// 1. 和非公平锁相比,这里多了一个判断:是否有线程在等待
if (!hasQueuedPredecessors() &&
compareAndSetState(0, acquires)) {
setExclusiveOwnerThread(current);
return true;
}
}
else if (current == getExclusiveOwnerThread()) {
int nextc = c + acquires;
if (nextc < 0)
throw new Error("Maximum lock count exceeded");
setState(nextc);
return true;
}
return false;
}
}
源码-非公平锁的lock方法:
static final class NonfairSync extends Sync {
final void lock() {
// 2. 和公平锁相比,这里会直接先进行一次CAS,成功就返回了
if (compareAndSetState(0, 1))
setExclusiveOwnerThread(Thread.currentThread());
else
acquire(1);
}
// AbstractQueuedSynchronizer.acquire(int arg)
public final void acquire(int arg) {
if (!tryAcquire(arg) &&
acquireQueued(addWaiter(Node.EXCLUSIVE), arg))
selfInterrupt();
}
protected final boolean tryAcquire(int acquires) {
return nonfairTryAcquire(acquires);
}
}
/**
* Performs non-fair tryLock. tryAcquire is implemented in
* subclasses, but both need nonfair try for trylock method.
*/
final boolean nonfairTryAcquire(int acquires) {
final Thread current = Thread.currentThread();
int c = getState();
if (c == 0) {
//3.这里也是直接CAS,没有判断前面是否还有节点。
if (compareAndSetState(0, acquires)) {
setExclusiveOwnerThread(current);
return true;
}
}
else if (current == getExclusiveOwnerThread()) {
int nextc = c + acquires;
if (nextc < 0) // overflow
throw new Error("Maximum lock count exceeded");
setState(nextc);
return true;
}
return false;
}
总结 非公平锁和公平锁的两处不同:
- 非公平锁在调用 lock 后,首先就会调用 CAS 进行一次抢锁,如果这个时候恰巧锁没有被占用,那么直接就获取到锁返回了。
- 非公平锁在 CAS 失败后,和公平锁一样都会进入到 tryAcquire 方法,在 tryAcquire 方法中,如果发现锁这个时候被释放了(state == 0),非公平锁会直接 CAS 抢锁,但是公平锁会判断等待队列是否有线程处于等待状态,如果有则不去抢锁,乖乖排到后面。
公平锁和非公平锁就这两点区别,如果这两次 CAS 都不成功,那么后面非公平锁和公平锁是一样的,都要进入到阻塞队列等待唤醒。
相对来说,非公平锁会有更好的性能,因为它的吞吐量比较大。当然,非公平锁让获取锁的时间变得更加不确定,可能会导致在阻塞队列中的线程长期处于饥饿状态。
注解的说明:
@BenchmarkMode(Mode)
表示 JMH 进行 Benchmark 时所使用的模式。通常是测量的维度不同,或是测量的方式不同。目前JMH 共有四种模式:
- Throughput: 整体吞吐量,例如“1秒内可以执行多少次调用”。
- AverageTime: 调用的平均时间,例如“每次调用平均耗时xxx毫秒”。
- SampleTime: 随机取样,最后输出取样结果的分布,例如“99%的调用在xxx毫秒以内,99.99%的调用在xxx毫秒以内”
- SingleShotTime: 以上模式都是默认一次 iteration 是 1s,唯有 SingleShotTime 是只运行一次。往往同时把 warmup 次数设为0,用于测试冷启动时的性能。
@State(Scope.Thread)
State 用于声明某个类是一个“状态”,然后接受一个 Scope 参数用来表示该状态的共享范围。因为很多 benchmark 会需要一些表示状态的类,JMH 允许你把这些类以依赖注入的方式注入到 benchmark 函数里。Scope 主要分为三种。
- Thread: 该状态为每个线程独享。
- Benchmark: 该状态在所有线程间共享。
- Group:线程组共享一个示例,在测试方法上使用 @Group 设置线程组。
@fork
进行 fork 的次数。如果 fork 数是2的话,则 JMH 会 fork 出两个线程来进行测试。
@Warmup:
Warmup 是指在实际进行 benchmark 前先进行预热的行为。为什么需要预热?因为 JVM 的 JIT 机制的存在,如果某个函数被调用多次之后,JVM 会尝试将其编译成为机器码从而提高执行速度。所以为了让 benchmark 的结果更加接近真实情况就需要进行预热。
@Measurement
进行 5 次微基准测试,也可用在测试方法上
@Benchmark
表示该方法是需要进行 benchmark 的对象,用法和 JUnit 的 @Test 类似。
@OutputTimeUnit
benchmark 结果所使用的时间单位。
@Param 可以用来指定某项参数的多种情况。特别适合用来测试一个函数在不同的参数输入的情况下的性能。
@Setup 会在执行 benchmark 之前被执行,正如其名,主要用于初始化。
@TearDown 和 @Setup 相对的,会在所有 benchmark 执行结束以后执行,主要用于资源的回收等。
Iteration 是 JMH 进行测试的最小单位。在大部分模式下,一次 iteration 代表的是一秒,JMH 会在这一秒内不断调用需要 benchmark 的方法,然后根据模式对其采样,计算吞吐量,计算平均执行时间等。
include是benchmark 所在的类的名字,注意这里是使用正则表达式对所有类进行匹配的。