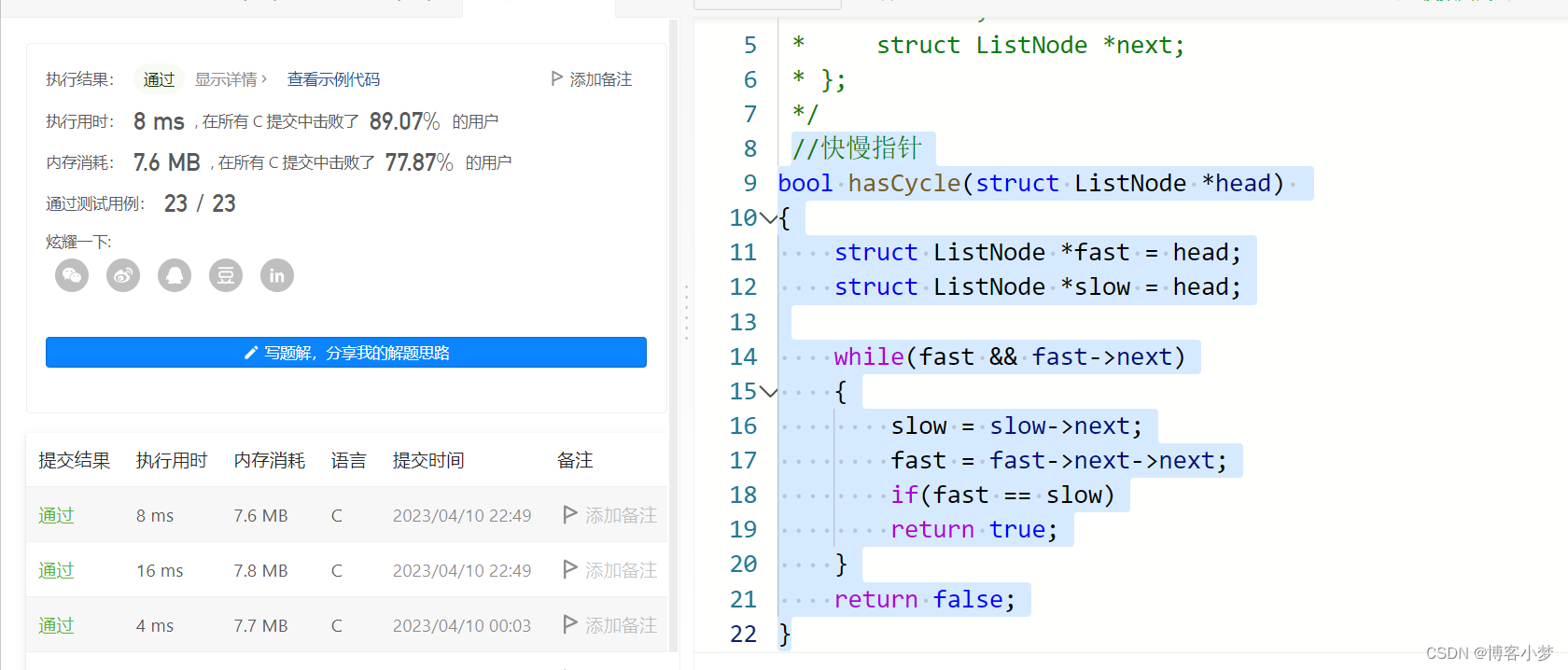
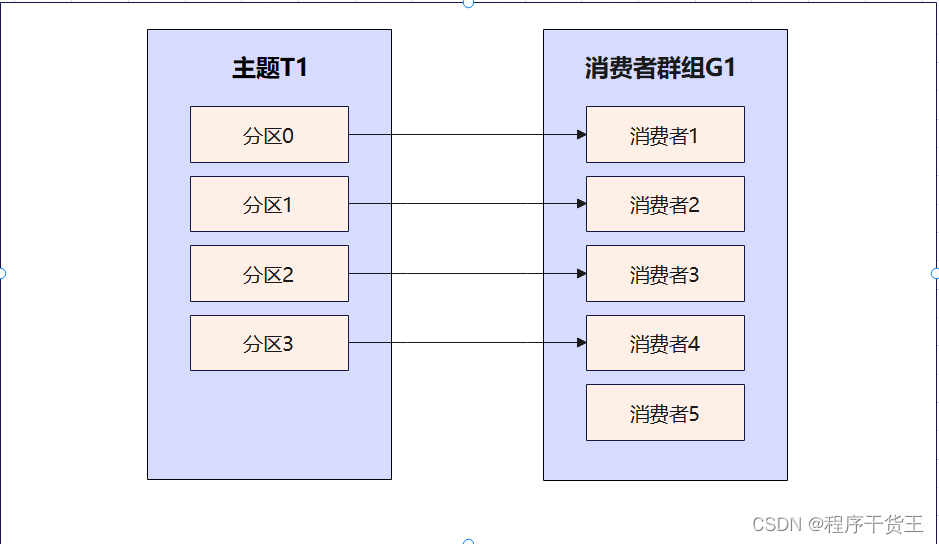
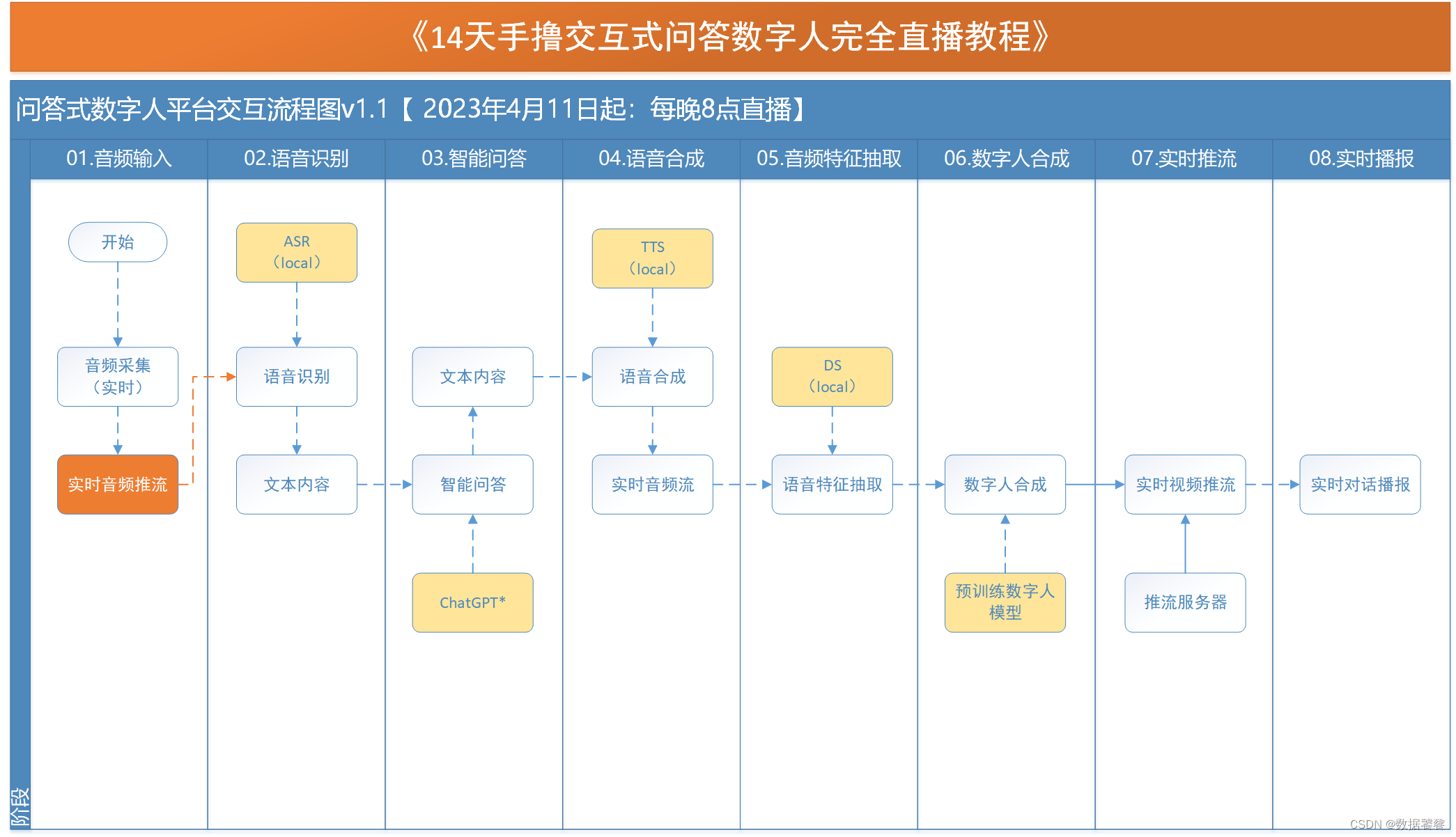
两种做法的效率差异
做法一:SAM记录子串第一次结束位置

做法二:SAM + hash

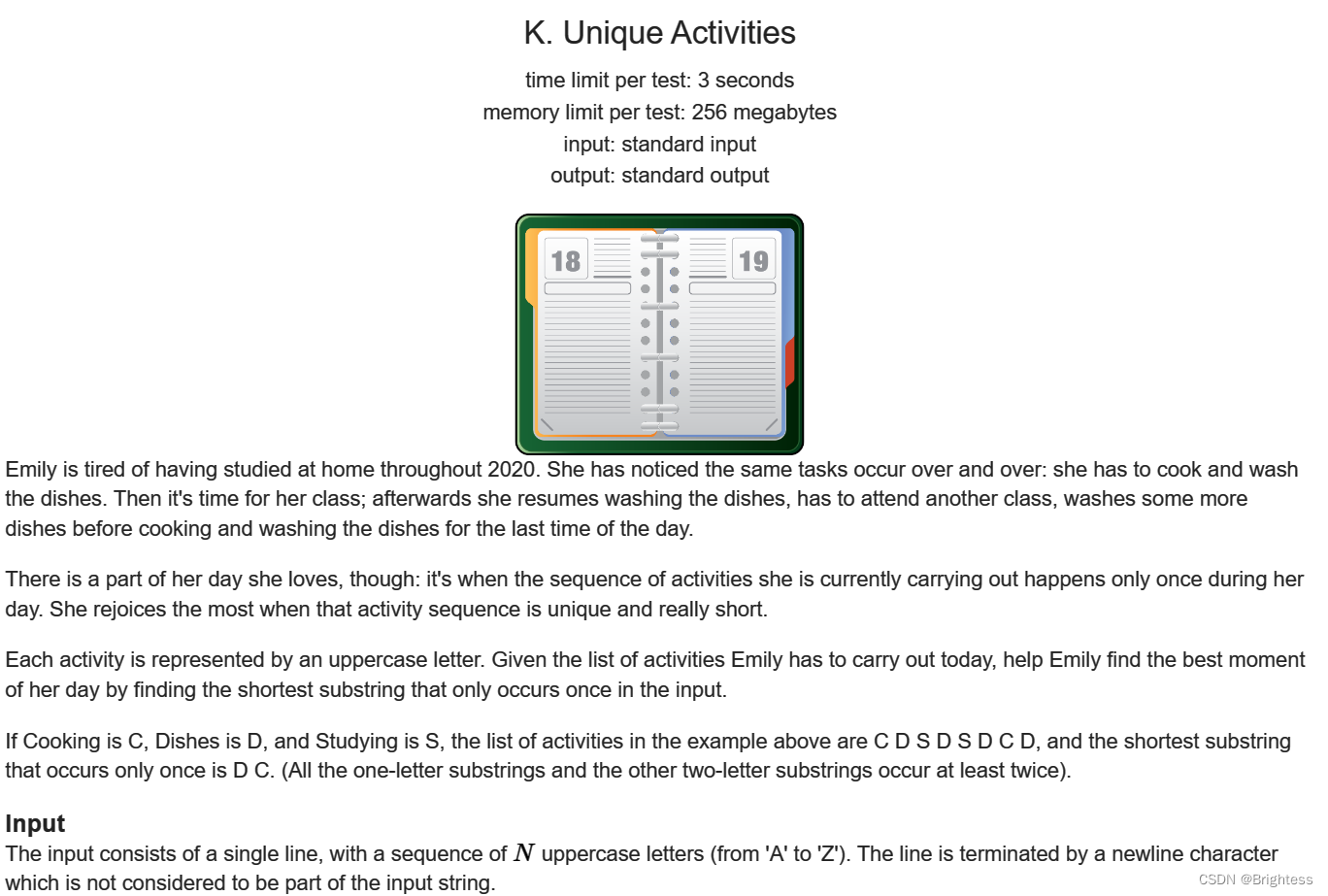
题意:
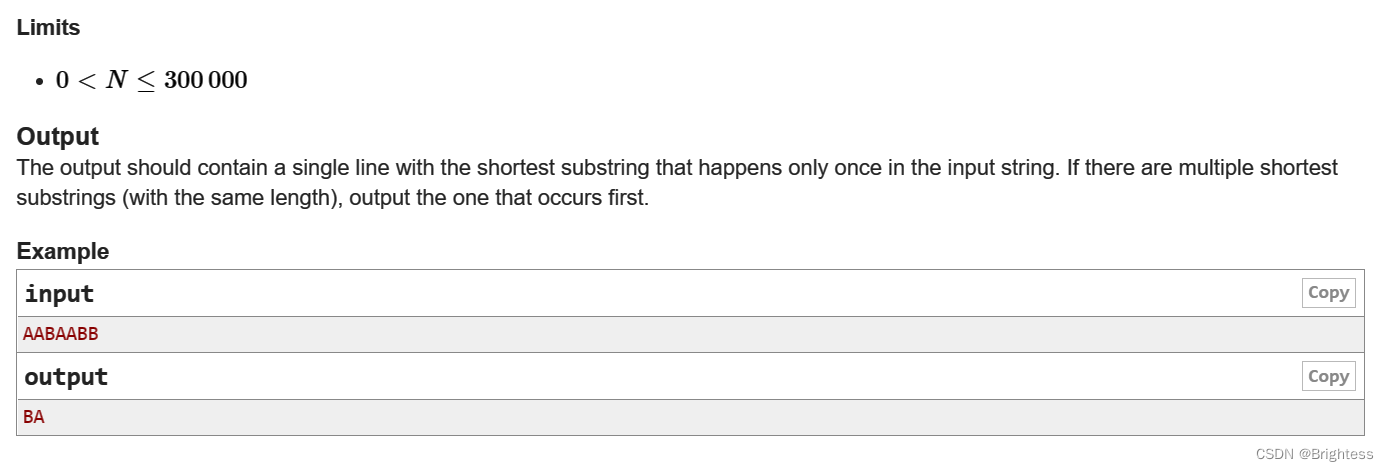
给定一个字符串,让你找到只出现过一次,且长度最短的子串并输出,如果有多个则输出最先出现的那个。
思路:
思路一:对原串构建后缀自动机,构建的同时维护一个firstpos数组,用于记录每个节点代表子串第一次出现时的结束位置(然后我们又维护了len数组,其实就等效于可以记录子串第一次出现时的开始位置了)。构建完成后在后缀链接树上跑dfs,回溯的时候计算每个节点代表子串出现的次数,当某个节点出现次数为1时,我们判断是否能够更新目标串的长度anslen和结尾下标ed,不断迭代。最终dfs完毕后,根据目标串的长度和结尾下标能直接算出开始位置sta,输出目标串即可。
思路二:对原串构建后缀自动机和字符串哈希数组,dfs的过程和思路一差不多,只不过我们只能得到目标串的长度anslen,之后对原串进行长度为anslen的尺取遍历计算每一段的哈希值,把所有哈希值丢到map里面计数,最后再尺取遍历原串,如果当前哈希值出现次数正好为1,则直接输出该段子串即可。
时间复杂度: O ( n ) O(n) O(n)
代码:
法一:
#include<bits/stdc++.h>
using namespace std;
const int N = 3e5 + 10, M = N << 1;
int ch[M][26], fa[M], len[M], fipos[M], np = 1, tot = 1;//其中新增一个fipos数组用于记录SAM中每个节点所代表的子串 “第一次出现时的结束位置下标”
long long cnt[M];
char s[N];
vector<int> g[M];
int anslen, ed = 0; //目标串的长度和结束位置
void extend(int c) {
int p = np; np = ++tot;
len[np] = len[p] + 1, cnt[np] = 1, fipos[np] = len[np] - 1; //如果下标从0开始则减一
while (p && !ch[p][c]) {
ch[p][c] = np;
p = fa[p];
}
if (!p) {
fa[np] = 1;
}
else {
int q = ch[p][c];
if (len[q] == len[p] + 1) fa[np] = q;
else {
int nq = ++tot;
len[nq] = len[p] + 1;
fa[nq] = fa[q], fa[q] = fa[np] = nq;
fipos[nq] = fipos[q]; //每次复制的节点nq的fipos因为是从一个节点q中分出来的,所以还是q的fipos值。
while (p && ch[p][c] == q) {
ch[p][c] = nq;
p = fa[p];
}
memcpy(ch[nq], ch[q], sizeof ch[q]);
}
}
}
void dfs(int u)
{
for (auto son : g[u]) {
dfs(son);
cnt[u] += cnt[son];
fipos[u] = min(fipos[u], fipos[son]); //不加这句也可以过
}
if (cnt[u] == 1 && u > 1) { //当当前节点代表子串只出现过一次
if (anslen > len[fa[u]] + 1) { //满足这个条件就可更新目标串的长度和结束位置
anslen = len[fa[u]] + 1;
ed = fipos[u];
}
else if (anslen == len[fa[u]] + 1) { //这个判断是一定要加的,因为是在树上进行,而不是在一个数组上
ed = min(ed, fipos[u]);
}
}
}
signed main()
{
scanf("%s", s);
anslen = strlen(s);
for (int i = 0; s[i]; ++i) extend(s[i] - 'A');
for (int i = 2; i <= tot; ++i) g[fa[i]].emplace_back(i);
dfs(1);
int sta = ed - anslen + 1; //目标串的开始位置
for (int i = sta; i <= ed; ++i) {
putchar(s[i]);
}
puts("");
return 0;
}
法二:
#include<bits/stdc++.h>
using namespace std;
typedef unsigned long long ull;
const int N = 3e5 + 10, M = N << 1, P = 1331;
ull p[N], hah[N];
int ch[M][26], fa[M], len[M], np = 1, tot = 1;
long long cnt[M];
char s[N];
vector<int> g[M];
int anslen = N;
int n;
unordered_map<ull, int> ha;
ull get(int l, int r) {
return hah[r] - hah[l - 1] * p[r - l + 1];
}
void init() {
p[0] = 1;
n = strlen(s);
for (int i = 1; i <= n; ++i) {
p[i] = p[i - 1] * P;
hah[i] = hah[i - 1] * P + s[i - 1];
}
}
void extend(int c) {
int p = np;
np = ++tot;
len[np] = len[p] + 1, cnt[np] = 1;
while (p && !ch[p][c]) {
ch[p][c] = np;
p = fa[p];
}
if (!p) {
fa[np] = 1;
}
else {
int q = ch[p][c];
if (len[q] == len[p] + 1) fa[np] = q;
else {
int nq = ++tot;
len[nq] = len[p] + 1;
fa[nq] = fa[q], fa[q] = fa[np] = nq;
while (p && ch[p][c] == q) {
ch[p][c] = nq;
p = fa[p];
}
memcpy(ch[nq], ch[q], sizeof ch[q]);
}
}
}
void dfs(int u)
{
for (auto son : g[u]) {
dfs(son);
cnt[u] += cnt[son];
}
if (cnt[u] == 1) {
anslen = min(anslen, len[fa[u]] + 1);
}
}
signed main()
{
scanf("%s", s);
init();
for (int i = 0; s[i]; ++i) extend(s[i] - 'A');
for (int i = 2; i <= tot; ++i) {
g[fa[i]].emplace_back(i);
}
dfs(1);
int l = 1, r = min(l + anslen - 1, n);
while (r <= n) {
ull tmp = get(l, r);
ha[tmp]++;
l++, r++;
}
l = 1, r = min(l + anslen - 1, n);
while (r <= n) {
ull tmp = get(l, r);
if (ha[tmp] == 1) {
for (int i = l - 1; i <= r - 1; ++i) {
printf("%c", s[i]);
}
puts("");
return 0;
}
l++, r++;
}
return 0;
}