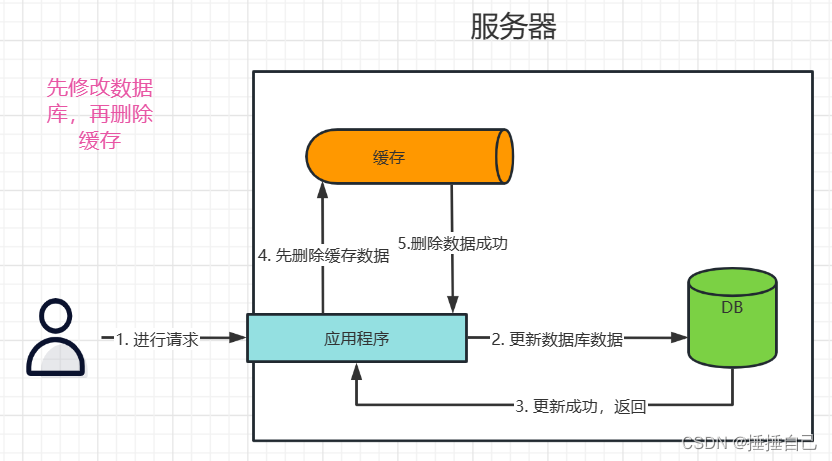
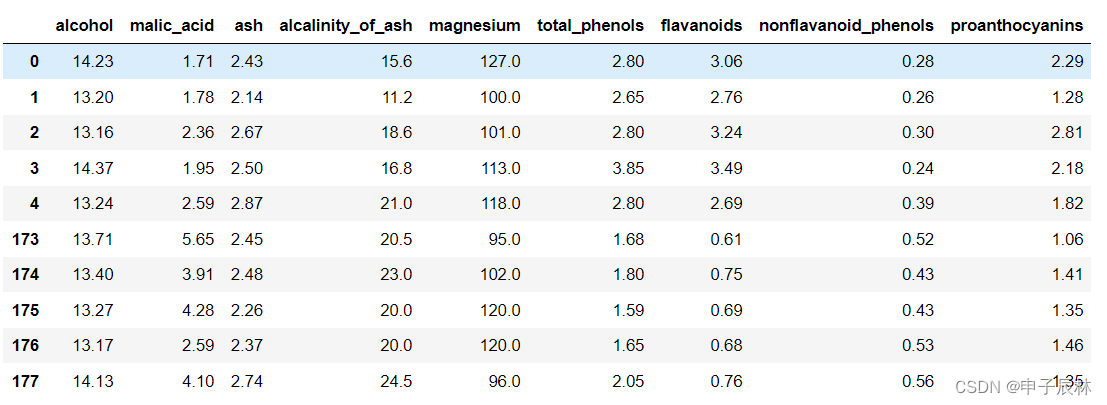
1、红酒数据介绍
经典的红酒分类数据集是指UCI机器学习库中的Wine数据集。该数据集包含178个样本,每个样本有13个特征,可以用于分类任务。
具体每个字段的含义如下:
alcohol:酒精含量百分比
malic_acid:苹果酸含量(克/升)
ash:灰分含量(克/升)
alcalinity_of_ash:灰分碱度(以mEq/L为单位)
magnesium:镁含量(毫克/升)
total_phenols:总酚含量(以毫克/升为单位)
flavanoids:类黄酮含量(以毫克/升为单位)
nonflavanoid_phenols:非类黄酮酚含量(以毫克/升为单位)
proanthocyanins:原花青素含量(以毫克/升为单位)
color_intensity:颜色强度(以 absorbance 为单位,对应于 1cm 路径长度处的相对宽度)
hue:色调,即色彩的倾向性或相似性(在 1 至 10 之间的一个数字)
od280/od315_of_diluted_wines:稀释葡萄酒样品的光密度比值,用于测量葡萄酒中各种化合物的浓度
proline:脯氨酸含量(以毫克/升为单位),是一种天然氨基酸,与葡萄酒的品质和口感有关。
2、引入依赖库
import pandas as pd
import numpy as np
from sklearn.datasets import load_wine
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score
3、加载红酒数据集
# 加载红酒数据集
wineBunch = load_wine()
type(wineBunch)
sklearn.utils.Bunch
sklearn.utils.Bunch是Scikit-learn库中的一个数据容器,类似于Python字典(dictionary),
它可以存储任意数量和类型的数据,并且可以使用点(.)操作符来访问数据。Bunch常用于存储机器学习模型的数据集,
例如描述特征矩阵的数据、相关联的目标向量、特征名称等等,以便于组织和传递这些数据到模型中进行训练或预测。
len(wineBunch.data),len(wineBunch.target)
(178, 178)
featuresDf = pd.DataFrame(data=wineBunch.data, columns=wineBunch.feature_names) # 特征数据
labelDf = pd.DataFrame(data=wineBunch.target, columns=["target"]) # 标签数据
wineDf = pd.concat([featuresDf, labelDf], axis=1) # 横向拼接
wineDf.head(5).append(wineDf.tail(5)) # 打印首尾5行
wineDf.columns
Index([‘alcohol’, ‘malic_acid’, ‘ash’, ‘alcalinity_of_ash’, ‘magnesium’,
‘total_phenols’, ‘flavanoids’, ‘nonflavanoid_phenols’,
‘proanthocyanins’, ‘color_intensity’, ‘hue’,
‘od280/od315_of_diluted_wines’, ‘proline’, ‘target’],
dtype=‘object’)
3、构造训练集、验证集和测试集
# 将数据集分成训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(wineDf.drop("target", axis=1), wineDf["target"], test_size=0.2)
# 将训练集和验证集进一步划分为训练集和验证集
X_train, X_val, y_train, y_val = train_test_split(X_train, y_train, test_size=0.2)
type(X_train),type(y_train)
(pandas.core.frame.DataFrame, pandas.core.series.Series)
X_train.shape, X_test.shape, y_train.shape, y_test.shape
((113, 13), (36, 13), (113,), (36,))
X_train.shape, X_val.shape, y_train.shape, y_val.shape
((113, 13), (29, 13), (113,), (29,))
wineDf.target.unique() # 3个分类
array([0, 1, 2])
4、训练决策树模型
# 使用决策树算法进行训练
clf = DecisionTreeClassifier()
clf.fit(X_train, y_train)
# 在验证集上评估模型性能以避免过拟合
val_pred = clf.predict(X_val)
val_accuracy = accuracy_score(y_val, val_pred)
print("验证集准确率:", val_accuracy)
验证集准确率: 0.9655172413793104
# 在测试集上评估模型性能
test_pred = clf.predict(X_test)
test_accuracy = accuracy_score(y_test, test_pred)
print("测试集准确率:", test_accuracy)
测试集准确率: 0.9166666666666666
clf.feature_importances_ # 使用特征的数量的重要性
[*zip(wineBunch.feature_names, clf.feature_importances_)] # 特征名称和重要性
[(‘alcohol’, 0.0),
(‘malic_acid’, 0.0),
(‘ash’, 0.0),
(‘alcalinity_of_ash’, 0.0),
(‘magnesium’, 0.0),
(‘total_phenols’, 0.0),
(‘flavanoids’, 0.39118650550280015),
(‘nonflavanoid_phenols’, 0.0),
(‘proanthocyanins’, 0.0),
(‘color_intensity’, 0.4062066644389752),
(‘hue’, 0.0),
(‘od280/od315_of_diluted_wines’, 0.026685709144887784),
(‘proline’, 0.17592112091333678)]
5、训练SVM向量机模型
from sklearn.preprocessing import StandardScaler
from sklearn.svm import SVC
# 将数据集分成训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(wineDf.drop("target", axis=1), wineDf["target"], test_size=0.2)
# 将训练集和验证集进一步划分为训练集和验证集
X_train, X_val, y_train, y_val = train_test_split(X_train, y_train, test_size=0.2)
scaler = StandardScaler()
# 对特征进行标准化处理,以确保不同特征之间具有相同的范围
X_train = scaler.fit_transform(X_train) # 特征标准化
X_test = scaler.fit_transform(X_test) # 特征标准化
X_val = scaler.fit_transform(X_val) # 特征标准化
# SVM模型训练
svm = SVC(kernel='rbf', # 使用径向基函数(rbf)核
C=1, # 正则化参数C取值为1
gamma=0.1) # 核系数gamma取值为0.1
svm.fit(X_train, y_train)
# 在验证集上评估模型性能以避免过拟合
val_pred = svm.predict(X_val)
val_accuracy = accuracy_score(y_val, val_pred)
print("验证集准确率:", val_accuracy)
# 在测试集上评估模型性能
test_pred = svm.predict(X_test)
test_accuracy = accuracy_score(y_test, test_pred)
print("测试集准确率:", test_accuracy)
测试集准确率: 0.9722222222222222
结果说明:SVM向量机算法模型在红酒数据集上的性能表现优于决策树分类模型。