1. 结构图
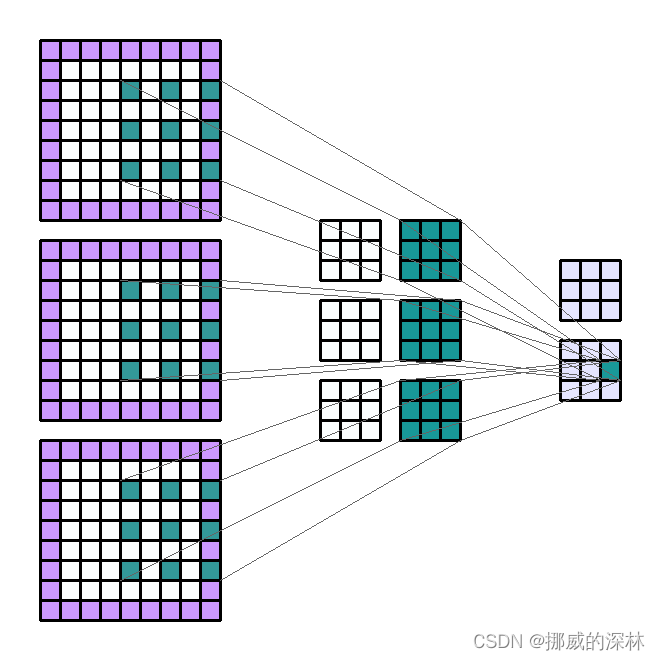
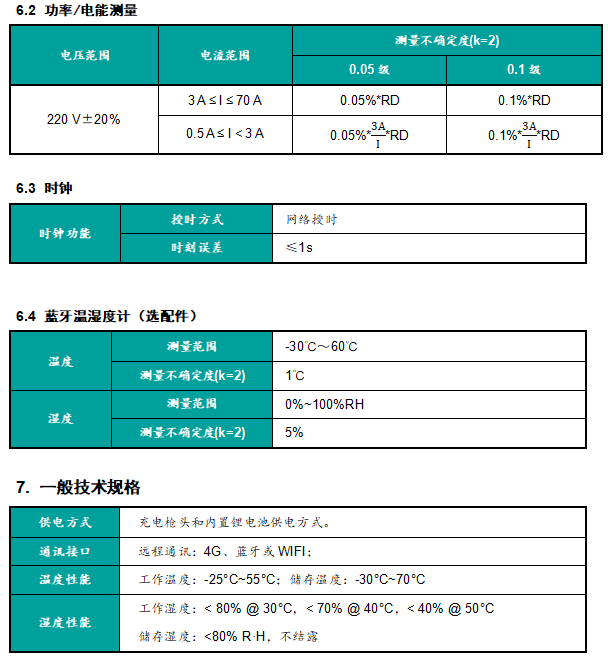
Input Shape : (3, 7, 7) — Output Shape : (2, 3, 3) — K : (3, 3) — P : (1, 1) — S : (2, 2) — D : (2, 2) — G : 1
The parts of this post will be divided according to the following arguments. These arguments can be found in the Pytorch documentation of the Conv2d module :
- in_channels (int) — Number of channels in the input image
- out_channels (int) — Number of channels produced by the convolution
- kernel_size (int or tuple) — Size of the convolving kernel
- stride (int or tuple, optional) — Stride of the convolution. Default: 1
- padding (int or tuple, optional) — Zero-padding added to both sides of the input. Default: 0
- dilation (int or tuple, optional) — Spacing between kernel elements. Default: 1
- groups (int, optional) — Number of blocked connections from input channels to output channels. Default: 1
- bias (bool, optional) — If
True, adds a learnable bias to the output. Default:True
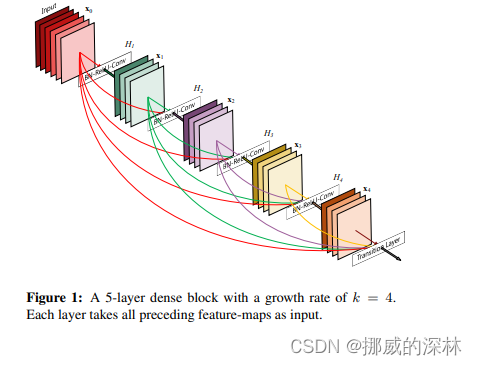
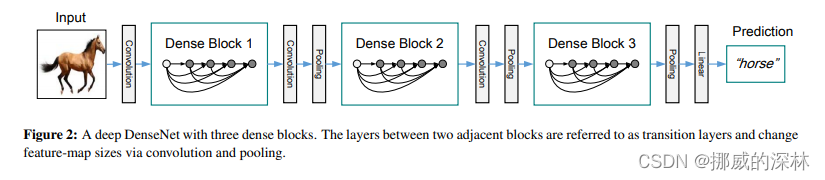
- 在Fig 1中, the last layer is called the translation layer. this layer is responsible for the reducing of the dimension (如图 2, pooling)
- 尽管该技术可以阻断identity backpropagation, 但是这仅仅发生在DenseNet block中的部分layers, 并不影响梯度流
- DenseNet 的代码结构主要分为以下三块
#. DenseLayer: 其主要在 DenseBlock 中完成一个单个的layer
#. DenseBlock:
#. TransitionLayer
2. 建立模型


O= Size (width) of output image.
I= Size (width) of input image.
N= Size (width) of kernels used in the Conv Layer.
K= Number of kernels.
S= Stride of the convolution operation.
P= Padding.
The size O of the output image is given by
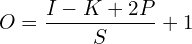
class _DenseLayer(nn.Module):
def __init__(
self, num_input_features: int, growth_rate: int, bn_size: int, drop_rate: float, memory_efficient: bool = False
) -> None:
super().__init__()
self.norm1 = nn.BatchNorm2d(num_input_features)
self.relu1 = nn.ReLU(inplace=True)
self.conv1 = nn.Conv2d(num_input_features, bn_size * growth_rate, kernel_size=1, stride=1, bias=False)
self.norm2 = nn.BatchNorm2d(bn_size * growth_rate)
self.relu2 = nn.ReLU(inplace=True)
self.conv2 = nn.Conv2d(bn_size * growth_rate, growth_rate, kernel_size=3, stride=1, padding=1, bias=False)
self.drop_rate = float(drop_rate)
self.memory_efficient = memory_efficient
def bn_function(self, inputs: List[Tensor]) -> Tensor:
concated_features = torch.cat(inputs, 1)
bottleneck_output = self.conv1(self.relu1(self.norm1(concated_features))) # noqa: T484
return bottleneck_output
# todo: rewrite when torchscript supports any
def any_requires_grad(self, input: List[Tensor]) -> bool:
for tensor in input:
if tensor.requires_grad:
return True
return False
@torch.jit.unused # noqa: T484
def call_checkpoint_bottleneck(self, input: List[Tensor]) -> Tensor:
def closure(*inputs):
return self.bn_function(inputs)
return cp.checkpoint(closure, *input)
@torch.jit._overload_method # noqa: F811
def forward(self, input: List[Tensor]) -> Tensor: # noqa: F811
pass
@torch.jit._overload_method # noqa: F811
def forward(self, input: Tensor) -> Tensor: # noqa: F811
pass
# torchscript does not yet support *args, so we overload method
# allowing it to take either a List[Tensor] or single Tensor
def forward(self, input: Tensor) -> Tensor: # noqa: F811
if isinstance(input, Tensor):
prev_features = [input]
else:
prev_features = input
if self.memory_efficient and self.any_requires_grad(prev_features):
if torch.jit.is_scripting():
raise Exception("Memory Efficient not supported in JIT")
bottleneck_output = self.call_checkpoint_bottleneck(prev_features)
else:
bottleneck_output = self.bn_function(prev_features)
new_features = self.conv2(self.relu2(self.norm2(bottleneck_output)))
if self.drop_rate > 0:
new_features = F.dropout(new_features, p=self.drop_rate, training=self.training)
return new_features
class _DenseBlock(nn.ModuleDict):
_version = 2
def __init__(
self,
num_layers: int,
num_input_features: int,
bn_size: int,
growth_rate: int,
drop_rate: float,
memory_efficient: bool = False,
) -> None:
super().__init__()
for i in range(num_layers):
layer = _DenseLayer(
num_input_features + i * growth_rate,
growth_rate=growth_rate,
bn_size=bn_size,
drop_rate=drop_rate,
memory_efficient=memory_efficient,
)
self.add_module("denselayer%d" % (i + 1), layer)
def forward(self, init_features: Tensor) -> Tensor:
features = [init_features]
for name, layer in self.items():
new_features = layer(features)
features.append(new_features)
return torch.cat(features, 1)
class _Transition(nn.Sequential):
def __init__(self, num_input_features: int, num_output_features: int) -> None:
super().__init__()
self.norm = nn.BatchNorm2d(num_input_features)
self.relu = nn.ReLU(inplace=True)
self.conv = nn.Conv2d(num_input_features, num_output_features, kernel_size=1, stride=1, bias=False)
self.pool = nn.AvgPool2d(kernel_size=2, stride=2)
class DenseNet(nn.Module):
r"""Densenet-BC model class, based on
`"Densely Connected Convolutional Networks" <https://arxiv.org/pdf/1608.06993.pdf>`_.
Args:
growth_rate (int) - how many filters to add each layer (`k` in paper)
block_config (list of 4 ints) - how many layers in each pooling block
num_init_features (int) - the number of filters to learn in the first convolution layer
bn_size (int) - multiplicative factor for number of bottle neck layers
(i.e. bn_size * k features in the bottleneck layer)
drop_rate (float) - dropout rate after each dense layer
num_classes (int) - number of classification classes
memory_efficient (bool) - If True, uses checkpointing. Much more memory efficient,
but slower. Default: *False*. See `"paper" <https://arxiv.org/pdf/1707.06990.pdf>`_.
"""
def __init__(
self,
growth_rate: int = 32,
block_config: Tuple[int, int, int, int] = (6, 12, 24, 16),
num_init_features: int = 64,
bn_size: int = 4,
drop_rate: float = 0,
num_classes: int = 1000,
memory_efficient: bool = False,
) -> None:
super().__init__()
# _log_api_usage_once(self)
# First convolution
self.features = nn.Sequential(
OrderedDict(
[
("conv0", nn.Conv2d(3, num_init_features, kernel_size=7, stride=2, padding=3, bias=False)),
("norm0", nn.BatchNorm2d(num_init_features)),
("relu0", nn.ReLU(inplace=True)),
("pool0", nn.MaxPool2d(kernel_size=3, stride=2, padding=1)),
]
)
)
# Each denseblock
num_features = num_init_features
for i, num_layers in enumerate(block_config):
block = _DenseBlock(
num_layers=num_layers,
num_input_features=num_features,
bn_size=bn_size,
growth_rate=growth_rate,
drop_rate=drop_rate,
memory_efficient=memory_efficient,
)
self.features.add_module("denseblock%d" % (i + 1), block)
num_features = num_features + num_layers * growth_rate
if i != len(block_config) - 1:
trans = _Transition(num_input_features=num_features, num_output_features=num_features // 2)
# self.features.add_module("transition%d" % (i + 1), trans)
# num_features = num_features // 2
# Final batch norm
self.features.add_module("norm5", nn.BatchNorm2d(num_features))
# Linear layer
self.classifier = nn.Linear(num_features, num_classes)
# Official init from torch repo.
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight)
elif isinstance(m, nn.BatchNorm2d):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
elif isinstance(m, nn.Linear):
nn.init.constant_(m.bias, 0)
def forward(self, x: Tensor) -> Tensor:
features = self.features(x)
out = F.relu(features, inplace=True)
out = F.adaptive_avg_pool2d(out, (1, 1))
out = torch.flatten(out, 1)
out = self.classifier(out)
return out