在影视、有声书内容中,背景音是一种表现丰富的艺术形式。语音转换(Voice Conversion)如能将源说话人语音转换成目标说话人语音的同时,保留源语音中的背景音,将会提供更沉浸的语音转换体验。之前的语音转换研究主要关注于干净语音,对于带有背景音的语音转换进行的研究相对较少。在语音转换中保留背景音的关键问题中,除语音分离模型引起的不可避免的语音失真外,还存在分离模型与语音转换模型之间级联造成的训练目标不匹配问题。
为了解决上述问题,西工大音频语音与语言处理研究组被ICASSP2023接收的论文“Preserving background sound in noise-robust voice conversion via multi-task learning”,提出了一种基于多任务学习的端到端框架,通过顺序级联源语音的分离模块、瓶颈特征提取模块和语音转换模块,以实现转换后语音保留源语音背景音的功能。语音分离任务明确考虑了关键的相位信息,并有效限制了由不完美分离过程引起的失真。同时,分离任务、典型的语音转换任务和统一任务共享联合训练约束的统一重建损失,以减少分离模块和语音转换模块之间的不匹配。实验表明,该方案在说话人相似度与音质上显著优于基线系统,在保留背景音的同时,能够达到与基于干净数据训练的语音转换模型相当的转换效果。
论文题目:Preserving background sound in noise-robust voice conversion via multi-task learning
作者列表:姚继珣,雷怡,王晴,郭鹏程,宁子谦,谢磊,李海,刘俊晖,谢丹铭
合作单位:爱奇艺
论文原文:https://arxiv.org/abs/2211.03036

图1:发表论文截图
1. 背景动机
语音转换是一种能将原始说话人的语音转换为目标说话人的语音,并且保留原始语言内容的技术[1]。其在影视配音、个性化语音合成和语音隐私保护等各种应用方面具有多种潜在应用,一直以来备受关注。实际录音中的语音通常会伴有背景音,例如电影和有声书的混音音轨中既包含语音,同时带有各种背景音乐和音效等。这对当前的语音转换系统的鲁棒性提出了挑战。另一方面,在一些应用中,为了提供更好的听觉体验,在转换后的语音中保留源语音的背景音也是十分必要的。一个理想的语音转换系统应该是可控的,可以根据特定应用的需求保留或去除语音中背景音。此外,背景音对于基于语音转换的数据增广(data augmentation)也是一种有价值的资源,可用于提高包括语音识别在内的下游系统的鲁棒性。
传统的语音转换研究通常旨在从原始语音中分离语言内容和说话人音色,而没有明确处理原始语音中的背景音。然而,由于实际应用中的原始语音通常与背景声音混杂在一起,例如电影和有声读物中的混合音轨,这会对语音转换系统的鲁棒性造成挑战。常见的方法是使用额外的降噪模型来处理带噪语音,这虽然能在一定程度上抑制噪声,但由于不完美的降噪处理导致原始语音中不可避免的语音失真也会传递到下游任务,从而降低转换语音的质量。因此,需要探索一种解决原始语音中背景音保留的方法。
为了解决这一问题,我们提出了一个端到端多任务学习框架,用于在语音转换的同时保留源语音中的背景音。我们通过顺序级联一个语音分离模块、一个瓶颈特征提取模块和一个语音转换模块来构建端到端框架,并设计了多个特定的学习目标。具体而言,语音分离任务基于DCCRN模型[2],采用PLCPA损失和asymmetry 损失[3],显式考虑相位信息来限制语音失真。除了语音分离任务和语音转换任务之外,统一任务共享一个约束联合训练的统一重构损失,以减少语音分离和语音转换模块之间的不匹配,同时确保转换后语音的质量。实验表明所提出方法的显著优势。
2. 多任务学习框架

图3: 提出的多任务学习框架
图3(a) 展示了本文提出的多任务系统结构,其中BN代表瓶颈特征。该框架由语音分离模块、瓶颈特征提取模块和语音转换模块按顺序级联而成,并使用了多个特定设计的学习目标;(b) 图展示了语音分离模块的细节;(c) 图则展示了语音转换模块的细节,其中实线代表正向传播,虚线代表用于模块输出的损失函数。
2.1 语音分离模块
DCCRN是一个基于复数谱建模的语音增强模型[2],具有良好的性能。在原始的 DCCRN 模型中,通过对带噪语谱的实部和虚部进行处理,得到复数比率掩模 (CRM)。本文使用 DCCRN 作为语音分离模型,并通过增加干净语音的额外 CRM 来实现。图 3(b) 展示了这一过程。同时,我们使用 PLCPA-ASYM 损失函数来代替原始的比例不变信噪比 (SI-SNR) 损失函数,以限制语音失真并实现更好的功率控制,PLCPA-ASYM 损失函数如下:

2.2 语音转换模块
通过语音分离模块从带有背景声音的源波形中提取语音后,我们使用语音转换模块将语音转换为目标说话人的语音,如图3(c)所示。语音转换模块由卷积长短期记忆(Conv-LSTM)编码器和基于HiFiGAN的解码器组成。Conv-LSTM由三个卷积层块组成,后跟LeakyReLU激活函数。最终卷积层的输出传递给单个LSTM层。来自说话人查找表的说话人表征作为目标语音生成的条件。解码器的架构与HiFi-GAN 的配置相同。
2.3 多任务训练
在存在背景音的语音转换过程中,为了解决语音分离模块和语音转换模块之间不匹配问题,我们采用了多任务学习策略,分为以下步骤:
1)仅优化语音转换模块,使语音分离模块保持冻结状态;
2)使用PLCPA-ASYM损失对语音分离模块进行优化;
3)采用多任务学习方法对语音分离模块和语音转换模块进行联合优化,同时保持瓶颈特征提取模块的冻结状态。
多任务学习损失函数包含三部分:统一损失,源语音分离损失以及语音转换损失,如下所示:

3. 实验
3.1 实验数据
为了训练语音分离模块,我们从musdb18-train数据集中获取背景音,从VCTK数据集中获取语音。需要注意的是,我们不使用musdb18-train数据集中的人声通道。语音转换模块使用VCTK数据集进行训练,该数据集包含110名英语说话人,每个说话人提供400段录音。对于语音分离和语音转换模块的联合训练,我们混合了MUSDB18-train和VCTK数据集以进行背景音保留的语音转换任务的评估。我们随机选择背景音并处理为与语音相同长度的裁剪片段,信噪比范围为0到10 dB。
从VCTK数据集中随机选择了4个源说话人(p245、p264、p270和p361)和2个目标说话人(p294和p334),混合了来自MUSDB18-test数据集的片段进行评估。对于每个源和目标说话人,保留30个句话作为测试集。所有的训练和评估数据均为16 kHz采样率。
3.2 基线系统
为了公平比较,我们使用相同的语音转换模块对以下系统进行评估:1)Upper Bound,将音频从干净源语音进行转换,然后与原始背景声音叠加;2)Baseline1(Sep),包括一个语音转换模块和一个语音分离模型,与[4]使用相同的语音分离方法;3)Baseline2(Sep+Denoise),包括一个语音转换模块,与Baseline1相同的语音分离模型和与[5]相同的降噪模型。语音分离模型和降噪模型是在ISMIR和DNS挑战赛中均取得SOTA的流行开源模型。Baseline2可以被视为比[5]更为鲁棒的语音分离方法;4)Proposed,本文提出的多任务学习框架。
3.3 验证指标
为了比较所提出的框架与基线系统,我们进行了客观和主观评估。对于主观评估,使用对比平均意见分数(CMOS)来比较带有背景音的转换语音与基线系统,并使用Upper Bound结果作为参考来确定合成质量。为了更有效地评估音质和说话人相似性,还对没有叠加背景音的转换语音进行了平均意见分数(MOS)测试。采用SI-SDR、PESQ和客观差异度(ODG)作为客观指标,以评估分离的背景音和转换后的语音。
3.4 实验结果
主观结果 我们首先将对比系统与Upper Bound进行CMOS测试,评估背景音存在时语音转换的整体性能,如表1所示。CMOS的结果为:Sep方法为-0.54,Sep+Denoise方法为-0.35,而本文提出方法为-0.12。这表明,与基线系统相比,本文提出的框架在统计上显著优于基线系统。此外,得分为-0.12表明,所提出框架中背景音保留的转换语音在合成质量上与Upper Bound相比仅有轻微下降。
表1 主观评测结果

为了评估转换语音的音质和说话人相似性,我们对不同系统进行了MOS测试,如表1所示。为了获得更准确的评分结果,我们使用了未叠加背景音的转换语音进行主观听感测试。我们可以发现,与两个基线系统相比,所提出的框架在音质方面取得了更好的结果。同时还表明,同性之间的语音转换优于跨性别转换。而在说话人相似度方面,我们提出的框架在跨性别和同性别转换时均显著优于基线。主观结果表明,所提出的多任务学习框架可以有效处理背景音,将源音色转换为目标说话人音色,同时在转换后的语音中保留源语音中的背景音。
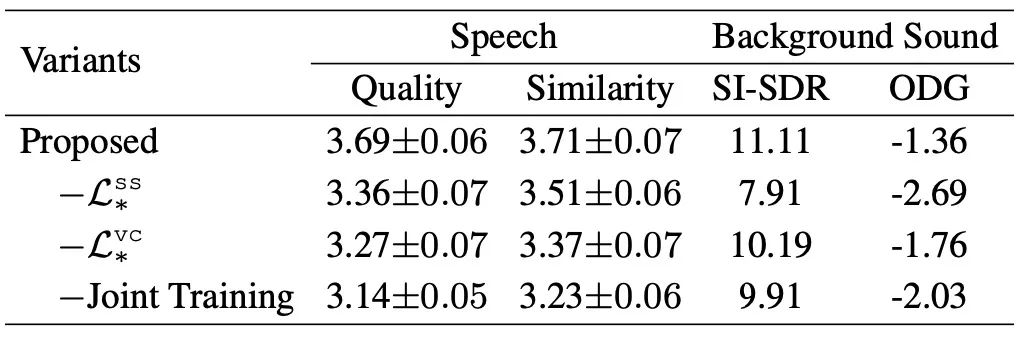
客观结果 客观实验结果如表2所示。针对语音部分的评估,我们的提出的框架在SI-SDR和PESQ指标上均比两个基线系统得分更高,这证实了该框架在分离语音方面的良好性能。此外,我们发现Sep+Denoise的PESQ得分与我们提出的框架相同。在背景音部分,我们的提出的框架优于两个基线系统,在SI-SDR和ODG指标中得分最高,即11.11和-1.36。根据客观结果,我们的多任务学习框架可以通过单个语音分离模块实现比基线系统更好的分离结果。
表2 客观测评结果

消融实验 在消融实验中,我们在联合训练过程中分别去除了语音分离任务的损失和语音转换任务的损失,并对比了不同变体。结果表明,去除语音转换损失“-Lvc”和去除语音分离损失“-Lss”都会导致主客观指标下降。去除“Lss”时,背景音的分离性能会大幅下降,SI-SDR和ODG指标均变差。而变体“-Lvc”虽然在ODG方面略有改善,但在音质和说话人相似性方面表现更差。这表明,去除语音转换损失会使得变体更关注语音分离任务。此外,没有进行联合训练的变体也会导致语音和背景音性能的下降。我们认为,这是由于在将分离结果直接用于转换时,语音分离模块和语音转换模块不匹配,从而导致转换语音存在失真。消融实验进一步验证了我们提出的基于多任务学习的语音转换方法对于带背景声音的语音转换的有效性,既能保证转换语音的音质、说话人相似性,同时将源语音中的背景音迁移到转换语音中。
表3 消融实验结果
参考文献
[1] Berrak Sisman, Junichi Yamagishi, Simon King, and Haizhou Li, “An overview of voice conversion and its challenges: From statistical modeling to deep learning,” IEEE/ACM Trans Audio Speech Lang. Process., vol. 29, pp. 132–157, 2020.
[2] Yanxin Hu, Yun Liu, ShuboLv, MengtaoXing, ShiminZhang, Yihui Fu, Jian Wu, Bihong Zhang, and Lei Xie, “DCCRN: deep complex convolution recurrent network for phase-aware speech enhancement,” in Proc. Interspeech, 2020, pp. 2472– 2476.
[3] Sefik Emre Eskimez, Takuya Yoshioka, Huaming Wang, Xiaofei Wang, Zhuo Chen, and Xuedong Huang, “Personalized speech enhancement: new models and comprehensive evaluation,” in Proc. ICASSP, 2022, pp. 356–360.
[4] Divyesh G. Rajpura, Jui Shah, Maitreya Patel, Harshit Malaviya, Kirtana Phatnani, and Hemant A. Patil, “Effectiveness of transfer learning on singing voice conversion in the presence of background music,” in Proc. SPCOM, 2020, pp.1–5.
[5] Chao Xie, Yi-Chiao Wu, Patrick Lumban Tobing, Wen-Chin Huang, and Tomoki Toda, “Direct noisy speech modeling for noisy-to-noisy voice conversion,” in Proc. ICASSP, 2022, pp.6787–6791.




![[ROC-RK3568-PC] [Firefly-Android] 10min带你了解Camera的使用](https://img-blog.csdnimg.cn/bab327e98da44a5d9f771d59909d698d.png)