MapReduce Partition 分区
MapReduce输出结果个数研究
-
在默认情况下
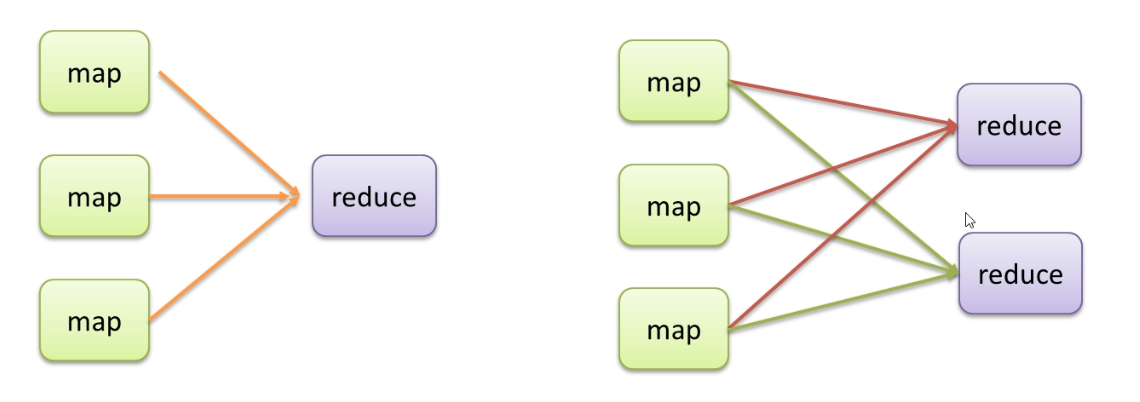
不管Map阶段有多少个并发执行的task,到Reduce阶段,所有结果都将有一个task来进行处理,并且最终结果将输出到一个文件中,part-r-0000。

-
可以进行手动的设置reduceTask的个数
JavaAPI中设置:job.setNumReduceTasks(int number);
设置的个数为几,就会产生几个文件,默认情况下为1,可见输出结果文件的个数和reducetask的个数是一个对等的关系。
-
数据分区
当MapReduce中有多个reducetask执行时,此时MapTask的输出就面领着一个问题:
究竟将自己的输出数据交给哪一个reducetask来进行处理?这就是所谓的数据分区问题(partition)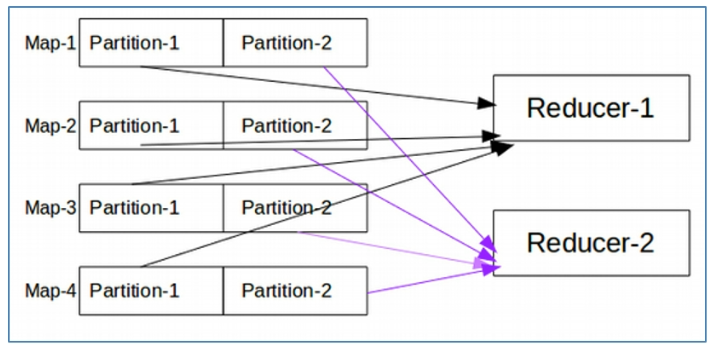
Partition概念
-
默认情况下MapReduce是只有一个Reducetask进行数据的处理,这使得不管输出的数据量多大,最终的结果都是输出到一个文件中。
-
当改变ReduceTask的个数的时候,作为maptask就会涉及到分区的问题,即:
MapTask输出的结果如何分配给各个ReduceTask来处理。
Partition默认规则
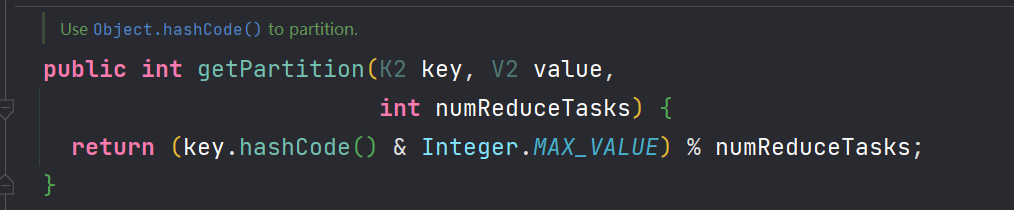
- MapReduce默认分区规则是
HashPartitioner - 分区结果和Map输出的key相关:
Partition注意事项
ReduceTask个数的改变导致了数据分区的产生,而不是有数据分区导致了ReduceTask个数的改变- 数据分区的
核心是分区的规则,即如何分配数据各个ReduceTask - 默认的规则可以保证
只要Map阶段输出的key一样,数据就一定可以分取到一个ReduceTask,但是不能保证数据平均分区 - ReduceTask个数的改变还会导致输出结果文件不再是一个整体,而是输出到多个文件中
MapReduce Combiner规约
数据归约的含义
- 数据规约是指在尽可能
保持数据原貌的前提下,最大限度的精简数据量
MapReduce 弊端
- MapReduce是一种具有两个执行阶段的分布式计算程序,Map阶段和Reduce阶段之间会涉及到跨网络数据传递。
- 每一个MapTask都可能产生大量的本地输出,这就导致跨网络传输数据量变大,网络IO性能低,比如WordCount单词统计案例,加入文件中又1000个单词,但是999个为hello,那么就会产生999个<hello,1>的键值对在网络中进行传输,使其性能低下
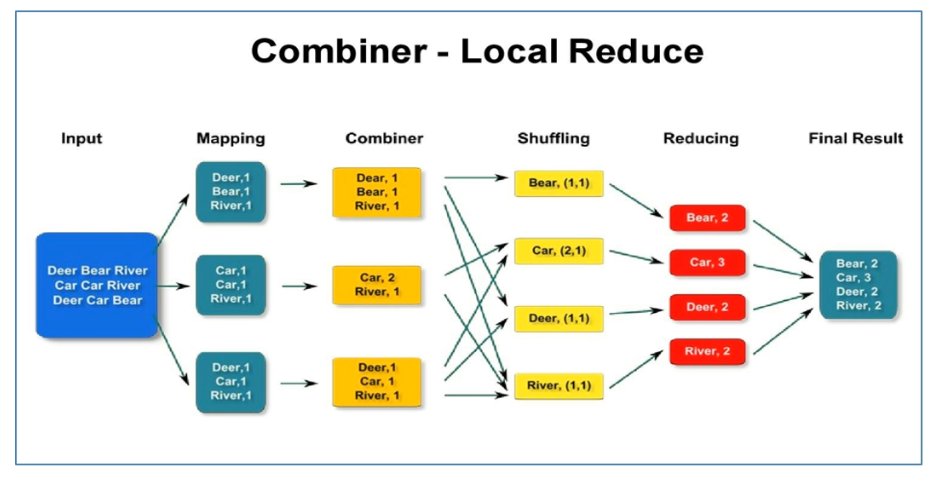
Combiner组件概念
- Combiner中文: 规约,是MapReduce的一种优化手段
- Combiner的作用就
是对Map端的输出先做一次局部合并,以减少Map和Reduce节点之间的数据传输量
Combiner组件的使用
-
Combiner是MapReduce程序中出了Mapper和Reducer之外的一种组件,
默认情况下不启用 -
Combiner本质上就是Reducer,combiner和reducer的区别在于运行的位置:
Combiner是在每一个MapTask所在的节点本地运行,是局部聚合
Reducer是对所有的MapTask的输出结果计算,是全局聚合 -
具体实现步骤:
-
自定义一个CustomCombiner类,继承Reducer,重写Reducer方法
-
job.setCombinerClass(CustomCombiner.class)
-
Combiner使用注意事项
- Combiner能够应用的前提是不能影响最终的业务逻辑,而且,Combiner的输出kv应该跟Reduce的输出KV类型对应起来
- 以下业务禁止使用Combiner,因为这样不仅优化了网络传输数据量,还改变了最终的执行结果:
- 业务和数据个数相关的
- 业务和整体排序相关的
Combiner组件不是禁用,而是慎用,用的好可以提高程序性能,用的不好,改变程序结果且不易被发现