自动化的运维管理:探究Kubernetes工作机制的奥秘
文章目录
- 1. 云计算时代的操作系统
- 2. kubernets 的基本架构
- 3.节点内部的结构
- 3.1 master 节点
- 3.2 node 节点
- 4. Kubernetes 的大致工作流程
- 5.插件有哪些?
- 5.1 重要的插件
- 6. kubernetes 架构思维导图
- 7. 思考的问题
- 7.1你觉得 Kubernetes 算得上是一种操作系统吗?和真正的操作系统相比有什么差异?
- 7.2说说你理解的 Kubernetes 组件的作用,你觉得哪几个最重要?
1. 云计算时代的操作系统
Kubernetes 是一个生产级别的容器编排平台和集群管理系统,能够创建、调度容器,监控、管理服务器。容器是什么?
容器是软件,是应用,是进程。服务器是什么?服务器是硬件,是 CPU、内存、硬盘、网卡。那么,既可以管理软件,也可以管理硬件,这样的东西应该是什么?你也许会脱口而出:这就是一个操作系统(Operating System)!
没错,从某种角度来看,Kubernetes 可以说是一个集群级别的操作系统,主要功能就是资源管理和作业调度。但 Kubernetes 不是运行在单机上管理单台计算资源和进程,而是运行在多台服务器上管理几百几千台的计算资源,以及在这些资源上运行的上万上百万的进程,规模要大得多。

2. kubernets 的基本架构
操作系统的一个重要功能就是抽象,从繁琐的底层事务中抽象出一些简洁的概念,然后基于这些概念去管理系统资源。
Kubernetes 也是这样,它的管理目标是大规模的集群和应用,必须要能够把系统抽象到足够高的层次,分解出一些松耦合的对象,才能简化系统模型,减轻用户的心智负担。
所以,Kubernetes 扮演的角色就如同一个“大师级别”的系统管理员,具有丰富的集群运维经验,独创了自己的一套工作方式,不需要太多的外部干预,就能够自主实现原先许多复杂的管理工作。
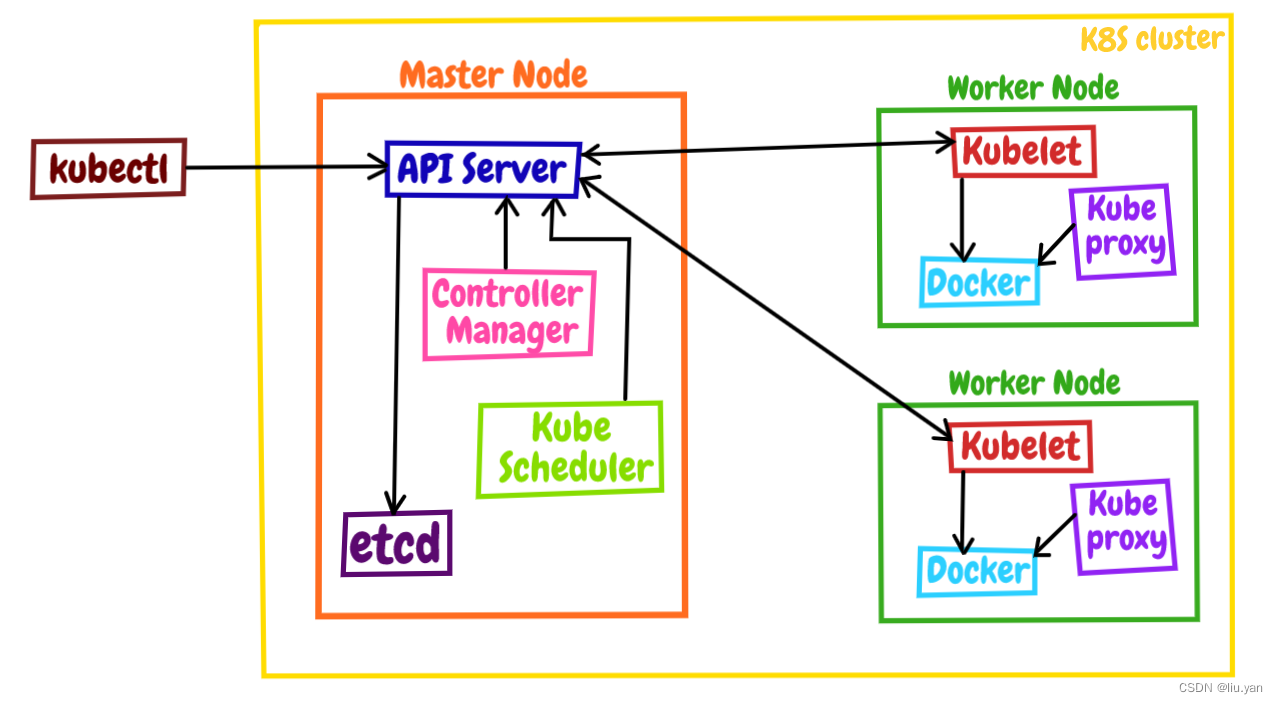
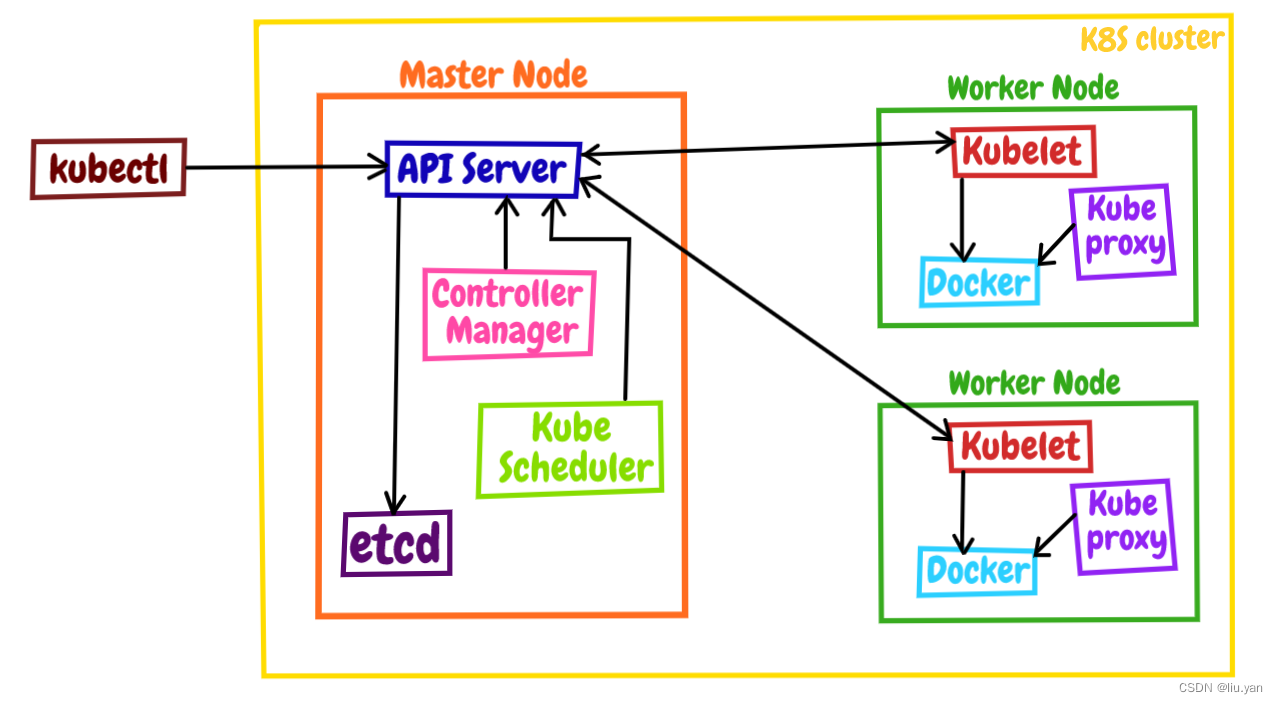
ubernetes 采用了现今流行的“控制面 / 数据面”(Control Plane / Data Plane)架构,集群里的计算机被称为“节点”(Node),可以是实机也可以是虚机,少量的节点用作控制面来执行集群的管理维护工作,其他的大部分节点都被划归数据面,用来跑业务应用。
控制面的节点在 Kubernetes 里叫做 Master Node,一般简称为 Master,它是整个集群里最重要的部分,可以说是 Kubernetes 的大脑和心脏。
数据面的节点叫做 Worker Node,一般就简称为 Worker 或者 Node,相当于 Kubernetes 的手和脚,在 Master 的指挥下干活。
Node 的数量非常多,构成了一个资源池,Kubernetes 就在这个池里分配资源,调度应用。因为资源被“池化”了,所以管理也就变得比较简单,可以在集群中任意添加或者删除节点。
在这张架构图里,我们还可以看到有一个 kubectl,它就是 Kubernetes 的客户端工具,用来操作 Kubernetes,但它位于集群之外,理论上不属于集群。
你可以使用命令 kubectl get node 来查看 Kubernetes 的节点状态:kubectl get node

3.节点内部的结构
3.1 master 节点
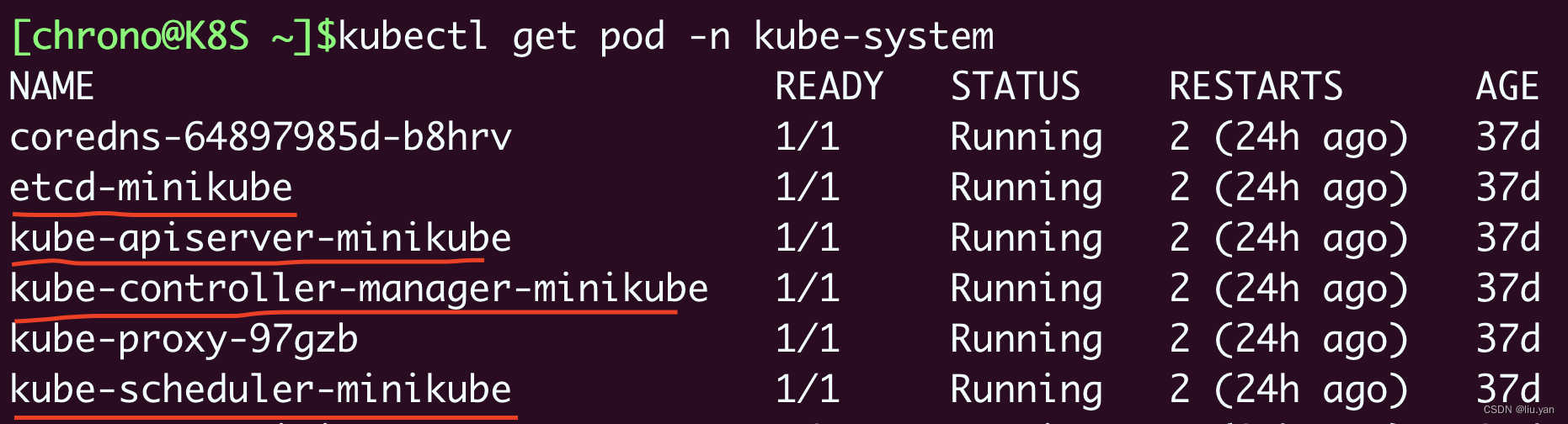
Master 里有 4 个组件,分别是 apiserver、etcd、scheduler、controller-manager
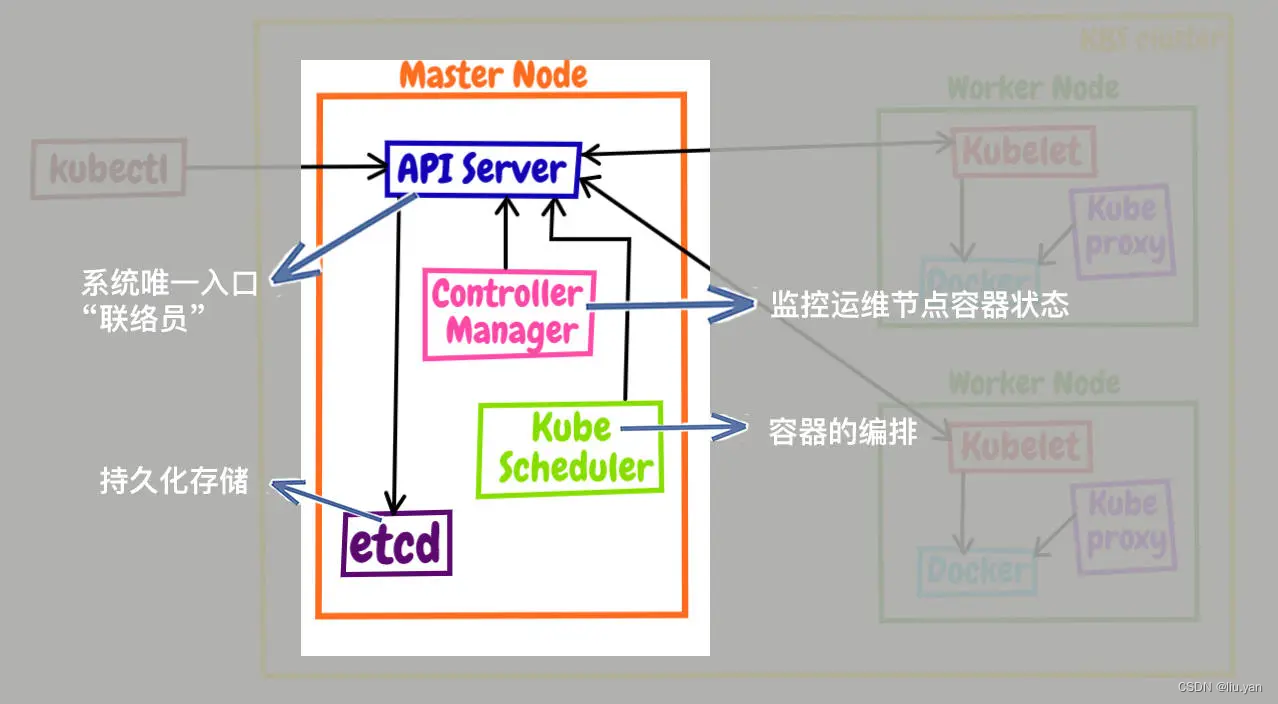
piserver 是 Master 节点——同时也是整个 Kubernetes 系统的唯一入口,它对外公开了一系列的 RESTful API,并且加上了验证、授权等功能,所有其他组件都只能和它直接通信,可以说是 Kubernetes 里的联络员。
etcd 是一个高可用的分布式 Key-Value 数据库,用来持久化存储系统里的各种资源对象和状态,相当于 Kubernetes 里的配置管理员。注意它只与 apiserver 有直接联系,也就是说任何其他组件想要读写 etcd 里的数据都必须经过 apiserver。
scheduler 负责容器的编排工作,检查节点的资源状态,把 Pod 调度到最适合的节点上运行,相当于部署人员。因为节点状态和 Pod 信息都存储在 etcd 里,所以 scheduler 必须通过 apiserver 才能获得。
controller-manager 负责维护容器和节点等资源的状态,实现故障检测、服务迁移、应用伸缩等功能,相当于监控运维人员。同样地,它也必须通过 apiserver 获得存储在 etcd 里的信息,才能够实现对资源的各种操作。这 4 个组件也都被容器化了,运行在集群的 Pod 里,我们可以用 kubectl 来查看它们的状态,使用命令:
3.2 node 节点
Master 里的 apiserver、scheduler 等组件需要获取节点的各种信息才能够作出管理决策,那这些信息该怎么来呢?
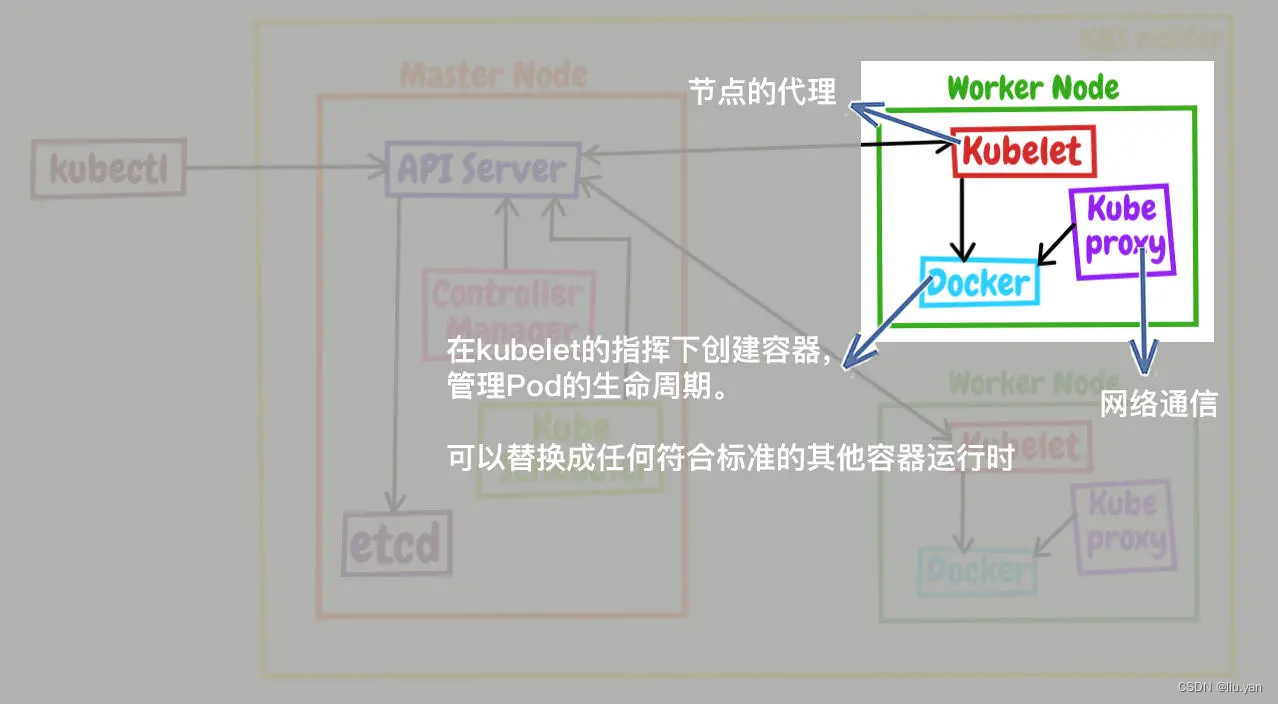
这就需要 Node 里的 3 个组件了,分别是 kubelet、kube-proxy、container-runtime。
kubelet 是 Node 的代理,负责管理 Node 相关的绝大部分操作,Node 上只有它能够与 apiserver 通信,实现状态报告、命令下发、启停容器等功能,相当于是 Node 上的一个“小管家”。
kube-proxy 的作用有点特别,它是 Node 的网络代理,只负责管理容器的网络通信,简单来说就是为 Pod 转发 TCP/UDP 数据包,相当于是专职的“小邮差”。
第三个组件 container-runtime 我们就比较熟悉了,它是容器和镜像的实际使用者,在 kubelet 的指挥下创建容器,管理 Pod 的生命周期,是真正干活的“苦力”
4. Kubernetes 的大致工作流程
- 每个 Node 上的 kubelet 会定期向 apiserver 上报节点状态,apiserver 再存到 etcd 里。
- 每个 Node 上的 kube-proxy 实现了 TCP/UDP 反向代理,让容器对外提供稳定的服务。
- scheduler 通过 apiserver 得到当前的节点状态,调度 Pod,然后 apiserver 下发命令给某个 Node 的 kubelet,kubelet 调用 container-runtime 启动容器。
- controller-manager 也通过 apiserver 得到实时的节点状态,监控可能的异常情况,再使用相应的手段去调节恢复。
这些组件就好像是无数个不知疲倦的运维工程师,把原先繁琐低效的人力工作搬进了高效的计算机里,就能够随时发现集群里的变化和异常,再互相协作,维护集群的健康状态。
5.插件有哪些?
只要服务器节点上运行了 apiserver、scheduler、kubelet、kube-proxy、container-runtime 等组件,就可以说是一个功能齐全的 Kubernetes 集群了。
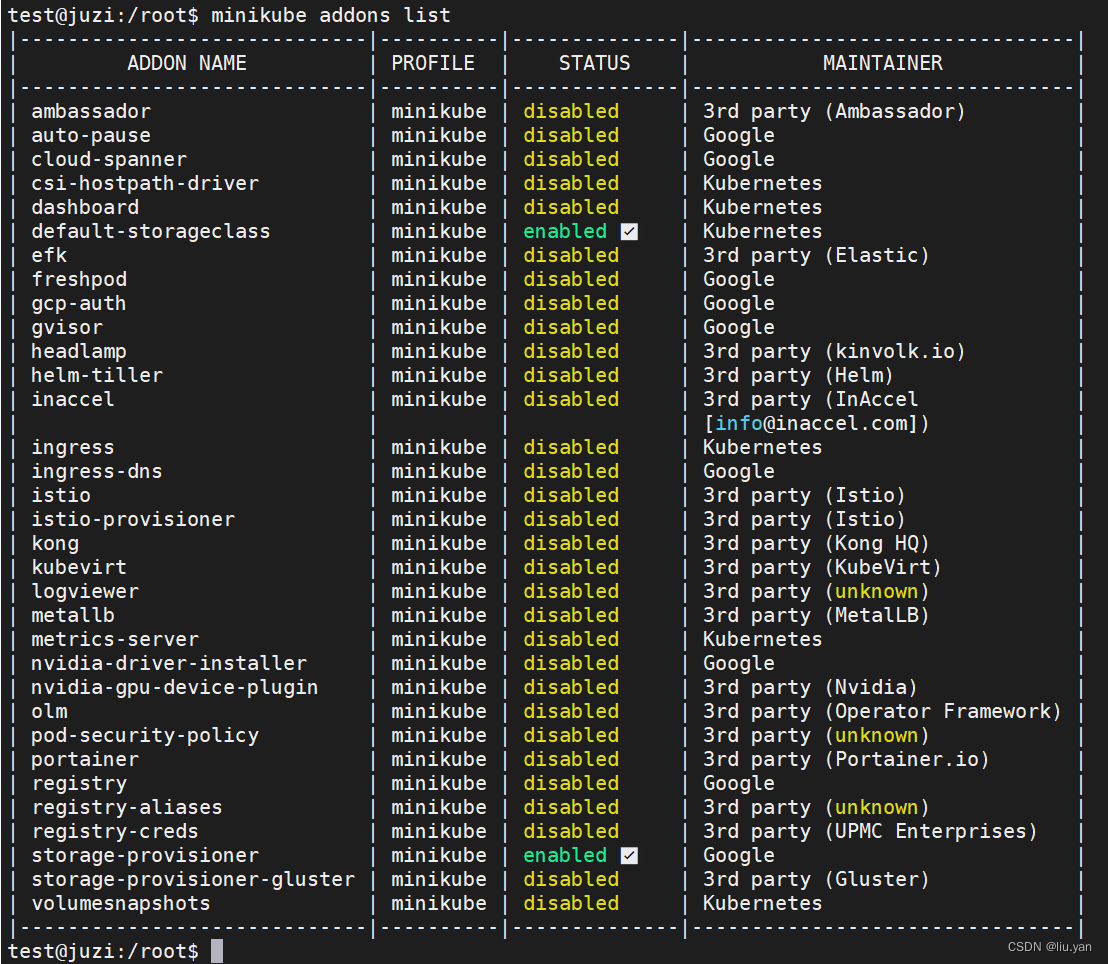
不过就像 Linux 一样,操作系统提供的基础功能虽然“可用”,但想达到“好用”的程度,还是要再安装一些附加功能,这在 Kubernetes 里就是插件(Addon)。
由于 Kubernetes 本身的设计非常灵活,所以就有大量的插件用来扩展、增强它对应用和集群的管理能力。
minikube 也支持很多的插件,使用命令 minikube addons list 就可以查看插件列表:
5.1 重要的插件
插件中我个人认为比较重要的有两个:DNS 和 Dashboard。
DNS 你应该比较熟悉吧,它在 Kubernetes 集群里实现了域名解析服务,能够让我们以域名而不是 IP 地址的方式来互相通信,是服务发现和负载均衡的基础。由于它对微服务、服务网格等架构至关重要,所以基本上是 Kubernetes 的必备插件。
Dashboard 就是仪表盘,为 Kubernetes 提供了一个图形化的操作界面,非常直观友好,虽然大多数 Kubernetes 工作都是使用命令行 kubectl,但有的时候在 Dashboard 上查看信息也是挺方便的。你只要在 minikube 环境里执行一条简单的命令,就可以自动用浏览器打开 Dashboard 页面,而且还支持中文:
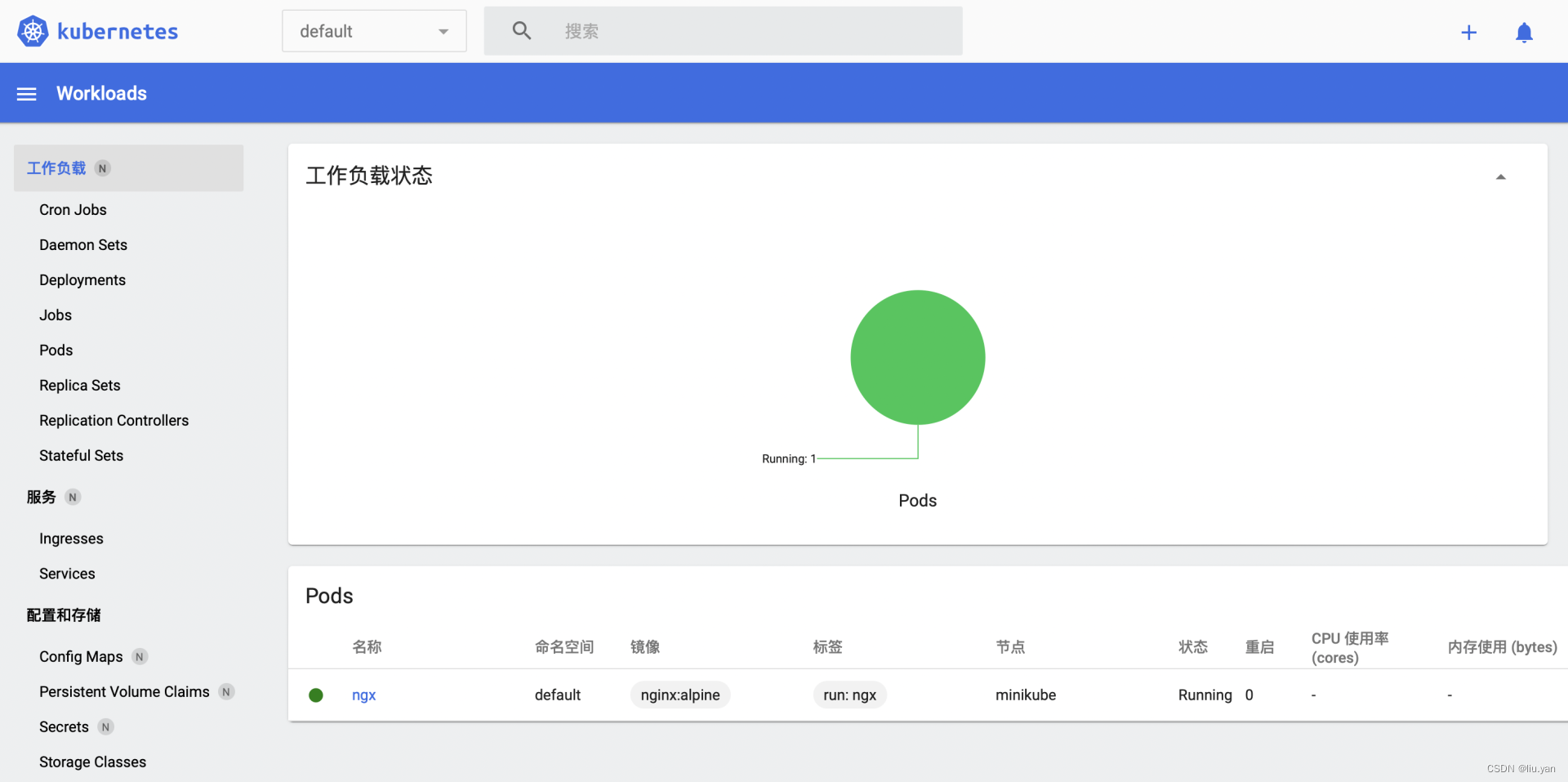
6. kubernetes 架构思维导图
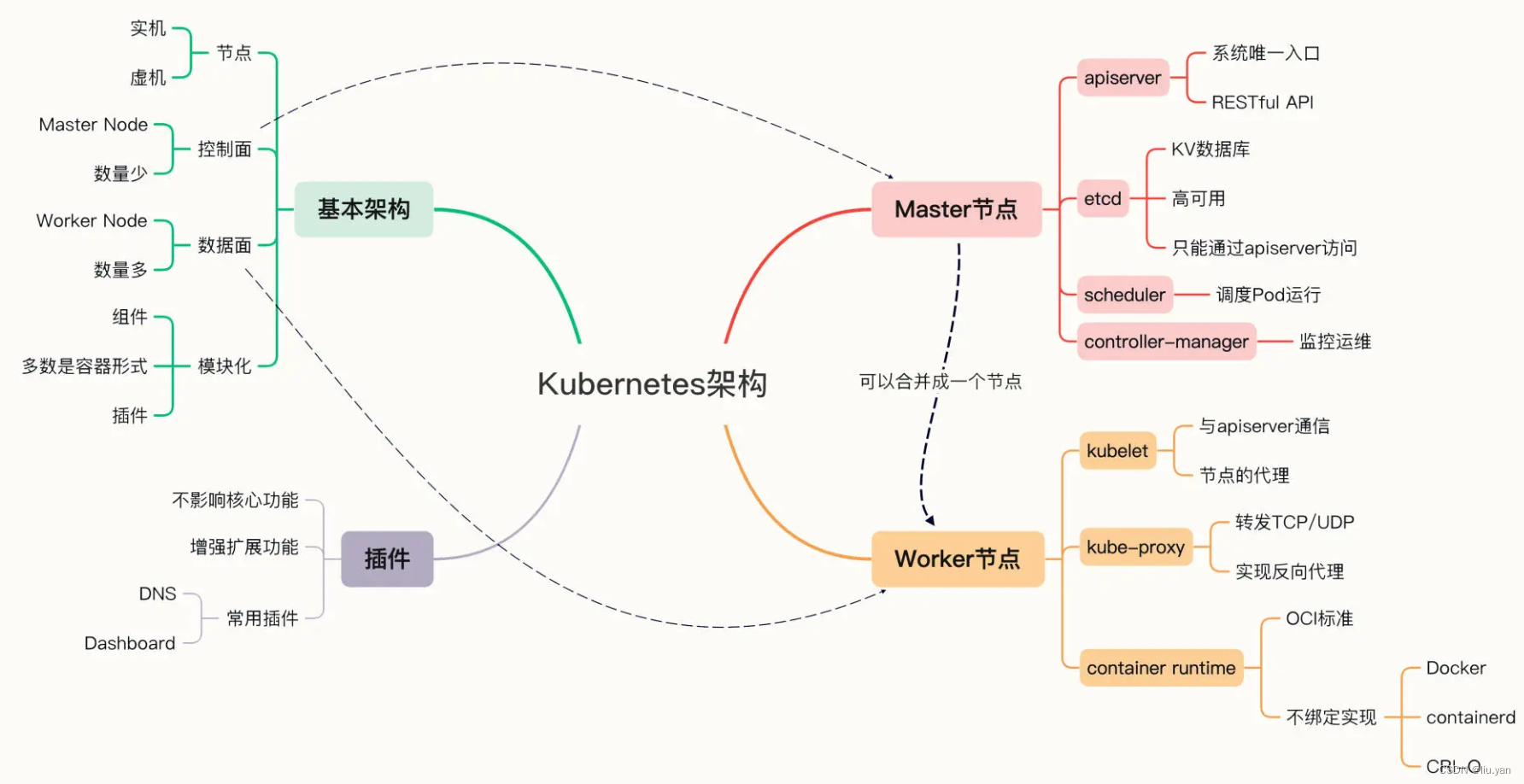
小结:
- Kubernetes 能够在集群级别管理应用和服务器,可以认为是一种集群操作系统。它使用“控制面 / 数据面”的基本架构,Master 节点实现管理控制功能,Worker 节点运行具体业务。
- Kubernetes 由很多模块组成,可分为核心的组件和选配的插件两类。
- Master 里有 4 个组件,分别是 apiserver、etcd、scheduler、controller-manager。
- Node 里有 3 个组件,分别是 kubelet、kube-proxy、container-runtime。
- 通常必备的插件有 DNS 和 Dashboard。
7. 思考的问题
7.1你觉得 Kubernetes 算得上是一种操作系统吗?和真正的操作系统相比有什么差异?
k8s 感觉更像是一个介于操作系统和应用之间的服务,相比传统的操作系统,它提供了更强大的资源抽象功能