1、问题现象
某一天,项目组一个同事向我反馈,他们使用公司的数据同步产品将MySQL数据同步到MQ集群,然后使用消费者将数据再同步到ES,反馈数据同步延迟严重,但对应的消费组确没有积压,但最近最近几分钟的数据都没有同步过来。
那问题来了,消费端没有消费积压,而且通过查看数据同步平台该通过任务的同步状态,同样显示没有积压,那是为什么呢?
遇到这个问题,我们应该冷静下来,分析一下其大概的数据流向图,梳理后如下图所示:

通过初步的诊断,从数据同步产品查看Binlog同步无延迟、MQ消费无积压,那为什么最终Es集群中的数据与MySQL有高达几分钟的延迟呢?
2、问题排查
根据上图几个关键组件数据同步延迟的检测,基本就排除了数据同步组件、MQ消费端本身消费的问题,问题的症结应该就是数据同步组件成功将数据写入到MQ集群,并且MQ集群返回了写入成功,但消费端并没有及时感知这个消息,也就是说消息虽然写入到MQ集群,但并没有达到消费队列。
因为如果数据同步组件如果没有写入成功,则MySQL Binlog日志就会出现延迟。但如果是MQ消费端的问题,则MQ平台也会显示消费组积压。
那为什么消息服务器写入成功,但消费组为什么感知不到呢?
首先为了验证上述结论是否正确,我还特意去看了一下主题的详细信息:

查看主题的统计信息时发现当前系统的时间为19:01分, 但主题最新的写入时间才是18:50,两者之间相差将近10分钟。
备注:上述界面是我们公司内部的消息运营管理平台,其实底层是调用了RocketMQ提供的topicStatus命令。
那这又是怎么造成的呢?
在这里我假设大家对RocketMQ底层的实现原理还不是特别熟悉,在这样的情况下,我觉得我们应该首先摸清楚topicStatus这个命令返回的minOffset、maxOffset以及lastUpdate这些是的具体获取逻辑,只有了解了这些,我们才能寻根究底,最终找到解决办法。
2.1 问题探究与原理剖析
在这个场景中,我们可以通过对topicStatus命令进行解析,从而探究其背后的实现原理。
当我们在命令行中输入 sh ./mqadmin topicStatus命令时,最终是调用defaultMQAdminExtImpl的examineTopicStats方法,最终在服务端的处理逻辑定义在AdminBrokerProcessor的getTopicStatsInfo方法中,核心代码如下:
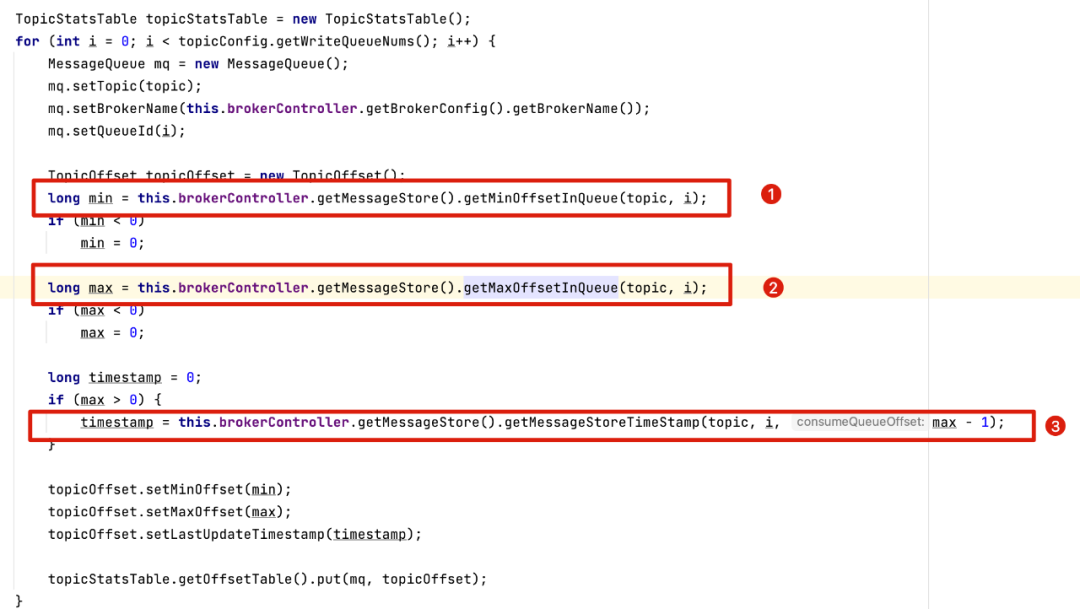
这里的实现要点:
-
通过MessageStore的getMinOffsetInQueue获取最小偏移量。
-
通过MessageStore的getMaxOffsetInQueue获取最大偏移量。
-
最新更新时间为最大偏移量减去一(表示最新一条消息)的存储时间
故要弄清队列最大、最小偏移量,关键是要看懂getMaxOffsetInQueue或者getMinOffsetInQueue的计算逻辑。
我也注意到分析源码虽然能直抵真相,但阅读起来太粗糙,所以我接下来的文章会尽量避免通篇的源码解读,取而代之的是只点出源码的入口处,其旁支细节将通过时序图获流程图,方便感兴趣的读者朋友去探究,我重点进行知识点的提炼,降低大家的学习成本。
如果大家想成体系的研究RocketMQ,想将消息中间件当成自己职业的闪光点,强烈建议购买我的两本关于RocketMQ的数据:《RocketMQ技术内幕》与《RocketMQ实战》。
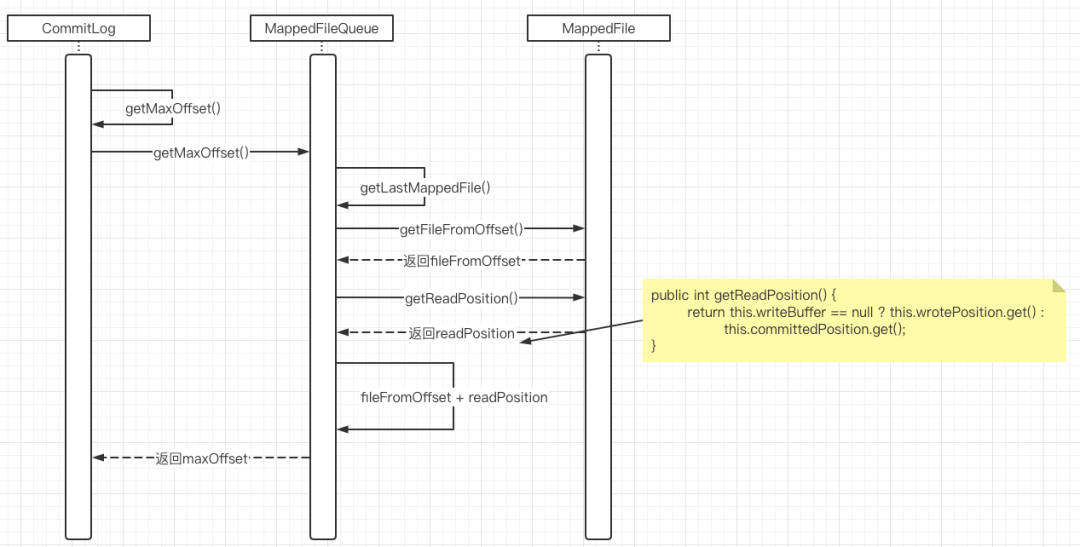
MessageStore的getMaxOffsetInQueue的时序图如下所示:
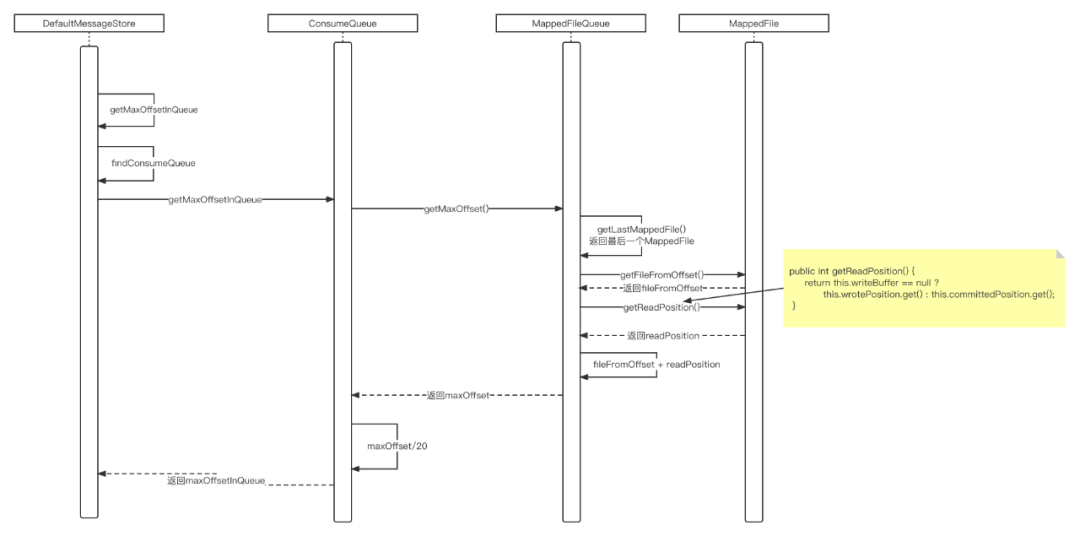
从上述时序图我们可以得知,调用DefaultMessageStore的getMaxOffsetInQueue方法,首先是根据主题、队列ID获取ConsumeQueue对象(在RocketMQ中一个主题的一个队列会对应一个ConsumeQueue,代表一个消费队列),也就是这里获取的偏移量指的是消费者队列中的偏移量,而不是Commitlog文件的偏移量。
如果是找最大偏移量,就从该队列中的找到最后一个文件,去获取器最大的有效偏移量,也就是等于文件的起始偏移量(fileFromOffset)加上该文件当前最大可读的偏移量(readPosition),故引起这张时序图一个非常关键的点,就是如何获取消费队列最大的可读偏移量,代码见MappedFile的getReadPosition:
public int getReadPosition() {
return this.writeBuffer == null ? this.wrotePosition.get() : this.committedPosition.get();
}
由于ConsumeQueue并没有 transientStorePoolEnable 机制,数据直接写入到FlieChannel中,故这里的writeBuffer为空,取的是 wrotePosition的值,那ConsumeQueue文件的wrotePosition值在什么地方更新呢?
这个可以通过查看MappedFile中修改wrotePosition的方法appendMessage方法的调用,如下图所示:
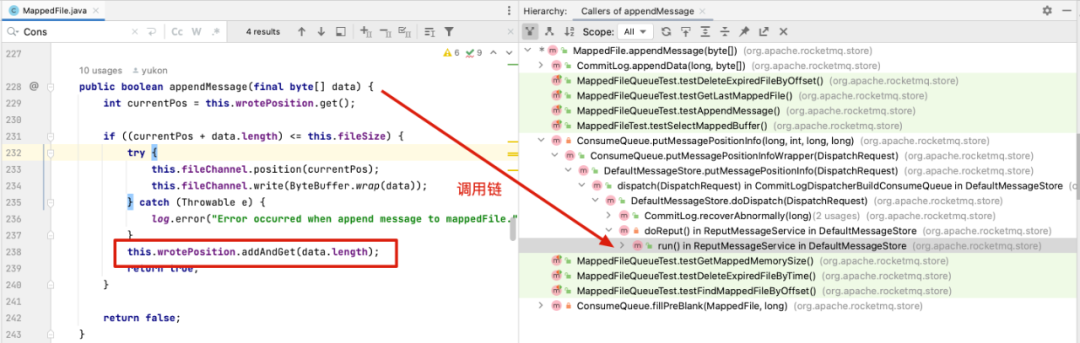
与ConsumeQueue对应的入口主要有两个:
-
ReputMessageService#doReput Commitlog异步转发线程,通过该线程异步构建Consumequeue、Index等文件
-
Commitlog#recoverAbnormally RocketMQ启动时根据Commitlog文件自动恢复Consumequeue文件
今天的主角当然不让非ReputMessageService莫属,这里先和大家普及一下一个最基本的知识:RocketMQ为了追求极致的顺序写,会将所有主题的消息顺序写入到一个文件(Commitlog文件),然后异步转发到ConsumeQueue(消费队列文件)、IndexFile(索引文件)。
其转发服务就是通过ReputMessageService来实现的。
在深入介绍Commitlog文件的转发机制之前,我在这里先问大家一个问题:消息是写入到内存就转发给ConsumeQueue,亦或是刷写到磁盘后再转发呢?
为了方便大家对这个问题的探究,其代码的核心入口如下图所示:
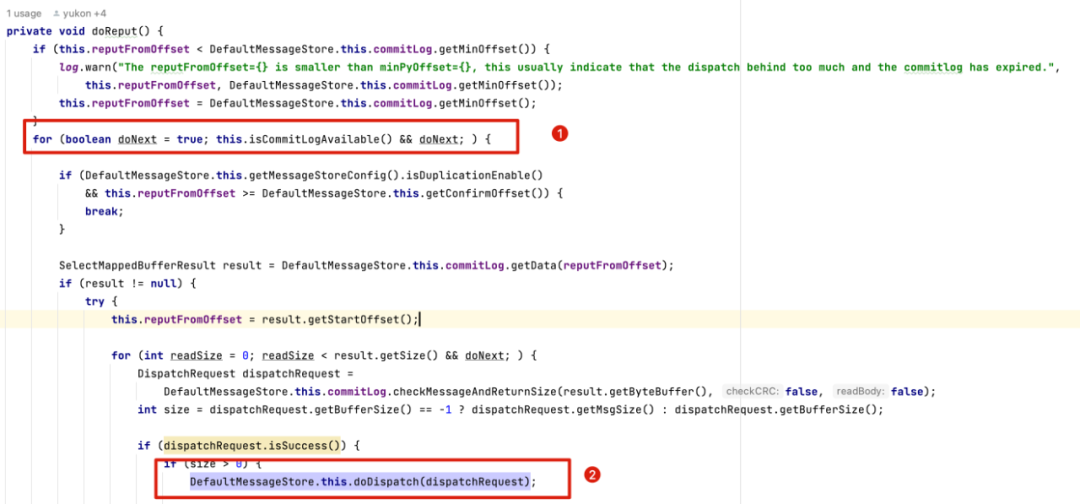
这里的关键实现要点如下:
-
判断是否转发关键条件在于 isCommitlogAvailable()方法返回true
-
根据转发位点reputFromOffset,从Commitlog文件中获取消息的物理偏移量、消息大小,tags等信息转发到消息消费队列、索引文件。
那isCommitlogAvailable的核心如下所示:

故转发的关键就在于Commitlog的maxOffset的获取逻辑了,其实现时序图如下所示:
这里核心重点是getReadPosition方法的实现,在RocketMQ写Commitlog文件,为了提升写入性能,引入了内存级读写分离机制,具体的实现原理如下图所示:
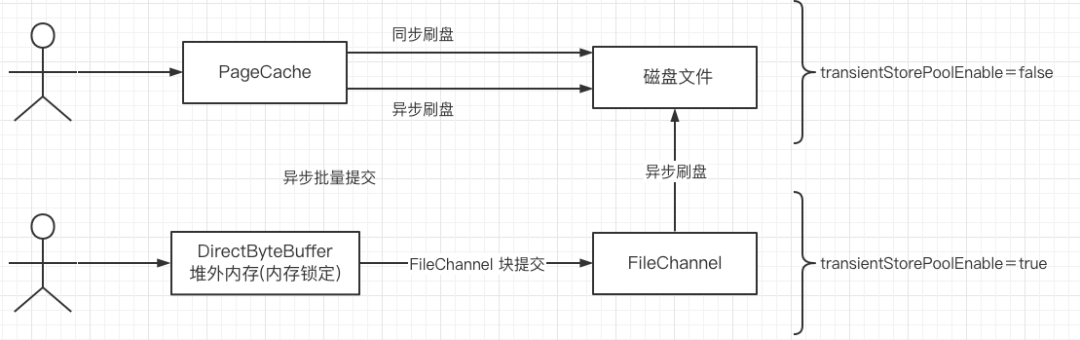
具体在实现层面,就是如果transientStorePoolEnable=true,数据写入到堆外内存(writeBuffer)中,然后再提交到FileChannel,提交的位置(commitedPosition来表示)。
大家可以分别看一下改变wrotePosition与committedPposition的调用链。
其中wrotePosition的调用链如下所示:

可以得知:wrotePosition是消息写入到内存(pagecache或者堆外内存)都会更新,但一旦开启了堆外内存机制,并不会取该值,所以我们可以理解为当消息写入到Pagecache中时,就可以被转发到消息消费队列。
紧接着我们再看一下committedPosition的调用链,如下所示:
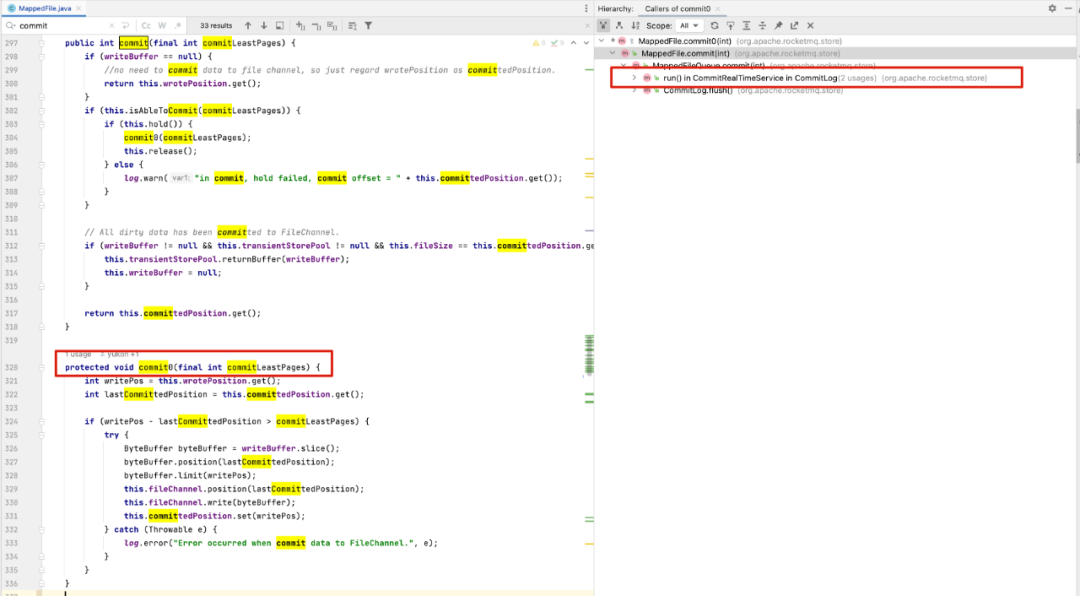
原来在RocketMQ中,如果开启了transientStorePoolEnable机制,消息先写入到堆外内存,然后就会向消息发送者返回发送成功,然后会有一个异步线程(CommitRealTimeService)定时将消息(默认200ms一次循环)提交到FileChannel,即更新committedPosition的值,消息就会转发给消费队列,从而消费者就可以进行消费。
2.2 问题原因提炼
经过上面的解析,问题应该有所眉目了。
由于我们公司为了提高RocketMQ的资源利用率,提升RocketMQ的写入性能,我们开启了transientStorePoolEnable机制,消息发送端写入到堆外内存,就会返回写入成功,这样MySQL Binlog数据同步并不会产生延迟,那这里的问题,无非就2个:
-
CommitRealTimeService 线程并没有及时将堆外内存中的数据提交到FileChannel
-
ReputMessageService线程没有及时将数据转发到消费队列
由于目前我暂时对底层存储写入的原理还认识不够深入,对相关系统采集指标不够敏感,当时主要分析了一下线程栈,发现ReputMessageService线程一直在工作,推测可能是转发不及时,这块我还需要更加深入去研究,如果大家对这块有其实理解,欢迎留言,我也会在后续工作中提升这块的技能,更加深入去理解底层的原理。
也就是目前知道了问题的表象原因,虽然底层原理还未通透,但目前足以指导我们更好的处理问题:将集群内消息写入大的主题,迁移到其他负载较低的集群,从而降低该集群的写入压力,当迁移了几个主题后,果不其然,消息到达消费队列接近实时,集群得以恢复。