目录
1:Dubbo高级特性
1.1:超时与重试
什么是超时?
什么是重试?
如何配置超时与重试:
1.2:启动检查
1.3:多版本
1.4:负载均衡
1.5:序列化
1.6:地址缓存
1.7:集群容错
1.8:服务降级
1:Dubbo高级特性
Dubbo的特性有很多,这里介绍几个常用的高级特性
1.1:超时与重试
什么是超时?
-
服务消费者在调用服务提供者的时候发生了阻塞、等待的情形,这个时候,服务消费者会一直等待下去。
-
在某个峰值时刻,大量的请求都在同时请求服务消费者,会造成线程的大量堆积,势必会造成雪崩现象。
-
dubbo 利用超时机制来解决这个问题(使用timeout属性配置超时时间,默认值1000,单位毫秒)
-
若超时时间较短,当网络波动时请求就会失败,Dubbo通过重试机制避免此类问题的发生
-
超时机制:通过 设置超时时间,如果一个请求超过了设置的请求时间,判定为超时,请求失败,来防止多个请求陷入等待这一现象
什么是重试?
重试机制:如果只用超时机制来处理这种请求阻塞的情况,势必也会出现新的问题,例如:我在宿舍玩着和平精英,网络断了三秒,假如我的提供者游戏板块超时时间一秒,那完了这一次请求失败了,被迫离开了。我们dubbo就想了个办法,我给它搞一个重试机制,我第一次请求网络抖动了超时了,没关系,我可以重试一下问问你好了吗?这边答复ok了,那我继续连接继续完请求成功,如果我两次询问都不好,那就算我连接/请求失败了
注意:默认是重试请求两次,加上第一次请求,总共三次
如何配置超时与重试:
第一种在消费者或者提供者模块的application.yml文件中进行设置
dubbo:
registry:
address: nacos://127.0.0.1:8848
consumer:
timeout: 3000
retries: 0第二种在消费者模块和提供者模块的相关注解上面添加超时和重试参数
消费者模块调用配置到注册中心的提供者服务的注解上加入: 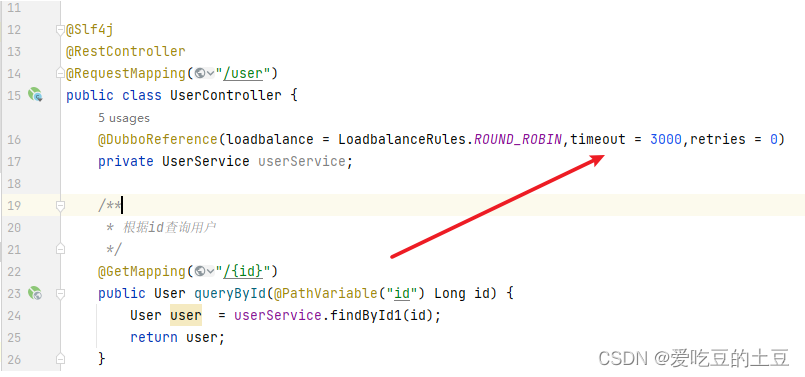
提供者模块相关注解上加入: 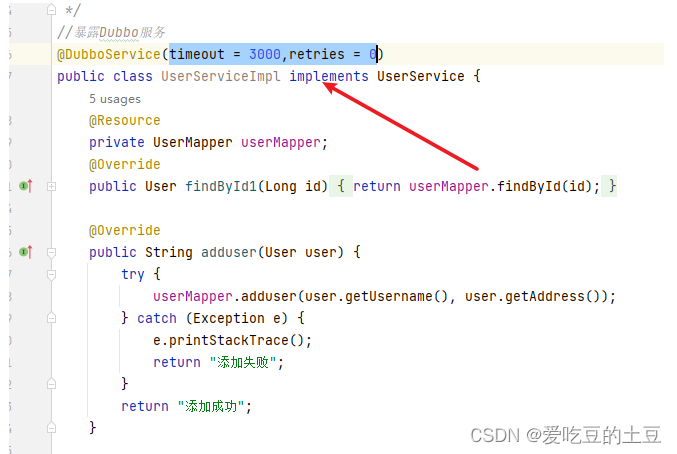
注意:如果消费者和提供者模块都配置了超时时间,消费者模块的超时时间会覆盖提供者模块的超时时间。
推荐在提供者模块配置超时时间即可。
1.2:启动检查
-
为了保障服务的正常可用,Dubbo 缺省会在启动时检查依赖的服务是否可用,不可用时会抛出异常

-
在正式环境这是很有必要的一项配置,可以保证整个调用链路的平稳运行
-
在开发时,往往会存在没有提供者的情况。由于启动检查的原因,可能导致开发测试出现问题
-
可以通过check=false关闭
-
-
user-consumer模块中添加配置信息
dubbo:
registry:
address: nacos://127.0.0.1:8848
consumer:
check: false
1.3:多版本
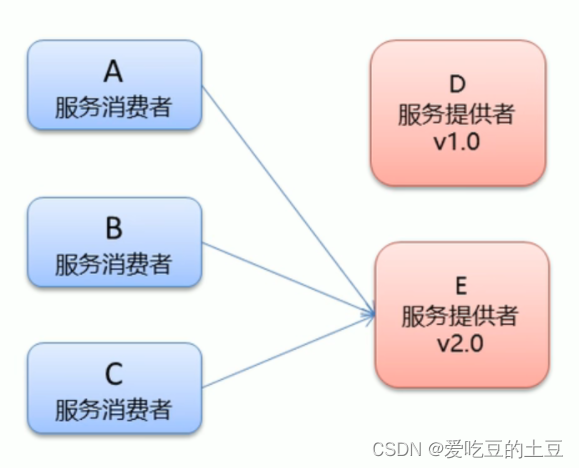
-
灰度发布:当出现新功能时,会让一部分用户先使用新功能,用户反馈没问题时,再将所有用户迁移到新功能。
-
Dubbo提供了提供者多版本的支持,平滑处理项目功能升级部署
-
dubbo中使用version属性来设置和调用同一个接口的不同版本
(1)user-provider定义新的服务实现类UserServiceImpl2,指定版本
@DubboService(version = “2.0.0”)
public class UserServiceImpl2 implements UserService {
…………
}(2)user-consumer消费者调用时,指定版本调用
@RestController
@RequestMapping("/user")
public class UserController {
//引用远程服务
@DubboReference(version = "2.0.0")
private UserService userService;
………
}
1.4:负载均衡

-
在集群部署时,Dubbo提供了4种负载均衡策略,帮助消费者找到最优提供者并调用
-
Random :按权重随机,默认值。按权重设置随机概率。
-
RoundRobin :按权重轮询
-
LeastActive:最少活跃调用数,相同活跃数的随机。
-
ConsistentHash:一致性 Hash,相同参数的请求总是发到同一提供者。
-
提供者创建集群配置文件 application-18082.yml 
server:
port: 18082
spring:
application:
name: user-provider
datasource:
url: jdbc:mysql://localhost:3306/test?useSSL=false
username: root
password: 1234
driver-class-name: com.mysql.jdbc.Driver
logging:
level:
com.czxy: debug
pattern:
dateformat: HH:mm:ss:SSS
#配置dubbo提供者
dubbo:
protocol:
name: dubbo #dubbo协议和访问端口
port: 20882
registry:
address: nacos://127.0.0.1:8848 #注册中心的地址
scan:
base-packages: com.czxy.user.service #dubbo注解的包扫描 在idea中配置多个服务器提供者 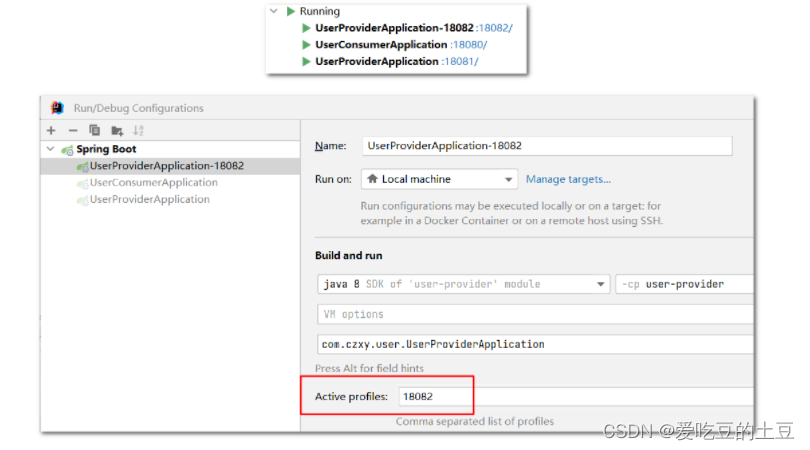
-
消费者,配置负载均衡策略
@RestController
@RequestMapping("/user")
public class UserController {
//引用远程服务
@DubboReference(loadbalance = LoadbalanceRules.ROUND_ROBIN)
private UserService userService;
}
-
观看控制台,可以看到服务提供者依次被调用。如果需要返回不同信息,可以修改服务提供者
//暴露dubbo服务,
@DubboService(version = "1.0.0")
public class UserServiceImpl implements UserService {
@Autowired
private UserMapper userMapper;
@Override
public User queryById(Long id) {
User user = userMapper.findById(id);
// 获得dubbo绑定的端口号
int port = DubboProtocol.getDubboProtocol().getServers().get(0).getRemotingServer().getLocalAddress().getPort();
user.setUsername(user.getUsername()+"v1.0" + port);
return user;
}
}
1.5:序列化
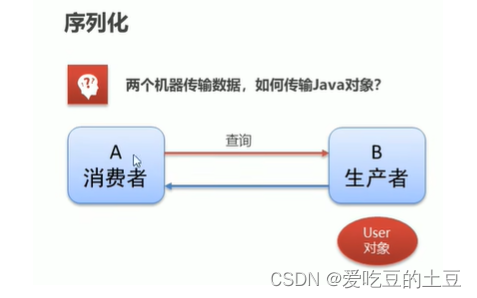
两个机器传输数据,如何传输Java对象?
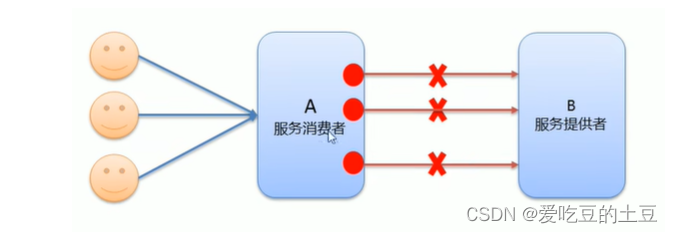
如图:现在用户请求消费者A获取数据,消费者A调用生产者B提供的方法,生产者B中的方法获得User对象数据,返回给消费者A,然后再返回给用户。很完美的一套流程。
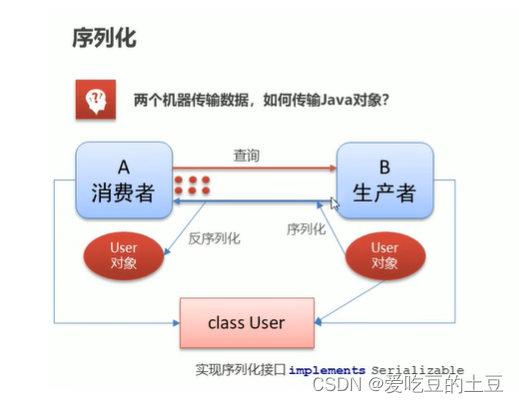
问题来了,两者之间怎么传输数据呢?就是用序列化呗!首先两个模块之间进行通信,需要建立数据流管道进行传输数据,我们将传输的数据序列化成数据流,在数据流管道上进行传输,传输到消费者A端后再进行反序列化即可。
那怎么实现序列化呢?就是将User对象实现序列化接口implements Serializable。
如图我们也能发现消费者A模块和生产者B模块都需要用到User对象,通过我们会将User对象这个JavaBean抽成一个单独的模块,使消费者A和消费者B都进行Maven依赖这个单独的模块。
可能有人会问,序列化和反序列化操作多麻烦,这个不用担心,我们只需要将JavaBean实现序列化接口即可,我们使用的dubbo框架已经将序列化和反序列化的过程进行封装了。
如果没有实现序列化接口会抛出异常。
1.6:地址缓存
注册中心挂了,服务是否可以正常访问?
答案是可以的,因为dubbo服务消费者在第一次调用时,会将服务提供方地址缓存到本地,以后在调用不会进行访问注册中心
当服务提供者地址发生变化时,注册中心会通知服务消费者!
1.7:集群容错
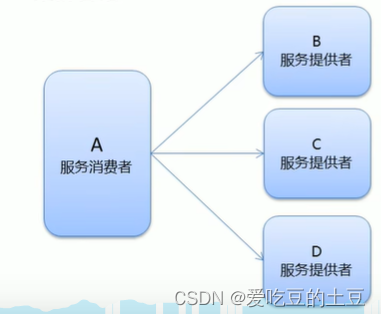
集群容错就是:提供者服务配置在了多个集群上面,当消费者调用提供者服务时,如果这个集群中的提供者服务挂机了没关系,我再进行调用其他集群中的提供者服务即可
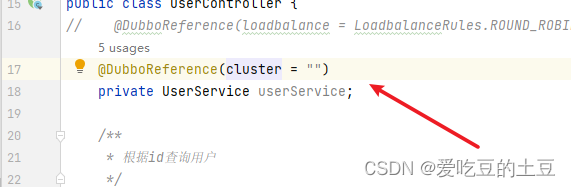
消费者调用提供者的注解上进行配置cluster,默认的容错模式是:失败重试

1.8:服务降级
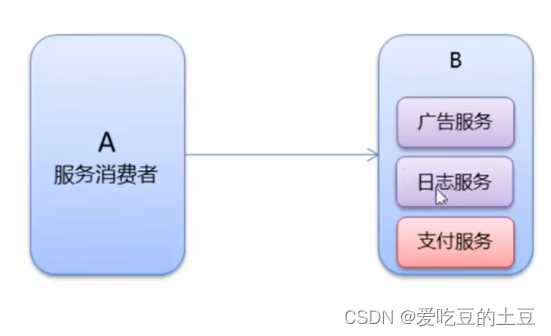
什么是服务降级呢?就是说我在B机器上部署了好多个不相同的服务模块,内存已经占用了很高了快崩掉了,那么运营维护人员想了想关闭一些不重要的服务模块,把广告和日志都给停止了,留下了支付服务,这个就称之为服务降级。
dubbo提供了两种不同的降级方式:
在消费者方面配置第一种:mock=force:return null 表示消费者对该服务的方法调用都直接返回null值,不发起远程调用,用来屏蔽不重要服务不可用时对调用方的影响

在消费者方面配置第二种:mock=fail:return null 表示消费者对服务的方法调用在失败后,再返回null值,不抛异常,用来容忍不重要服务不稳定时对调用方的影响。