一、配置文件
1、临时属性设置
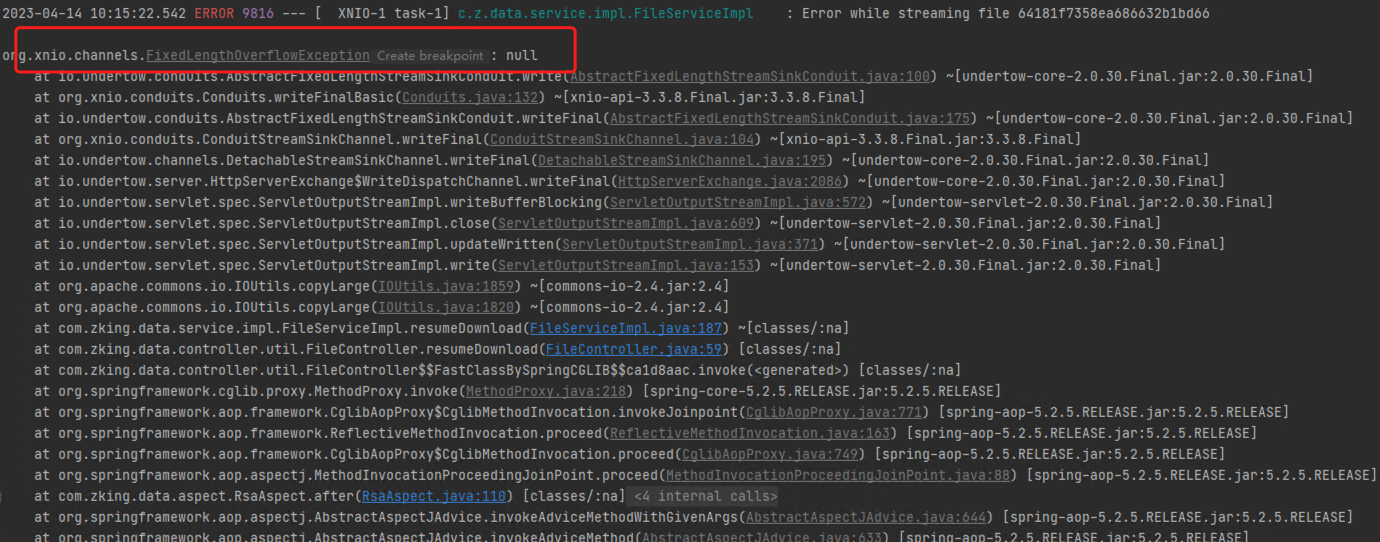
目前我们的程序包打好了,可以发布了。但是程序包打好以后,里面的配置都已经是固定的了,比如配置了服务器的端口是8080。如果我要启动项目,发现当前我的服务器上已经有应用启动起来并且占用了8080端口,这个时候就尴尬了。难道要重新把打包好的程序修改一下吗?比如我要把打包好的程序启动端口改成80。
SpringBoot提供了灵活的配置方式,如果你发现你的项目中有个别属性需要重新配置,可以使用临时属性的方式快速修改某些配置。方法也特别简单,在启动的时候添加上对应参数就可以了。
java –jar springboot.jar –-server.port=80上面的命令是启动SpringBoot程序包的命令,在命令输入完毕后,空一格,然后输入两个-号。下面按照属性名=属性值的形式添加对应参数就可以了。记得,这里的格式不是yaml中的书写格式,当属性存在多级名称时,中间使用点分隔,和properties文件中的属性格式完全相同。
如果你发现要修改的属性不止一个,可以按照上述格式继续写,属性与属性之间使用空格分隔。
java –jar springboot.jar –-server.port=80 --logging.level.root=debug1.1、属性加载优先级
现在我们的程序配置受两个地方控制了,第一配置文件,第二临时属性。并且我们发现临时属性的加载优先级要高于配置文件的。那是否还有其他的配置方式呢?其实是有的,而且还不少,打开官方文档中对应的内容,就可以查看配置读取的优先顺序。地址奉上:https://docs.spring.io/spring-boot/docs/current/reference/html/spring-boot-features.html#boot-features-external-config
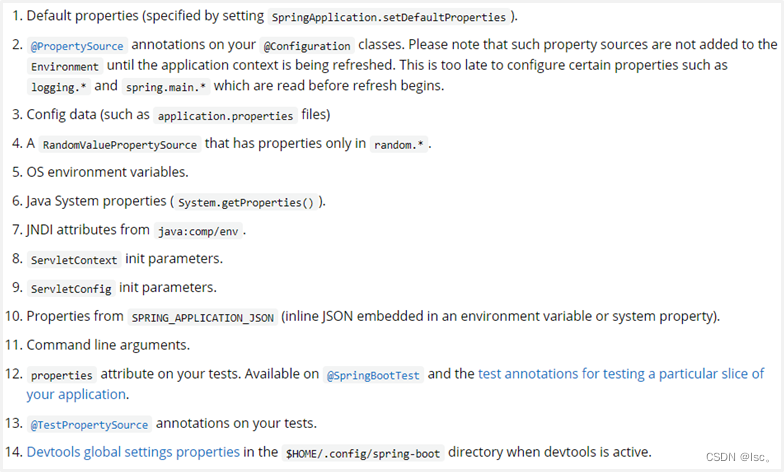
我们可以看到,居然有14种配置的位置,而我们现在使用的是这里面的2个。第3条Config data说的就是使用配置文件,第11条Command line arguments说的就是使用命令行临时参数。而这14种配置的顺序就是SpringBoot加载配置的顺序,言外之意,命令行临时属性比配置文件的加载优先级高,所以这个列表上面的优先级低,下面的优先级高。其实这个东西不用背的,你就记得一点,你最终要什么效果,你自己是知道的,不管这个顺序是怎么个高低排序,开发时一定要配置成你要的顺序为准。这个顺序只是在你想不明白问题的时候帮助你分析罢了。
比如你现在加载了一个user.name属性。结果你发现出来的结果和你想的不一样,那肯定是别的优先级比你高的属性覆盖你的配置属性了,那你就可以看着这个顺序挨个排查。哪个位置有可能覆盖了你的属性。
总结
使用jar命令启动SpringBoot工程时可以使用临时属性替换配置文件中的属性
临时属性添加方式:java –jar 工程名.jar –-属性名=值
多个临时属性之间使用空格分隔
临时属性必须是当前boot工程支持的属性,否则设置无效
2、配置文件分类
SpringBoot提供了配置文件和临时属性的方式来对程序进行配置。前面一直说的是临时属性,这一节要说说配置文件了。其实这个配置文件我们一直在使用,只不过我们用的是SpringBoot提供的4级配置文件中的其中一个级别。4个级别分别是:
类路径下配置文件(一直使用的是这个,也就是resources目录中的application.yml文件)
类路径下config目录下配置文件
程序包所在目录中配置文件
程序包所在目录中config目录下配置文件
好复杂,一个一个说。其实上述4种文件是提供给你了4种配置文件书写的位置,功能都是一样的,都是做配置的。那大家关心的就是差别了,没错,就是因为位置不同,产生了差异。总体上来说,4种配置文件如果都存在的话,有一个优先级的问题,说白了就是加入4个文件我都有,里面都有一样的配置,谁生效的问题。上面4个文件的加载优先顺序为
file :config/application.yml 【最高】
file :application.yml
classpath:config/application.yml
classpath:application.yml 【最低】
那为什么设计这种多种呢?说一个最典型的应用吧。
场景A:你作为一个开发者,你做程序的时候为了方便自己写代码,配置的数据库肯定是连接你自己本机的,咱们使用4这个级别,也就是之前一直用的application.yml。
场景B:现在项目开发到了一个阶段,要联调测试了,连接的数据库是测试服务器的数据库,肯定要换一组配置吧。你可以选择把你之前的文件中的内容都改了,目前还不麻烦。
场景C:测试完了,一切OK。你继续写你的代码,你发现你原来写的配置文件被改成测试服务器的内容了,你要再改回来。现在明白了不?场景B中把你的内容都改掉了,你现在要重新改回来,以后呢?改来改去吗?
解决方案很简单,用上面的3这个级别的配置文件就可以快速解决这个问题,再写一个配置就行了。两个配置文件共存,因为config目录中的配置加载优先级比你的高,所以配置项如果和级别4里面的内容相同就覆盖了,这样是不是很简单?
级别1和2什么时候使用呢?程序打包以后就要用这个级别了,管你程序里面配置写的是什么?我的级别高,可以轻松覆盖你,就不用考虑这些配置冲突的问题了。
总结
配置文件分为4种
项目类路径配置文件:服务于开发人员本机开发与测试
项目类路径config目录中配置文件:服务于项目经理整体调控
工程路径配置文件:服务于运维人员配置涉密线上环境
工程路径config目录中配置文件:服务于运维经理整体调控
多层级配置文件间的属性采用叠加并覆盖的形式作用于程序
二、多环境开发
讲的内容距离线上开发越来越近了,下面说一说多环境开发问题。
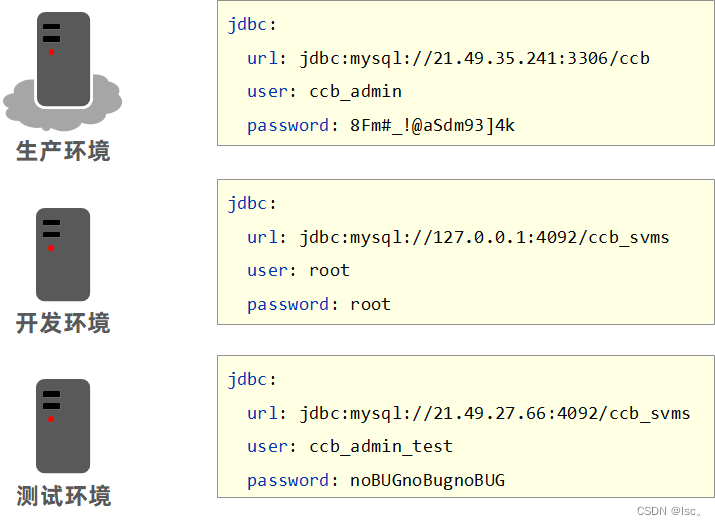
什么是多环境?其实就是说你的电脑上写的程序最终要放到别人的服务器上去运行。每个计算机环境不一样,这就是多环境。常见的多环境开发主要兼顾3种环境设置,开发环境——自己用的,测试环境——自己公司用的,生产环境——甲方爸爸用的。因为这是绝对不同的三台电脑,所以环境肯定有所不同,比如连接的数据库不一样,设置的访问端口不一样等等。
1、yaml单一文件版
那什么是多环境开发?就是针对不同的环境设置不同的配置属性即可。比如你自己开发时,配置你的端口如下:
server:
port: 80如何想设计两组环境呢?中间使用三个减号分隔开
server:
port: 80
---
server:
port: 81如何区分两种环境呢?起名字呗
spring:
profiles: pro
server:
port: 80
---
spring:
profiles: dev
server:
port: 81那用哪一个呢?设置默认启动哪个就可以了
spring:
profiles:
active: pro # 启动pro
---
spring:
profiles: pro
server:
port: 80
---
spring:
profiles: dev
server:
port: 81其中关于环境名称定义上述格式是过时格式,标准格式如下
spring:
config:
activate:
on-profile: pro总结
多环境开发需要设置若干种常用环境,例如开发、生产、测试环境
yaml格式中设置多环境使用---区分环境设置边界
每种环境的区别在于加载的配置属性不同
启用某种环境时需要指定启动时使用该环境
2、yaml多文件版
将所有的配置都放在一个配置文件中,尤其是每一个配置应用场景都不一样,这显然不合理,于是就有了将一个配置文件拆分成多个配置文件的想法。拆分后,每个配置文件中写自己的配置,主配置文件中写清楚用哪一个配置文件就好了。
主配置文件
spring:
profiles:
active: pro # 启动pro环境配置文件
server:
port: 80环境配置文件因为每一个都是配置自己的项,所以连名字都不用写里面了。那问题是如何区分这是哪一组配置呢?使用文件名区分。
application-pro.yaml
server:
port: 80application-dev.yaml
server:
port: 81文件的命名规则为:application-环境名.yml。
在配置文件中,如果某些配置项所有环境都一样,可以将这些项写入到主配置中,只有哪些有区别的项才写入到环境配置文件中。
主配置文件中设置公共配置(全局)
环境分类配置文件中常用于设置冲突属性(局部)
总结
可以使用独立配置文件定义环境属性
独立配置文件便于线上系统维护更新并保障系统安全性
3、多环境开发独立配置文件书写技巧
作为程序员在搞配置的时候往往处于一种分久必合合久必分的局面。开始先写一起,后来为了方便维护就拆分。对于多环境开发也是如此,下面给大家说一下如何基于多环境开发做配置独立管理,务必掌握。
准备工作
将所有的配置根据功能对配置文件中的信息进行拆分,并制作成独立的配置文件,命名规则如下
application-devDB.yml
application-devRedis.yml
application-devMVC.yml
使用
使用include属性在激活指定环境的情况下,同时对多个环境进行加载使其生效,多个环境间使用逗号分隔
spring:
profiles:
active: dev
include: devDB,devRedis,devMVC注意
当主环境dev与其他环境有相同属性时,主环境属性生效;其他环境中有相同属性时,最后加载的环境属性生效
改良
但是上面的设置也有一个问题,比如我要切换dev环境为pro时,include也要修改。因为include属性只能使用一次,这就比较麻烦了。SpringBoot从2.4版开始使用group属性替代include属性,降低了配置书写量。简单说就是我先写好,你爱用哪个用哪个。
spring:
profiles:
active: dev
group:
"dev": devDB,devRedis,devMVC
"pro": proDB,proRedis,proMVC
"test": testDB,testRedis,testMVC三、日志
运维篇最后一部分我们来聊聊日志,日志大家不陌生,简单介绍一下。日志其实就是记录程序日常运行的信息,主要作用如下:
编程期调试代码
运营期记录信息
记录日常运营重要信息(峰值流量、平均响应时长……)
记录应用报错信息(错误堆栈)
记录运维过程数据(扩容、宕机、报警……)
1、代码中使用日志工具记录日志
步骤①:添加日志记录操作
@RestController
@RequestMapping("/books")
public class BookController extends BaseClass{
private static final Logger log = LoggerFactory.getLogger(BookController.class);
@GetMapping
public String getById(){
log.debug("debug...");
log.info("info...");
log.warn("warn...");
log.error("error...");
return "springboot is running...2";
}
}上述代码中log对象就是用来记录日志的对象,下面的log.debug,log.info这些操作就是写日志的API了。
步骤②:设置日志输出级别
日志设置好以后可以根据设置选择哪些参与记录。这里是根据日志的级别来设置的。日志的级别分为6种,分别是:
TRACE:运行堆栈信息,使用率低
DEBUG:程序员调试代码使用
INFO:记录运维过程数据
WARN:记录运维过程报警数据
ERROR:记录错误堆栈信息
FATAL:灾难信息,合并计入ERROR
一般情况下,开发时候使用DEBUG,上线后使用INFO,运维信息记录使用WARN即可。下面就设置一下日志级别:
# 开启debug模式,输出调试信息,常用于检查系统运行状况
debug: true这么设置太简单粗暴了,日志系统通常都提供了细粒度的控制
# 开启debug模式,输出调试信息,常用于检查系统运行状况
debug: true
# 设置日志级别,root表示根节点,即整体应用日志级别
logging:
level:
root: debug还可以再设置更细粒度的控制
步骤③:设置日志组,控制指定包对应的日志输出级别,也可以直接控制指定包对应的日志输出级别
logging:
# 设置日志组
group:
# 自定义组名,设置当前组中所包含的包
ebank: com.itheima.controller
level:
root: warn
# 为对应组设置日志级别
ebank: debug
# 为对包设置日志级别
com.itheima.controller: debug说白了就是总体设置一下,每个包设置一下,如果感觉设置的麻烦,就先把包分个组,对组设置,没了,就这些。
总结
日志用于记录开发调试与运维过程消息
日志的级别共6种,通常使用4种即可,分别是DEBUG,INFO,WARN,ERROR
可以通过日志组或代码包的形式进行日志显示级别的控制
2、优化日志对象创建代码
写代码的时候每个类都要写创建日志记录对象,这个可以优化一下,使用前面用过的lombok技术给我们提供的工具类即可。
@Slf4j //这个注解替代了下面那一行
@RestController
@RequestMapping("/books")
public class BookController extends BaseClass{
private static final Logger log = LoggerFactory.getLogger(BookController.class); //这一句可以不写了
}3、日志输出格式控制
日志已经能够记录了,但是目前记录的格式是SpringBoot给我们提供的,如果想自定义控制就需要自己设置了。先分析一下当前日志的记录格式。

对于单条日志信息来说,日期,触发位置,记录信息是最核心的信息。级别用于做筛选过滤,PID与线程名用于做精准分析。了解这些信息后就可以DIY日志格式了。本课程不做详细的研究,有兴趣的小伙伴可以学习相关的知识。下面给出课程中模拟的官方日志模板的书写格式,便于大家学习。
logging:
pattern:
console: "%d %clr(%p) --- [%16t] %clr(%-40.40c){cyan} : %m %n"4、日志文件
日志信息显示,记录已经控制住了,下面就要说一下日志的转存了。日志不能仅显示在控制台上,要把日志记录到文件中,方便后期维护查阅。
对于日志文件的使用存在各种各样的策略,例如每日记录,分类记录,报警后记录等。这里主要研究日志文件如何记录。
记录日志到文件中格式非常简单,设置日志文件名即可。
logging:
file:
name: server.log虽然使用上述格式可以将日志记录下来了,但是面对线上的复杂情况,一个文件记录肯定是不能够满足运维要求的,通常会每天记录日志文件,同时为了便于维护,还要限制每个日志文件的大小。下面给出日志文件的常用配置方式:
logging:
logback:
rollingpolicy:
max-file-size: 3KB
file-name-pattern: server.%d{yyyy-MM-dd}.%i.log以上格式是基于logback日志技术设置每日日志文件的设置格式,要求容量到达3KB以后就转存信息到第二个文件中。文件命名规则中的%d标识日期,%i是一个递增变量,用于区分日志文件。