目录
1 UDTF
1.1 概述
1.2 explode
1.3 posexplode
1.4 inline
1.5 Lateral View
2 窗口函数(开窗函数)
2.1 定义
2.2 语法
2.2.1 语法--函数
2.2.2 语法--窗口
2.2.3 常用窗口函数
3 自定义函数
3.1 基本知识
3.2 实现自定义函数
3.2.1 创建Maven项目
3.2.2 创建临时函数
3.2.3 创建永久函数
1 UDTF
1.1 概述
UDTF ( Table-Generating Functions),又被称为炸裂函数,接收一行数据,输出一行或多行数据。
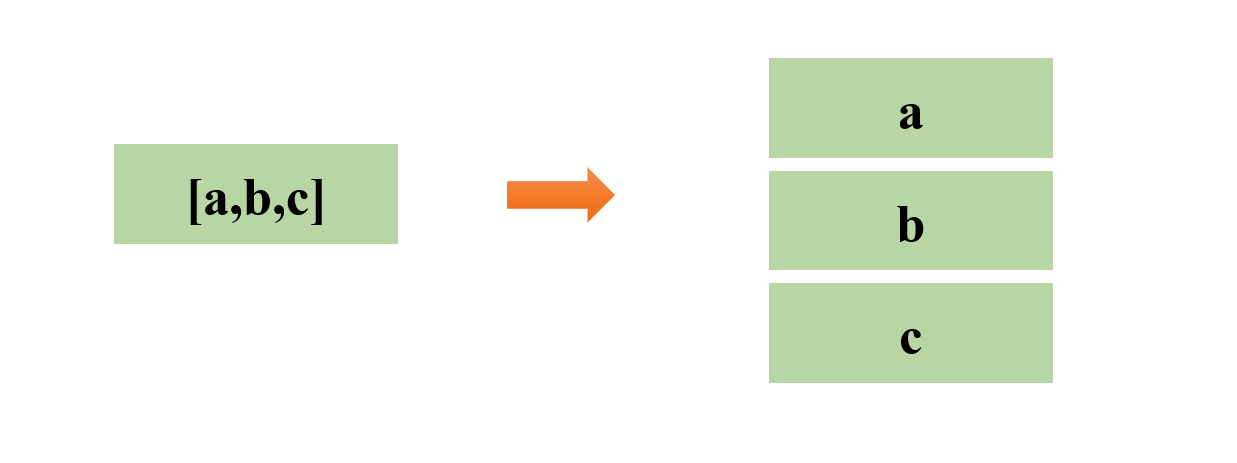
1.2 explode
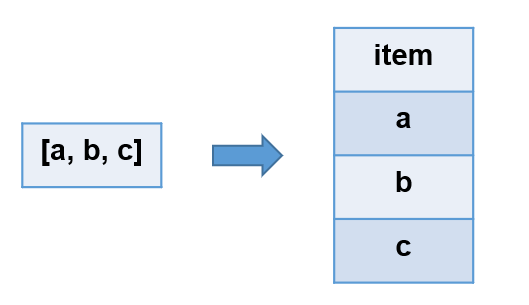
参数
explode(Map<K,V> m)语法
select explode(`array`(1,2,3,4)) num;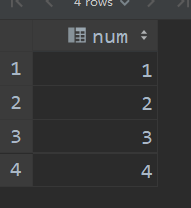
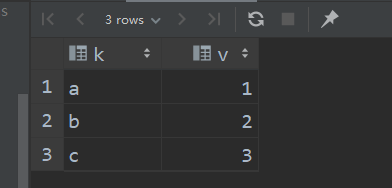
1.3 posexplode
参数
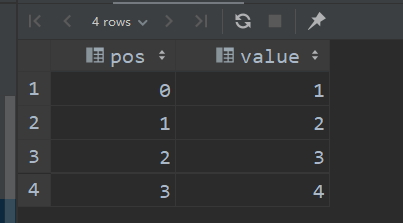
posexplode(ARRAY<T> a)语法
select posexplode(`array`(1,2,3,4)) as(pos,value);
1.4 inline

参数
inline(ARRAY<STRUCT<f1:T1,...,fn:Tn>> a)语法
select inline(
`array`(
named_struct(
"id",1,
"name","lala",
"st", named_struct("z",1)),
named_struct(
"id",2,
"name","lala2",
"st",named_struct("z",2))))
as (`学号`,`姓名`,`struct`);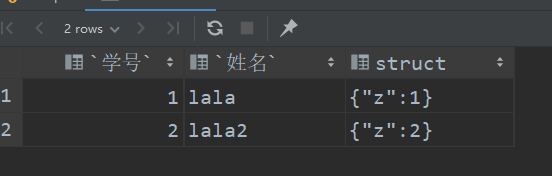
1.5 Lateral View
定义:Latera View 通常与UDTF配合使用。Lateral View可以将UDTF应用到源表的每行数据,将每行数据转换为一行或多行,并将源表中每行的输出结果与该行连接起来,形成一个虚拟表。
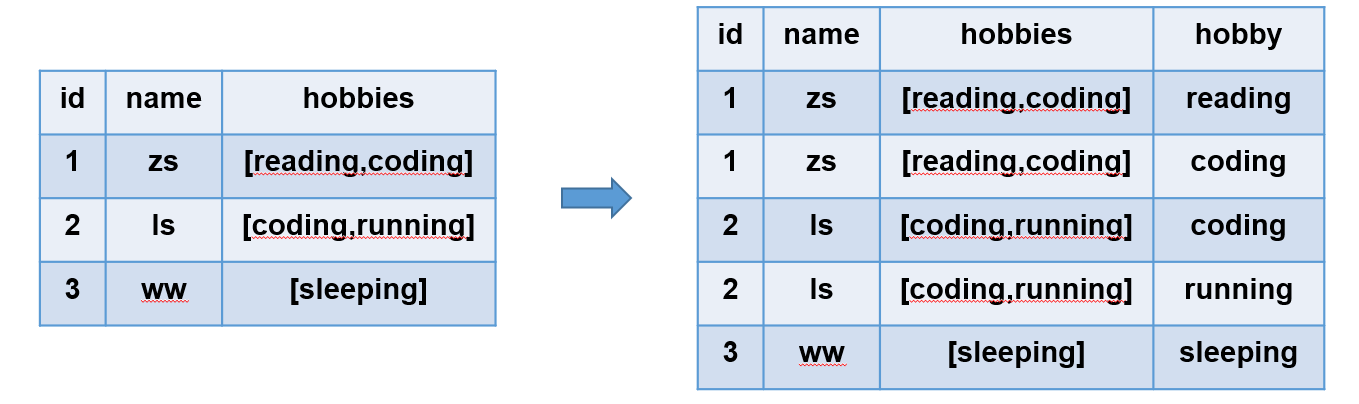
语法
(数据准备)
create table stu(
id int,
name string,
hobbies array<string>
)
row format delimited fields terminated by "\t";
set mapreduce.framework.name=local;
select * from stu;
insert into stu values (3,"zs3",`array`("reading","singing"));
insert into stu values (4,"ls4",`array`("dancing","basketball"));语法
select id, name, hobbies, hobby
from stu lateral view explode(hobbies) tmp as hobby;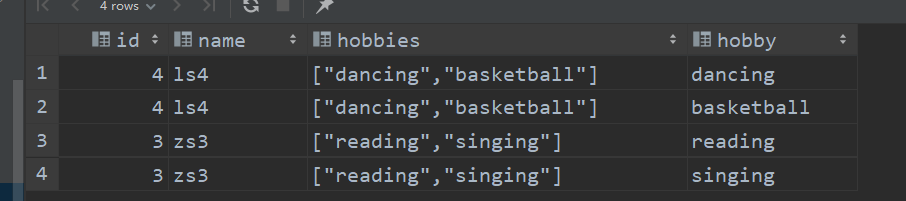
2 窗口函数(开窗函数)
2.1 定义
窗口函数,能为每行数据划分一个窗口,然后对窗口范围内的数据进行计算,最后将计算结果返回给该行数据。
2.2 语法
窗口函数的语法中主要包括“窗口”和“函数”两部分。其中“窗口”用于定义计算范围,“函数”用于定义计算逻辑。
基本语法如下:
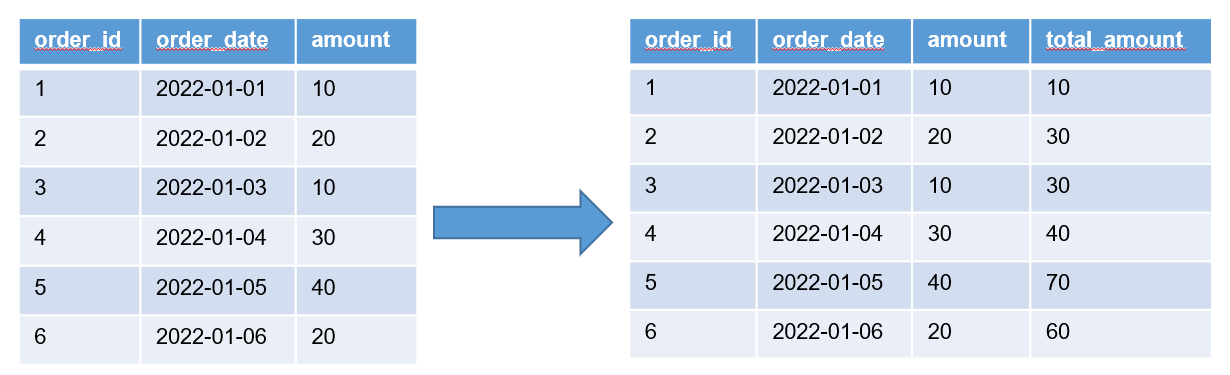
select
order_id,
order_date,
amount,
函数(amount) over (窗口范围) total_amount
from order_info;
2.2.1 语法--函数
绝大多数的聚合函数都可以配合窗口使用,例如max(),min(),sum(),count(),avg()等。
select
order_id,
order_date,
amount,
sum(amount) over (窗口范围) total_amount
from order_info;
请思考:若窗口范围是上一行到当前行,该查询语句的结果是什么?
2.2.2 语法--窗口
窗口范围的定义分为两种类型,一种是基于行的,一种是基于值的。
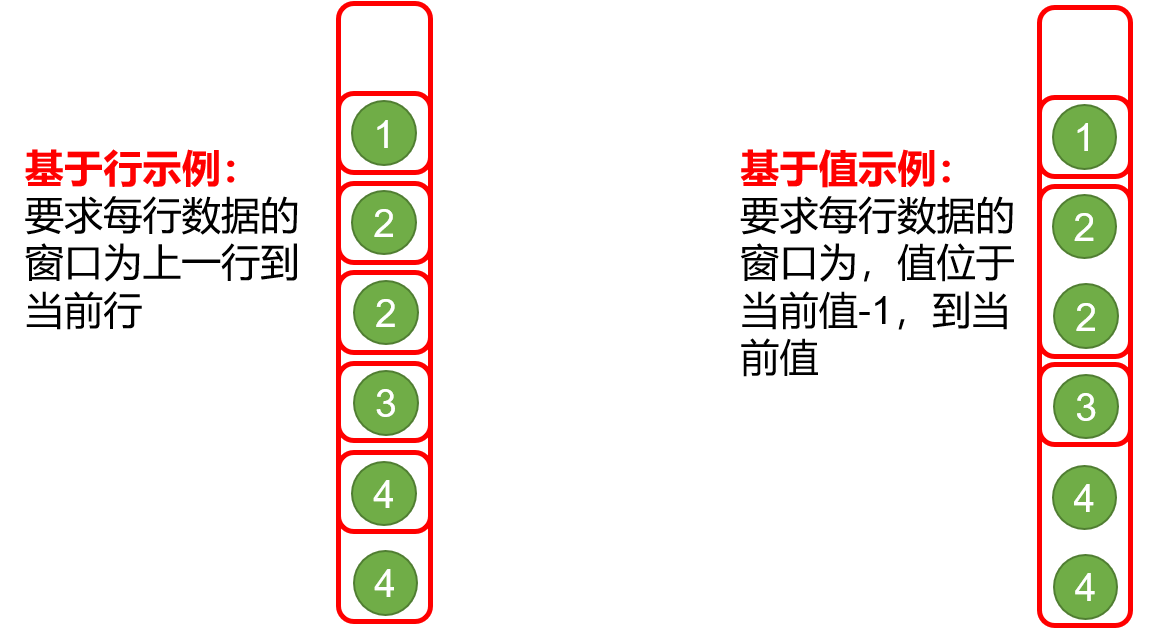
1)基于行
开始条件不同,结束条件会有不同的选择(参照相同颜色框)
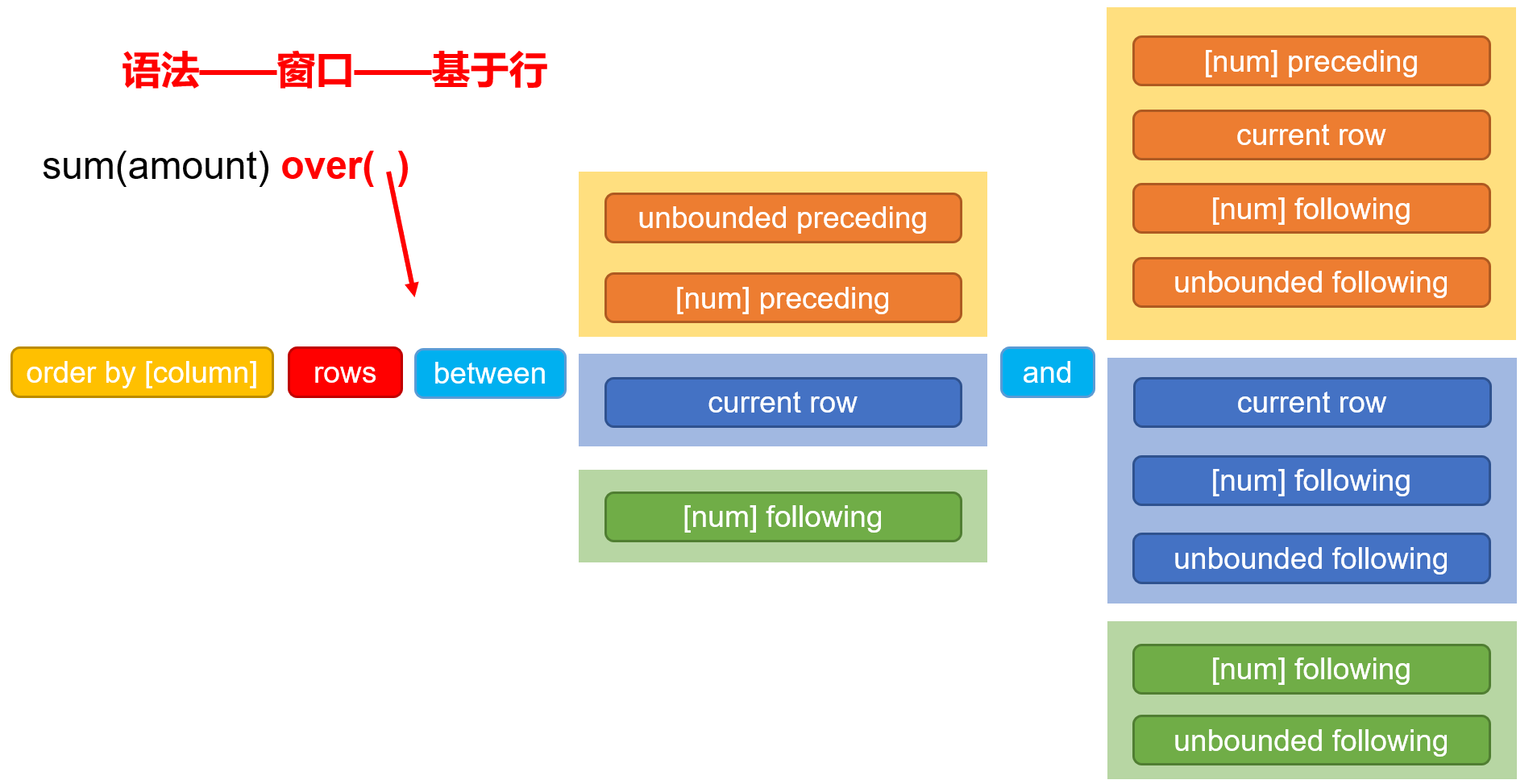
- order by [column]:排序
- unbounded preceding:窗口内第一行
- unbounded following:窗口内最后一行
- [num] preceding:前面第num行
- [num] following:后面第num行
- current row:当前行
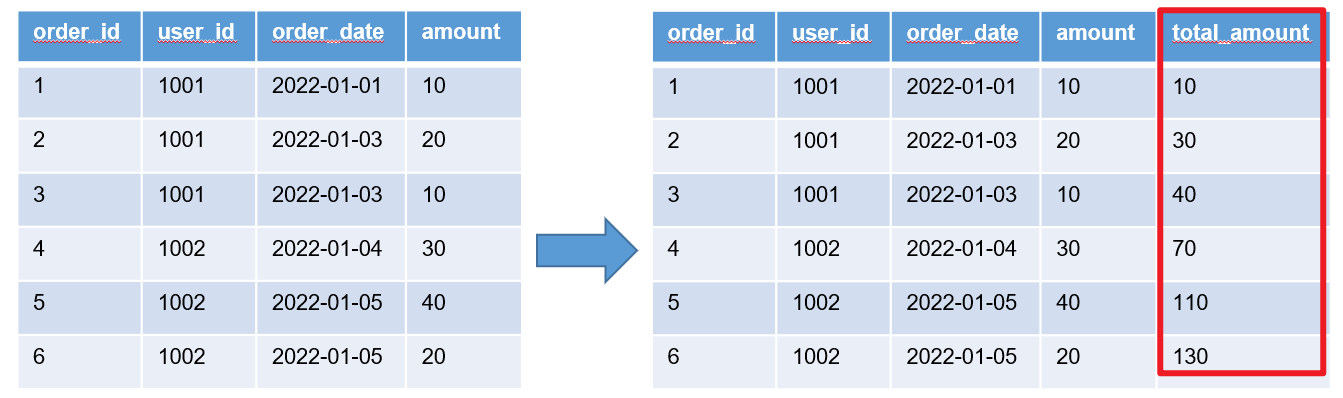
select
order_id,
order_date,
amount,
sum(amount) over (order by order_date rows between unbounded preceding and current row) total_amount
from order_info;
2)基于值(使用较少)
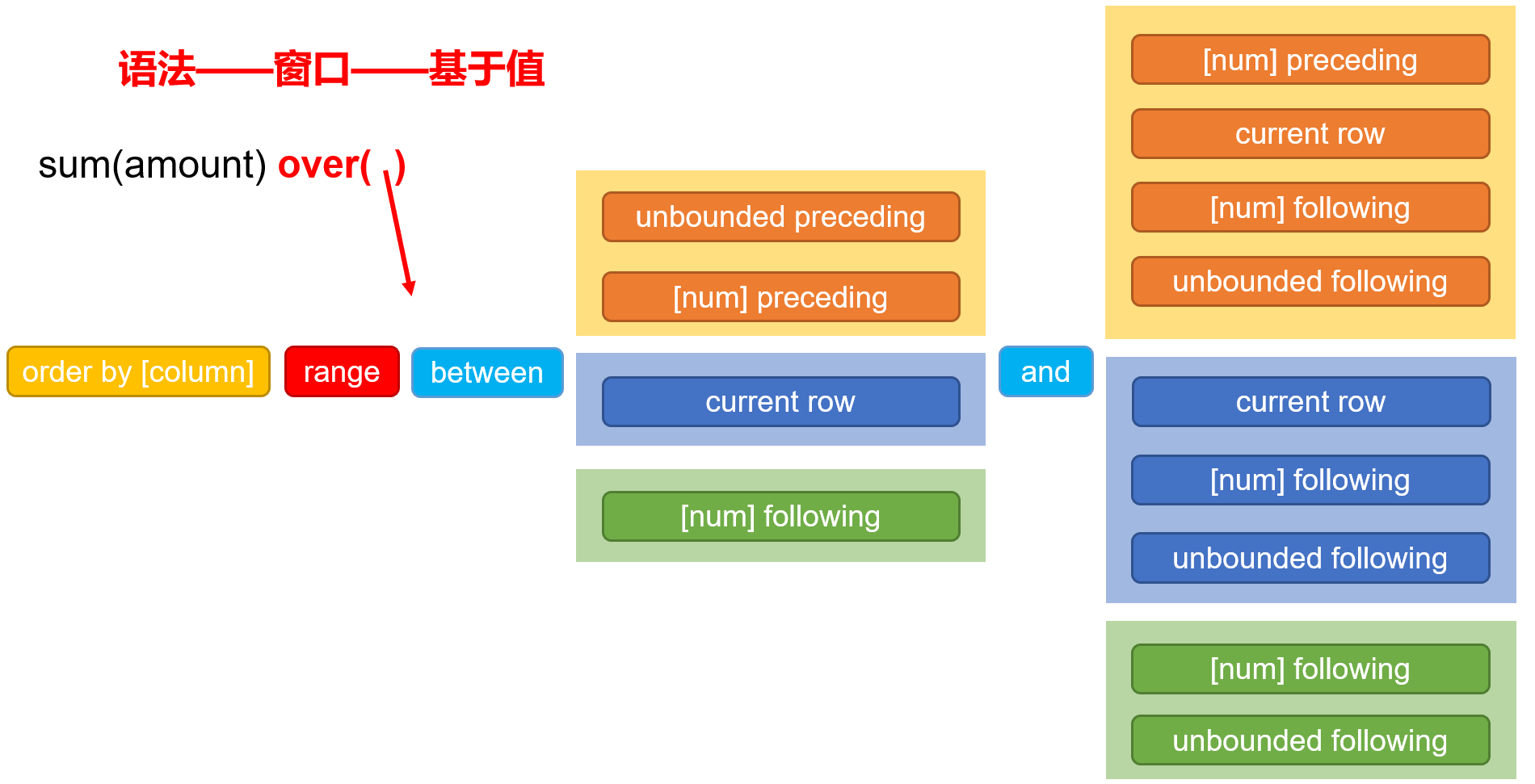
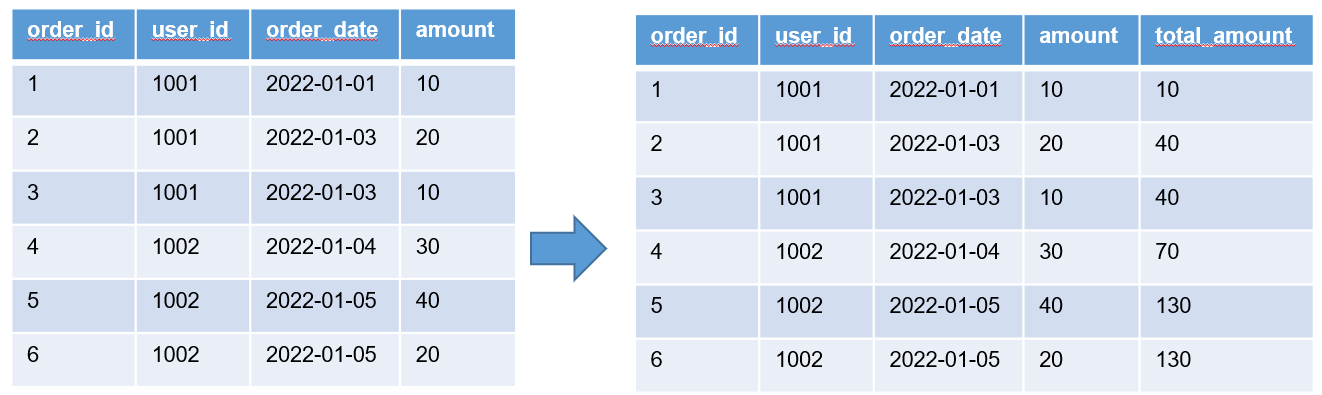
select
order_id,
order_date,
amount,
sum(amount) over (order by order_date range between unbounded preceding and current row) total_amount
from order_info;
3)分区
定义窗口范围时,可以指定分区字段,每个分区单独划分窗口。
该示例划分窗口范围时,将数据划分为了“黄”和“绿”两个区。

select
order_id,
order_date,
amount,
sum(amount) over (partition by user_id order by order_date rows between unbounded preceding and current row) total_amount
from order_info;
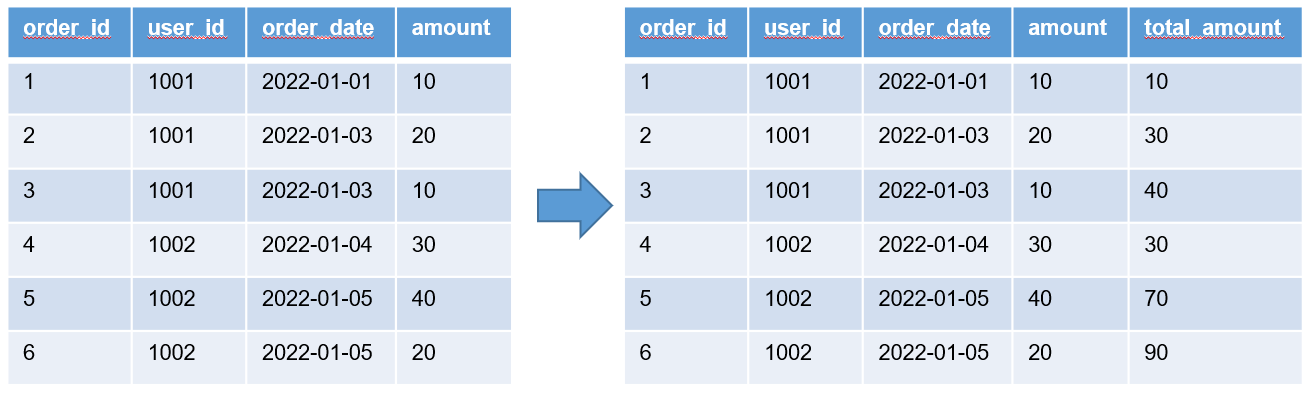 4)缺省
4)缺省
over( ) 中的三部分内容partition by、order by、(rows|range) between … and … 均可省略不写。
① partition by省略不写,表示不分区
② order by 省略不写,表示不排序
③ (rows|range) between … and … 省略不写,则使用其默认值,默认值如下:
若over()中包含order by,则默认值为
range between unbounded preceding and current row
若over()中不包含order by,则默认值为
rows between unbounded preceding and unbounded following
select
order_id,
order_date,
amount,
sum(amount) over (partition by user_id order by order_date) total_amount
from order_info;
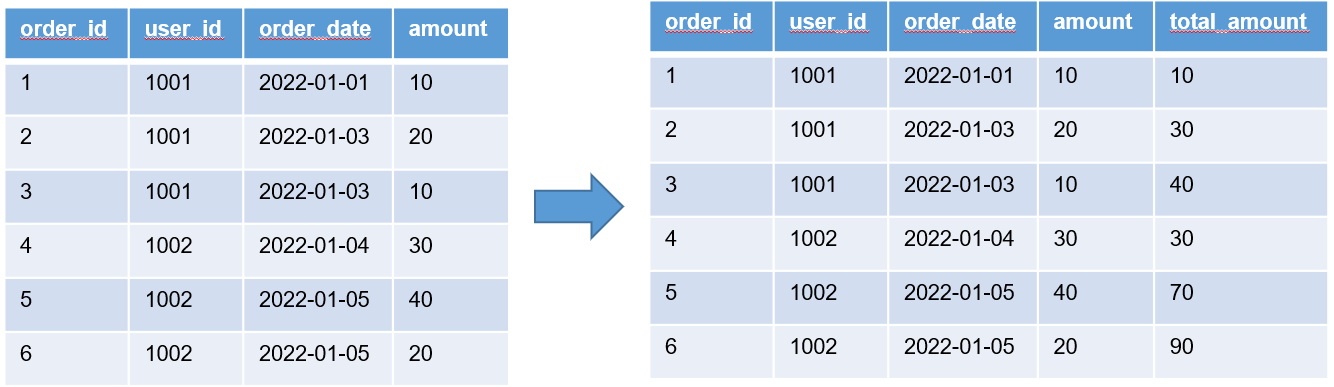
2.2.3 常用窗口函数
按照功能,常用窗口可划分为如下几类:聚合函数、跨行取值函数、排名函数。
1)聚合函数
max:最大值。
min:最小值。
sum:求和。
avg:平均值。
count:计数。
2)跨行取值函数
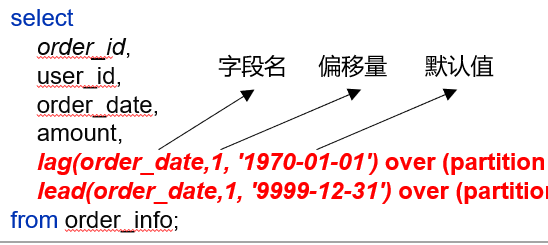
(1)lead和lag
功能:获取当前行的上/下边某行、某个字段的值。
lag表示前,lead表示后边
select
order_id,
user_id,
order_date,
amount,
lag(order_date,1, '1970-01-01') over (partition by user_id order by order_date) last_date,
lead(order_date,1, '9999-12-31') over (partition by user_id order by order_date) next_date
from order_info;

注:lag和lead函数不支持自定义窗口。
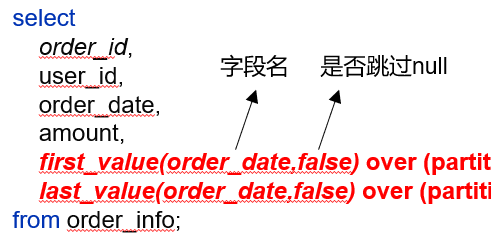
(2)first_value和last_value
功能:获取窗口内某一列的第一个值/最后一个值
select
order_id,
user_id,
order_date,
amount,
first_value(order_date,false) over (partition by user_id order by order_date) first_date,
last_value(order_date,false) over (partition by user_id order by order_date) last_date
from order_info;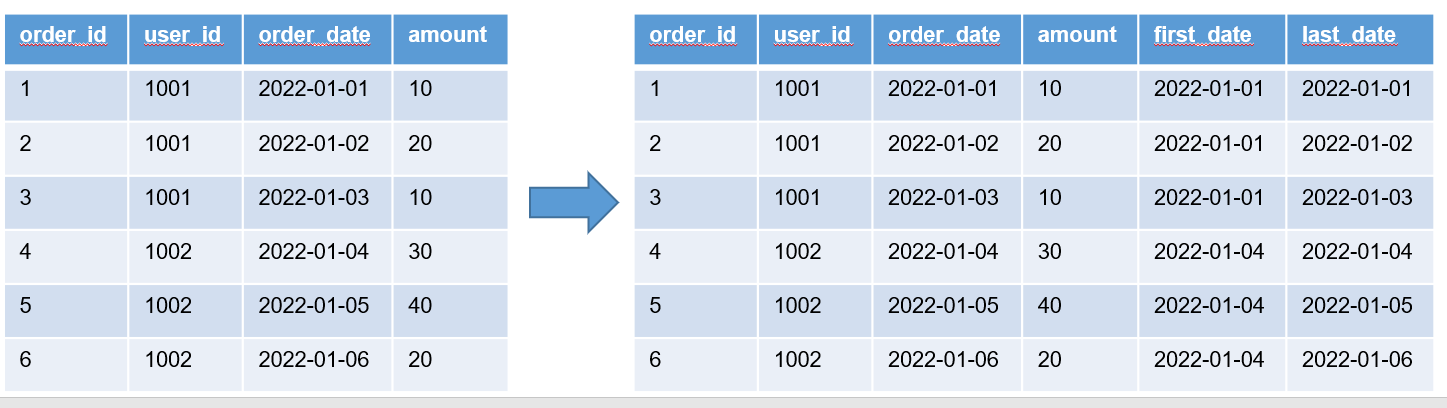
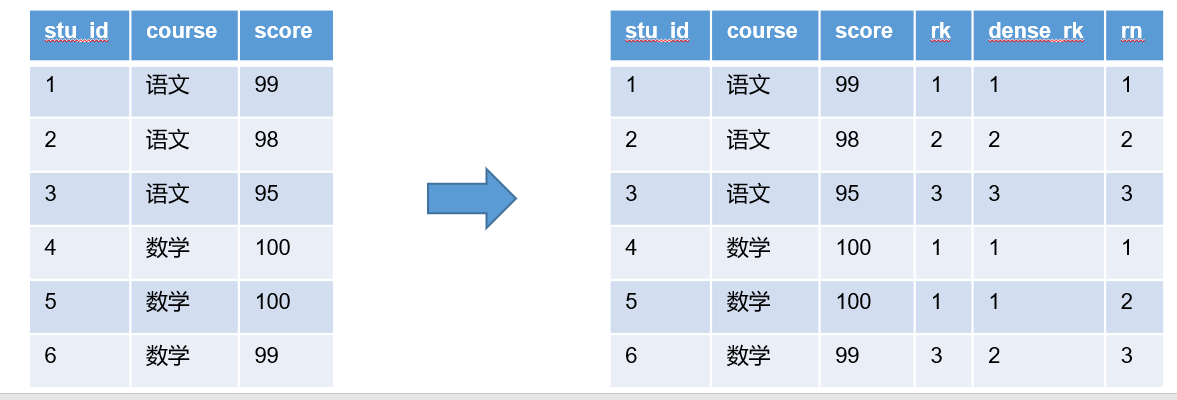
3)排名函数
功能:计算排名
select
stu_id,
course,
score,
rank() over(partition by course order by score desc) rk,
dense_rank() over(partition by course order by score desc) dense_rk,
row_number() over(partition by course order by score desc) rn
from score_info;
注:rank 、dense_rank、row_number不支持自定义窗口。
3 自定义函数
3.1 基本知识
1)Hive自带了一些函数,比如:max/min等,但是数量有限,自己可以通过自定义UDF来方便的扩展。
2)当Hive提供的内置函数无法满足你的业务处理需要时,此时就可以考虑使用用户自定义函数(UDF:user-defined function)。
3)根据用户自定义函数类别分为以下三种:
(1)UDF(User-Defined-Function)
一进一出。
(2)UDAF(User-Defined Aggregation Function)
用户自定义聚合函数,多进一出。
类似于:count/max/min
(3)UDTF(User-Defined Table-Generating Functions)
用户自定义表生成函数,一进多出。
如lateral view explode()
4)官方文档地址
https://cwiki.apache.org/confluence/display/Hive/HivePlugins
5)在实际中自定义函数使用次数较少,且在使用时,通常定义单行函数
3.2 实现自定义函数
自定义一个UDF实现计算给定基本数据类型的长度为例,这里只讲使用方法,而不是函数逻辑
3.2.1 创建Maven项目
1)导入以下依赖
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-exec</artifactId>
<version>3.1.3</version>
</dependency>2)创建类
import org.apache.hadoop.hive.ql.exec.UDFArgumentException;
import org.apache.hadoop.hive.ql.metadata.HiveException;
import org.apache.hadoop.hive.ql.udf.generic.GenericUDF;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.PrimitiveObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.primitive.PrimitiveObjectInspectorFactory;
public class MyLength extends GenericUDF {
@Override
public ObjectInspector initialize(ObjectInspector[] args) throws UDFArgumentException {
// 在运行sql时,运行当前函数之前调用一次initialize
// ObjectInspector对象检查器 校验参数个数
if (args.length != 1) {
throw new UDFArgumentException("只接受一个参数");
}
// 参数类型校验
ObjectInspector arg = args[0];
if (ObjectInspector.Category.PRIMITIVE != arg.getCategory()) {
throw new UDFArgumentException("只接受基本数据类型的参数");
}
// 参数类型校验
PrimitiveObjectInspector primitiveObjectInspector = (PrimitiveObjectInspector) arg;
if (primitiveObjectInspector.getPrimitiveCategory() != PrimitiveObjectInspector.PrimitiveCategory.STRING) {
throw new UDFArgumentException("只接受String类型的参数");
}
// 返回整数类型
return PrimitiveObjectInspectorFactory.javaIntObjectInspector;
}
@Override
public Object evaluate(DeferredObject[] args) throws HiveException {
// 每处理一行数据,调用一次evaluate
// 不用再校验参数
DeferredObject arg = args[0];
Object o = arg.get();// 获取到数据
if (o == null) { // 行内数据可能为null
return 0;
} else {
return o.toString().length();
}
}
@Override
public String getDisplayString(String[] strings) {
// 使用explain后,在执行计划中展示的东西
// 一般不用写
return null;
}
}
3.2.2 创建临时函数
当前会话断了,就无法在使用
1)打包并上传到Hive所在的服务器
- 打包
- 上传
2)将jar包添加到hive的classpath,临时生效
add jar /opt/module/hive-3.1.3/data/length.jar;
3)创建临时函数与开发好的java class关联
create temporary function my_len
as "MyLength"; -- 这里是全限定路径名4)在hql中使用自定义的临时函数


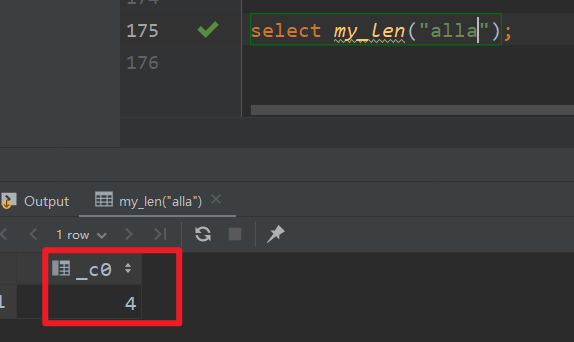
3.2.3 创建永久函数
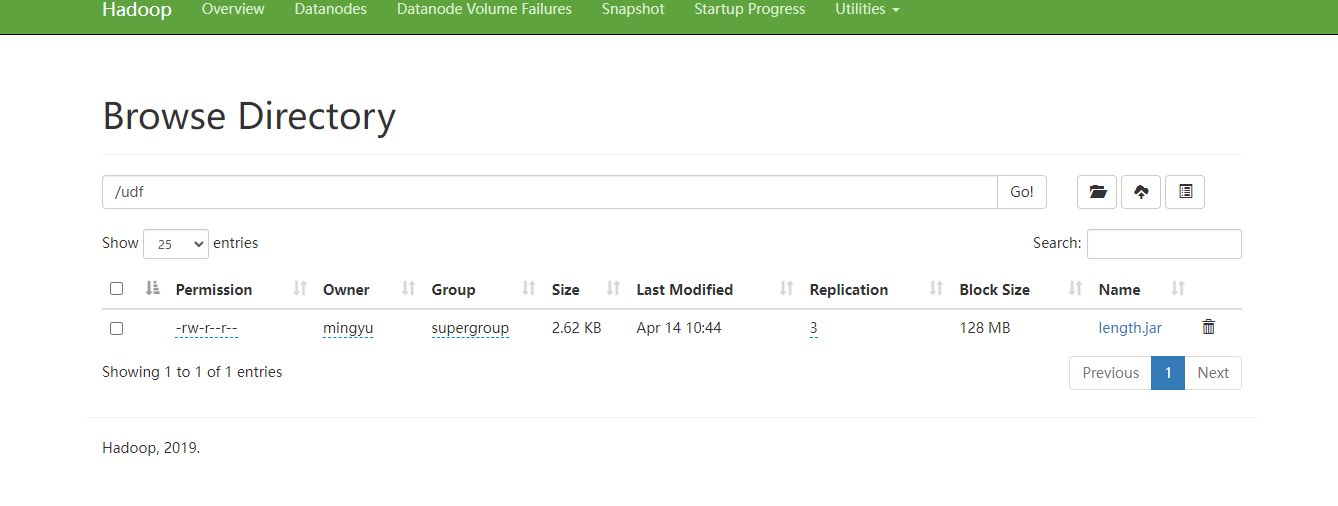
注意:因为add jar本身也是临时生效,所以在创建永久函数的时候,需要制定路径(并且因为元数据的原因,这个路径还得是HDFS上的路径)。
1) 上传length.jar到hdfs
2) 创建永久函数
create function my_len
as "MyLength"
using jar "hdfs://hadoop102:8020/udf/length.jar";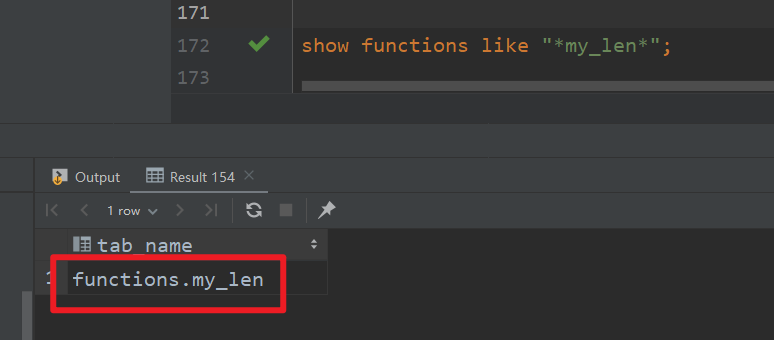
3)使用永久函数
创建了永久函数之后,会在函数名之前加上数据库的名称,在functions库中使用该函数直接用my_len(),其它数据库使用该函数则需要加上数据库名,例如functions.my_len()
functions数据库
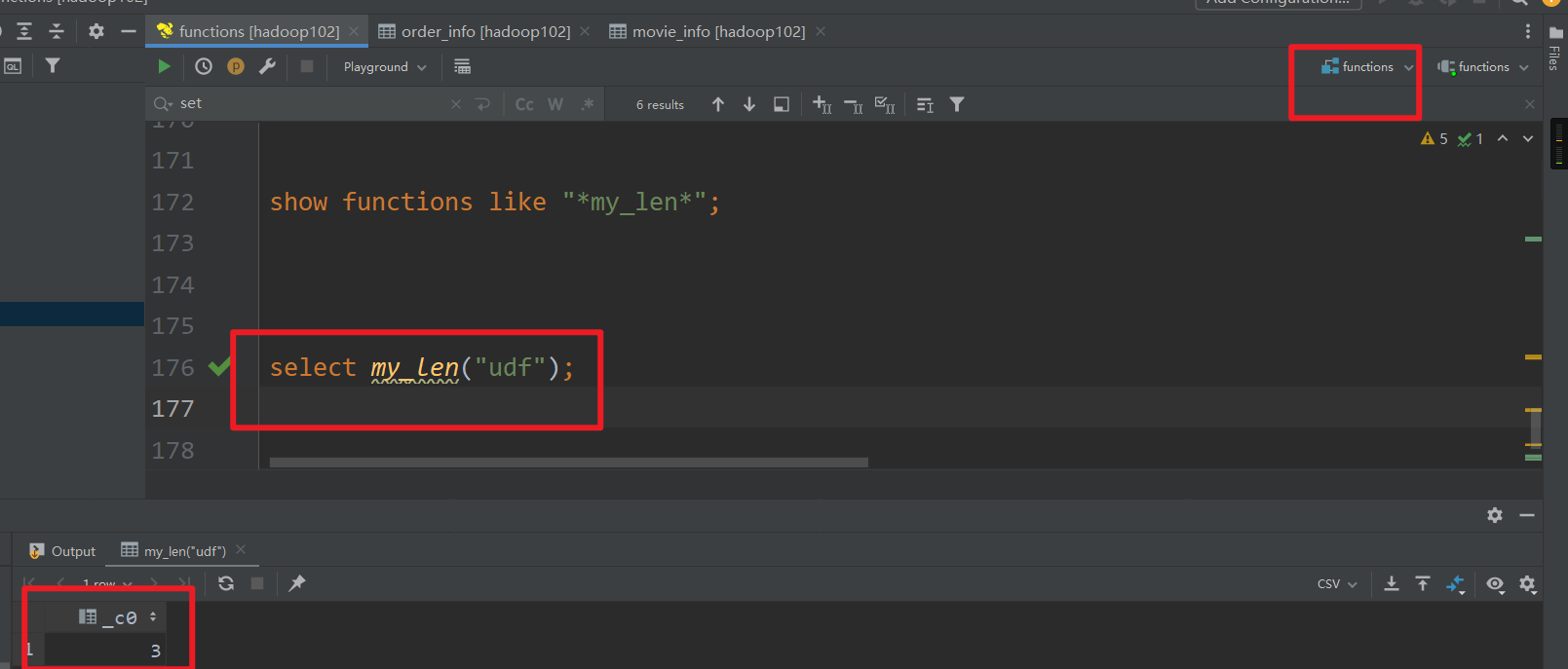
其它数据库
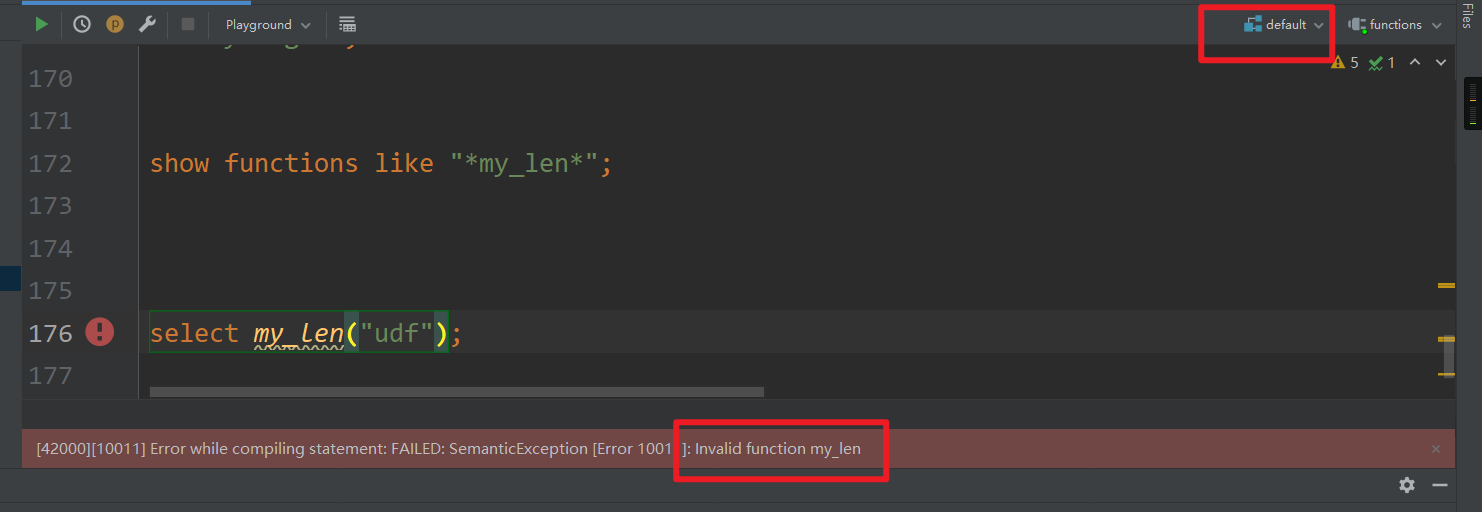
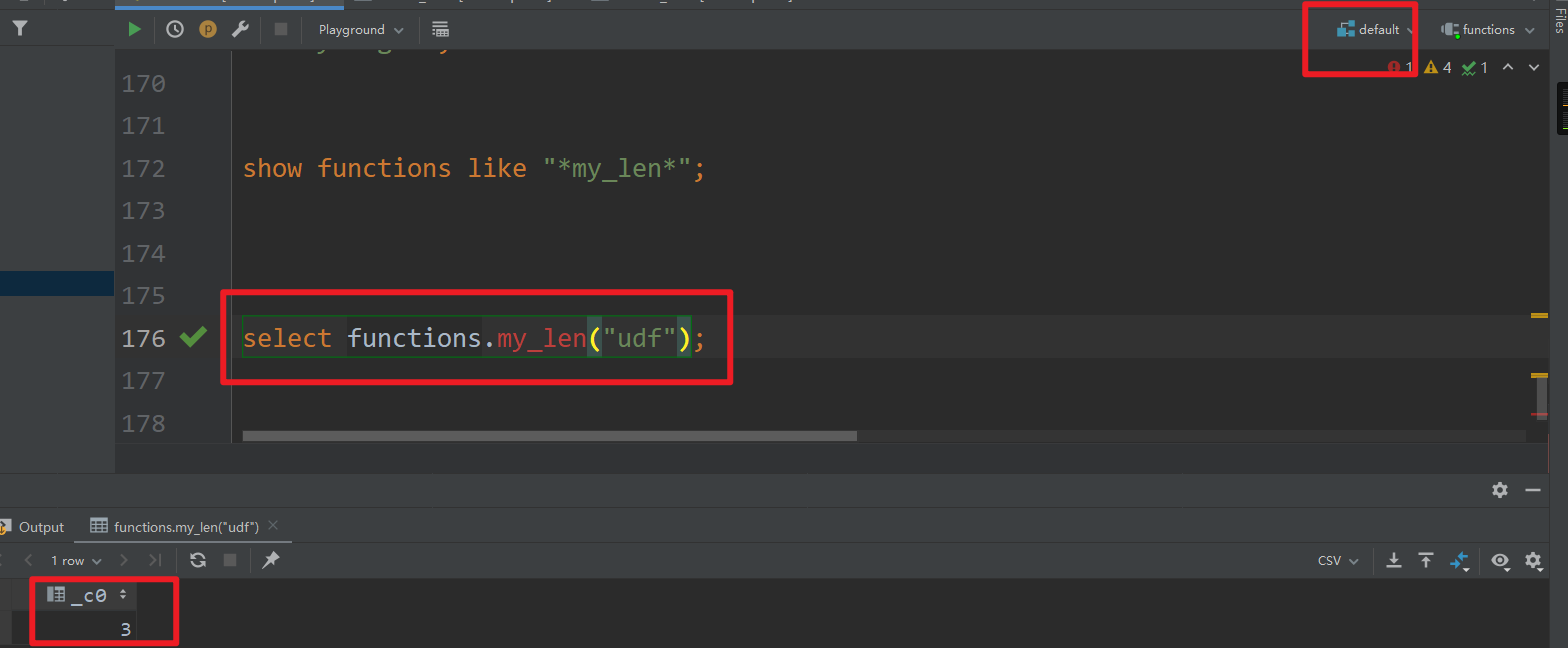
(my_len爆红是因为DataGrip的bug)




![[Java]Session机制](https://img-blog.csdnimg.cn/ec3d29351ac24586a1ae608eb497601c.png)