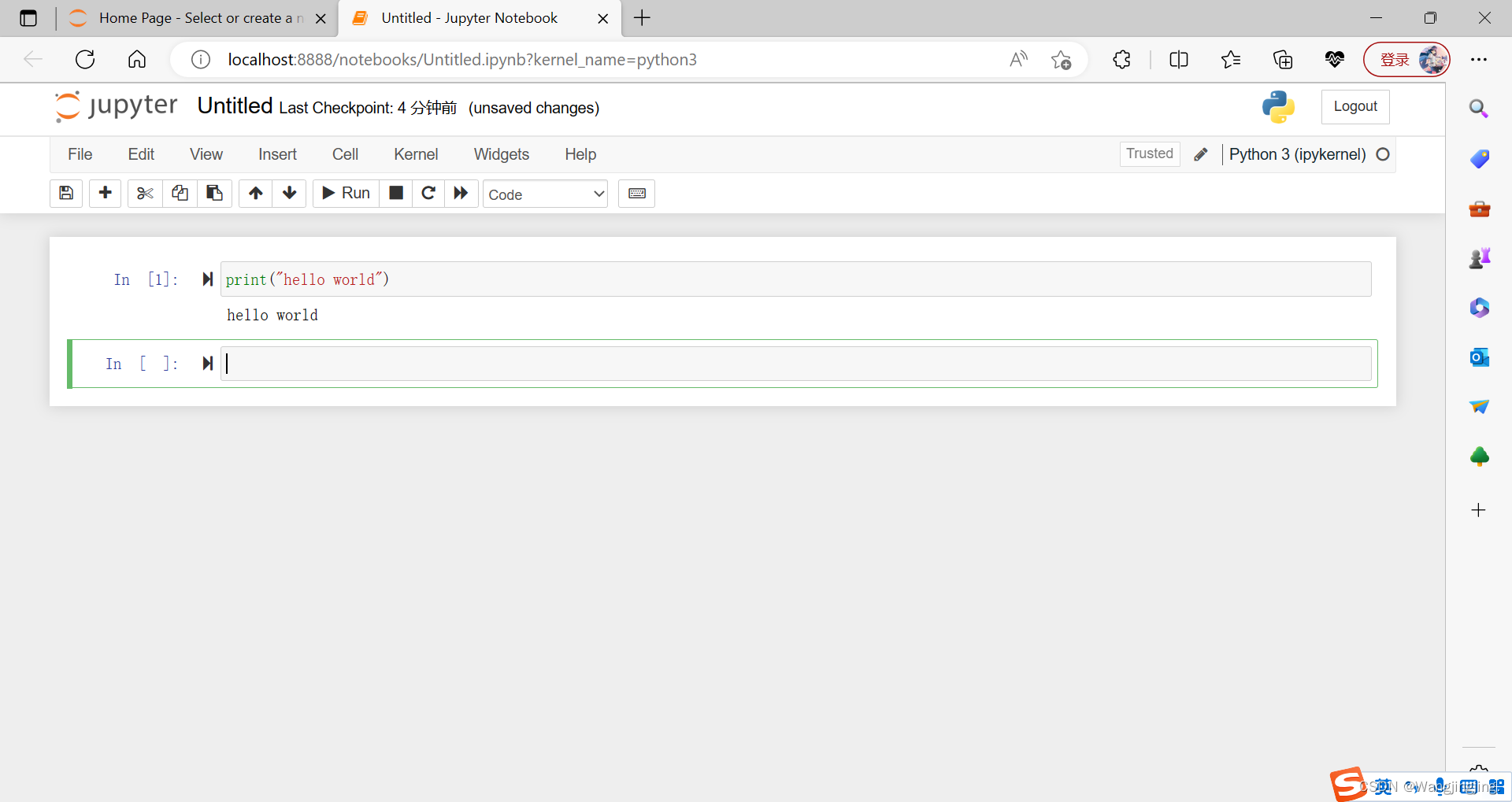
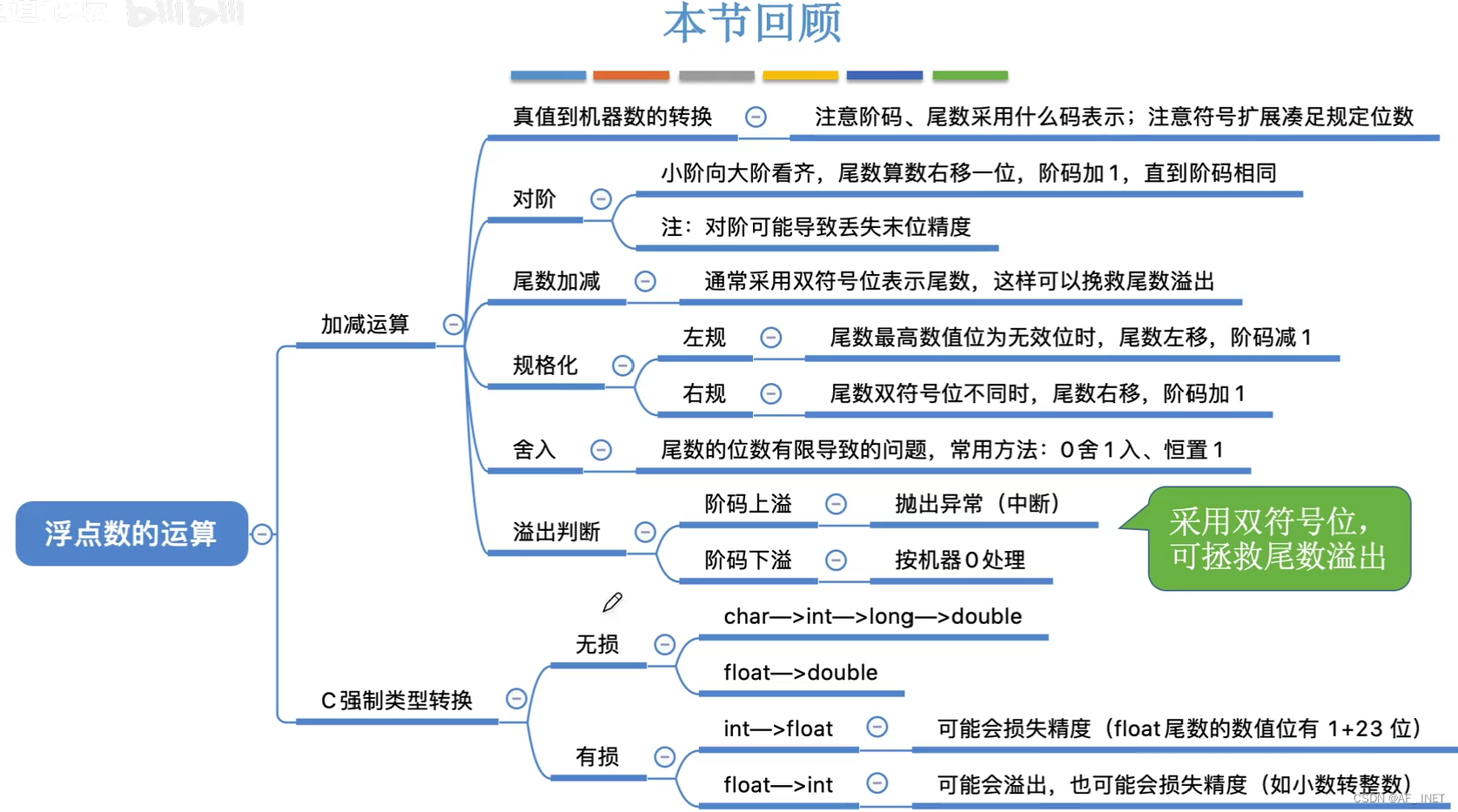
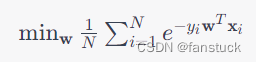纠正:上图中是通过根元素、父元素、子元素…


Xpath检索方法及路径:


绝对路径代码示例:
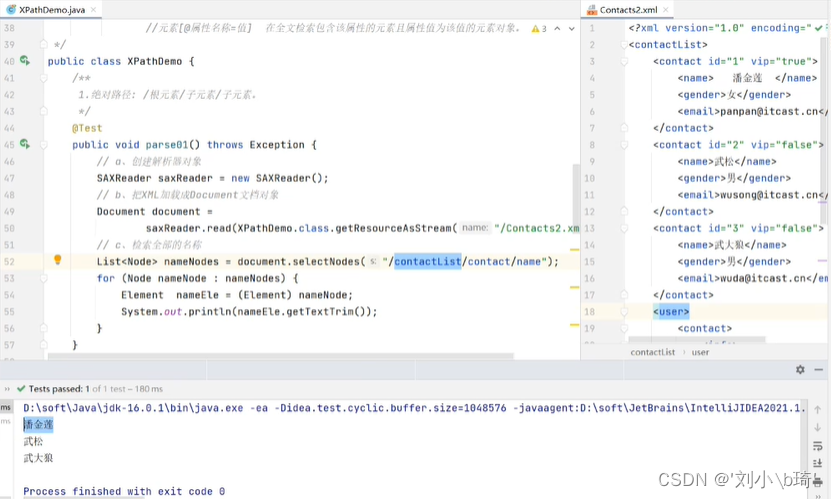 47行:Xpath解析技术也是基于Dom4J的技术;
47行:Xpath解析技术也是基于Dom4J的技术;
52行:List<Node> 创建Node类型的集合nameNodes,selectNodes(…)方法是检索XML元素,它 只能一级一级的检索,括号中放的是“/根元素名/子元素名/孙元素名”。这样它就会找到XML 文件中所有符合这一路径的孙元素(name);
53行:遍历nameNodes集合;
54行:将每一个集合中的元素转换成Element类型;
55行:获取所有name元素去掉空格后的文本内容,运行结果如图所示。

相对路径代码示例:
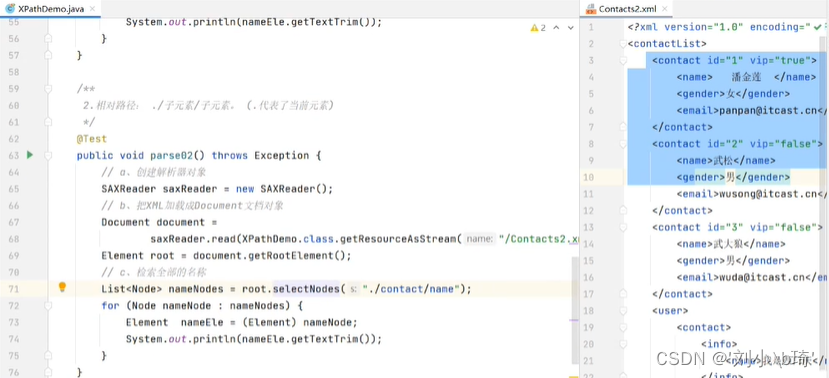 69行(前同绝对路径):获取一个根元素;
69行(前同绝对路径):获取一个根元素;
71行(后同绝对路径):root.selectNodes(…)是在根元素中检索元素,括号中放的是“./子元素名/孙元素名” ,其中的“.”指的是当前的(根)元素。这样它就会找到XML文件的根元素中所有符合这一路径的孙元素(name),运行结果如图所示。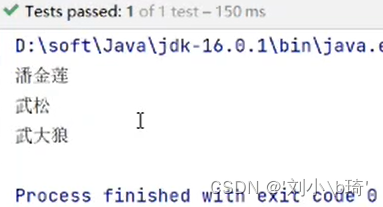

全文检索代码示例:
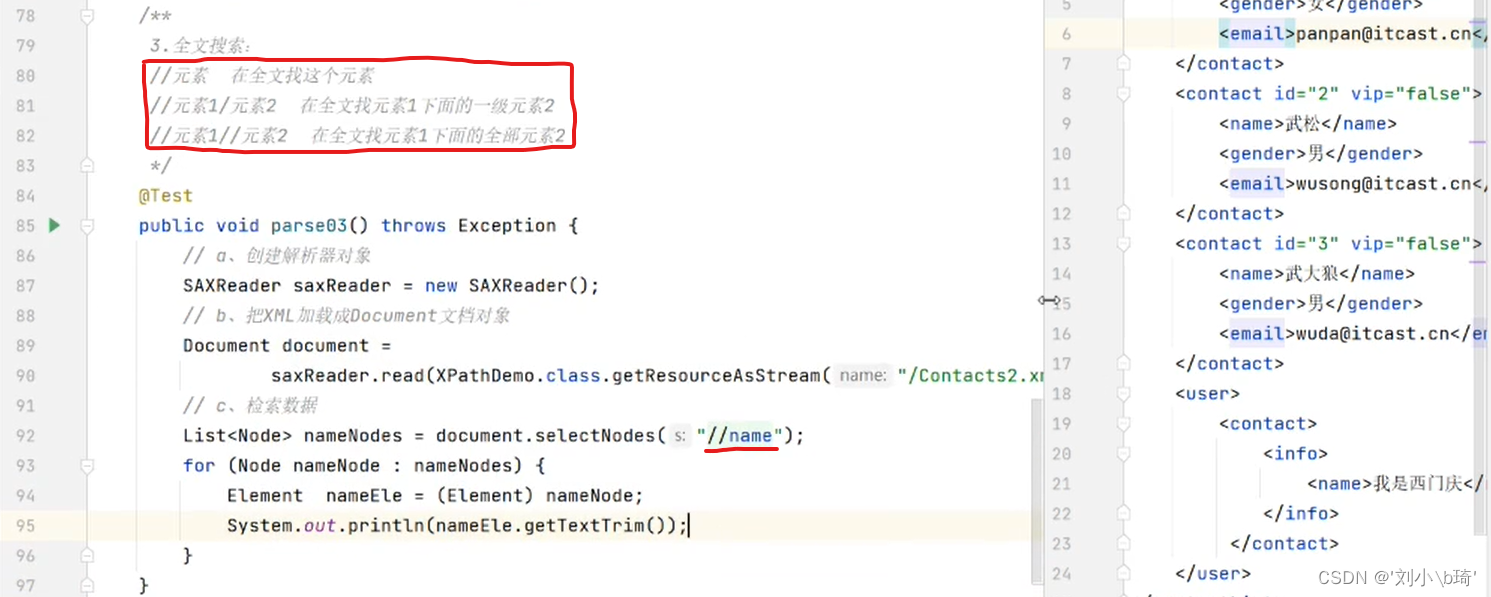
【在全文查找元素】
图中的“//name”,意思是在全文中找name元素,此时检索的是XML文件中所有的name元素,所以在运行时会显示与之前不同路径下的name元素“我是西门庆”,如图。
【在全文查找所有元素1下面的一级元素2】
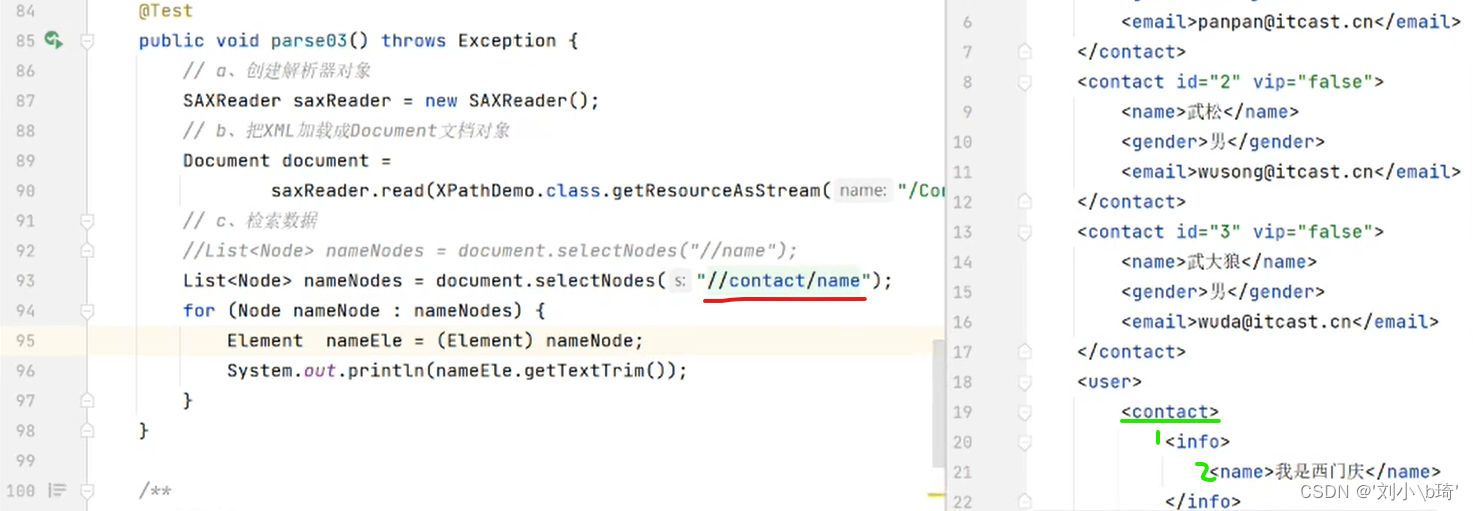 图中的“//contact/name",意思是在XML文件中检索所有元素1 contact下面的一级元素2 name,在运行时将不会再有“我是西门庆”的name元素,因为它是contact的二级元素,运行结果如图。
图中的“//contact/name",意思是在XML文件中检索所有元素1 contact下面的一级元素2 name,在运行时将不会再有“我是西门庆”的name元素,因为它是contact的二级元素,运行结果如图。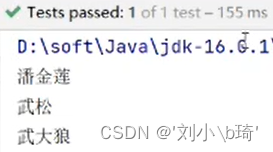
【在全文查找所有元素1下面的所有元素2】
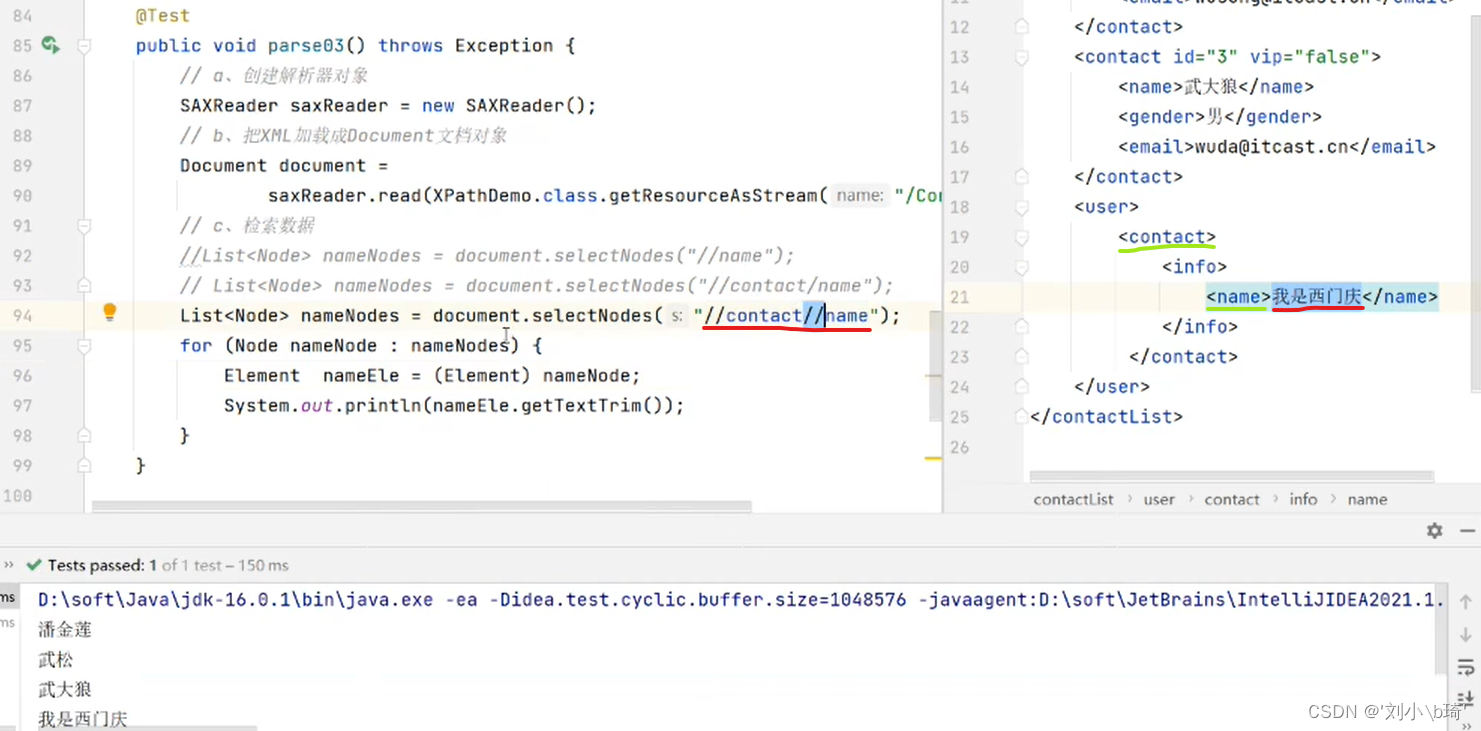
图中的“//contact//name",意思是在XML文件中检索所有元素1 contact下面的所有元素2 name,在运行时会出现“我是西门庆”的name元素,因为它存在于contact元素下,运行结果如图所示。

属性查找代码示例:
【在全文检索属性对象】
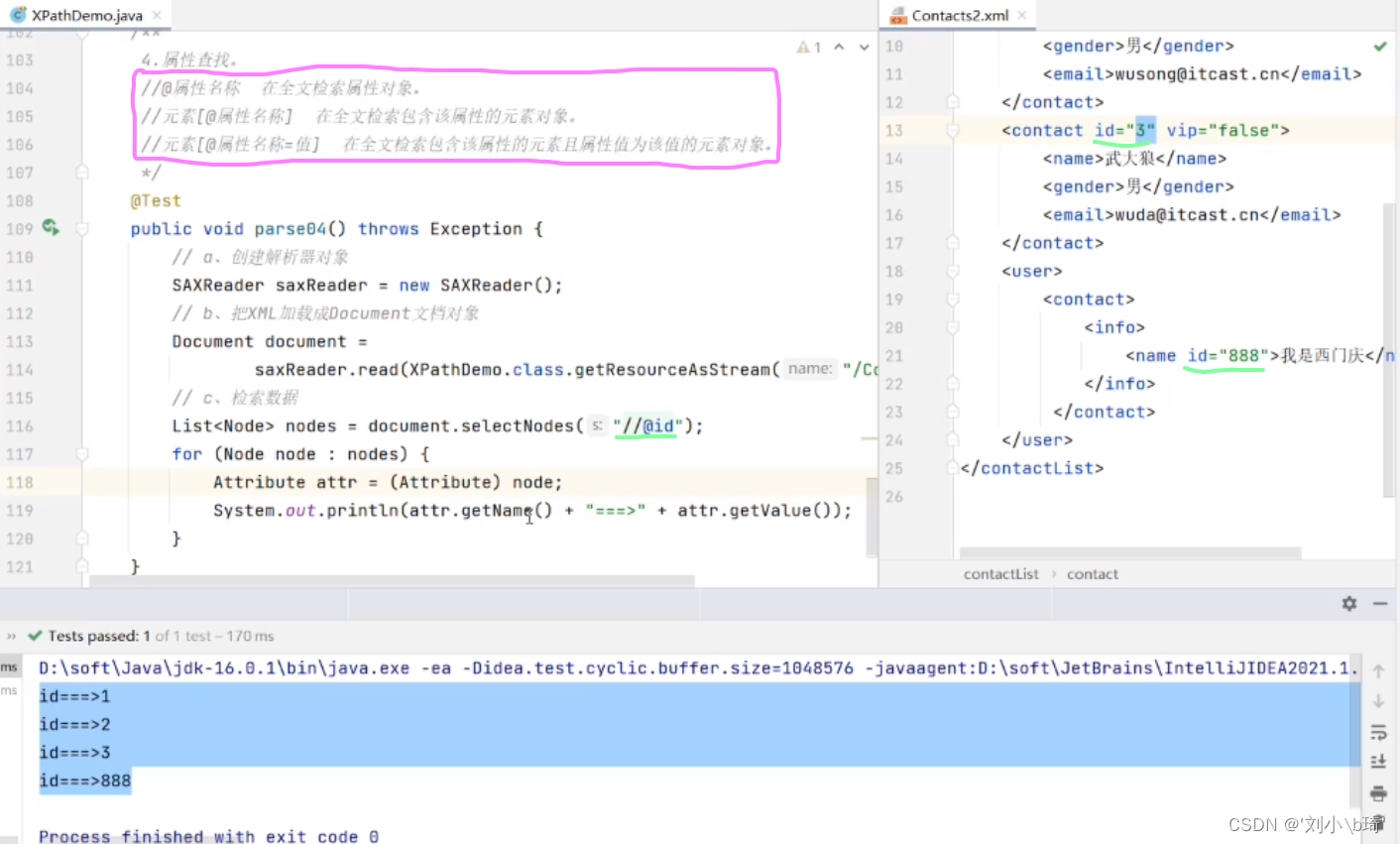
116行:“//@id”意思是在XML文件中检索全部名为id的属性元素,注意:检索属性元素时,需在元 素名前加@符号。
118行:把遍历到的集合中检索到的每一个id属性元素转换成属性类型(Attribute)。
【在全文中检索包含某属性的元素对象】
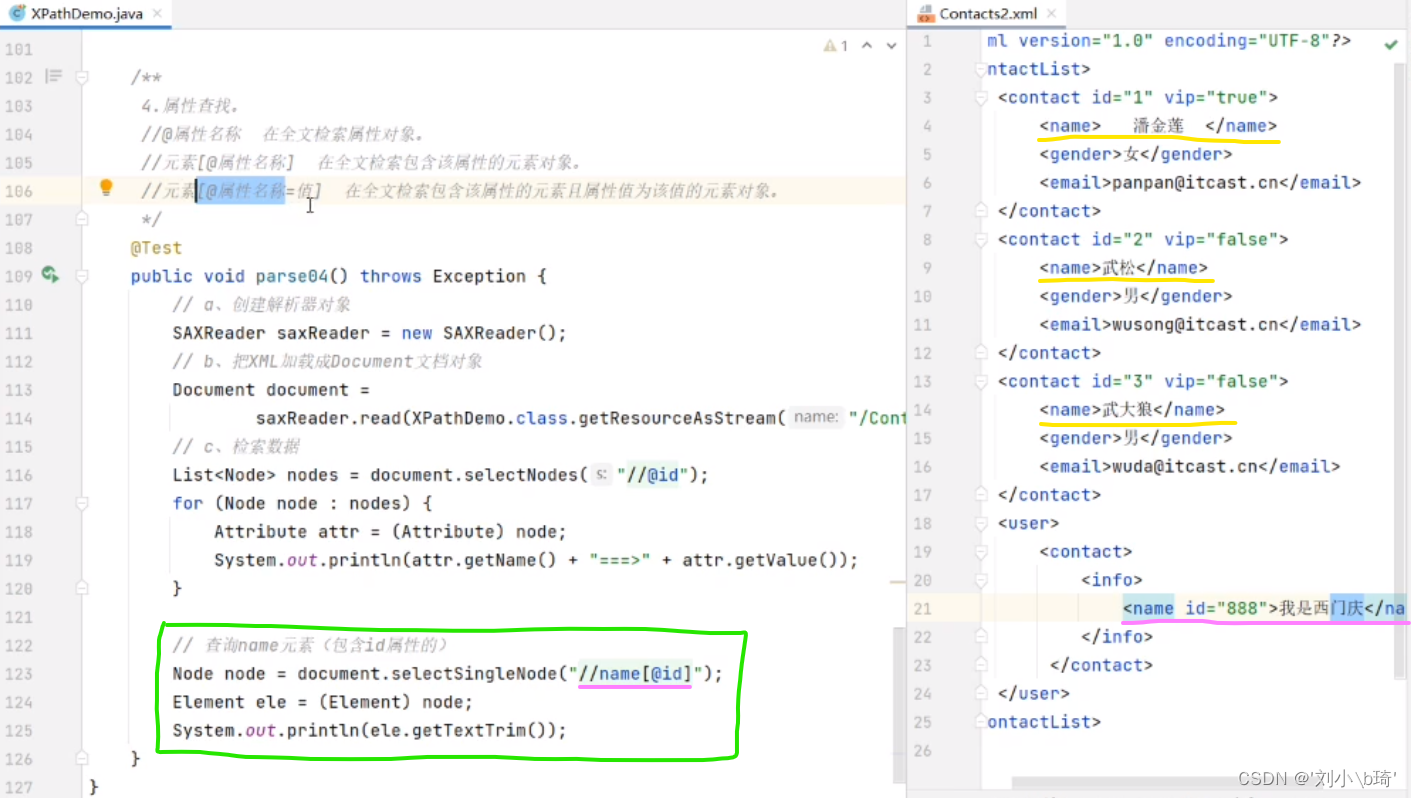
图中的“//name[@id]",意思是在XML文件中检索所有含id属性的元素,在运行时只会出现“我是西门庆”的name元素,因为只有这一个name元素中包含id属性元素,运行结果如图。
【在全文检索包含某属性的元素且该属性为指定值的元素对象】

图中的“//name[@id=888]",意思是在XML文件中检索所有含id属性且属性值为888的元素,在运行时只会出现“我是西门庆”的name元素,因为只有这一个name元素中包含id属性元素且其属性值为888。
总结: