目录
前言
一、损失函数概述
二、损失函数分类
1.分类问题的损失函数
1.交叉熵损失函数(Cross Entropy Loss)
2.Hinge损失函数
3.余弦相似度损失函数(Cosine Similarity Loss)
4.指数损失函数(Exponential Loss)
点关注,防走丢,如有纰漏之处,请留言指教,非常感谢
前言
损失函数无疑是机器学习和深度学习效果验证的核心检验功能,用于评估模型预测值与实际值之间的差异。我们学习机器学习和深度学习或多或少都接触到了损失函数,但是我们缺少细致的对损失函数进行分类,或者系统的学习损失函数在不同的算法和任务中的不同的应用。因此有必要对整个损失函数体系有个比较全面的认识,方便以后我们遇到各类功能不同的损失函数有个清楚的认知,而且一般面试以及论文写作基本都会对这方面的知识涉及的非常深入。故本篇文章将结合实际Python代码实现损失函数功能,以及对整个损失函数体系进行深入了解。
博主专注建模四年,参与过大大小小数十来次数学建模,理解各类模型原理以及每种模型的建模流程和各类题目分析方法。此专栏的目的就是为了让零基础快速使用各类数学模型、机器学习和深度学习以及代码,每一篇文章都包含实战项目以及可运行代码。博主紧跟各类数模比赛,每场数模竞赛博主都会将最新的思路和代码写进此专栏以及详细思路和完全代码。希望有需求的小伙伴不要错过笔者精心打造的专栏。
一、损失函数概述
我们举一个通俗的例子:”假如你玩一个抽卡游戏,这段时间新活动刚好出了一个新的角色你想要抽到她,一般来说抽到这个角色基本都要保底,大部分人都需要一个648才能抽到,但是你的手气实在太非了,氪了两个648才抽到了,那么这和你预估的结果少了一个648的钱,也就是你大抵损失的金额。“通过上面这个例子我们再将大部分人预估抽到的金额设定为Y,而且实际用到的抽奖金额为Y',那么两者的差距|Y-Y'|就是损失函数了。
那么我们通过案例很容易明白损失函数就是用以衡量实际值和预测值在当前位置的差值或误差,这提高了一些模型的有效性,通过向模型提供反馈,使其可以调整参数以最大程度减少误差。
二、损失函数分类
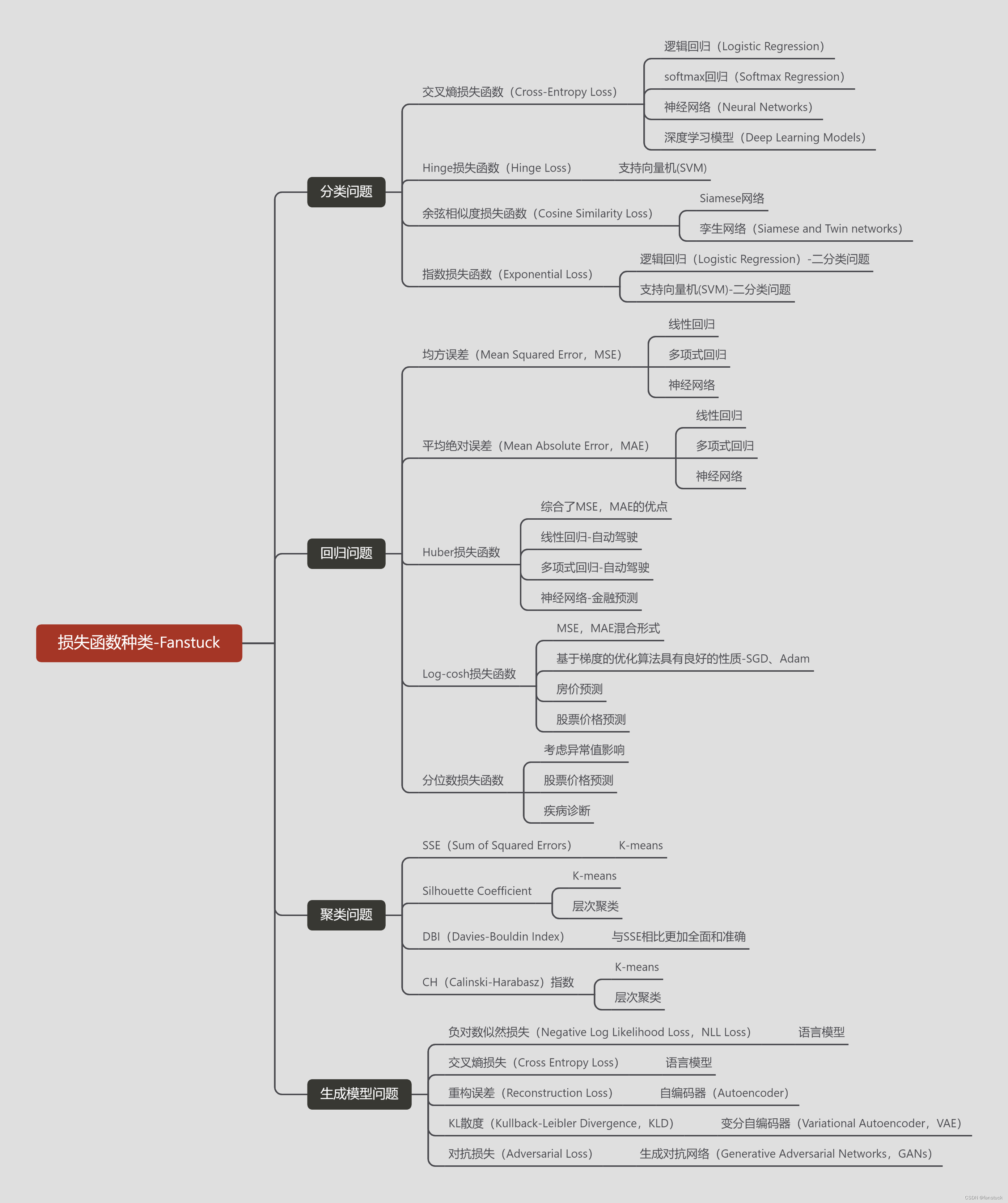
我们知道损失函数就是衡量预测值和实际值的差量,那么根据算法需要解决的目标问题分类就可以将整个损失函数进行分类。
1.分类问题的损失函数
分类问题是机器学习领域中最为常见的问题之一。在分类问题中,我们需要根据给定的输入特征将其分为多个预定义的类别之一。分类问题的损失函数是用来评估分类器的预测值与真实标签之间的差异,从而指导分类器的训练。
1.交叉熵损失函数(Cross Entropy Loss)
交叉熵损失函数是用于度量分类问题中预测值与真实标签之间的差距,它在深度学习中得到了广泛的应用。交叉熵损失函数在多分类问题中的表现非常好,比如在图像分类、自然语言处理等领域。
假设有个类别,对于一个样本
,其真实类别标签是
,模型预测的类别概率分布为
,其中
表示样本
属于第
类的概率。那么交叉熵损失函数的计算公式为:
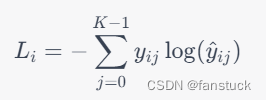
其中,表示样本
是否属于第
类,
表示属于,
表示不属于。因为对于每个样本来说,只有一个标签是正确的,所以这个损失函数的实际含义是用正确的标签来对模型预测结果进行惩罚。
交叉熵损失函数的本质是用来度量两个概率分布之间的距离。在分类问题中,我们希望模型输出的概率分布能够与真实标签的分布尽量接近。如果预测值和真实值相同,交叉熵损失函数就趋近于。如果预测值和真实值不同,交叉熵损失函数就会变得非常大。
在Python中,可以使用TensorFlow、PyTorch等深度学习框架中提供的函数来计算交叉熵损失函数。
在TensorFlow 2.x版本中,可以使用tf.keras.losses模块提供的交叉熵损失函数来进行计算。
import tensorflow as tf
# 定义标签和预测值
y_true = [[0, 1], [0, 0]]
y_pred = [[0.6, 0.4], [0.4, 0.6]]
# 定义交叉熵损失函数
cross_entropy_loss = tf.keras.losses.CategoricalCrossentropy()
# 计算损失函数值
loss = cross_entropy_loss(y_true, y_pred)
print(loss.numpy()) # 输出损失函数值
y_true表示真实标签,y_pred表示预测值。通过tf.keras.losses.CategoricalCrossentropy()定义交叉熵损失函数,然后调用该函数并传入真实标签和预测值即可计算损失函数值。

在PyTorch中,可以使用torch.nn.CrossEntropyLoss()函数来计算交叉熵损失函数。
import torch
# 计算交叉熵损失函数
logits = torch.tensor([[1.0, 2.0, 3.0], [2.0, 1.0, 3.0], [3.0, 2.0, 1.0]]) # 预测值
labels = torch.tensor([2, 1, 0]) # 真实值
criterion = torch.nn.CrossEntropyLoss()
loss = criterion(logits, labels)
print(loss.item()) 
2.Hinge损失函数
Hinge损失函数是一种常用于支持向量机(SVM)的损失函数,用于解决分类问题。
假设有训练集,其中
为输入特征向量,
为输出标签。分类问题的目标是在训练集上学习一个线性分类器
,使得预测标签
和真实标签
的误差最小。
Hinge损失函数的定义如下:
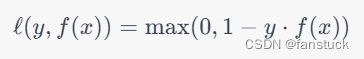
其中,为真实标签,
为预测标签。如果预测正确,则误差为0;如果预测错误,则误差为
。这里的
表示真实标签和预测标签之间的乘积。
对于线性分类器,我们可以用决策函数来表示。其中,
为权重向量,
为偏置项。我们希望找到一个最优的
和
,使得在训练集上的损失函数最小化。
Hinge损失函数的优化目标是:
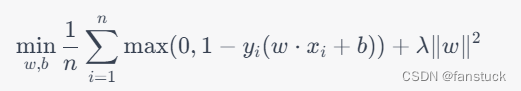
为了优化Hinge损失函数,我们可以使用梯度下降算法来求解最优的权重向量和偏置项。具体来说,对于第个样本
,其梯度为:
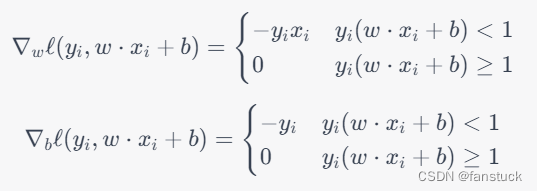
在每一轮迭代中,我们随机选择一个样本,并更新权重向量和偏置项:
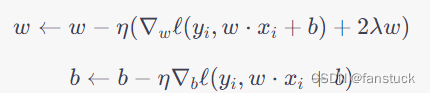
其中,为学习率。这样不断地迭代,直到达到收敛条件为止。
在Python中,可以使用NumPy库实现Hinge损失函数的计算。
import numpy as np
def hinge_loss(y_true, y_pred):
# 计算每个样本的Hinge损失
loss = np.maximum(0, 1 - y_true * y_pred)
# 计算所有样本的平均损失
avg_loss = np.mean(loss)
return avg_loss
其中,y_true是真实标签,y_pred是模型的预测输出。这个函数返回的是所有样本的平均Hinge损失。如果想要计算单个样本的Hinge损失,可以直接使用np.maximum(0, 1 - y_true * y_pred)。
3.余弦相似度损失函数(Cosine Similarity Loss)
余弦相似度(Cosine Similarity)是一种常用的相似度度量方法,通常用于计算两个向量之间的相似程度。在神经网络中,可以使用余弦相似度损失函数来度量模型输出的向量与标签向量之间的相似程度。其计算原理如下:
假设模型输出的向量为 ,标签向量为
,则余弦相似度可以表示为它们之间的夹角余弦值:
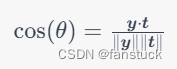
其中, 表示
和
的内积,
和
分别表示
和
的模长。由于余弦相似度的取值范围
之间,因此可以使用
作为损失函数,使得损失函数的取值范围在
之间。
当和
的夹角
较小时,它们的余弦相似度较大,损失函数的取值较小,表示模型的输出与标签的相似度较高;当
较大时,它们的余弦相似度较小,损失函数的取值较大,表示模型的输出与标签的相似度较低。
因此,使用余弦相似度损失函数可以促进模型输出向量与标签向量之间的相似程度的提高。
余弦相似度损失函数的计算过程比较简单,可以直接使用NumPy实现。假设有两个向量和
,则余弦相似度损失函数的计算方法如下:
import numpy as np
def cosine_loss(x, y):
# 计算向量x和y的余弦相似度
cosine_sim = np.dot(x, y) / (np.linalg.norm(x) * np.linalg.norm(y))
# 将余弦相似度转化为损失
loss = 1 - cosine_sim
return loss
其中,np.dot(x, y)表示向量和
的点积,
np.linalg.norm(x)表示向量的范数,
1 - cosine_sim表示余弦相似度损失函数的值。
4.指数损失函数(Exponential Loss)
指数损失函数(Exponential Loss)是一种二分类损失函数,通常用于概率估计问题。
假设有一组数据 ,其中
是一个
维特征向量,
是一个二分类的标签,表示样本属于哪一类。对于一个给定的模型,它可以计算每个样本属于正类的概率
,则指数损失函数可以表示为:
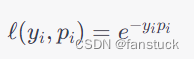
其中 是样本的真实标签,
是样本属于正类的预测概率。指数损失函数的含义是:如果样本的真实标签为
,但是模型预测其属于负类的概率
较高,那么指数损失函数的值将会非常大;反之,如果样本的真实标签为
,但是模型预测其属于正类的概率
较高,那么指数损失函数的值也会非常大。
对于一组数据 ,假设模型的参数为
,则该数据集上的指数损失函数可以表示为:
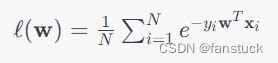
其中是数据集的大小。对于一个二分类问题,
表示样本
属于正类的概率,可以通过模型输出的概率值计算得到。
模型的训练目标是最小化所有样本的指数损失函数之和,即:
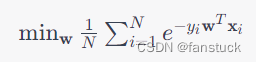
可以使用梯度下降等优化算法求解上述问题。
需要注意的是,指数损失函数对异常值比较敏感,因此需要注意数据的预处理和模型的选择。
import numpy as np
def exponential_loss(y_true, y_pred):
"""
计算指数损失函数
:param y_true: 真实标签,形状为(n_samples, )
:param y_pred: 模型预测概率,形状为(n_samples, )
:return: 指数损失值,标量
"""
loss = np.exp(-y_true * y_pred)
return np.mean(loss)
对于二分类问题,真实标签通常为1或-1,模型的预测概率通常为一个实数,可以通过sigmoid函数将其转换为0到1之间的概率值。对于多分类问题,可以使用softmax函数将模型的输出转换为概率分布。
那么分类问题常见损失函数就已经差不多了,下一章我将详细对回归问题的损失函数进行讲解。
点关注,防走丢,如有纰漏之处,请留言指教,非常感谢
以上就是本期全部内容。我是fanstuck ,有问题大家随时留言讨论 ,我们下期见。