文章目录
- 1. 前言
- 2. 表的设计
- 2.1 一对一
- 2.2 一对多
- 2.3 多对多
- 3.将查询结果放到另一个表中
- 4. 聚合查询
- 4.1 聚合函数
- 4.2 GROUP BY
- 4.3 HAVING
- 5. 联合查询(多表查询)
- 5.1 内连接
- 5.2 外连接
- 5.3 自连接
- 5.4 子查询
- 5.5 合并查询
- 6. 总结
1. 前言
文章主要围绕着以下三个问题:
- group by的作用
- where与having的区别
- 表的连接分为哪些,分别是什么作用
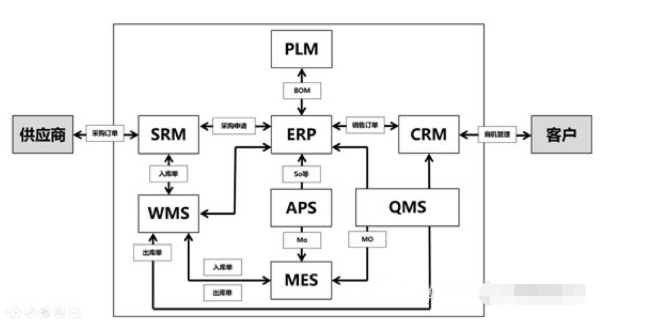
2. 表的设计
在创建数据表时,我们通常时根据需求找到"实体", 梳理"实体"之间的关系,从而进行创建.
"实体"之间可能会有以下几种关系:1.没关系 2.一对一 3.一对多 4.多对多.
没关系应该是最好理解的,就是单独的一张表,并不涉及到其它的表.
2.1 一对一
一对一的关系在生活中是很常见的,例如每个学生都有属于自己的学号,每个学号就只对应一个学生. 类似于这样的情况,就是一对一的关系.
此时就可以创建两张表,一个是学生表,另一个是学号表. 学生表里的学号就可以和学号表中的学号关联起来.
2.2 一对多
学生在学校上课时,会有一个班级. 但是一个班级可以有多个学生. 这就是一对多的关系.
2.3 多对多
举个例子,我们在学习课程时,可以选择多门课程进行学习,而课程也可以被多个学生进行选择. 这就是多对多的关系.
多对多的关系,在创建表时,可以使用"关联表" 将两个实体联系起来.
如果在设计数据库表时,场景很复杂,可以使用ER图帮助我们更好的创建数据库表.
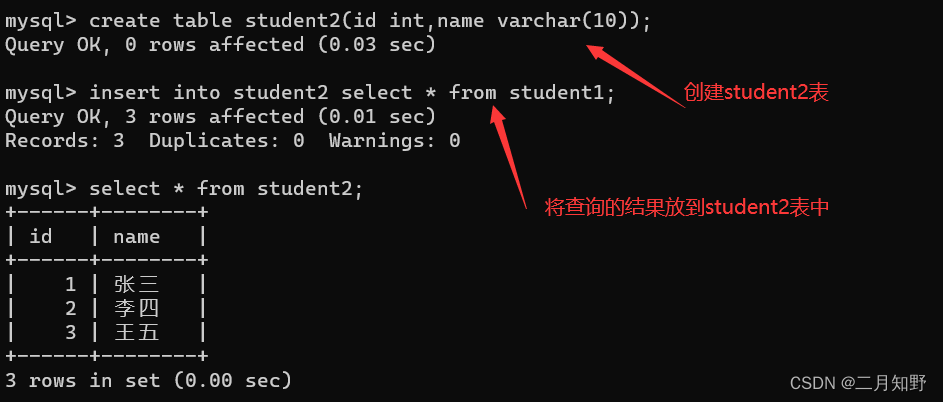
3.将查询结果放到另一个表中
insert into 表2 select 字段 from 表1;
# 表2 是要存放查询结果的表
# 表1 是要查询的表
# 查询结果的列要和表2的列相匹配!
# 也可以将查询结果存放在表2的指定列中
示例:
下面这个"student1"这个表中,有三条数据.
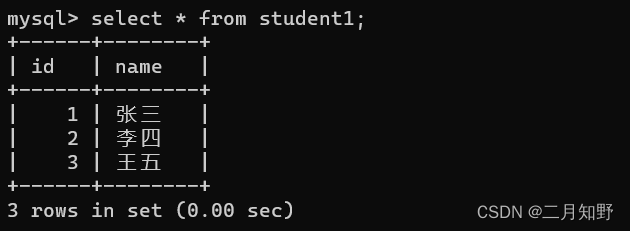
接下来我们把查询结果放到一张新的 "student2"这个表中
4. 聚合查询
聚合查询可以进行"行"与"行"之间的运算
4.1 聚合函数
| 函数 | 说明 |
|---|---|
| COUNT([DISTINCT] expr) | 返回查询到的数据的 数量 |
| SUM([DISTINCT] expr) | 返回查询到的数据的 总数 |
| AVG([DISTINCT] expr) | 返回查询到的数据的 平均值 |
| MAX([DISTINCT] expr) | 返回查询到的数据的 最大值 |
| MIN([DISTINCT] expr) | 返回查询到的数据的 最小值 |
- count函数 可以对行进行计算,也可以对列进行计算.
示例:
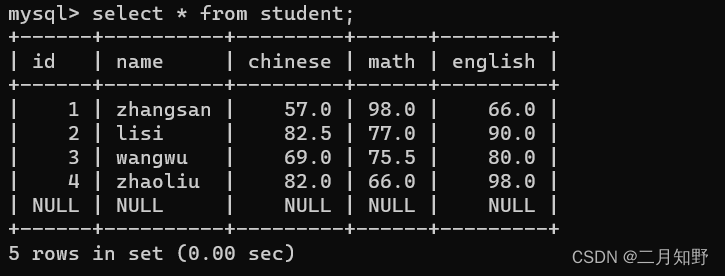
这里有一张学生表,里面有学生的id,姓名,语数英三科的成绩.

- sum,avg,max和min 都是只对数字生效,如果不是数字则没有意义
sum函数的用法和count函数类似. 不过只能计算"列",如果这一列存在"null",则不会参与运算
avg,max,min的用法 和 sum 类似,就不一一介绍了
4.2 GROUP BY
GROUP BY 语句用于结合合计函数,根据一个或多个列对结果集进行分组。
例如:
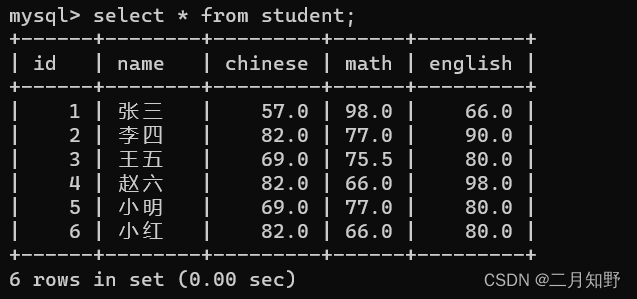
在我的学生表中有这样一些数据.现在我要对语文成绩进行分组
使用group by之后,我们可以看到这已经以语文成绩进行分组了
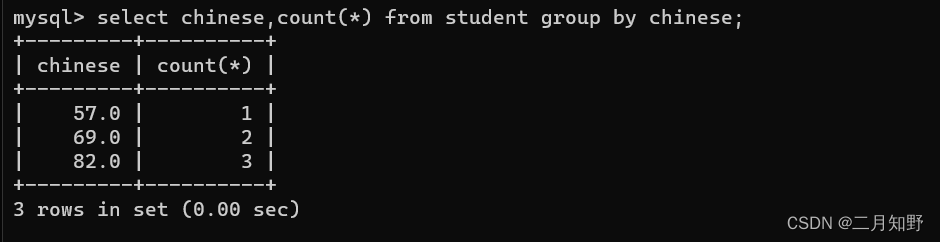
成绩为57的有一个,69的有两个,82的有三个
需要注意的是:在进行查询分组的时候,只有分组的这一列,可以查询,其它列必须搭配聚合函数来进行查询
4.3 HAVING
分组查询还可以指定条件,这里的只当条件可以分组之前指定还可以分组之后指定 分组前进行筛选使用的是where 分组后进行筛选使用的则是having SQL 中增加 HAVING 子句原因就是因为WHERE 关键字无法与合计函数一起使用。
去除id=1的语文成绩后进行分组
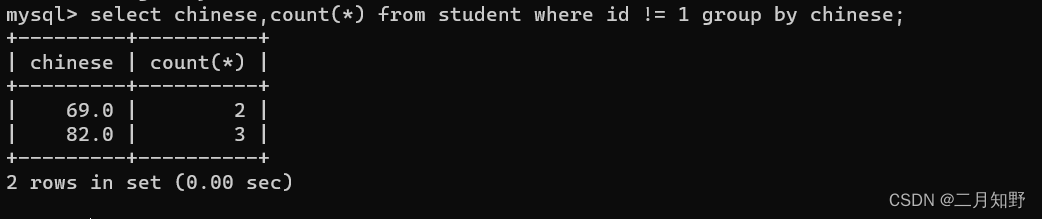
分组之后筛选出语文成绩>60分的学生数量

where 关键字虽然无法与合计函数一起使用,但是可以和having一起使用
5. 联合查询(多表查询)
联合查询一般是在多表之间建立连接后查询的过程.其实就是计算"笛卡尔积"的过程
但是当表很大的时候,如果进行联合查询,效率就会特别低.因为"笛卡尔积"就是简单的排列组合,有些数据是"合理"的,有些数据是"不合理"的.所以我们就要把"有效"的数据筛选出来.因此联合查询通常需要加连接条件和其它筛选条件
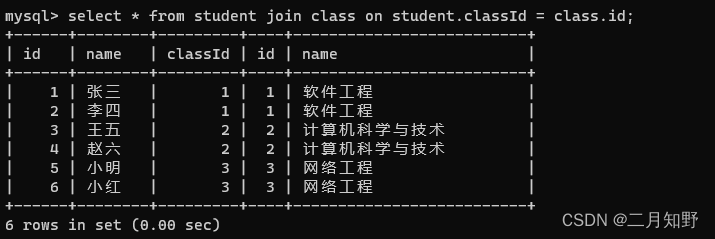
5.1 内连接
内连接得到的是两张表中都存在的数据
两种写法:
select 字段 from 表1,表2;
select 字段 from 表1 join 表2 on 条件;
举个例子:
学生表:
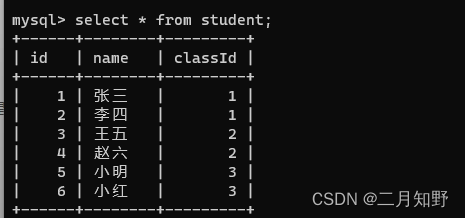
班级表:
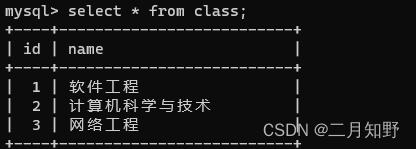
要求查询"王五"的班级的名字.
这就涉及到了两张表,就需要使用联合(多表)查询.
1.首先进行笛卡尔积
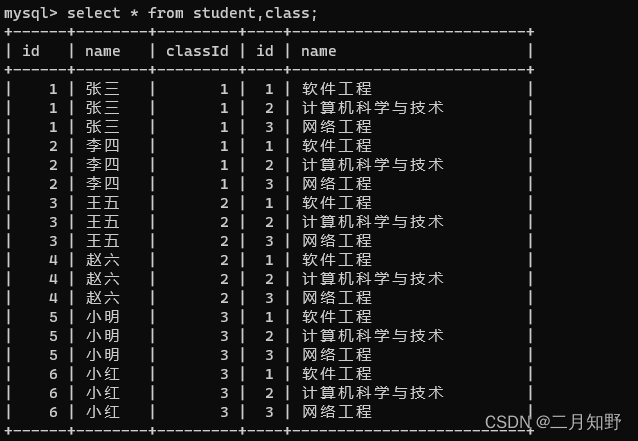
其实就是学生表和班级表进行排列组合,里面有很多无效的数据.
2. 添加连接条件

注意这里的条件写法,应该是表名.字段名,因为涉及到多个表,多个表中的字段名可能相同,因此需要使用 表名.字段 表明是哪个表中的字段.当然如果这个列名是唯一的,也可以不加 表名.

刚才的结果还是太多了,我们也可以加上指定列进行查询,同样需要使用表名.字段的形式进行查询
使用join on也可以实现相同的效果,同样是刚才的例子
使用join on的方式来完成
1.首先进行笛卡尔积
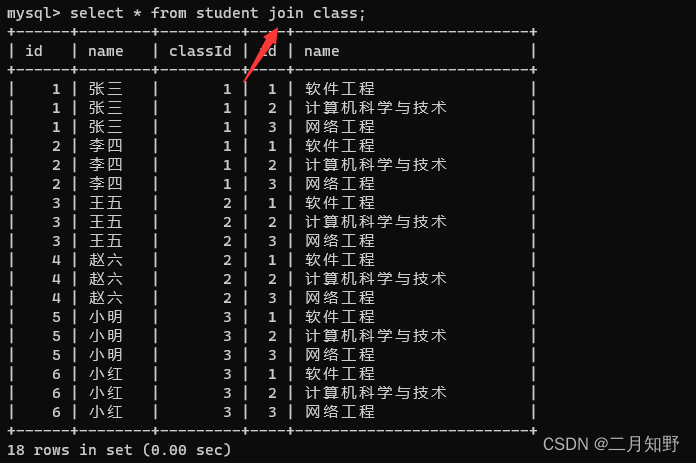
2. 添加条件

直接写join或者inner join就是内连接
join on不仅可以实现内连接,还可以实现外连接
5.2 外连接
外连接分为左外连接(left join)和右外连接(right join)
还是刚才的学生表:

但班级表中多有两条数据
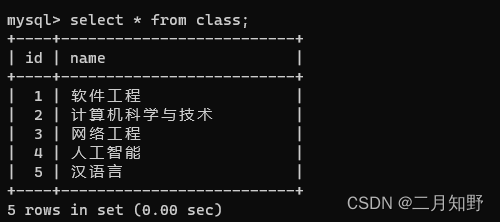
进行笛卡尔积后得到的结果
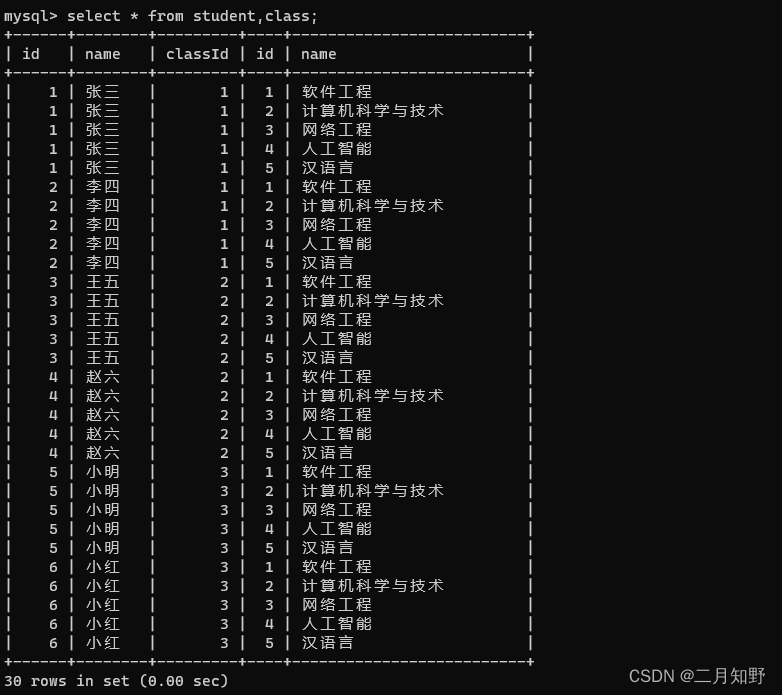
这是内连接得到的结果:
这个是进行右连接得到的结果
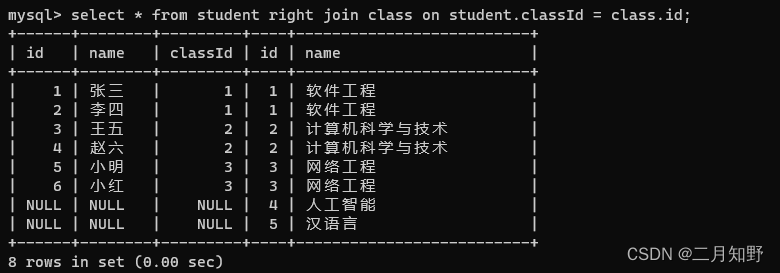
右连接会把右侧表中的数据都获取到,即使左边的值是NULL,也会显示出来
左连接也是类似,会把左侧表中的数据都获取到,即使右边的值是NULL,也会显示出来.
如果两张表中的数据,在对方表中都有,那么此时内外连接是没有区别的,如果两张表中的数据只有一部分在对方的表中,内连接就是获取两张表的"交集",如果是外连接,那么获取到的值就是一侧表的全部记录.
还有一种连接是"全外连接",但是在MySQL中并不支持
5.3 自连接
自连接就是和自己进行笛卡尔积
在条件查询中,只是"列"和"列"之间的比较,但是有的地方需要用的 "行"和"行"之间的比较,就需要使用自连接,将"行"转为"列"再进行比较
例如这里有一张成绩表
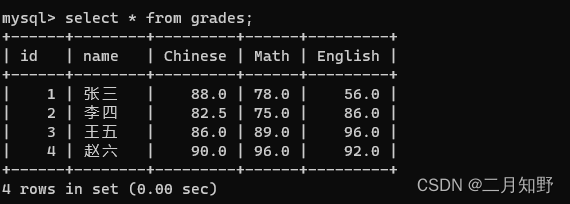
如果要查询数学成绩比语文成绩高的同学的名字,就需要使用自连接.因为如果进行比较,那么就是"行"和"行"进行的比较

可以看到,如果是直接进行连接,那么是会报错的.
Not unique table/alias: 'grades': 这句话告诉我们不是唯一的表,但是可以起别名
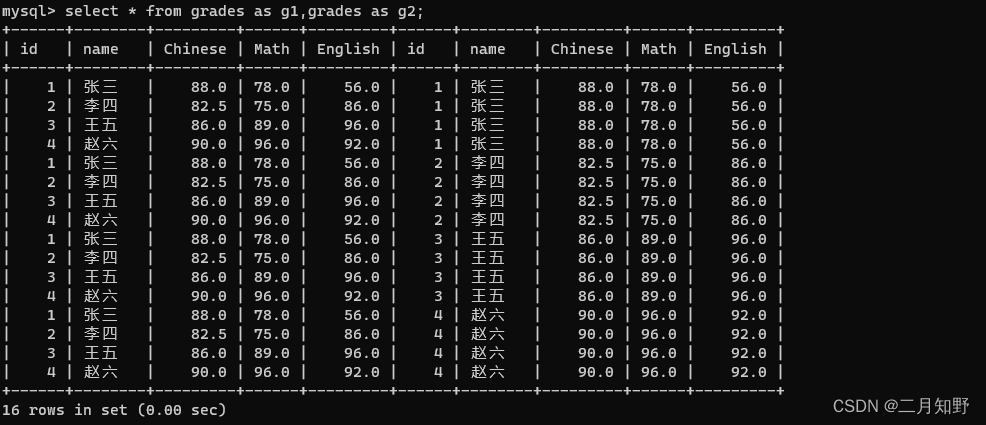
通过起别名的方式,成功进行自连接
加上连接条件,先筛选出一部分记录,此时我们可以看到语文成绩和数学成绩就在两列了
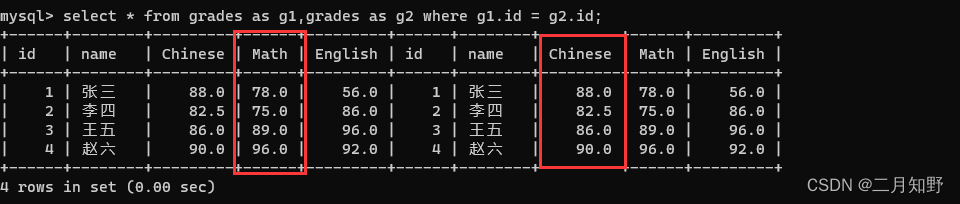
将条件补全,就可以得到我们想要的结果了

5.4 子查询
子查询本质就是将多个查询语组合成一个SQL语句,例如在查询得到的临时表上再次进行查询
例如:在班级表中,找到与"张三"班级相同的同学
查到"张三"的班级id这个想必大家都会

我们要将得到的这个结果继续参与查询:

此时就得到"李四"同学的这条记录了,因为这里的班级id就只有一个,所以后面使用的是 = ,但是如果这个的临时表数据有多条,就可以使用 in 来完成
5.5 合并查询
合并查询是把两个查询的结果集合合并到一起,使用的是union 和union all 这两个关键字
- union: 如果有重复的数据,就会去重
- union all: 如果有重复的数据,则不会去重
还是刚才的分数表
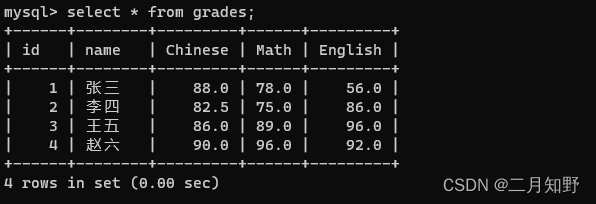
如果我们要查询数学成绩>90和英语成绩<60的人的姓名,就可以使用合并查询
6. 总结
在SQL语句中,查询数据的操作与其它操作语句相比还是有一些难度的,主要涉及到一些多表查询等操作.对于里面涉及到的一些关键字,连接类型要熟练掌握
感谢你的观看!希望这篇文章能帮到你!
专栏:《速通MySQL》在不断更新中,欢迎订阅!
“愿与君共勉,携手共进!”