目录
获取验证码图片
用opencv-python处理图片
制作训练数据集
训练模型
识别验证码
编写古诗文网的登录爬虫代码
总结与提高
源码下载
在本节我们将使用sklearn和opencv-python这两个库过掉古诗文网的4位数字+字母混合验证码,验证码风格如下所示。
![]()
验证码获取链接:https://so.gushiwen.cn/RandCode.ashx
获取验证码图片
为顺利识别古诗文网的验证码,我们就需要大量验证码图片用作训练数据。关于获取该训练数据的方式,笔者想到三种:
- 人工手动下载保存验证码图片并命名文件。
- 编写程序自动下载保存验证码图片,通过免费但限额的百度识别API去识别验证码,然后根据识别结果给文件命名。
- 用程序批量生成类似目标验证码风格的图片。
第一种方式很累,不推荐。第二种方式的话还是要人工检查识别结果。第三种的话比较推荐,主要因为古诗文网的验证码风格还是比较好模仿的。如果目标验证码风格奇奇怪怪,比较难模仿的话,还是建议第一种或第二种。
以下是生成验证码图片的完整程序代码。
# captcha.py
from PIL import Image, ImageDraw, ImageFont
import concurrent.futures
from pathlib import Path
import random
import shutil
IMG_WIDTH = 55 # 图片宽度
IMG_HEIGHT = 22 # 图片高度
FONT_SIZE = 13 # 字体大小
def get_random_point():
"""获取随机点坐标"""
x = random.randint(0, IMG_WIDTH)
y = random.randint(0, IMG_HEIGHT)
return x, y
def draw_lines(img, pen):
"""绘制线条"""
# 线条宽度和颜色
line_width = 1
color = (191, 191, 191)
# 边框线条
top_left = (0, 0)
top_right = (IMG_WIDTH-1, 0)
bottom_left = (0, IMG_HEIGHT-1)
bottom_right = (IMG_WIDTH-1, IMG_HEIGHT-1)
pen.line((top_left, top_right), fill=color, width=line_width)
pen.line((top_right, bottom_right), fill=color, width=line_width)
pen.line((bottom_right, bottom_left), fill=color, width=line_width)
pen.line((bottom_left, top_left), fill=color, width=line_width)
# 内部随机线条
for i in range(20):
x1, y1 = get_random_point()
x2, y2 = get_random_point()
pen.line(((x1, y1), (x2, y2)), fill=color, width=line_width)
return img
def draw_texts(img, pen):
"""绘制文本"""
total = 4 # 要绘制的字符总数
char_list = [] # 字符列表
seed = "0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZ" # 字符池
color_list = [(0, 0, 204), (51, 0, 153), # 每个文本的颜色
(51, 0, 102), (102, 0, 51)]
x_gap = IMG_WIDTH / (total+0.5)
y_gap = (IMG_HEIGHT - FONT_SIZE) / 2
for i in range(total):
char = random.choice(seed)
char_list.append(char)
# W字符宽度较大,在绘制W时,将其往左挪动一些
# 这样就不会与后面的字符贴在一起,方便分割
if char == "W":
x = x_gap * (i+0.5) - 2
else:
x = x_gap * (i + 0.5)
y = y_gap
color = color_list[i]
font = ImageFont.truetype("./font.ttc", size=FONT_SIZE)
pen.text((x, y), char, color, font)
return img, "".join(char_list)
def generate_captcha(num, output_dir, thread_name=0):
"""
生成一定数量的验证码图片
:param num: 生成数量
:param output_dir: 存放验证码图片的文件夹路径
:param thread_name: 线程名称
:return: None
"""
# 目录存在则删除
if Path(output_dir).exists():
shutil.rmtree(output_dir)
# 创建目录
Path(output_dir).mkdir()
for i in range(num):
img = Image.new("RGB", size=(IMG_WIDTH, IMG_HEIGHT), color="white")
pen = ImageDraw.Draw(img, mode="RGB")
img = draw_lines(img, pen)
img, text = draw_texts(img, pen)
save_path = f"{output_dir}/{i+1}-{text}.png"
img.save(save_path, format="png")
print(f"Thread {thread_name}: 已生成{i+1}张验证码")
print(f"Thread {thread_name}: 验证码图片生成完毕")
def main():
with concurrent.futures.ThreadPoolExecutor(max_workers=10) as executor:
for i in range(3):
executor.submit(generate_captcha, 10000, f"./captcha{i}", i)
if __name__ == "__main__":
main()该程序使用Pillow库生成随机4位纯数字/纯字母/数字和字母混合的验证码图片,像素大小为55px*22px,图片上还设置了干扰线条。在main()函数中,我们开启了3个子线程,每一个子线程负责生成10000张验证码并保存在各自的文件夹中。该程序生成的验证码图片如下所示。

注:笔者找的字体跟目标验证码上的字体很像,但有些字符还是明显有区别的(比如字符1)。读者找到更像的字体的话,那对提高识别精读会有很大的帮助。
用opencv-python处理图片
将验证码图片交给模型识别前的一个重要操作就是图像处理。为了提高识别精读,我们应该将验证码上的图片的线条尽可能去除。还好古诗文网验证码上的线条干扰相当于摆设,因为线条都比较细而且颜色都比较浅,最重要的是字符是覆盖在线条上的。
![]()
因此。我们用opencv-python很容易就能够去除线条干扰。下方的adjust_img()函数会返回一个二值化后的验证码图片。
# process.py
def adjust_img(img):
"""调整图像"""
# 图片灰度化
img_gray = cv.cvtColor(img, cv.COLOR_BGR2GRAY)
# 高斯模糊
img_gaussian = cv.GaussianBlur(img_gray, (1, 1), 0)
# 二值化
ret, img_threshold = cv.threshold(img_gaussian, 0, 255,
cv.THRESH_BINARY_INV + cv.THRESH_OTSU)
# 腐蚀处理
kernel = np.ones((1, 1), np.float32)
img_erode = cv.erode(img_threshold, kernel)
return img_erode高斯模糊和腐蚀处理可以有效去除图像中的线条干扰,处理后的效果显示如下。
![]()
我们要用sklearn识别单个字符(这样识别难度会小一些),而验证码上是4个字符,所以我们应该将验证码图片进行切割,切割后的每张图片只包含一个字符。下方的split_img()函数实现了这个功能。
# process.py
def split_img(img):
"""分割图像"""
roi_list = []
bg_width, bg_height = 20, 20
cnts, hiers = cv.findContours(img, cv.RETR_EXTERNAL, cv.CHAIN_APPROX_SIMPLE)
for cnt in sorted(cnts, key=lambda x: cv.boundingRect(x)[0]):
x, y, w, h = cv.boundingRect(cnt)
if w > bg_width or h > bg_height:
continue
roi = img[y:y+h, x:x+w]
roi[roi == 255] = 1
bg = np.zeros((bg_width, bg_height))
start_x = (bg_width - w) // 2
start_y = (bg_height - h) // 2
bg[start_y:start_y+h, start_x:start_x+w] = roi
roi_list.append(bg)
if len(roi_list) == 4:
return True, roi_list
else:
return False, None古诗文网的验证码字符位置会有变化,有时候字符整体偏左,有时候整体偏右,所以不应该通过图片均分切割去获取单个字符,而是应该用opencv-python的findContours()方法去寻找各个的字符轮廓并截取。截取出来的字符图像被放进了20*20像素的黑色背景中,确保所有字符图像的大小一致。
如果验证码上某几个字符靠的比较近,那就会导致findContours()返回的某个轮廓中包含多个字符,轮廓宽度也就大于黑色背景宽度20,这种验证码就只能先舍弃掉。如果roi_list的最终长度为4,那就表示我们成功获取到了各个字符图像。
通过adjust_img()函数我们得到的是二值化图像,图像各像素的值只会是0或255,不过笔者通过以下代码将图像中值为255的像素全部设置成了1,因为这样更有利于机器学习。
roi[roi == 255] = 1切割结果如下所示:
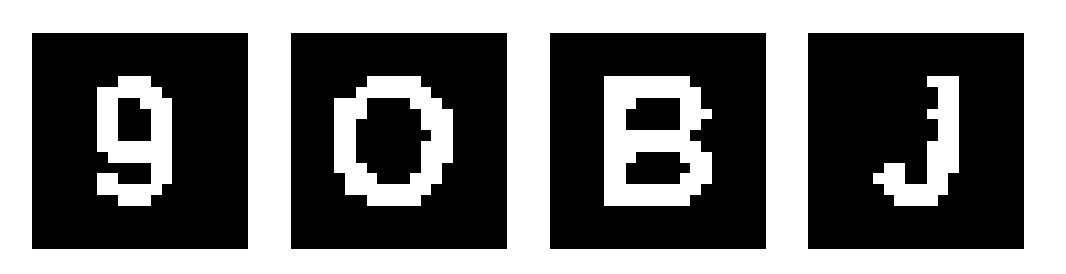
我们要知道的一点是,在图像处理这一步骤中,有少部分验证码图片肯定会不合格,不能拿来放进机器学习数据集中,也无法被正常识别。图像处理的好坏跟识别准确度高低有很大关系。图像处理的完整代码如下所示。
# process.py
import cv2 as cv
import numpy as np
import matplotlib.pyplot as plt
def adjust_img(img):
"""调整图像"""
# 图片灰度化
img_gray = cv.cvtColor(img, cv.COLOR_BGR2GRAY)
# 高斯模糊
img_gaussian = cv.GaussianBlur(img_gray, (1, 1), 0)
# 二值化
ret, img_threshold = cv.threshold(img_gaussian, 0, 255,
cv.THRESH_BINARY_INV + cv.THRESH_OTSU)
# 腐蚀处理
kernel = np.ones((1, 1), np.float32)
img_erode = cv.erode(img_threshold, kernel)
return img_erode
def split_img(img):
"""分割图像"""
roi_list = []
bg_width, bg_height = 20, 20
cnts, hiers = cv.findContours(img, cv.RETR_EXTERNAL, cv.CHAIN_APPROX_SIMPLE)
for cnt in sorted(cnts, key=lambda x: cv.boundingRect(x)[0]):
x, y, w, h = cv.boundingRect(cnt)
if w > bg_width or h > bg_height:
continue
roi = img[y:y+h, x:x+w]
roi[roi == 255] = 1
bg = np.zeros((bg_width, bg_height))
start_x = (bg_width - w) // 2
start_y = (bg_height - h) // 2
bg[start_y:start_y+h, start_x:start_x+w] = roi
roi_list.append(bg)
if len(roi_list) == 4:
return True, roi_list
else:
return False, None
def main():
img = cv.imread("captcha_verify/2-9OBJ.png")
img = adjust_img(img)
is_ok, roi_list = split_img(img)
if not is_ok:
return
for i, roi in enumerate(roi_list):
plt.subplot(1, 4, i+1)
plt.axis("off")
plt.imshow(roi, cmap="gray")
plt.show()
if __name__ == "__main__":
main()制作训练数据集
验证码图片有了,图像处理也好了,接下来就是把所有单个数字图像保存为训练数据集,完整代码如下所示。
# data.py
import os
import cv2 as cv
import numpy as np
from pathlib import Path
import concurrent.futures
from process import adjust_img, split_img
def make_data(captcha_dir, thread_name=0):
"""制作训练数据集"""
data = [] # 特征数据
target = [] # 数据标签
seed = "0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZ" # 字符池
for i, filename in enumerate(os.listdir(captcha_dir)):
print(f"Thread {thread_name}: 正在处理第{i+1}张图片")
file_path = f"{captcha_dir}/{filename}"
img = cv.imread(file_path)
img = adjust_img(img)
is_ok, roi_list = split_img(img)
if not is_ok:
continue
# 从图片名称中获取真实验证码
captcha = filename.split("-")[-1].replace(".png", "")
for i, roi in enumerate(roi_list):
data.append(roi.ravel())
target.append(seed.index(captcha[i]))
data = np.array(data)
target = np.array(target)
Path("./data").mkdir(exist_ok=True)
Path("./target").mkdir(exist_ok=True)
np.save(f"./data/data{thread_name}.npy", data)
np.save(f"./target/target{thread_name}.npy", target)
print(f"Thread {thread_name}: 已保存数据和标签")
def main():
with concurrent.futures.ThreadPoolExecutor(max_workers=10) as executor:
for i in range(3):
executor.submit(make_data, f"./captcha{i}", i)
if __name__ == "__main__":
main()该程序开启了3个子线程,每个线程负责一个验证码文件夹中的所有图片。最终结果是将所有单个图片数据以及对应的标签保存在npy格式的文件中。
注:要记得将标签从字符串类型转换成数值类型,笔者这里用字符在seed变量中的索引来表示对应的标签字符。
训练模型
有了数据之后就可以开始训练了。首先,我们应该把各个npy数据加载进来,并正进行整合,请看以下代码。
# train.py
def load_data():
"""加载各个npy数据,返回整合后的数据"""
data_list = []
target_list = []
for i in range(3):
data_list.append(np.load(f"./data/data{i}.npy"))
for i in range(3):
target_list.append(np.load(f"./target/target{i}.npy"))
X = np.vstack(data_list)
y = np.hstack(target_list)
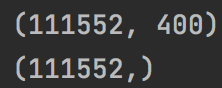
print(X.shape)
print(y.shape)
return X, y如果在图像处理部分完全没问题的话,那结果总数应该是4*30000 = 120000条数据。从打印结果看,数据数量还是可以的。
通过以下代码可以得知各个字符的数量。
from collections import Counter
Counter(sorted(y))Counter({0: 3044,
1: 3204,
2: 3183,
3: 3220,
4: 3077,
5: 3111,
6: 3210,
7: 3074,
8: 3148,
9: 3134,
10: 3191,
11: 3275,
12: 3105,
13: 3268,
14: 3310,
15: 3246,
16: 3178,
17: 3151,
18: 3262,
19: 3141,
20: 3020,
21: 3240,
22: 2045,
23: 3130,
24: 3036,
25: 3270,
26: 3124,
27: 3307,
28: 3205,
29: 3012,
30: 3098,
31: 3141,
32: 2222,
33: 3148,
34: 2985,
35: 3037})注:对于这种验证码,数据量其实有点多了。因为我们可以发现古诗文网验证码上的各个字符在大小和倾斜度上都没有发生改变,切割出来后可能也不会有多大变化,也就是说我们训练集中的各个字符对应的多张图像很可能是一样的,这对机器学习来说不是好事,很容易导致过拟合。
接下来,选择最合适的模型,不断调参(这里其实会花费很多时间)。出于演示目的,笔者这里就选择KNN了,请看以下代码。
# train.py
def get_best_estimator(X, y):
"""调整参数,获取最佳的KNN模型"""
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0)
param_grid = {
"n_neighbors": [i for i in range(5, 13, 2)]
}
grid_search = GridSearchCV(KNeighborsClassifier(), param_grid, cv=5)
grid_search.fit(X_train, y_train)
print(grid_search.score(X_test, y_test))
pred = grid_search.predict(X_test)
print(classification_report(y_test, pred))
return grid_search.best_estimator_在get_best_estimator()函数中,我们用GridSearchCV进行参数选择与模型评估,评分和报告如下所示。
1.0
precision recall f1-score support
0 1.00 1.00 1.00 547
1 1.00 1.00 1.00 633
2 1.00 1.00 1.00 669
3 1.00 1.00 1.00 650
4 1.00 1.00 1.00 619
5 1.00 1.00 1.00 618
6 1.00 1.00 1.00 618
7 1.00 1.00 1.00 644
8 1.00 1.00 1.00 651
9 1.00 1.00 1.00 623
10 1.00 1.00 1.00 600
11 1.00 1.00 1.00 663
12 1.00 1.00 1.00 611
13 1.00 1.00 1.00 709
14 1.00 1.00 1.00 661
15 1.00 1.00 1.00 657
16 1.00 1.00 1.00 621
17 1.00 1.00 1.00 626
18 1.00 1.00 1.00 693
19 1.00 1.00 1.00 650
20 1.00 1.00 1.00 575
21 1.00 1.00 1.00 673
22 1.00 1.00 1.00 421
23 1.00 1.00 1.00 658
24 1.00 1.00 1.00 608
25 1.00 1.00 1.00 626
26 1.00 1.00 1.00 605
27 1.00 1.00 1.00 672
28 1.00 1.00 1.00 607
29 1.00 1.00 1.00 610
30 1.00 1.00 1.00 610
31 1.00 1.00 1.00 636
32 1.00 1.00 1.00 456
33 1.00 1.00 1.00 614
34 1.00 1.00 1.00 570
35 1.00 1.00 1.00 607
accuracy 1.00 22311
macro avg 1.00 1.00 1.00 22311
weighted avg 1.00 1.00 1.00 22311验证了我们之前的猜想,彻彻底底的过拟合了。不慌,先拿这个模型实战验证下。
模型训练好了之后,我们就可以将它进行保存,请看以下代码。
# train.py
def save_model(best_estimator):
"""保存模型"""
with open("./model.pkl", "wb") as f:
pickle.dump(best_estimator, f)训练部分的完整代码所示如下:
# train.py
from sklearn.model_selection import train_test_split, GridSearchCV
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import classification_report
import numpy as np
import pickle
def load_data():
"""加载各个npy数据,返回整合后的数据"""
data_list = []
target_list = []
for i in range(3):
data_list.append(np.load(f"./data/data{i}.npy"))
for i in range(3):
target_list.append(np.load(f"./target/target{i}.npy"))
X = np.vstack(data_list)
y = np.hstack(target_list)
print(X.shape)
print(y.shape)
return X, y
def get_best_estimator(X, y):
"""调整参数,获取最佳的KNN模型"""
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0)
param_grid = {
"n_neighbors": [i for i in range(5, 13, 2)]
}
grid_search = GridSearchCV(KNeighborsClassifier(), param_grid, cv=5)
grid_search.fit(X_train, y_train)
print(grid_search.score(X_test, y_test))
pred = grid_search.predict(X_test)
print(classification_report(y_test, pred))
return grid_search.best_estimator_
def save_model(best_estimator):
"""保存模型"""
with open("./model.pkl", "wb") as f:
pickle.dump(best_estimator, f)
def main():
X, y = load_data()
best_estimator = get_best_estimator(X, y)
save_model(best_estimator)
if __name__ == "__main__":
main()识别验证码
笔者手动下载保存了50张古诗文网上的验证码,放在了captcha_verify文件夹中。这些验证码将拿来测试模型的准确度。
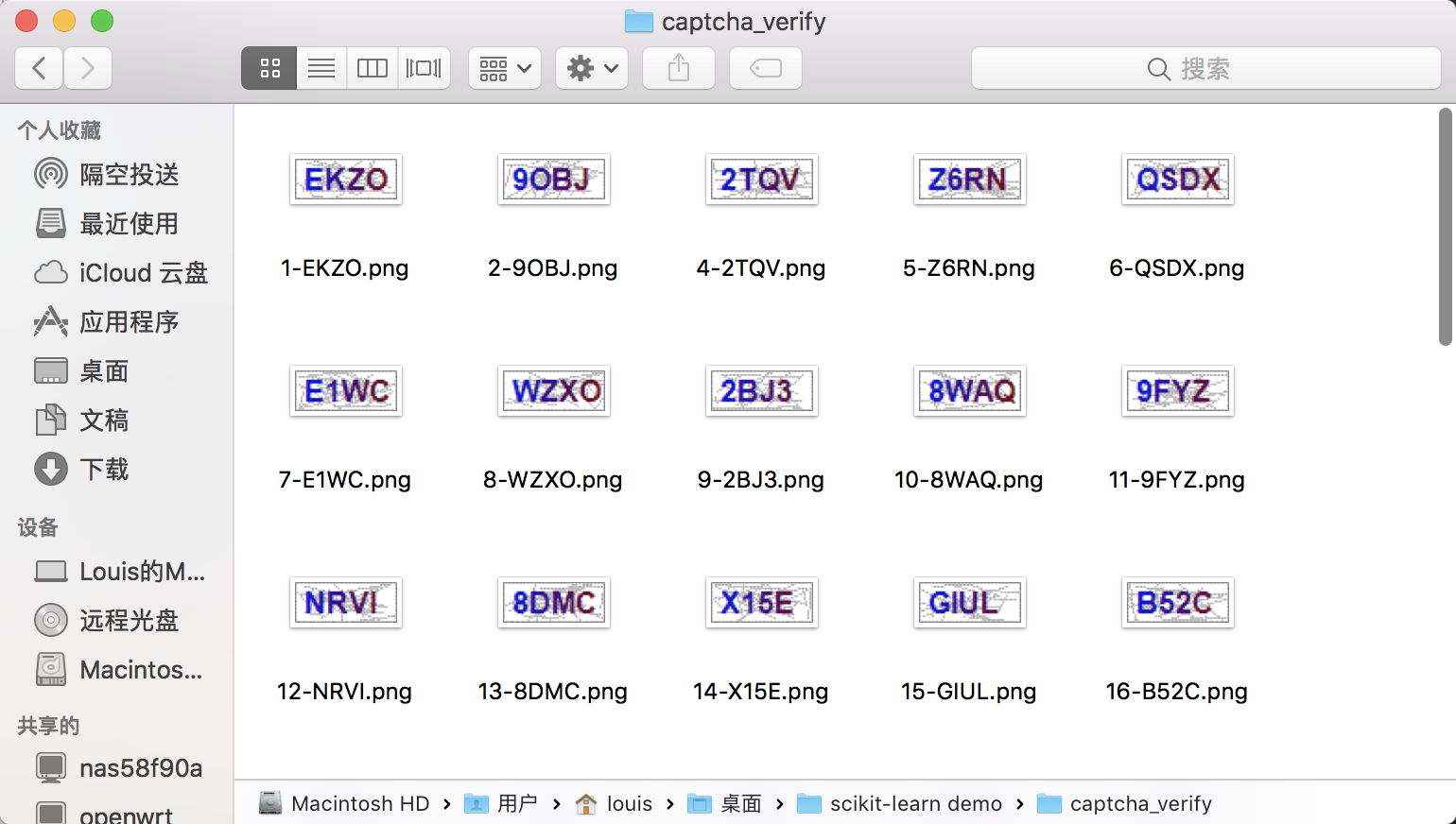
首先加载训练好的模型。
def load_model(mode_path):
"""加载模型"""
with open(mode_path, "rb") as f:
model = pickle.load(f)
return model然后是编写预测代码。
# predict.py
def predict(model, img_path):
seed = "0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZ" # 字符池
img = cv.imread(img_path)
img = adjust_img(img)
# 预测结果和真实结果
predict_result = ""
real_result = img_path.split("-")[-1].replace(".png", "")
# 如果图像处理成功,则返回单个数字图像的预测结果和真实结果
# 如果没成功,则返回0000和真实结果
is_ok, roi_list = split_img(img)
if is_ok:
for i, roi in enumerate(roi_list):
predict_result += seed[(model.predict(roi.reshape(1, -1))[0])]
print(f"{img_path}的识别结果为{predict_result}")
return predict_result, real_result
else:
print(f"{img_path}图片处理失败")
return "0000", real_result在predict()函数中,我们首先读取了图片并对图像进行处理和分割,然后调用model.predict()方法进行预测。model.predict()方法返回的是一个索引值,需要对应seed变量获取对应字符。
预测结果要和真实结果比对后就可以得到准确度了,请看以下代码。
# predict.py
def get_accuracy(model):
"""获取验证准确度"""
all_predict_result = []
all_real_result = []
for filename in sorted(os.listdir("./captcha_verify")):
if filename != ".DS_Store": # Mac电脑上的一种文件,排除掉
predict_result, real_result = predict(model, f"./captcha_verify/{filename}")
all_predict_result.append(predict_result)
all_real_result.append(real_result)
accuracy = (np.array(all_predict_result) == np.array(all_real_result)).sum() / len(all_predict_result)
return accuracy经笔者测试,accuracy的值在0.72左右,其中有几张是因为图像处理失败而预测错的,如果不把这几张计入识别精读统计的话,那accuracy的值就是正确识别数量/(图片总数-图像处理失败数量),也就是36 / (50-6) = 0.82。所以这个模型还不错的,可以用于实战。
./captcha_verify/1-EKZO.png的识别结果为EKZO
./captcha_verify/10-8WAQ.png的识别结果为8WAQ
./captcha_verify/11-9FYZ.png的识别结果为9FYZ
./captcha_verify/12-NRVI.png的识别结果为NRVI
./captcha_verify/13-8DMC.png的识别结果为8DMC
./captcha_verify/14-X15E.png的识别结果为X15E
./captcha_verify/15-GIUL.png的识别结果为GIUL
./captcha_verify/16-B52C.png的识别结果为B52C
./captcha_verify/17-XK4G.png的识别结果为XK4G
./captcha_verify/18-2O2O.png的识别结果为2O2O
./captcha_verify/19-E3CP.png的识别结果为E3CR
./captcha_verify/2-9OBJ.png的识别结果为9OBJ
./captcha_verify/20-8HW8.png的识别结果为8HW8
./captcha_verify/21-B6UT.png的识别结果为B6UT
./captcha_verify/22-TI21.png的识别结果为TI21
./captcha_verify/23-RXBA.png的识别结果为RXBA
./captcha_verify/24-MAY1.png图片处理失败
./captcha_verify/25-JC5E.png的识别结果为JC5E
./captcha_verify/26-VBXR.png的识别结果为VBXR
./captcha_verify/27-X85J.png图片处理失败
./captcha_verify/28-JRVX.png的识别结果为JRVX
./captcha_verify/29-VEE6.png的识别结果为VEE6
./captcha_verify/3-I7RE.png的识别结果为I7RE
./captcha_verify/30-7J38.png的识别结果为7J38
./captcha_verify/31-MWFH.png图片处理失败
./captcha_verify/32-DR3P.png的识别结果为DR3R
./captcha_verify/33-WOPB.png的识别结果为WORB
./captcha_verify/34-N3G4.png的识别结果为N3G4
./captcha_verify/35-7FH2.png的识别结果为7FH2
./captcha_verify/36-BZBO.png的识别结果为BZBO
./captcha_verify/37-KDEZ.png的识别结果为KDEZ
./captcha_verify/38-K91X.png的识别结果为K91X
./captcha_verify/39-ZFIP.png的识别结果为ZFIR
./captcha_verify/4-2TQV.png的识别结果为2TQV
./captcha_verify/40-X1ME.png的识别结果为X1ME
./captcha_verify/41-WZY8.png图片处理失败
./captcha_verify/42-VHDN.png的识别结果为VHDN
./captcha_verify/43-5PX9.png的识别结果为5RX9
./captcha_verify/44-RVWH.png的识别结果为RVWH
./captcha_verify/45-ZXQN.png图片处理失败
./captcha_verify/46-NRSD.png的识别结果为NR8D
./captcha_verify/47-P0WW.png图片处理失败
./captcha_verify/48-H7WJ.png的识别结果为H7WJ
./captcha_verify/49-98KS.png的识别结果为98K8
./captcha_verify/5-Z6RN.png的识别结果为Z6RN
./captcha_verify/50-QKR0.png的识别结果为QKR0
./captcha_verify/6-QSDX.png的识别结果为Q8DX
./captcha_verify/7-E1WC.png的识别结果为E1WC
./captcha_verify/8-WZXO.png的识别结果为WZXO
./captcha_verify/9-2BJ3.png的识别结果为2BJ3
0.72完整代码如下所示:
# predict.py
import os
import pickle
import cv2 as cv
import numpy as np
from process import adjust_img, split_img
def load_model(mode_path):
"""加载模型"""
with open(mode_path, "rb") as f:
model = pickle.load(f)
return model
def predict(model, img_path):
seed = "0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZ" # 字符池
img = cv.imread(img_path)
img = adjust_img(img)
# 预测结果和真实结果
predict_result = ""
real_result = img_path.split("-")[-1].replace(".png", "")
# 如果图像处理成功,则返回单个数字图像的预测结果和真实结果
# 如果没成功,则返回0000和真实结果
is_ok, roi_list = split_img(img)
if is_ok:
for i, roi in enumerate(roi_list):
predict_result += seed[(model.predict(roi.reshape(1, -1))[0])]
print(f"{img_path}的识别结果为{predict_result}")
return predict_result, real_result
else:
print(f"{img_path}图片处理失败")
return "0000", real_result
def get_accuracy(model):
"""获取验证准确度"""
all_predict_result = []
all_real_result = []
for filename in sorted(os.listdir("./captcha_verify")):
if filename != ".DS_Store": # Mac电脑上的一种文件,排除掉
predict_result, real_result = predict(model, f"./captcha_verify/{filename}")
all_predict_result.append(predict_result)
all_real_result.append(real_result)
accuracy = (np.array(all_predict_result) == np.array(all_real_result)).sum() / len(all_predict_result)
return accuracy
def main():
model = load_model("./model.pkl")
accuracy = get_accuracy(model)
print(accuracy)
if __name__ == "__main__":
main()编写古诗文网的登录爬虫代码
# login.py
from predict import load_model, predict
from parsel import Selector
from io import BytesIO
from PIL import Image
import requests
# 加载模型
model = load_model("./model.pkl")
# 账号密码
username = "你的账号"
password = "你的密码"
headers = {
"user-agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/105.0.0.0 Safari/537.36"
}
url = "https://so.gushiwen.cn/user/login.aspx?from=http://so.gushiwen.cn/user/collect.aspx"
s = requests.session()
r = s.get(url, headers=headers)
r.encoding = "utf-8"
# 首先获取__VIEWSTATE和__VIEWSTATEGENERATOR的值
sel = Selector(r.text)
viewstate = sel.xpath("//input[@id='__VIEWSTATE']/@value").extract_first()
viewstate_generator = sel.xpath("//input[@id='__VIEWSTATEGENERATOR']/@value").extract_first()
# 接着获取验证码图片并保存到本地
img_src = "https://so.gushiwen.org" + sel.xpath("//img[@id='imgCode']/@src").extract_first()
img_data = s.get(img_src, headers=headers).content
img = Image.open(BytesIO(img_data))
img.save("code.png")
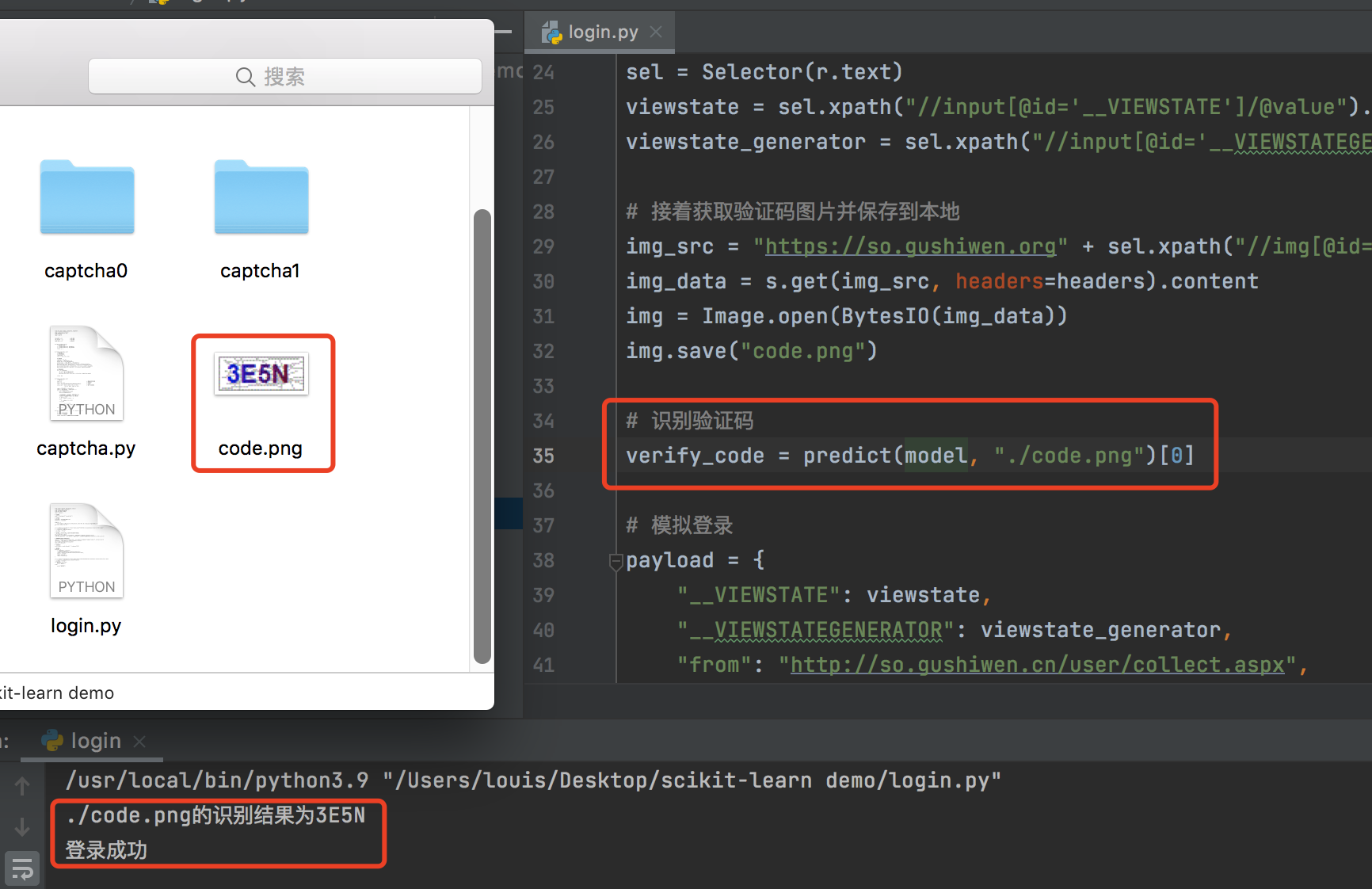
# 识别验证码
verify_code = predict(model, "./code.png")[0]
# 模拟登录
payload = {
"__VIEWSTATE": viewstate,
"__VIEWSTATEGENERATOR": viewstate_generator,
"from": "http://so.gushiwen.cn/user/collect.aspx",
"email": username,
"pwd": password,
"code": verify_code
}
url = "https://so.gushiwen.cn/user/login.aspx?from=http%3a%2f%2fso.gushiwen.cn%2fuser%2fcollect.aspx"
r = s.post(url, data=payload, headers=headers)
r.encoding = "utf-8"
if "删除账号" in r.text:
print("登录成功")
else:
print("登录失败")爬虫代码比较简单,不再赘述,运行结果如下所示。
总结与提高
为了能够训练一个识别古诗文网验证码的模型,我们用程序批量生成了和目标验证码的风格类似的图片用作训练集。然而,个别字符的字体样式还是有所区别,这就会影响最后的识别精读。如果能找到一个更相似的字体,那就最好不过了。
我们生成了30000张验证码图片,但是验证码上的字符在大小、倾斜度和线条干扰度上都没有多大改变,所以在训练集中,某些字符的多条数据其实是非常类似的,这不利于机器学习,很容易导致过拟合。训练集数量可以减少,也要在模型上加强正则化来防止过拟合。
在本节,笔者只选择了KNN模型,不过最终的识别准确度还是可以的。如果要提高识别精读,可以选用更强大的模型,或者在图像处理这一环节多下点功夫,尽量能够获取到好的分割图像。当然我们也可以修改下程序,把识别失败的图像挑出来,不计入识别精读统计结果。
KNeighborsClassifier模型在预测时比较慢,大家可改用逻辑回归LogisticRegression或者随机森林RandomForestClassifier,后两者的预测速度会快很多。不过要注意,随机森林更加容易过拟合。
源码下载
链接:https://pan.baidu.com/s/1b10xKsQAVWLNJXUYJN0YiA
密码:zoct