分库分表概念
一、什么是分库分表
分库分表是在海量数据下,由于单库、表数据量过大,导致数据库性能持续下降的问题,演变出的技术方案。
分库分表是由分库和分表这两个独立概念组成的,只不过通常分库与分表的操作会同时进行,以至于我们习惯性的将它们合在一起叫做分库分表。
通过一定的规则,将原本数据量大的数据库拆分成多个单独的数据库,将原本数据量大的表拆分成若干个数据表,使得单一的库、表性能达到最优的效果(响应速度快),以此提升整体数据库性能。
如下图:
二、为什么需要分库分表?
单机数据库的存储能力、连接数是有限的,它自身就很容易会成为系统的瓶颈。当单表数据量在百万以里时,我们还可以通过添加从库、优化索引或者查询慢查询的原因寻求相关优化手段来提升性能。
但是一旦数据量朝着千万体势增长,再怎么优化数据库,其实可能也不会有太大的改观,慢的根本原因是InnoDB存储引擎,聚簇索引结构的 B+tree 层级变高,磁盘IO变多查询性能变慢。
为了减少数据库的负担,提升数据库响应速度,缩短查询时间,这时候就需要进行分库分表。并且在阿里的开发手册中也建议,单表行数超过500万行或者单表容量超过2GB就推荐分库分表,不过预估三年内无法达到这个量级就无需创建时就考虑分库分表。而且即使数量级达到500万也要视具体实际情况决定。
三、分库分表的方式
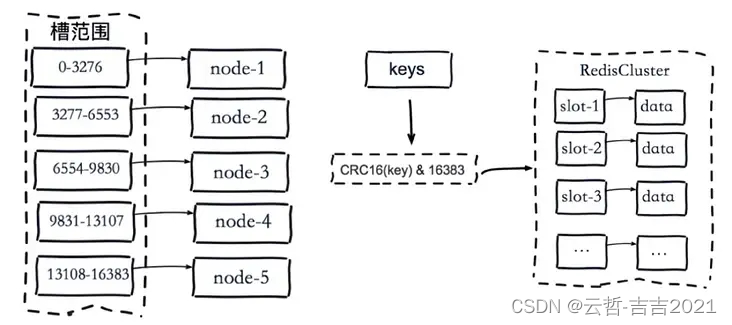
分库分表的核心就是对数据的分片(Sharding)并相对均匀的路由在不同的库、表中,以及分片后对数据的快速定位与检索结果的整合。
分库分表共分为四种方式:水平分库、水平分表、垂直分库、垂直分表,如下图:
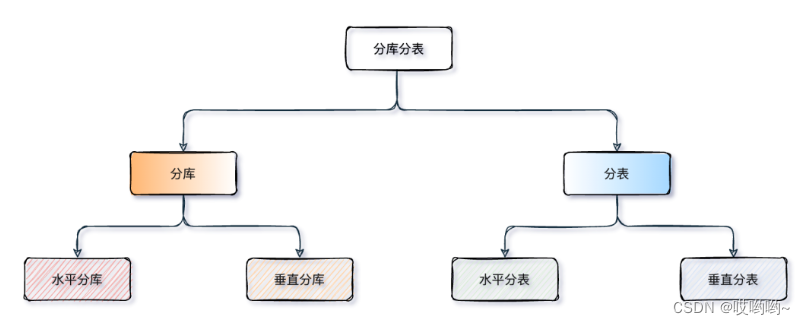
水平分库:水平分库是把同一个表拆分到不同的数据库中,每个库可以位于不同的服务器上。也就是不同的库中的表相同,通过相关规则定位到不同的库去操作。
水平分表:水平分表是在同一个数据库内,把一张表切分成多个结构完全相同表,而每个表只存原表的一部分数据。
垂直分库:以表为依据,按照业务归属不同,将不同的表拆分到不同的库中。
垂直分表:以字段为依据,按照字段的活跃性,将表中字段拆到不同的表(主表和扩展表)中。
四、分表策略
常见的分表策略: hash取模算法 、范围限定算法、范围+取模算法 、预定义算法
1、范围限定算法
以某些范围字段,如时间或ID区拆分。
优点: Range范围分表,有利于扩容。
缺点: 可能会有热点问题。比如双十一订单量激增,这些订单可能都汇聚到了一张表中,就容易单表压力过大。
2、hash取模
指定的路由key对分表总数进行取模,把数据分散到各个表中。
例如:Math.abs(orderId.hashCode()) % table_number
以t_order订单表为例,先给数据库从 0 到 N-1进行编号,对 t_order订单表中order_no订单编号字段进行取模hash(order_no) mod N,得到余数i。i=0存第一个库,i=1存第二个库,i=2存第三个库,以此类推。
优点:hash取模的方式,不会存在明显的热点问题。
缺点:取模算法对集群的伸缩支持不太友好,集群中有N个数据库实例hash(user_id) mod N,当某一台机器宕机,本应该落在该数据库的请求就无法得到处理,这时宕掉的实例会被踢出集群。
此时机器数减少算法发生变化hash(user_id) mod N-1,同一用户数据落在了在不同数据库中,等这台机器恢复,用user_id作为条件查询用户数据就会少一部分。
分表策略其实可以根据业务去灵活选择包括根据地理位置,提前设定好规则等等,只要能路由到想到的库表即可。
Sharding-JDBC实战
一、shardingjdbc中核心概念:
逻辑表:将一张表user水平拆分为两张表(user_1和user_2),此时user可以当做是逻辑表,总之,它是对真实存在的表的抽象。
真实表:user_1和user_2
分片键:可以理解为某一字段,应用需要操作某水平拆分后的多表时,shardingjdbc根据这个字段通过某种策略来计算数据应该落地到某张真实表,然后进行更新或者查询数据。
分片算法:以分片键为基础数据,实现某种算法,可以将数据落地到真实表,这种算法称之为分片算法
分片策略:分片键+分片算法=分片策略。shardingjdbc提供了inline,standard,complex,hint等默认分片策略,程序员可根据自己的需求实现自己的分片策略。
二、代码实战
导入依赖:
<!-- sharding-jdbc -->
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>sharding-jdbc-spring-boot-starter</artifactId>
<version>4.0.0-RC1</version>
</dependency>
<!--mysql-->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<scope>runtime</scope>
</dependency>
<!-- druid-->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid</artifactId>
<version>1.1.16</version>
</dependency>
1、水平分表
1.1、创建名为order1的数据库之后,新建两张结构相同的订单表
CREATE TABLE `order_1` (
`order_id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '主键ID',
`user_id` bigint(20) DEFAULT NULL COMMENT '用户ID',
`product_name` varchar(128) DEFAULT NULL COMMENT '商品名称',
`count` int(3) DEFAULT NULL COMMENT '订单数量',
PRIMARY KEY (`order_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='订单表';
CREATE TABLE `order_2` (
`order_id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT '主键ID',
`user_id` bigint(20) DEFAULT NULL COMMENT '用户ID',
`product_name` varchar(128) DEFAULT NULL COMMENT '商品名称',
`count` int(3) DEFAULT NULL COMMENT '订单数量',
PRIMARY KEY (`order_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COMMENT='订单表';
1.2、YML配置
这里的分表策略就是根据主键order_id,通过 order_id 的奇偶性,奇数入到order_1,偶数入到order_2。
spring:
main:
#设置为true时,后定义的bean会覆盖之前定义的相同名称的bean
allow-bean-definition-overriding: true
shardingsphere:
datasource:
# 配置数据源
names: ds1
# master-ds1数据库连接信息
ds1:
driver-class-name: com.mysql.cj.jdbc.Driver
maxPoolSize: 100
minPoolSize: 5
type: com.alibaba.druid.pool.DruidDataSource
url: jdbc:mysql://127.0.0.1:3306/order?useUnicode=true&useSSL=false&serverTimezone=Asia/Shanghai
username: root
password: 123456
# 显示sql
props:
sql:
show: true
sharding:
tables:
#指定表
order:
#数据节点
actual-data-nodes: ds1.order_$->{1..2}
#主键生成器
key-generator:
column: order_id #指定主键字段是哪一个
type: SNOWFLAKE #雪花算法,指定主键ID值的生成策略(即使数据库主键字段指定了自增,也会使用雪花算法生成的值)
# 分表策略
table-strategy:
inline:
#以order_id为分片键
sharding-column: order_id
#直接通过 order_id 的奇偶性,来判断到底是用哪个表
algorithm-expression: order_$->{order_id % 2 + 1}
1.3、实体类
package com.example.demo.shardingjdbc;
import com.baomidou.mybatisplus.annotation.TableField;
import com.baomidou.mybatisplus.annotation.TableId;
import com.baomidou.mybatisplus.annotation.TableName;
import lombok.Data;
/**
* @description: 订单表实体类
* @author: hbc
* @date: 2023-03-30 18:06
*/
@Data
@TableName(value = "order")
public class OrderInfo {
/**
* 主键id
*/
@TableId(value = "order_id")
private Long orderId;
@TableField(value = "user_id")
private Long userId;
@TableField(value = "product_name")
private String productName;
@TableField(value = "count")
private Integer count;
}
我这用的是mybatis-plus,大家自行实现连接数据库的sql即可。
1.4、插入测试,插入十条数据
@Test
public void test(){
for (int i = 0; i < 10; i++) {
int random = RandomUtils.nextInt();
OrderInfo orderInfo = new OrderInfo();
orderInfo.setOrderId((long) random);
orderInfo.setUserId((long) random);
orderInfo.setCount(10);
orderInfo.setProductName("空调 ="+random);
orderInfoMapper.insert(orderInfo);
}
}
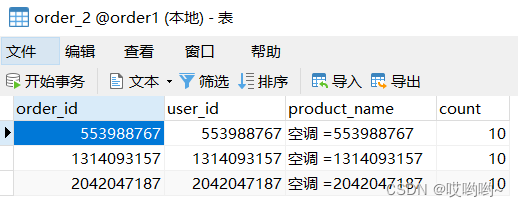
可以看到效果,十条数据根据order_id的奇偶性分配到了两个表中: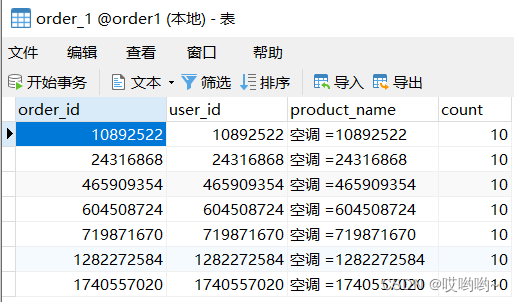
1.5、查询
@Test
public void test(){
ArrayList<Long> ids = new ArrayList<>();
ids.add(10892522L);
ids.add(553988767L);
List<OrderInfo> orderInfos = orderInfoMapper.selectBatchIds(ids);
System.err.println(orderInfos);
}
从两个表分别取出一个order_id,可以看到,分别从两个表中查询到了对应的数据
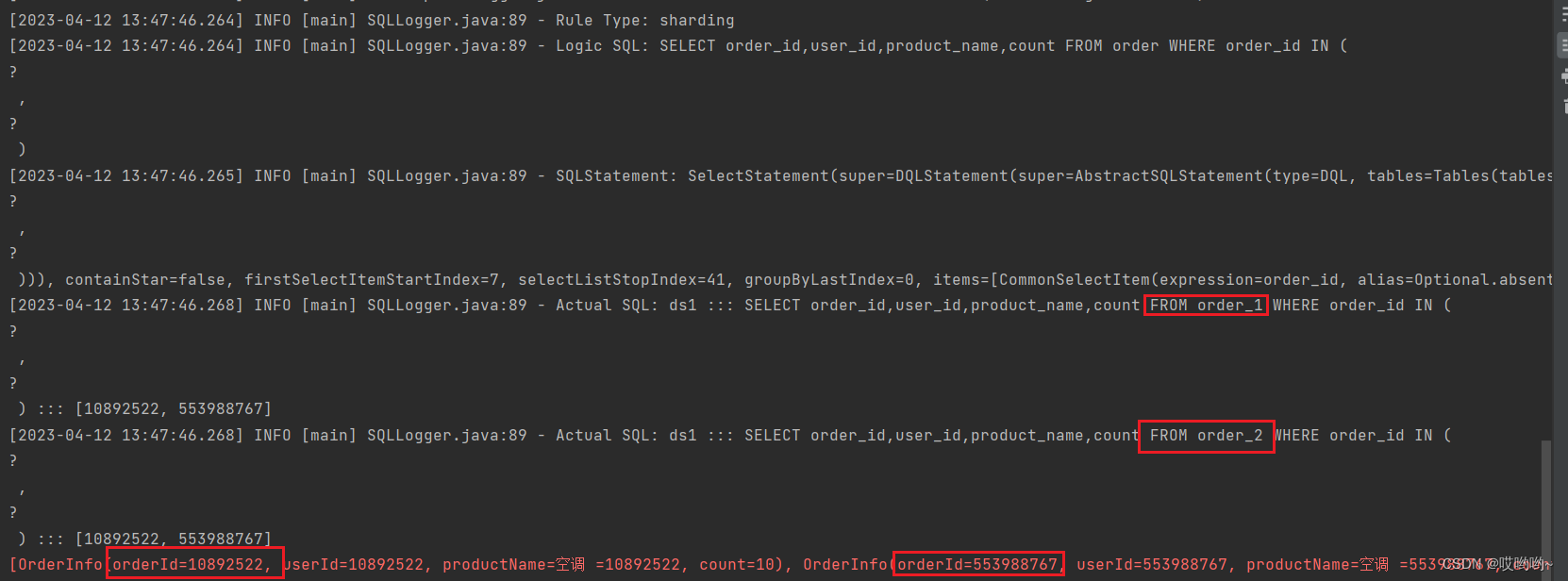
2、水平分库
2.1、建库
由1.1中所建的库表,再创建一个名为order2的数据库,并且也有一张order_1的表。
2.2、YML配置
spring:
main:
#设置为true时,后定义的bean会覆盖之前定义的相同名称的bean
allow-bean-definition-overriding: true
shardingsphere:
datasource:
# master-ds1数据库连接信息
ds1:
driver-class-name: com.mysql.cj.jdbc.Driver
maxPoolSize: 100
minPoolSize: 5
type: com.alibaba.druid.pool.DruidDataSource
url: jdbc:mysql://127.0.0.1:3306/order1?useUnicode=true&useSSL=false&serverTimezone=Asia/Shanghai
username: root
password: 123456
# slave-ds2数据库连接信息
ds2:
driver-class-name: com.mysql.cj.jdbc.Driver
maxPoolSize: 100
minPoolSize: 5
type: com.alibaba.druid.pool.DruidDataSource
url: jdbc:mysql://127.0.0.1:3306/order2?useUnicode=true&useSSL=false&serverTimezone=Asia/Shanghai
username: root
password: 123456
# 配置数据源
names: ds1,ds2
# 显示sql
props:
sql:
show: true
sharding:
tables:
#指定表
order_info:
#数据数据节点
actual-data-nodes: ds$->{1..2}.order_1
#主键生成器
key-generator:
column: order_id #指定主键字段是哪一个
type: SNOWFLAKE #雪花算法,指定主键ID值的生成策略(即使数据库主键字段指定了自增,也会使用雪花算法生成的值)
# 分库策略
database-strategy:
inline:
sharding-column: user_id #以user_id为分片键
#直接通过 user_id 的奇偶性,来判断到底是用哪个数据源,用哪个数据库和表数据
algorithm-expression: ds$->{user_id % 2 + 1} #分片策略,user_id为偶数操作ds1数据源,否则操作ds2
实体类再此就不写了,和1.3中的一样,不过注意此时使用的表名为order_1,所以需要修改实体类表名。
@TableName(value = "order_1")
2.3 测试
测试方法和1.4中一样。可以看到效果,这次根据user_id做分片键之后,根据奇偶性同样被分到了不同数据库的两个表中。
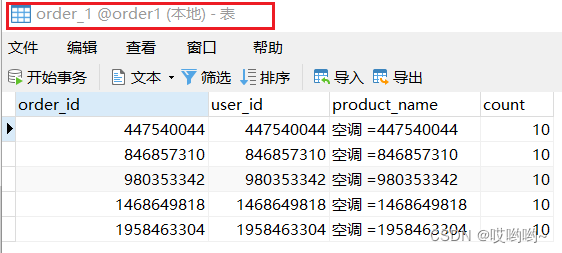
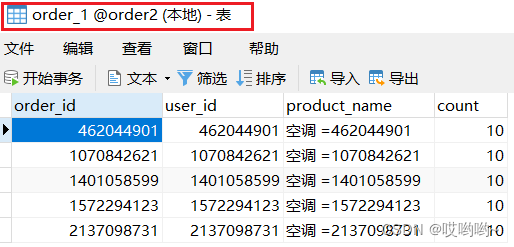
2.4、查询
从两个库的两张表分别取一个主键id进行查询
@Test
public void test(){
ArrayList<Long> ids = new ArrayList<>();
ids.add(10892522L);
ids.add(553988767L);
List<OrderInfo> orderInfos = orderInfoMapper.selectBatchIds(ids);
System.err.println(orderInfos);
}
效果,可以看到分别从两个库的两张表查到了结果。
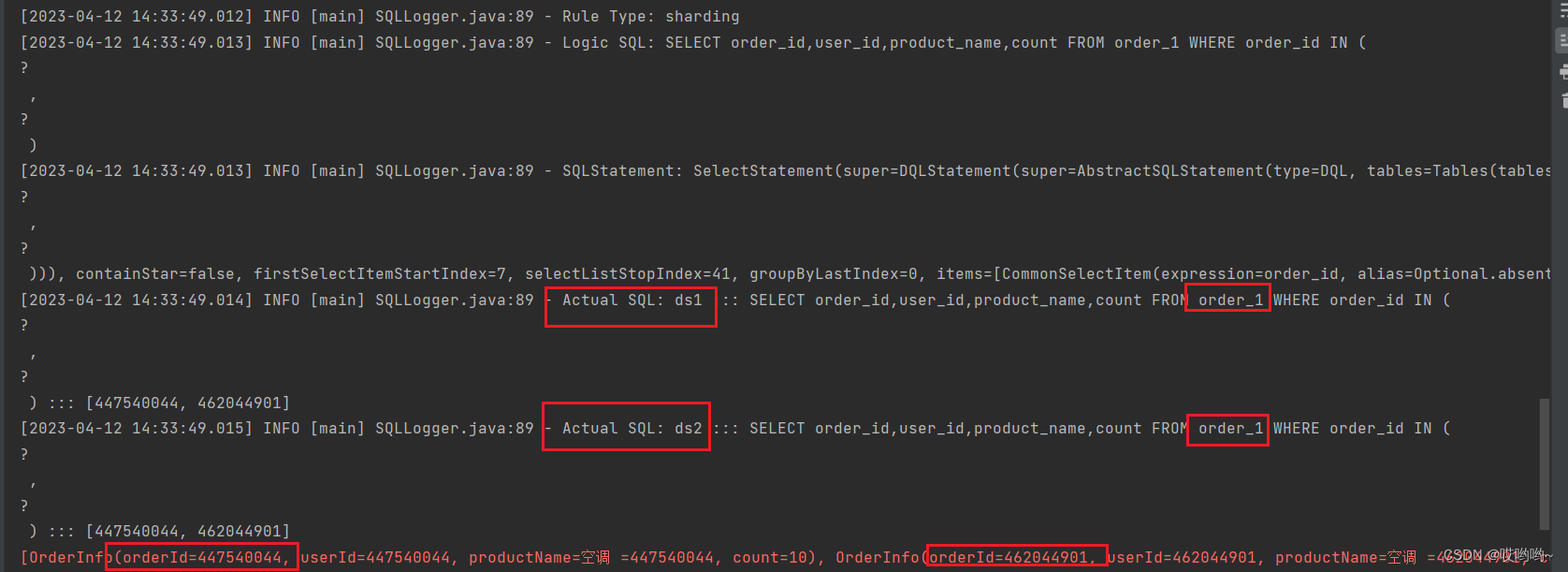
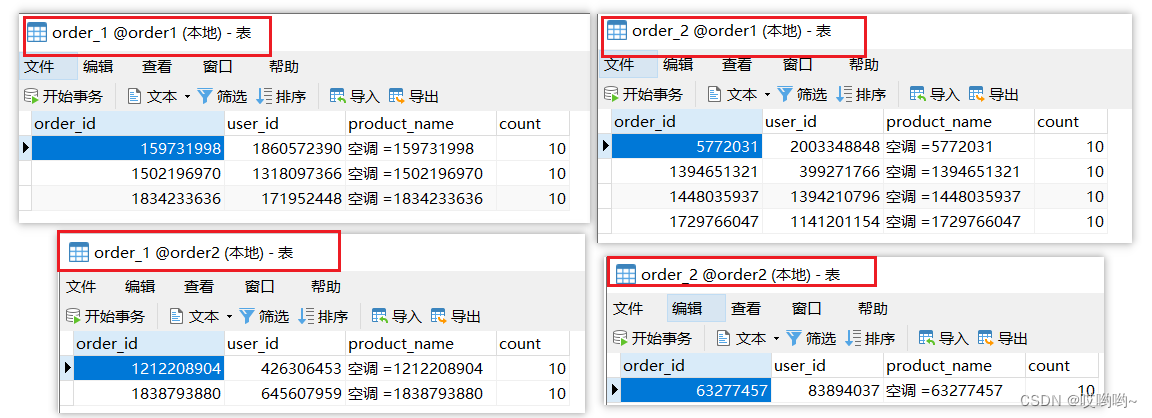
3、同时进行分库分表
大家从上述水平分库和水平分表的YML配置规则可以看出,配置分库策略和分表策略可以实现分库分表的功能,所以同时配置分库分表策略就可以将数据根据不同的规则路由到不同库的不同表中。
3.1、具体步骤和上述一样,我展示一下YML文件即可。注意此处的表名是
@TableName(value = “order”)
spring:
main:
#设置为true时,后定义的bean会覆盖之前定义的相同名称的bean
allow-bean-definition-overriding: true
shardingsphere:
datasource:
# 配置数据源
names: ds1,ds2
# master-ds1数据库连接信息
ds1:
driver-class-name: com.mysql.cj.jdbc.Driver
maxPoolSize: 100
minPoolSize: 5
type: com.alibaba.druid.pool.DruidDataSource
url: jdbc:mysql://127.0.0.1:3306/order1?useUnicode=true&useSSL=false&serverTimezone=Asia/Shanghai
username: root
password: 123456
# slave-ds2数据库连接信息
ds2:
driver-class-name: com.mysql.cj.jdbc.Driver
maxPoolSize: 100
minPoolSize: 5
type: com.alibaba.druid.pool.DruidDataSource
url: jdbc:mysql://127.0.0.1:3306/order2?useUnicode=true&useSSL=false&serverTimezone=Asia/Shanghai
username: root
password: 123456
# 显示sql
props:
sql:
show: true
sharding:
tables:
#指定表
order:
#数据节点
actual-data-nodes: ds$->{1..2}.order_$->{1..2}
#主键生成器
key-generator:
column: order_id #指定主键字段是哪一个
type: SNOWFLAKE #雪花算法,指定主键ID值的生成策略(即使数据库主键字段指定了自增,也会使用雪花算法生成的值)
# 分表策略
table-strategy:
inline:
#以order_id为分片键
sharding-column: order_id
#直接通过 order_id 的奇偶性,来判断到底是用哪个表
algorithm-expression: order_$->{order_id % 2 + 1}
# 分库策略
database-strategy:
inline:
sharding-column: user_id #以user_id为分片键
#直接通过 user_id 的奇偶性,来判断到底是用哪个数据源,用哪个数据库和表数据
algorithm-expression: ds$->{user_id % 2 + 1} #分片策略,user_id为偶数操作ds1数据源,否则操作ds2
上述YML配置规则为根据user_id 的奇偶性决定路由哪个库,根据order_id的奇偶性决定路由哪个表。
3.2、效果如图: