从大量文本中提取有用的关键信息是数据分析的一个重要环节。
Python 作为一门广泛应用于数据分析领域的编程语言,有着强大的文本处理库。
整理了几个用于文本关键词提取的优秀工具,一起学习下。
1、jieba库
jieba 是一个中文分词库,可以将一段文本分割为单独的单词。可以使用 jieba 库来提取中文文本的关键词。
1.安装
使用pip安装:
pip install jieba -i https://pypi.tuna.tsinghua.edu.cn/simple
这里使用清华大学的源地址
2. 示例代码
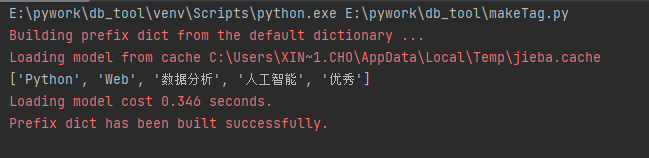
import jieba.analyse
text = "Python 是一个非常优秀的语言,它可以用于 Web 开发,人工智能,数据分析等领域。"
# 抽取5个关键词
keywords = jieba.analyse.extract_tags(text, topK=15)
print(keywords)输出:
2、textrank库
TextRank算法可以用来从文本中提取关键词和摘要(重要的句子)。TextRank4ZH是针对中文文本的TextRank算法的python算法实现。
2.1 安装
使用pip安装:
pip install scipy -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install textrank4zh -i https://pypi.tuna.tsinghua.edu.cn/simple
2.2 示例代码
from textrank4zh import TextRank4Keyword
text = "Python 是一个非常优秀的语言,它可以用于 Web 开发,人工智能,数据分析等领域。"
tr4w = TextRank4Keyword()
tr4w.analyze(text=text, lower=True, window=2)
# 抽取5个关键词
keywords = tr4w.get_keywords(15, word_min_len=1)
print(keywords)输出:
[{'word': '用于', 'weight': 0.16490795878329761},
{'word': '数据分析', 'weight': 0.16490795878329761},
{'word': 'web', 'weight': 0.15652499422860283},
{'word': '人工智能', 'weight': 0.15652499422860283},
{'word': '开发', 'weight': 0.15402639183765743}]
以上两种方法我们可以根据自己的需求进行选择使用,它们都有各自的优势和适用范围。
3、SnowNLP
SnowNLP 是一个 Python 中文文本处理库,可以提供中文分词、情感分析、文本相似度匹配等功能。
使用以下命令来安装 SnowNLP 库:
pip install snownlp -i https://pypi.tuna.tsinghua.edu.cn/simple
使用以下代码来利用 SnowNLP 库提取文本中的关键词:
from snownlp import SnowNLP
text = "Python 是一个非常优秀的语言,它可以用于 Web 开发,人工智能,数据分析等领域。"# 创建 SnowNLP 对象s = SnowNLP(text)
# 提取关键词keywords = s.keywords(5)
print(keywords)看下结果,虽然顺序有点乱,但是结果还行
['语言', '优秀', '一个', 'Python', '开发']
4、总结
jieba 的应用场景比较广泛,适用于中文文本的分词、词性标注、关键词提取等任务,是我们中文文本处理的重要工具。
textrank 主要应用于基于图模型的文本摘要和关键词提取,对于较长的英文文本的处理效果较好。
SnowNLP 的应用场景主要是中文文本情感分析、文本分类等任务,它能够识别出文本的情感色彩,并进行积极、消极等分类,对于中文文本的快速处理有不错的效果。
本文介绍了四个 Python 文本关键词提取库,分别是 jieba、textrank、SnowNLP。通过这些库的使用,我们可以从大量文本中提取出有用的关键信息,为后续的数据分析和挖掘提供重要的支持。当然,本文仅是简单介绍,Python 的文本处理远不止于此。未来,我们还可以学习更多高级的文本处理技巧,如情感分析、主题建模等,以进一步挖掘文本数据中的信息。Python 作为一个灵活、强大的工具,将继续在文本处理领域发挥着重要的作用。



![[composer-unused]扫描代码找出没有使用的依赖](https://img-blog.csdnimg.cn/img_convert/188f91adec1bd9a661f225f41f0ef635.png)