文章目录
- 前言
- 一、Spark的部署模式
- (一)Client模式
- 1. Standalone集群下的Client模式
- 2. Spark On Yarn集群下的Client模式
- (二)Cluster模式
- 1. Standalone集群下的Cluster模式
- 2. Spark On Yarn集群下的Cluster模式
- 总结
前言
#博学谷IT学习技术支持#
上篇文章介绍了PySpark的入门案例,大致了解了Spark的开发流程,本次继续探讨Spark的两种部署模式,Client模式和Cluster模式,让我们继续往下看。
一、Spark的部署模式
在Spark中,我们编写的代码成为Driver程序,Client模式和Cluster模式的区别在于Driver程序在哪里运行,Client模式时,Driver程序在提交任务的机器上运行,而Cluster模式则是将Driver提交到集群中运行。
Client和Cluster两种模式又分别存在于Standalone集群和Spark On Yarn集群,详情如下:
(一)Client模式
1. Standalone集群下的Client模式
Driver Program是一个JVM Process进程,该模式下,Driver程序运行在提交任务的主机上
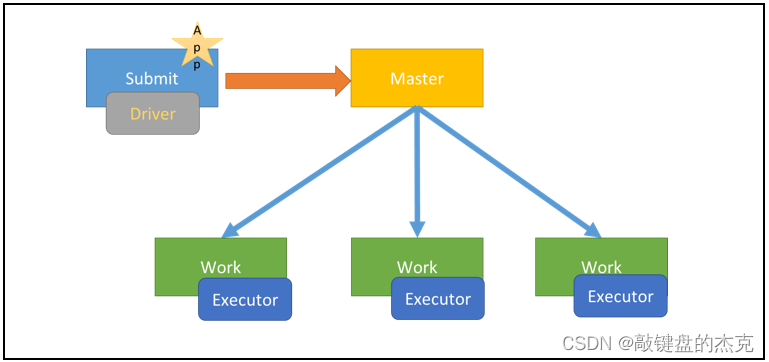
2. Spark On Yarn集群下的Client模式
Spark On Yarn集群的Client模式与Standalone集群的Client模式相同,该模式下,Driver程序也是运行在提交任务的主机上
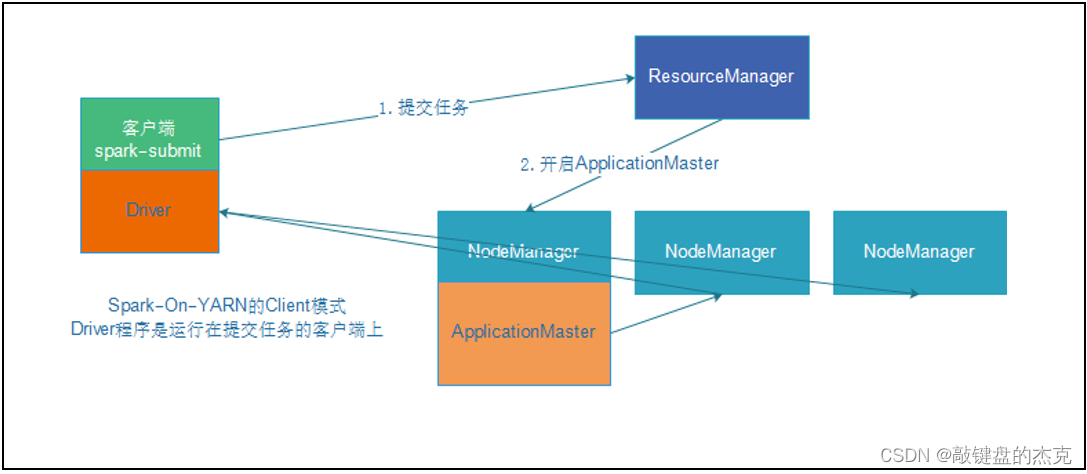
(二)Cluster模式
1. Standalone集群下的Cluster模式
Cluster模式时,Driver程序运行在集群从节点的任意一台Worker机器上
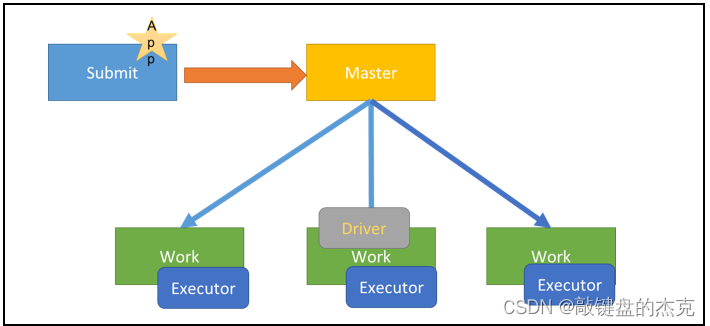
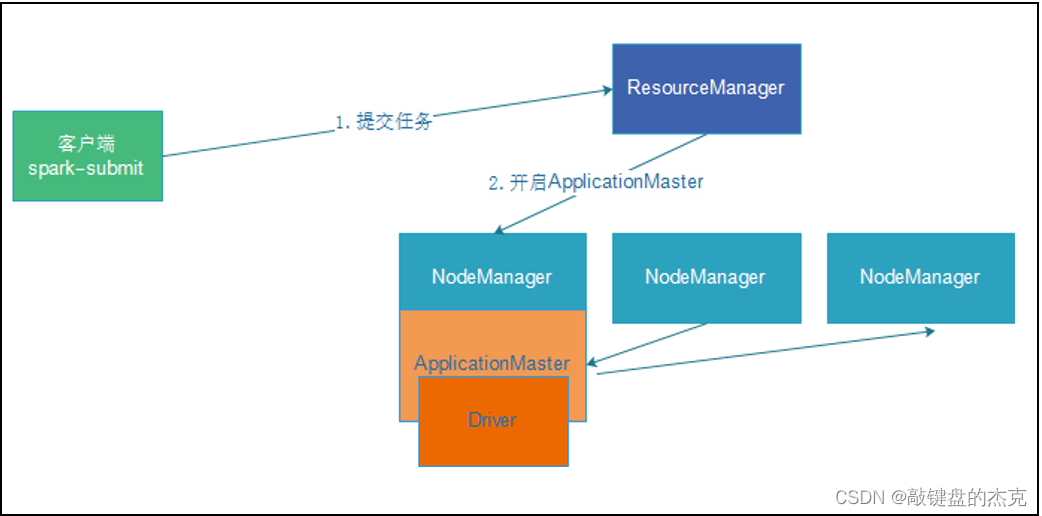
2. Spark On Yarn集群下的Cluster模式
该模式下,Driver程序运行在Yarn集群从节点的某一台机器上
开发环境下,部署模式一般设定为Client模式,而生产模式大多数都是设置为Cluster模式。
总结
Client模式与Cluster模式最主要的区别在于Driver程序运行在哪里,两种模式各有优缺点:
(1)Client模式下与集群的通信费用较高,但是执行结果可以显示在客户端,
(2)Cluster模式Driver运行在集群中,与集群的通信费用较低,但是执行结果不能显示在客户端,只能通过日志获取,由于该模式下,Driver程序由Yarn集群管理,如果运行过程中出现问题,Yarn集群会重启Driver程序。