目录
一、二叉搜索树
二、二叉搜索树的接口及实现
1、二叉搜索树的查找
2、二叉搜索树的插入
3、二叉搜索树的删除
三、二叉搜索树的递归版本
本期博客主要分享二叉搜索树的底层实现。(主要是笔记,供自己复习使用😂)
一、二叉搜索树
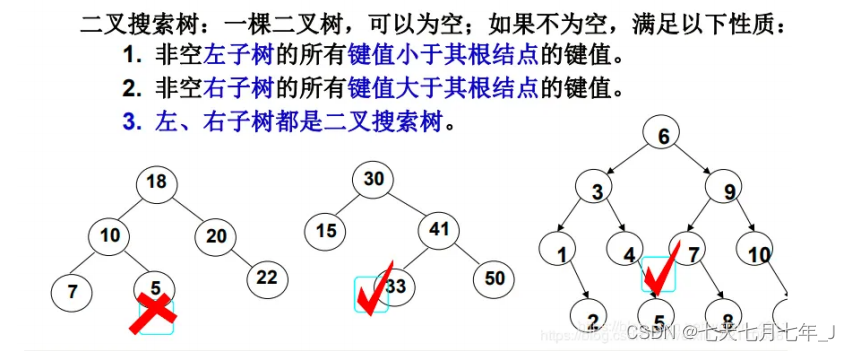
二叉搜索树(BST,Binary Search Tree)又称二叉排序树,它或者是一棵空树,或者是具有以下性质的二叉树:
若它的左子树不为空,则左子树上所有节点的值都小于根节点的值。
若它的右子树不为空,则右子树上所有节点的值都大于根节点的值。
它的左右子树也分别为二叉搜索树。
二、二叉搜索树的接口及实现
1、二叉搜索树的查找
a、从根开始比较,查找,比根大则往右边查找,比根小则往左边走查找。
b、最多查找高度次,如果走到空,还没找到,这个值在树中不存在。
代码实现:
bool Find(const K& key)
{
Node* cur = _root;
while (cur)
{
if (key < cur->_key)
{
//去左树
cur = cur->_left;
}
else if (key > cur->_key)
{
//去右树
cur = cur->_right;
}
else
{
//找到了
return true;
}
}
return false;
}2、二叉搜索树的插入
a、树为空,则直接新增节点,赋值给root指针
b、树不空,按二叉搜索树性质查找插入位置,插入新节点。
代码实现:
//插入
bool Insert(const K& key)
{
if (_root == nullptr)
{
_root == new Node(key);
return true;
}
Node* cur = _root;
Node* parent = nullptr;
//查找插入位置
while (cur)
{
if (cur->_key < key)
{
//去右树
parent = cur;
cur = cur->_right;
}
else if (cur->_key > key)
{
//去左树
parent = cur;
cur = cur->_left;
}
else
{
//相等
return false;
}
}
//找到插入位置
//判断我是左子还是右子
//因为cur为空,所以要根据值来判断
cur = new Node(key);
if (key < parent->_key)
{
parent->_left=cur;
}
else
{
parent->_right=cur;
}
return true;
}3、二叉搜索树的删除
删除比较麻烦。我们要对它的几种情境进行分析。
a、要删除的节点无孩子节点
b、要删除的节点只有左孩子节点
c、要删除的节点只有右孩子节点
d、要删除的节点有左、右孩子节点
实际情况a可以和情况b或者情况c一块处理。如果右孩子为空,则托孤给父亲节点它的左孩子。如果左孩子为空,则托孤给父亲节点它的右孩子。如果左右孩子都不为空,则要找替换节点。
替换规则:
找右子树的最左节点(右子树值最小),或者找左子树的最右节点(左子树值最大)与要删除节点替换。目的是为了满足根大于左子树而小于右子树。
代码:
bool Erase(const K& key)
{
//左孩子为空
Node* cur = _root;
Node* parent = nullptr;
while (cur)
{
if (cur->_key < key)
{
//key大于_key--去右子树查找
parent = cur;
cur = cur->_right;
}
else if (cur->_key > key)
{
parent = cur;
cur = cur->_left;
//左子树
}
else
{
//找到了
//分为三种情况
if (cur->_left == nullptr)
{
//左孩子为空
//托孤右孩子
//判断cur是parent左孩子还是右孩子
if (cur == _root)//考虑删根的情况
{
_root = cur->_right;
}
else
{
if (cur == parent->_left)
{
parent->_left = cur->_right;
}
else
{
//cur是右孩子
parent->_right = cur->_right;
}
}
delete cur;
}
else if (cur->_right == nullptr)
{
//右为空--托孤左孩子
if (cur == root)
{
_root = cur->_left;
}
else
{
if (cur == parent->_left)
{
parent->_left = cur->_left;
}
else
{
//cur是右孩子
parent->_right = cur->_left;
}
}
delete cur;
}
else
{
//左右都不为空
Node* minRight = cur->_right;//找右子树的最左节点
parent = cur;
while (minRight->_left)
{
parent = minRight;
minRight = minRight->_left;
}
cur->_key = minRight->_key;
//最左节点,不可能有左孩子,只可能有右孩子
if (minRight == parent->_left)
{
parent->_left = minRight->_right;
}
else
{
parent->_right = minRight->_right;
}
delete minRight;
}
return true;
}
}
return false;
}以上是循环版本主要接口的实现。而二叉搜索树递归版本也是非常有趣的。
三、二叉搜索树的递归版本
template<class K>
struct BSTreeNode
{
BSTreeNode<K>* _left;
BSTreeNode<K>* _right;
K _key;
BSTreeNode(const K& key)
:_left(nullptr)
,_right(nullptr)
,_key(key)
{}
};
template<class K>
class BSTree
{
typedef BSTreeNode<K> Node;
public:
BSTree()
:_root(nullptr)
{}
BSTree(const BSTree<K>& copyt)
{
//拷贝构造
_root = Copy(copyt._root);
}
BSTree<K>& operator=(BSTree<K> t)
{
swap(_root, t._root);
return *this;
}
~BSTree()
{
Destory(_root);
_root = nullptr;
}
void InOrder()
{
_InOrder(_root);
cout << endl;
}
bool FindR(const K& key)
{
return _FindR(_root, key);
}
bool InsertR(const K& key)
{
return _InsertR(_root, key);
}
bool EraseR(const K& key)
{
return _EraseR(_root, key);
}
private:
bool _InsertR(Node*& root, const K& key)
{
if (root == nullptr)
{
root = new Node(key);
return true;
}
if (root->_key < key)
{
return _InsertR(root->_right, key);
}
else if (root->_key > key)
{
return _InsertR(root->_left, key);
}
else
return false;
}
bool _FindR(Node* root, const K& key)
{
if (root == nullptr)
return false;
if (key > root->_key)
{
//右子树
return _FindR(root->_right, key);
}
else if (key < root->_key)
{
return _FindR(root->_left, key);
}
else
return true;
}
bool _EraseR(Node*& root, const K& key)
{
if (root == nullptr)
{
return false;
}
if (root->_key < key)
{
return _EraseR(root->_right,key);
}
else if (root->_key > key)
{
return _EraseR(root->_left, key);
}
else
{
//找到要删除的节点
//替换删除?
if (root->_left == nullptr)
root = root->_right;
else if (root->_right == nullptr)
root = root->_left;
else
{
//左右都不为空
//找左子树的最右节点,或者右子树的最左节点
Node* minRight = root->_right;
while (minRight->_left)
{
minRight = minRight->_left;
}
//左为空
swap(root->_key, minRight->_key);
//交换值后转换成在子树中去删除节点
return _EraseR(root->_right, key);
}
delete del;
return true;
}
}
Node* Copy(Node* root)
{
//前序遍历
if (root == nullptr)
return nullptr;
Node* newRoot = new Node(root->_key);
newRoot->_left = Copy(root->_left);
newRoot->_right = Copy(root->_right);
return newRoot;
}
void Destory(Node* root)
{
if (root == nullptr)
return;
Destory(root->_left);
Destory(root->_right);
delete root;
}
void _InOrder(Node* root)
{
//根左右
if (root == nullptr)
return;
_InOrder(root->_left);
cout << root->_key << " ";
_InOrder(root->_right);
}
Node* _root;
};递归版本实现非常巧妙的地方在于插入接口和删除接口的实现:
他们使用的是root地址的引用而不是地址的拷贝,这一点很是灵巧,博主就不多说大家细细品味其中的妙处使得代码大大简化。