1.ChineseBERT: Chinese Pretraining Enhanced by Glyph and Pinyin Information(ACL2021)
字形嵌入根据汉字的不同字体获得,能够从视觉特征中捕捉汉字语义,拼音嵌入表征汉字的发音,解决了汉语中非常普遍的异义异义现象(同一汉字有不同的发音,不同的意思)。汉字字形背后丰富的语义应该增强汉语自然语言处理模型的表现力。汉语中存在非常普遍的异音现象,同一个字有多个发音,每个发音都与特定的含义相关。这些信息无法通过上下文化或字形嵌入捕获,因此拼音在建模语义和语法信息时至关重要。每个发音都与特定的拼音表达相关联。 “乐” yuè means “music”, “lè”means “happy”。同一字符的不同发音不能通过字形嵌入来区分,因为标识是相同的,也不能通过字符ID嵌入来区分,因为它们都指向相同的字符ID,但可以通过拼音来区分。
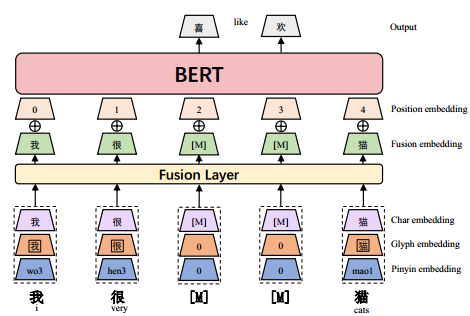
![]() 表示向量拼接,对于每个汉字,我们使用了三种类型的字体——方松、行楷和隶书,每种字体都是一个24 × 24的图像,像素值范围为0 ~ 255。图像被连接成大小为24 × 24 × 3的张量。张量被平面化并传递给FC层以获得字形嵌入。全连接层是一种密集连接层,其中所有神经元都与上一层的每个神经元相连。
表示向量拼接,对于每个汉字,我们使用了三种类型的字体——方松、行楷和隶书,每种字体都是一个24 × 24的图像,像素值范围为0 ~ 255。图像被连接成大小为24 × 24 × 3的张量。张量被平面化并传递给FC层以获得字形嵌入。全连接层是一种密集连接层,其中所有神经元都与上一层的每个神经元相连。
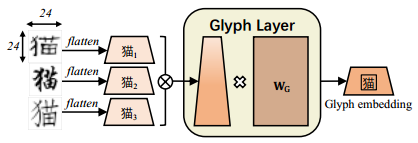
每个字符的拼音嵌入用于解耦属于同一字符形式的不同语义。使用开源的pypinyin package4为其组成字符生成拼音序列。Pypinyin是一个将机器学习模型与基于字典的规则相结合的系统,用于推断给定上下文字符的拼音。将宽度为2的CNN应用于拼音字母序列,然后使用max-pooling来获得最终的拼音嵌入。
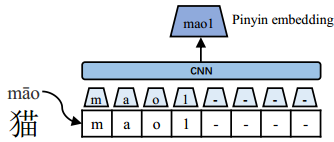
×为向量矩阵乘法。我们将字符嵌入、字形嵌入和拼音嵌入连接起来,并使用具有可学习矩阵WF的FC层来诱导融合嵌入
输出是每个输入汉字对应的上下文化表示
屏蔽策略,全字屏蔽(WWM)和字符屏蔽(CM)。Li et al (2019b)认为使用汉字作为基本输入单位可以缓解汉语词汇量不足的问题。因此,我们采用了在给定上下文中屏蔽随机字符的方法,称为Char masking。另一方面,汉语中大量的单词由多个字符组成,对于这些单词,CM策略可能太容易对模型进行预测。使用LTP工具包6来识别中文单词的边界,以实现全词掩蔽。
2.Ideography Leads Us to the Field of Cognition: A Radical-Guided Associative Model for Chinese Text Classification(AAAI2021)
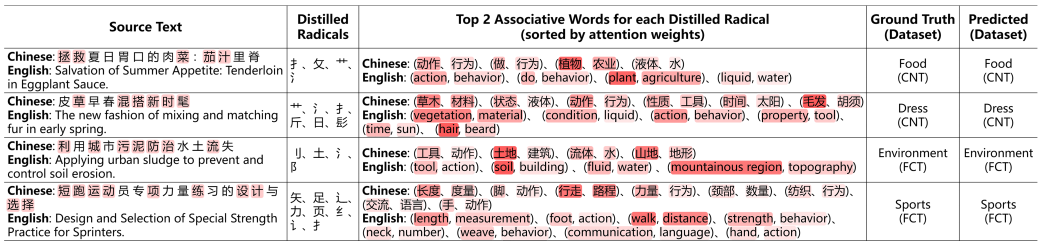
使用由词根引导的联想信息是保证语义理解稳健性的关键,汉语词典系统地收录了许多与偏旁相关的基本概念和扩展概念,这为改进汉语文本表示和分类提供了一条方便但尚未探索的途径。RAM由两个耦合的空间组成,即字面空间和联想空间,它模拟了人们理解中文文本时的真实思维过程。首先在文字空间中设计了一个序列化的建模结构,以全面地获取中文文本的顺序信息。然后,基于汉语词典提供的权威信息,设计了一个关联模块,并提出了一种以表意词根为媒介,在联想空间中对先验概念词进行关联的策略——词根-词关联。然后,我们设计了一个注意模块来模拟人们在文字空间和联想空间之间的匹配和决策,该模块可以平衡每个联想词在特定语境下的重要性。
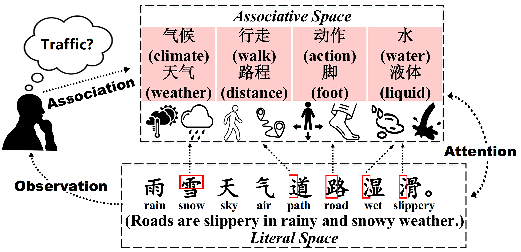
1)首先引入了文字空间,设计了序列化结构,对中文文本序列信息进行建模;2)然后,我们提出了一个关联模块和以词根为媒介进行词根-词关联的策略,从而在联想空间中建模联想内容;3)在此基础上,通过模拟人的心理认知过程,设计注意模块,模拟文字空间与联想空间的匹配与决策
字符类型屏蔽
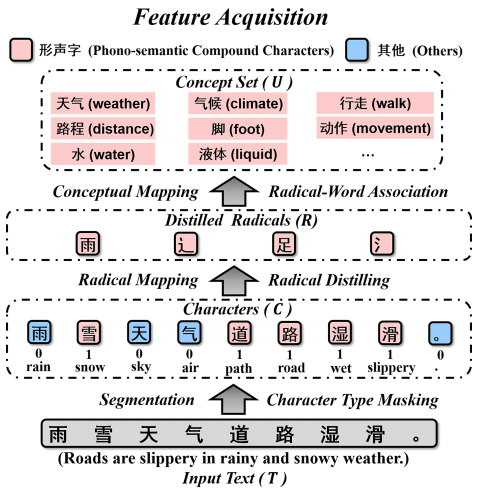
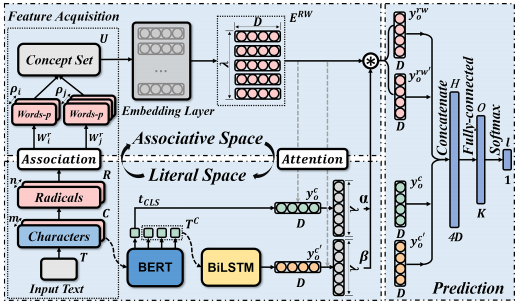
给定一个包含m个字符的输入中文文本T,我们首先将其分割成字符序列C = {c1, c2,…,其中C实际上代表t的字符级特征。然后,通过查阅中国字符类型字典我们能够为每个字符标记一个类型标签,从而实现字符类型屏蔽过程,其中Cp为音语义复合字
![]()
将每个字符的掩码代码与自身相乘,以确定哪些字符可以保留用于从中文字典中查询偏旁
![]()
Radical Query允许我们在新华字典的帮助下将每个汉字映射为单个根号。此外,我们过滤掉R中所有重复的自由基,以避免冗余处理。因此,R = {r1, r2,…, rn}是字符序列C的蒸馏基,其中n∈[0,m]。 不直接使用词根作为附加特征,而是将提取的词根作为关联表示属性和外延意义的高度相关联想词的媒介。在形式上,我们将此策略称为RadicalWord Association,它对应于图2中的关联模块。因此,与语音语义复合字相连的联想词记为words -p(红色)。通过查阅Radical Concept Dictionary,每个提炼出来的Radical ri∈R = {r1, r2,…, rn}将对应于一个关联词列表:
![]()
ρi≥1表示ri的关联词的数量,它会因根号的不同而不同。因此,从文本T中提取的所有R可以形成一组联想词U = {w1, w2,…wλ} 其中U实际上代表T的导入外部词级特征。由于不同的偏旁可能对应相同的联想词,这里的集合操作允许重复的联想词合并为一个
字空间建模
![]()
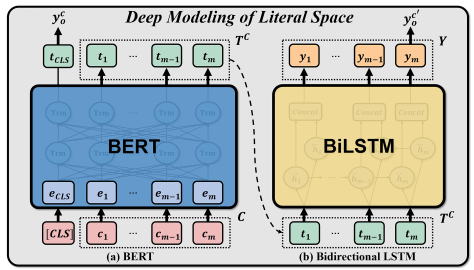
在每个序列C前添加的第一个标记[CLS]始终是一个特殊的分类标记,与此标记对应的最终隐藏状态tCLS用作分类任务的聚合序列表示。因为tCLS作为BERT的输出用于以后的分类,为了方便起见,我们还使用y co来表示它。同时,T C表示文本T中包含的对应m个字符的隐藏向量。然后,我们将BERT输出的隐藏状态作为初始化向量,然后将它们作为一个序列一起发送到BiLSTM中,进一步学习上下文依赖关系,如图4所示。形式上,我们取BERT的其余输出,即T C = {t1, t2,…, tm}作为c中每个字符ci(1≤i≤m)的复杂表示。然后,我们应用BiLSTM来进一步模拟概念的变化(Council et al
2000)在特定语境下的翻译,这与人们根据自己积累的经验来适应新的文本的过程是一致的。因此,给定BERT输出T C的向量嵌入序列,通过接收T C作为输入,计算BiLSTM的隐藏向量:
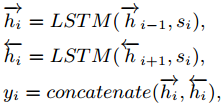
联想词嵌入。为了表示概念集U = {w1, w2,…, wλ}用于后续计算,我们需要将每个单词映射为低维实值向量。在这里,我们应用了基于分布假设的外部井预训练嵌入模型(Mikolov et al . 2013;Le and Mikolov 2014)和一个嵌入层来获得通过Radical-word Association获得的单词的嵌入向量:
![]() λ为U的总联想字数
λ为U的总联想字数
深度学习中的注意机制本质上类似于人类的选择性视觉注意机制。事实上,对于阅读理解,人们通常倾向于先通读句子,在脑海中形成一个初步的认知,然后根据句子的整体上下文,返回来选择和匹配合适的概念(Taatgen et al 2007)。在这一认知过程的启发下,我们设计了一个注意模块,它可以将我们的模型集中在U背中相对重要的联想词上,并考虑前面解释的学习上下文表示,即y co和y c 0 o。
形式上,我们将yco和yc0o作为查询,ERW同时作为键和值来实现注意机制。
也就是说,给定在联想空间中获得的联想词表示,即ERW = {e rw1, erw2,…, erw λ},利用Literal Space中得到的上下文表示,即y co和y c 0 o,关注每个联想词wi∈U,得到每个erw ∈erw和erw θ∈erw(1≤≤λ, 1≤θ≤λ)的注意权值:
其中α 0∈R1×λ, β 0∈R1×λ分别是ERW的两个向量,分别表示yco和yc0o两个上下文方面的注意权重。α 0 和β 0 θ表示,th或关联词的θ-th权值,f(·,·)表示距离函数,本文将其表述为逐元素点积运算。然后,我们需要用sof tmax函数归一化α 0和β 0:然后通过注意加权和得到联想词的两方面注意表示y rw o和y rw0
其中H∈R1×4D为通过维数拼接的向量,具有保留所有信息的优势(Zhang et al 2019a)。之后,我们利用完全连接的神经网络来学习这四种表示形式之间隐藏的相互作用和增强
![]()
其中W(l)、b (l)分别为全连通线性神经网络拟合的权值矩阵和偏置向量,O∈R1×K为其输出。注意,K表示标签集S的大小。最后,通过softmax函数和argmax操作对预测的标签l进行分类
3.Graph Convolutional Networks for Text Classification(AAAI2018)
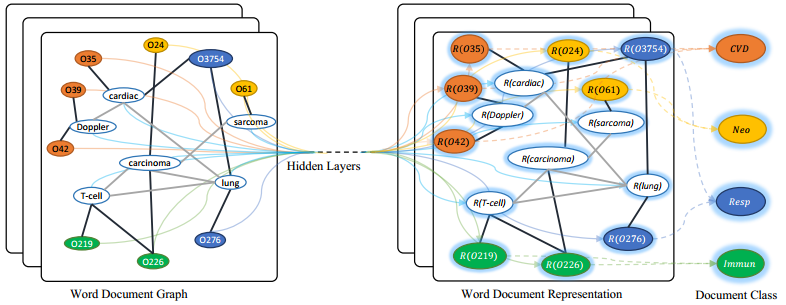
基于单词共现和文档单词关系为语料库构建单个文本图,然后学习语料库的文本图卷积网络(text GCN)。我们的文本GCN初始化为单词和文档的单一热表示,然后它联合学习单词和文档的嵌入,由文档的已知类标签监督
由于CNN和RNN优先考虑局部性和序列性(Battaglia et al 2018),这些深度学习模型可以,很好地捕获局部连续单词序列中的语义和句法信息,但可能会忽略语料库中携带非连续和长距离语义的全局单词共出现。图神经网络在具有丰富关系结构的任务中非常有效,可以保存图的全局结构信息 。从整个语料库中构建一个大型图,其中包含单词和文档作为节点。两个词节点之间的边界由词共现信息构建,单词节点和文档节点之间的边界由词频和单词的文档频率构建。然后将文本分类问题转化为节点分类问题。该方法可以在标记文档占比小的情况下获得较强的分类性能,并学习可解释的单词和文档节点嵌入。
深度学习文本分类研究可以分为两类。一组研究专注于基于词嵌入的模型。最近的几项研究表明,深度学习在文本分类上的成功在很大程度上取决于词嵌入的有效性(Shen et al 2018;Joulin等,2017;Wang et al 2018)。一些作者将无监督词嵌入聚合为文档嵌入,然后将这些文档嵌入馈送到分类器中(Le和Mikolov 2014;Joulin等,2017)。其他人共同学习了单词/文档和文档标签嵌入(Tang, Qu, and Mei 2015;Wang et al 2018)。我们的工作与这些方法有关,主要的区别是这些方法在学习词嵌入后构建文本表示,而我们同时学习单词和文档嵌入以进行文本分类。另一组研究采用了深度神经网络。两个代表性的深度网络是CNN和RNN。(Kim 2014)使用CNN进行句子分类。该体系结构是在计算机视觉中使用的cnn的直接应用,但具有一维卷积。(Zhang, Zhao, and LeCun 2015)和(Conneau et al 2017)设计了字符级cnn,并取得了很好的结果。(Tai, Socher, and Manning 2015), (Liu, Qiu, and Huang 2016)和(Luo 2017)使用LSTM,一种特定类型的RNN来学习文本表示。为了进一步增加这种模型的表示灵活性,注意机制已被引入作为用于文本分类的模型的一个组成部分(Yang et al 2016;Wang et al 2016)。这些方法虽然有效且应用广泛,但它们主要关注局部连续词序列,而没有显式地使用语料库中的全局词共现信息。
GCN是一种多层神经网络,它直接在图上操作,并根据其邻域的属性诱导节点的嵌入向量。
4.BertGCN: Transductive Text Classification by Combining GCN and BERT (ACL2021)
BertGCN在数据集上构造异构图,并使用BERT表示将文档表示为节点。通过联合训练BertGCN中的BERT和GCN模块,所提出的模型能够利用两个世界的优势:大规模预训练(利用大量原始数据的优势)和传导学习(通过图卷积传播标签影响来联合学习训练数据和未标记测试数据的表示)
构建了一个图表来模拟文档之间的关系。图中的节点表示单词和文档等文本单元,而边是基于节点之间的语义相似性构造的。然后将gnn应用到图中进行节点分类。gnn和转导学习的优点如下:(1)对一个实例(训练和测试)的决策不仅要靠自己,还要靠邻居。这使得模型对数据异常值更有免疫力;(2)在训练时,由于模型将监督标签的影响通过图边在训练实例和测试实例之间传播,因此无标签数据也有助于表示学习的过程,从而获得更高的性能。现有的结合BERT和gnn的工作使用图形来建模单个文档样本中标记之间的关系,这属于归纳学习的范畴。与这些工作不同的是,我们使用图来建模整个语料库中不同样本之间的关系,以利用标记文档和未标记文档之间的相似性,并使用gnn来学习它们之间的关系
使用BERT样式模型(例如BERT、RoBERTa)初始化文本图中文档节点的表示。这些表示被用作GCN的输入。然后,将使用GCN基于图结构迭代更新文档表示,其输出被视为文档节点的最终表示,并发送到softmax分类器进行预测。通过这种方式,我们能够利用预训练模型和图模型的互补优势。具体而言,我们在TextGCN之后构建了一个包含单词节点和文档节点的异构图(Yao et al, 2019)。我们分别基于术语频率-逆文档频率(TF-IDF)和正点互信息(PPMI)定义词-文档边和词-词边。两个节点i和j之间的边的权值定义为:
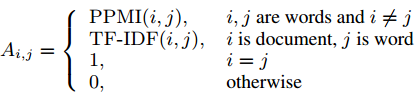





![后缀数组的应用:[Leetcode] 321.拼接最大数(困难)](https://img-blog.csdnimg.cn/c40fb687fe394dfa852ad41781d17b11.png)



