一、概述
Python 内部采用 引用计数法,为每个对象维护引用次数,并据此回收不在需要的垃圾对象。由于引用计数法存在重大缺陷,循环引用时由内存泄露风险,因此Python还采用 标记清除法 来回收在循环引用的垃圾对象。此外,为了提高垃圾回收(GC)效率,Python还引入了 分代回收机制。
二、3种回收方法介绍
1、引用计数法
1.引用计数法案例
Python采用了类似Windows内核对象一样的方式来对内存进行管理。每一个对象,都维护这一个对指向该对对象的引用的计数。
引用计数 是计算机编程语言中的一种 内存管理技术 ,它将资源被引用的次数保存起来,当引用次数变为 0 时就将资源释放。它管理的资源并不局限于内存,还可以是对象、磁盘空间等等。
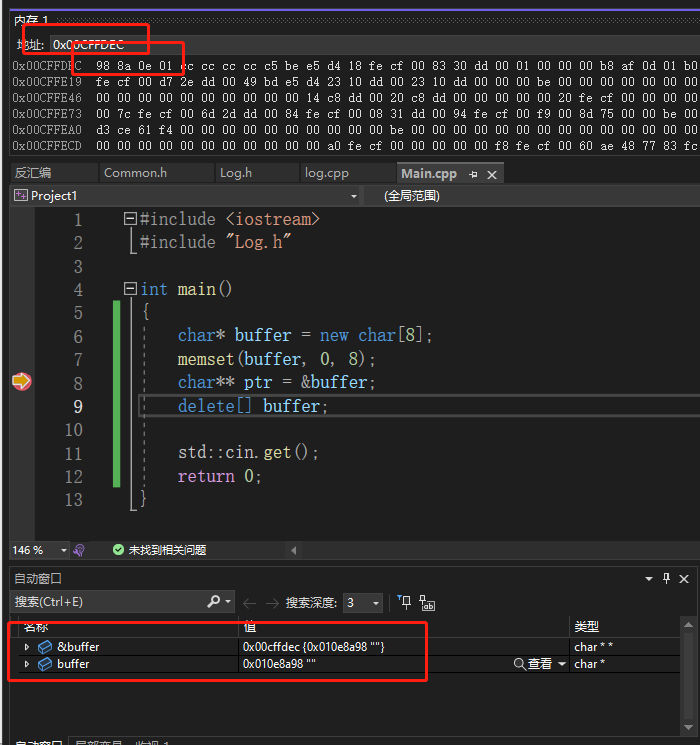
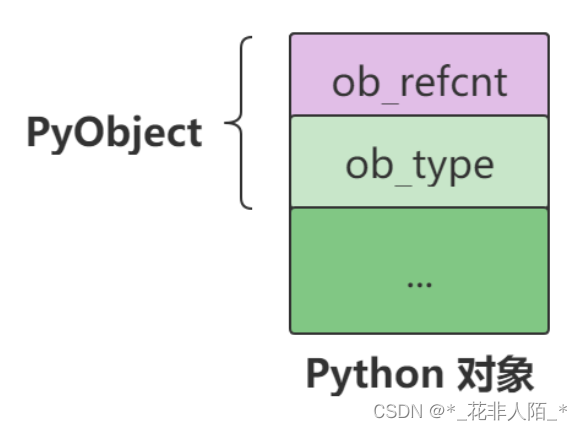
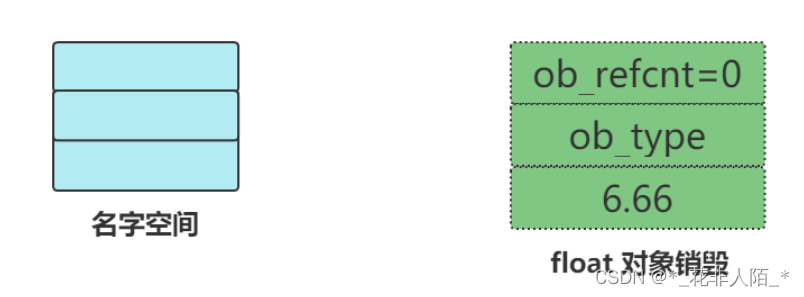
Python 也使用引用计数这种方式来管理内存,每个 Python 对象都包含一个公共头部,头部中的 ob_refcnt 字段便用于维护对象被引用次数。一个典型的 Python 对象结构如下:
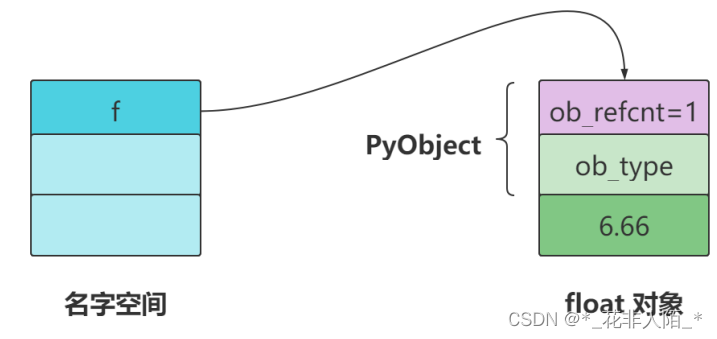
当创建一个对象实例时,先在堆上为对象申请内存,对象的引用计数被初始化为 1 。以 Python 为例,我们创建一个 float 对象保存6.66,并把它赋值到变量 f :
>>> import sys >>> f = 6.66 >>> sys.getrefcount(f) 2 ''' 引用计数器赋值是1,结果输出的是2 原因:初始化引用计数器赋值是1,当把对象作为函数参数传递给sys模块时, 会产生一个临时的引用,当输出这个值的时候永远要比实际+1,但实际他还是1 sys.getrefcount()函数返回指定对象的引用计数。 引用计数是一种追踪Python对象生命周期的技术,它表示指向该对象的引用数量。 '''当把 f 赋值给 ff 后,float对象的引用计数就变成了2,因为现在有两个变量在引用它
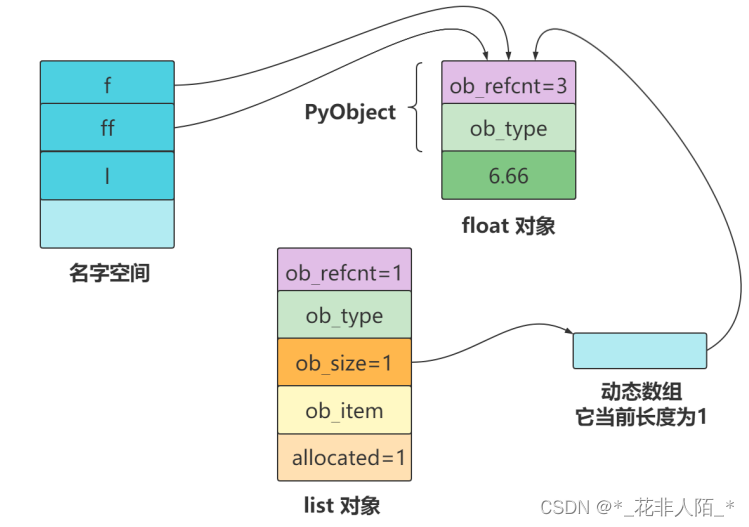
>>> ff = f >>> sys.getrefcount(f) 3新建一个 list 对象,并把 float 对象保存在里面。这样一来,float 对象有多了一个来自 list 对象的引用,因此它的引用计数又加一,变成 3 了:
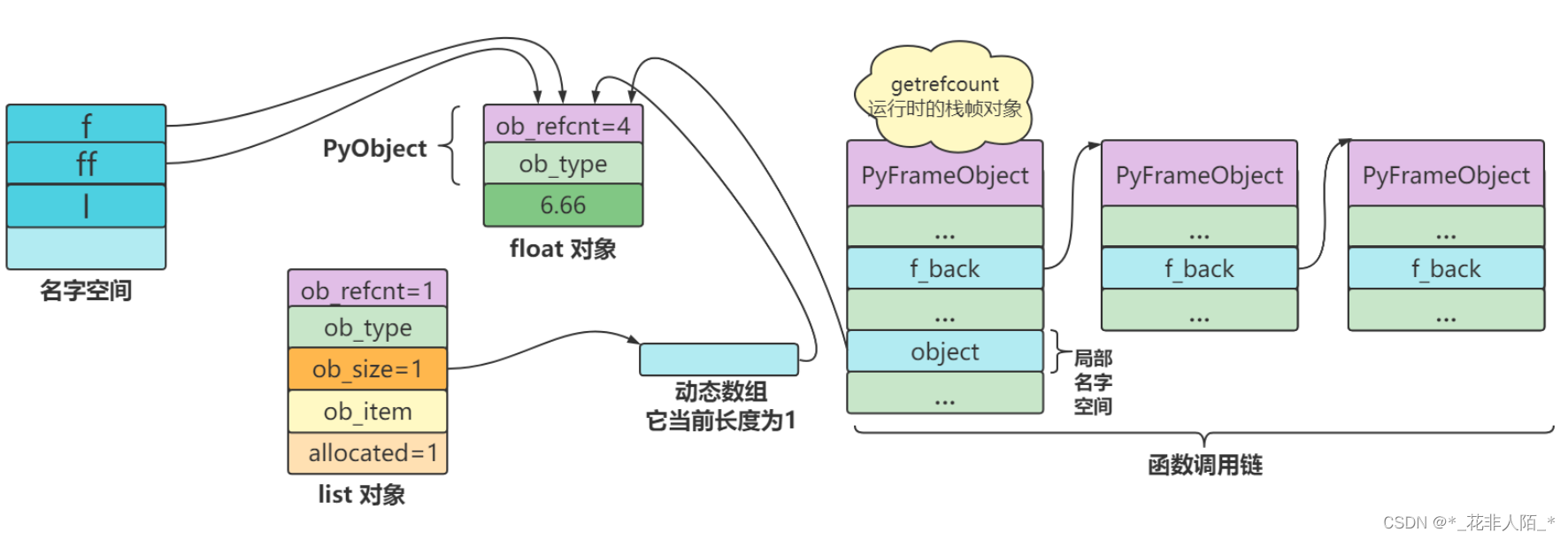
>>> l = [f] >>> l [4.56] >>> sys.getrefcount(f) 4引用计数不应该是 3 吗?为什么会是 4 呢?由于 float 对象被作为参数传给 getrefcount 函数,它在函数执行过程中作为函数的局部变量存在,创建了一个临时的引用,因此又多了一个引用:
随着 getrefcount 函数执行完毕并返回,它的栈帧对象将从调用链中解开并销毁,这时 float 对象的引用计数也跟着下降。因此,当一个对象作为参数传个函数后,它的引用计数将加一;当函数返回,局部名字空间销毁后,对象引用计数又减一。
引用计数就这样随着引用关系的变动,不断变化着。当所有引用都消除后,引用计数就降为零,这时 Python 就可以安全地销毁对象,回收内存了:>>> del l >>> del ff >>> del f >>> sys.getrefcount(f)
2.引用计数增加
- 对象被创建
- 如果有新的对象使用该对象
- 作为容器对象的一个元素
- 被作为参数传递给函数
3.引用计数减少
- 对象的引用被显示的销毁
- 新对象不在使用该对象
- 对象从列表中被移除,或者列表对象本身被销毁
- 函数调用结束
4.引用机制优点
- 简单
- 实时性:一旦没有引用,内存就直接释放了。
5.引用机制缺点
- 维护引用计数消耗资源
- 循环引用的问题无法解决
a = [1,2] b = [3,4] a.append(b) #b的计数器2 b.append(a) #a的计数器2 del a del b
2、标记-清除法
1. 对比引用计数法
引用计数法能够解决大多数垃圾回收的问题,但是遇到两个对象相互引用的情况,del语句可以减少引用次数,但是引用计数不会归0,对象也就不会被销毁,从而造成了内存泄漏问题。针对该情况,Python引入了标记-清除机制
2. 循环引用

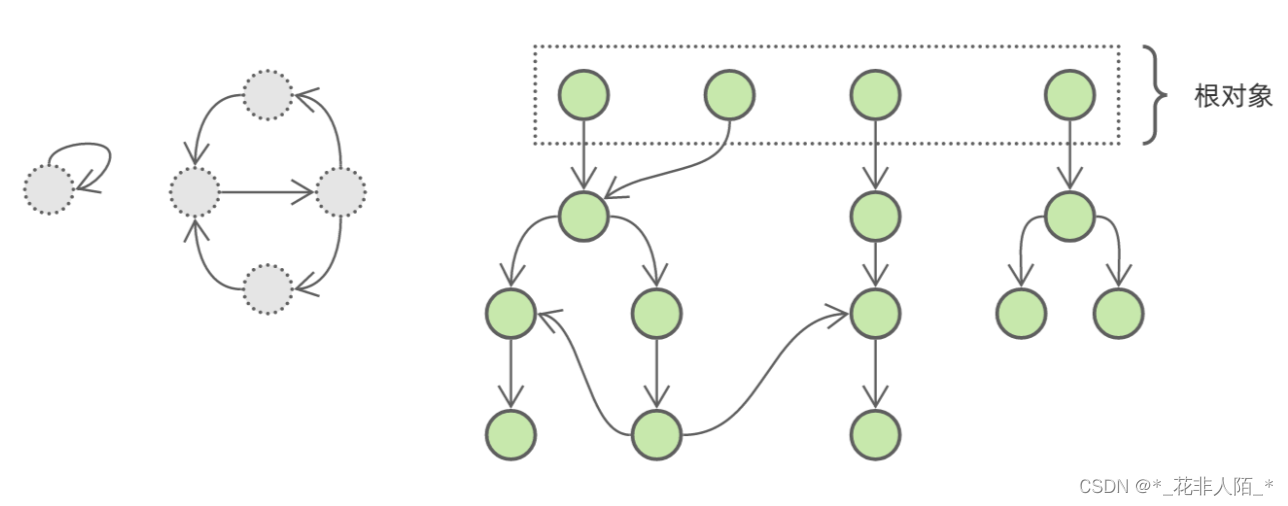
引用计数这种管理内存的方式虽然很简单,但是有一个比较大的瑕疵,即它不能很好的解决循环引用问题。如上图所示:对象 A 和对象 B,相互引用了对方作为自己的成员变量,只有当自己销毁时,才会将成员变量的引用计数减 1。因为对象 A 的销毁依赖于对象 B销毁,而对象 B 的销毁与依赖于对象 A 的销毁,这样就造成了我们称之为循环引用(Reference Cycle)的问题,这两个对象即使在外界已经没有任何指 针能够访问到它们了,它们也无法被释放。
class People:
pass
class Cat:
pass
#创建People的实例对象
p = People()
#创建Cat的实例对象
c = Cat()
#People的宠物属性指向Cat
p.pet = c
#Cat的主人属性指向People
c.master = p
#删除p和c对象
del p
del c上述实例中,对象p中的属性引用c,而对象c中属性同时来引用p,从而造成仅仅删除p和c对象,也无法释放其内存空间,因为他们依然在被引用。深入解释就是,循环引用后,p和c被引用个数为2,删除p和c对象后,两者被引用个数变为1,并不是0,而python只有在检查到一个对象的被引用个数为0时,才会自动释放其内存,所以这里无法释放p和c的内存空间。
主动思路一般分为两步:垃圾识别 和 垃圾回收 。垃圾对象被识别出来后,回收就只是自然而然的工作了,因此垃圾识别是解决问题的关键。那么,有什么办法可以将垃圾对象识别出来呢?我们来考察一个一般化例子:
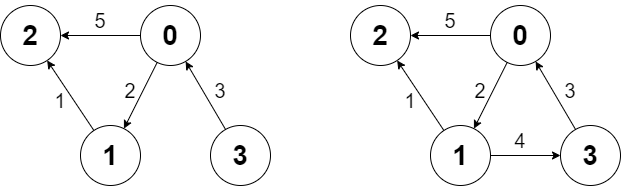
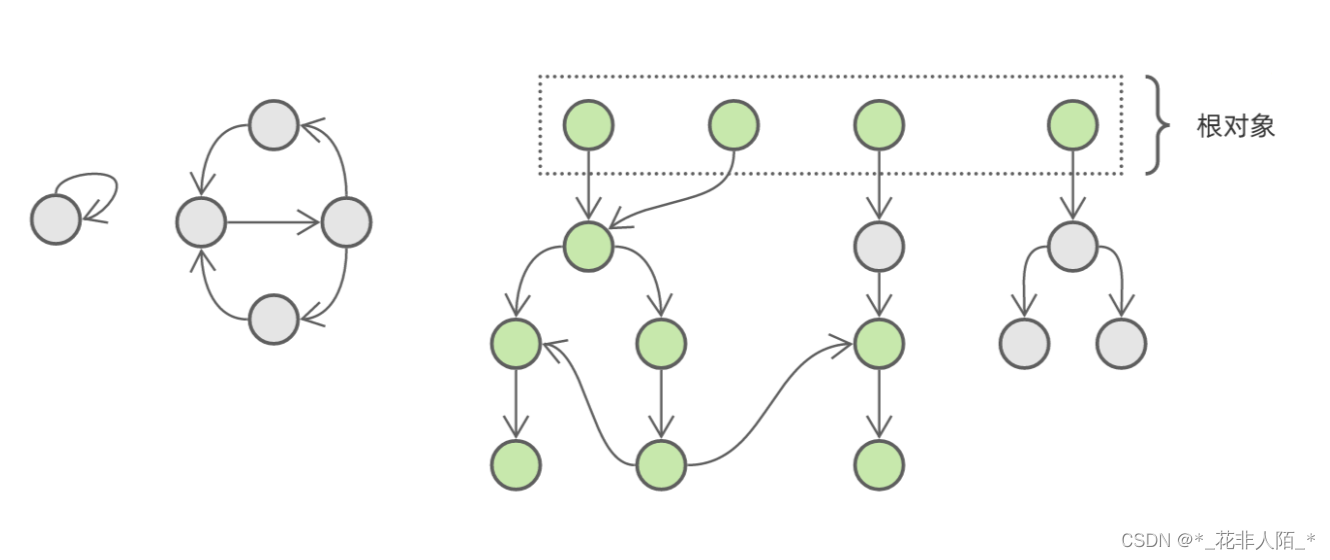
这是一个对象引用关系图,其中灰色部分是需要回收但由于循环引用而无法回收的垃圾对象,绿色部分是被程序引用而不能回收的活跃对象。如果我们能够将活跃对象逐个遍历并标记,那么最后没有被标记的对象就是垃圾对象。
遍历活跃对象,第一步需要找出 根对象 ( root object )集合。所谓根对象,就是指被全局引用或者在栈中引用的对象,这部分对象是不能被删除的。因此,我们将这部分对象标记为绿色,作为活跃对象遍历的起点。根对象本身是 可达的 ( reachable ),不能删除;被根对象引用的对象也是可达的,同样不能删除;以此类推。我们从一个根对象出发,沿着引用关系遍历,遍历到的所有对象都是可达的,不能删除
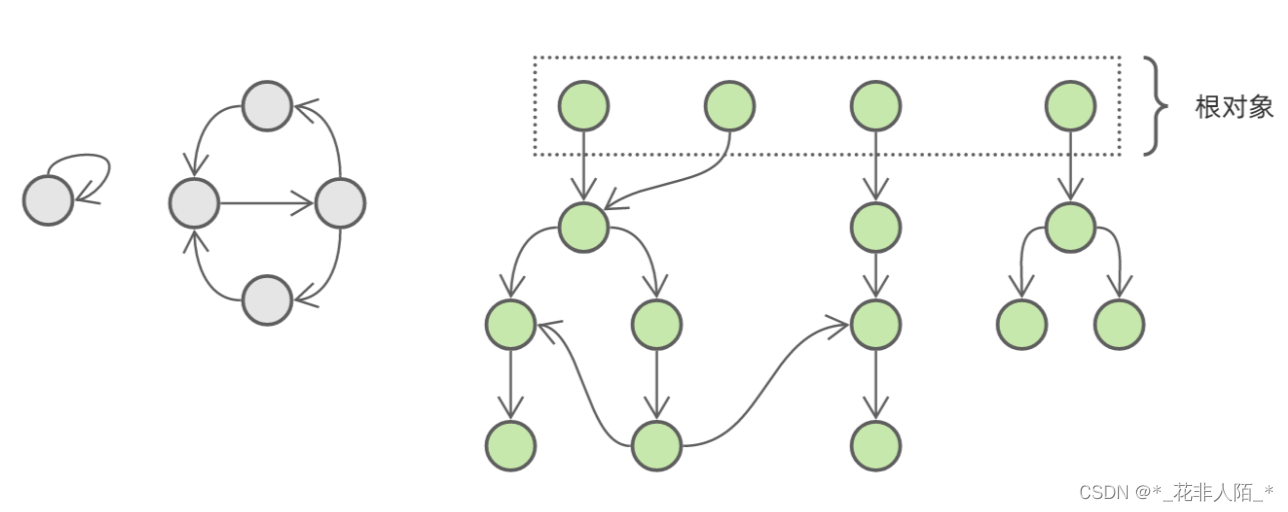
这样一来,当我们遍历完所有根对象,活跃对象也就全部找出来了:
而没有被标色的对象就是 不可达 ( unreachable )的垃圾对象,可以被安全回收。循环引用的致命缺陷完美解决了!
这就是垃圾回收中常用的 标记清除法 。

3. 【示例】标记清除法
下图中小黑点(变量)表示根节点,从根节点出发,每个对象都有引用和被引用的情况,如果该对象找不到根节点,那么就会被清除,如图1,2,3都有被小黑点(变量)引用,4,5没有变量引用,所以4,5就会被清除。

3、分代回收机制
1. 分代回收机制
Python 程序启动后,内部可能会创建大量对象。如果每次执行标记清除法时,都需要遍历所有对象,多半会影响程序性能。为此,Python 引入分代回收机制——将对象分为若干“代”( generation ),每次只处理某个代中的对象,因此 GC 卡顿时间更短。
考察对象的生命周期,可以发现一个显著特征:一个对象存活的时间越长,它下一刻被释放的概率就越低。我们应该也有这样的亲身体会:经常在程序中创建一些临时对象,用完即刻释放;而定义为全局变量的对象则极少释放。
因此,根据对象存活时间,对它们进行划分就是一个不错的选择。对象存活时间越长,它们被释放的概率越低,可以适当降低回收频率;相反,对象存活时间越短,它们被释放的概率越高,可以适当提高回收频率。
对象存活时间 释放概率 回收频率 长 低 低 短 高 高 Python 内部根据对象存活时间,将对象分为 3 代(见Include/internal/mem.h ):
#define NUM_GENERATIONS 3随着时间的推进,程序冗余对象逐渐增多,达到一定阈值,系统进行回收。
这 3 个代分别称为:初生代、中生代 以及 老生代。当这 3 个代初始化完毕后,对应的 gc_generation 数组大概是这样的:
import gc #python 中内置模块gc触发 print(gc.get_threshold()) #查看gc默认值 #输出(700, 10, 10)

2. 第一代链表
当第一代达到700,就开始检测哪些对象引用计数变成0了,把不是0的放到第二代链表里,此时第一代链表就是空了,当再次达到700时,就再检测一遍。
3.第二代链表
当第二代链表达到10,就检测一次。
4.第三代链表
第三代链表检测10之后,第三代链表检测一次。
import gc
#返回一个元组,分别获取这三代当前计数
gc.get_count()
#返回一个元组,分别获取这三代当前的收集阈值
gc.get_threshold()
#设置阈值
gc.set_threshold()
#关闭gc垃圾回收机制
gc.disable()