最近做的业务一直是和第三方交互的业务,为了加快速度,基本上都是采用多线程,然而时不时总是发生一些推送任务莫名的卡死,知道前几天的一次发现,让我开始了线程的排查之路,希望对大家的有一定的启发和借鉴
一:分布式锁导致的线程夯死
问题的发生是小伙伴突然和我说线上的数据推送任务不推送了,于是我基于对自己的代码信任,觉得不可能,(其实以前也发生过这样的问题,大多是代码中涉及的redis队列超时导致,不过我已经优化了一个版本,觉得不可能还有这样的问题,这时候小伙伴说重启吧,但是我想了想之前也遇到过这种灵异现象,这一次上头了,感觉事情没那么简单,于是我开始了排查之路
1.发现线程夯死
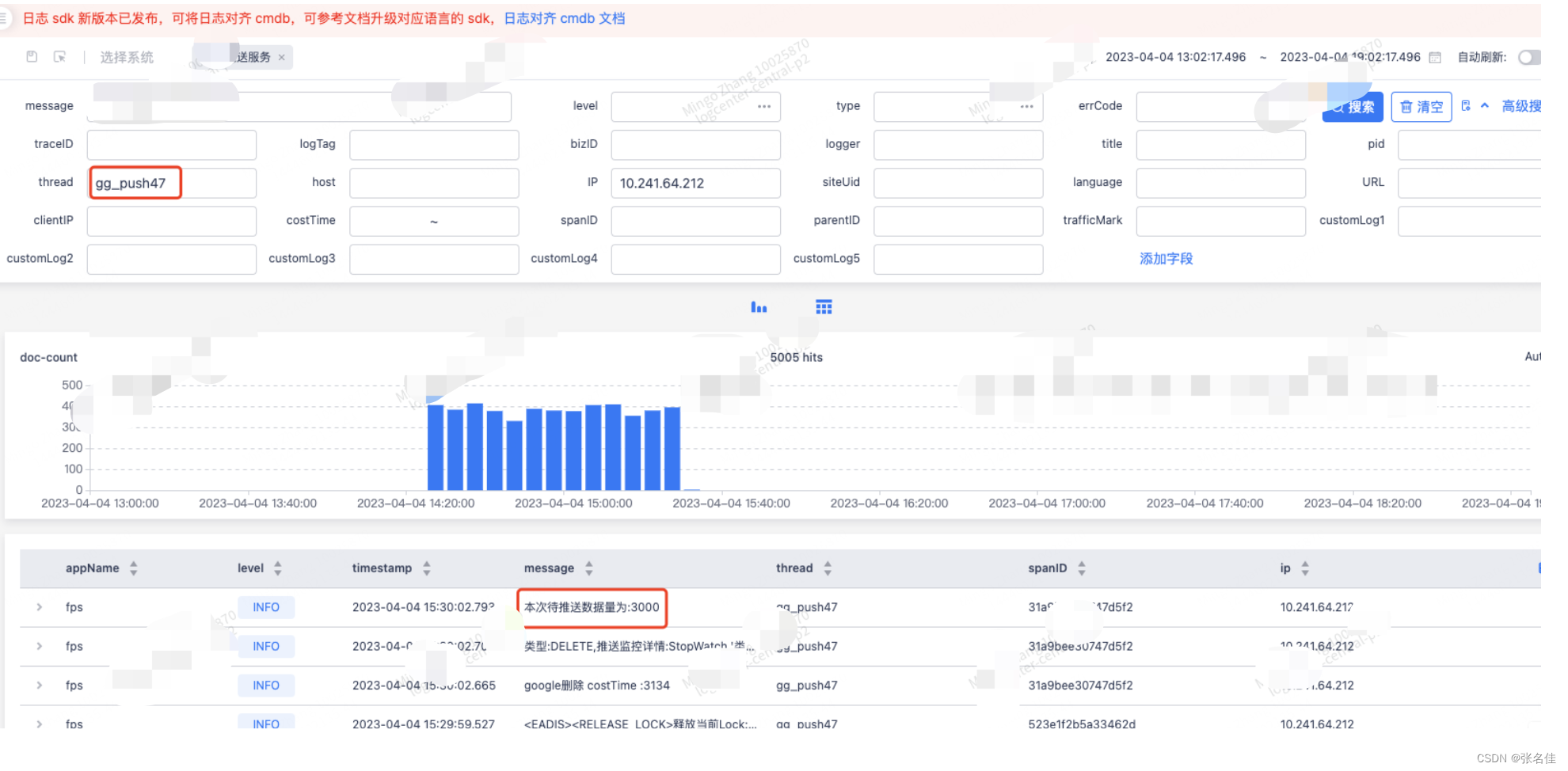
日志系统显示下午的15:30,google的推送线程(gg_push_47)捞取了数据打了日志就卡住了,初步怀疑线程夯死
2.确认线程夯死
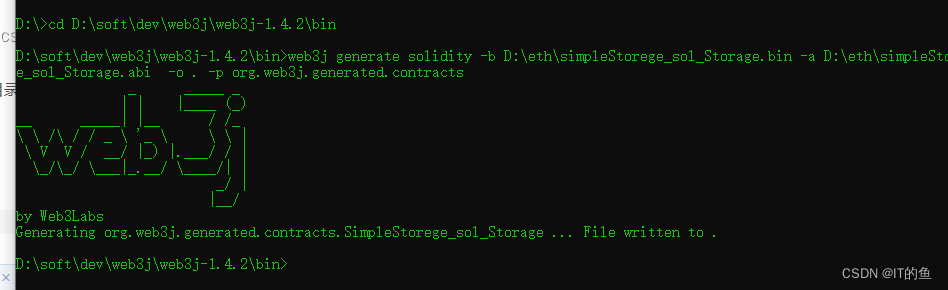
于是根据ip找到了具体的pod,以及里面的自主排障里的Arthas控制台,查询到了线程处于TIMED_WAITING,注意我配图的Arthas线程已经不是当时的线程了(gg_push_47),因为当时忘记截图了,所以随手找了一个,用来代表线程当时的状态

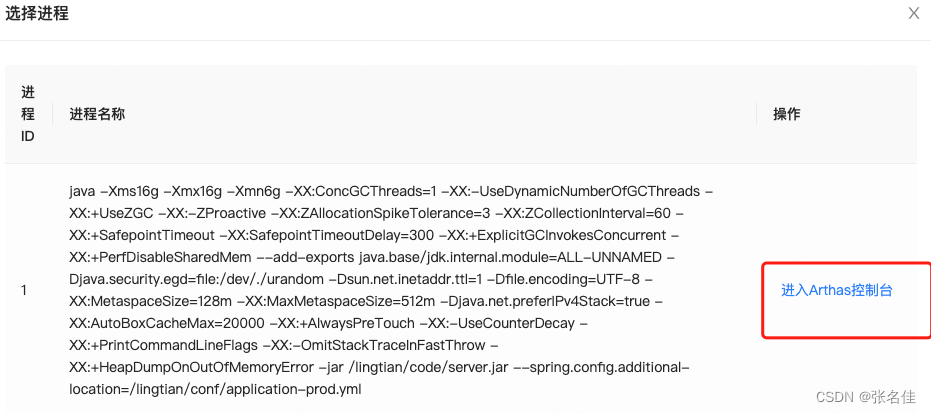
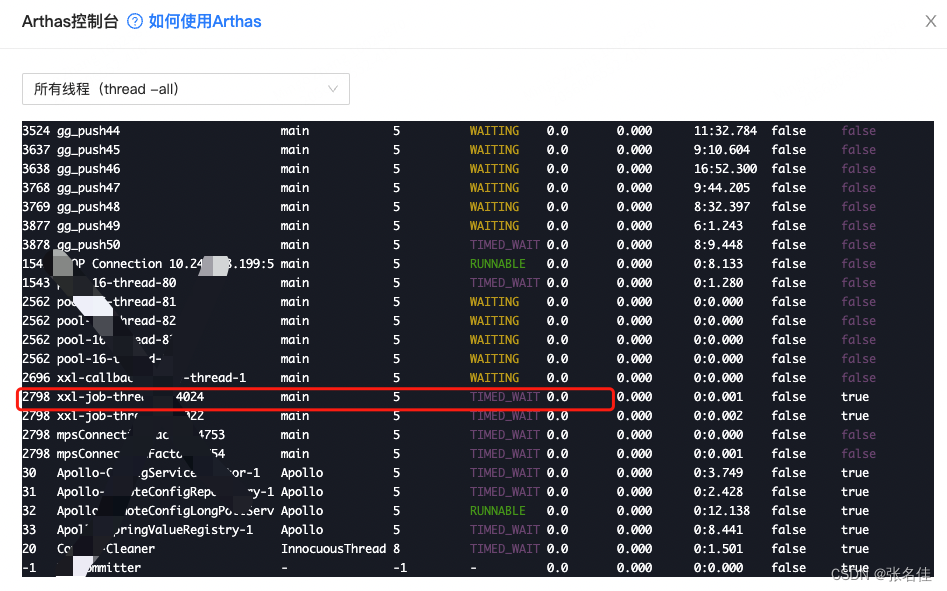
3.排查夯死原因
问题已经定位到了,于是找到了运维打了jstack日志(因为我没服务器权限。。。)可以看到gg_push_47夯死在了jedis的一个lock操作上面,而最后一次业务当法则是getToken
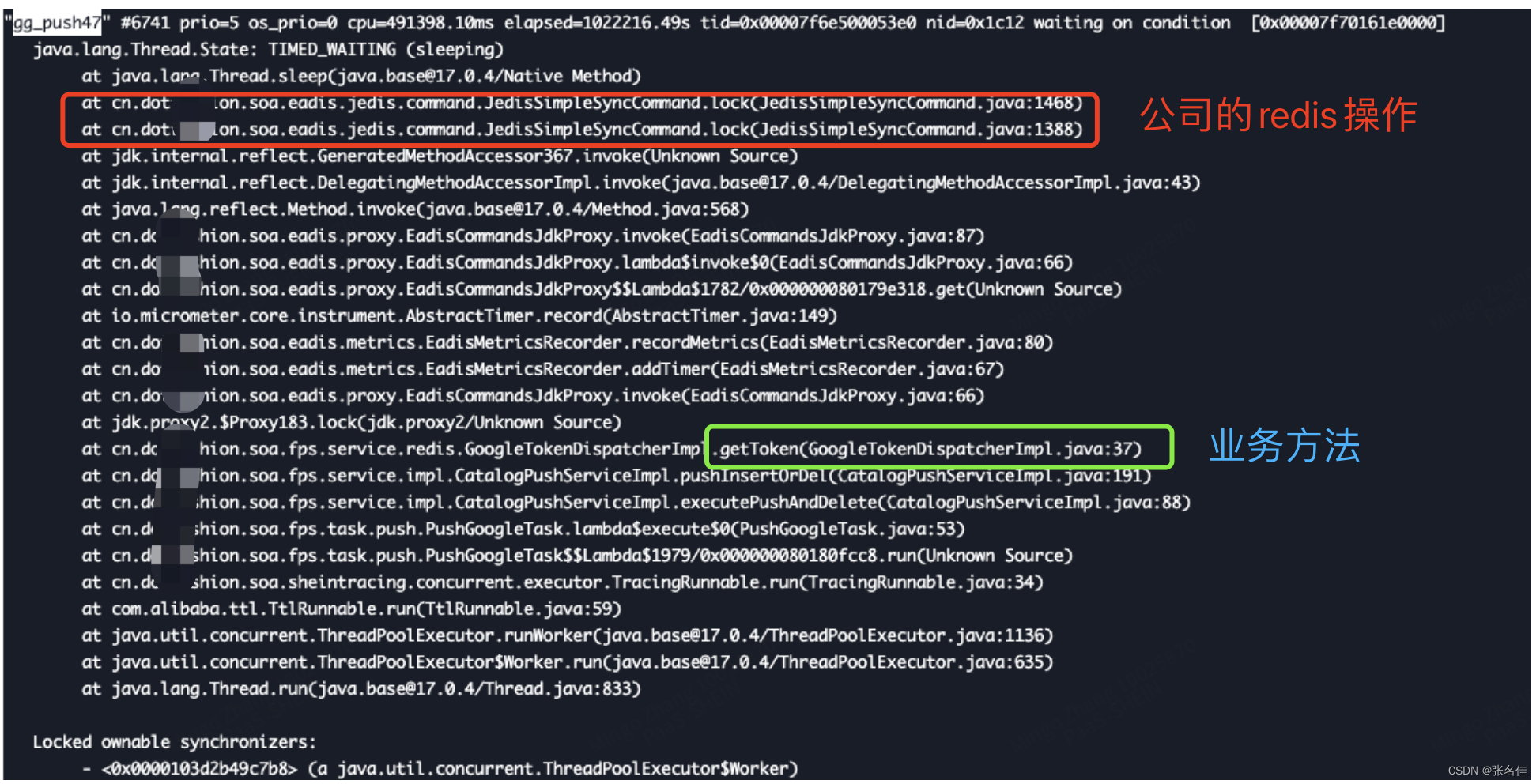
getToken中恰好也存在利用公司架构封装的redis使用的分布式锁,于是我们看看.getToken操作redis
到底做了啥

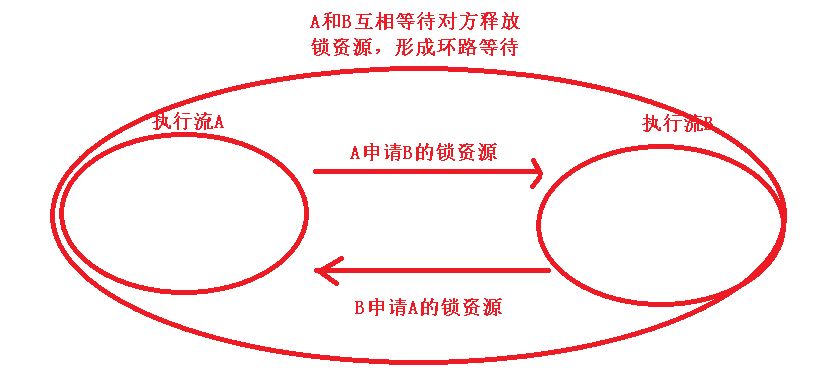
到这里其实原因就很清晰了,lock这个方法设置的锁,锁持有超时和锁等待时间都是-1,也就是永久
那么假设A线程调用 getToken但是由于释放锁的时候出现了redis超时的问题,也就是finally这段代码异常了,那么A线程由于锁永远持有,所以B线程(gg_push_47)由于设置的锁等待时间是-1,那么B线程虽然获取不到锁,但是也会永远等待,导致了线程的夯死
4.结论
分布式锁一定要设置锁超时和锁等待时间,如果不确定时间的值,那么可采用看门狗机制,我这里是维护之前的代码,没办法。。都是坑啊
二:网络请求不设置超时时间导致的线程夯死
问题的发生是小伙伴又和我说线上的数据推送任务不推送了,不过这次从google换成了facebook,tm的分布式锁搞定了啊,而且facebook没用分布式锁,设置任何JUC到LOCK都没,怎么可能会被夯死呢,这时候小伙伴又说重启吧,但是我又一次上头了,于是再次踏上排查之路。。。
1.确认线程夯死
有了上次的经验我直接拿到了停止推送的线程,发现不同于上次的等待这次一直处于runnable状态
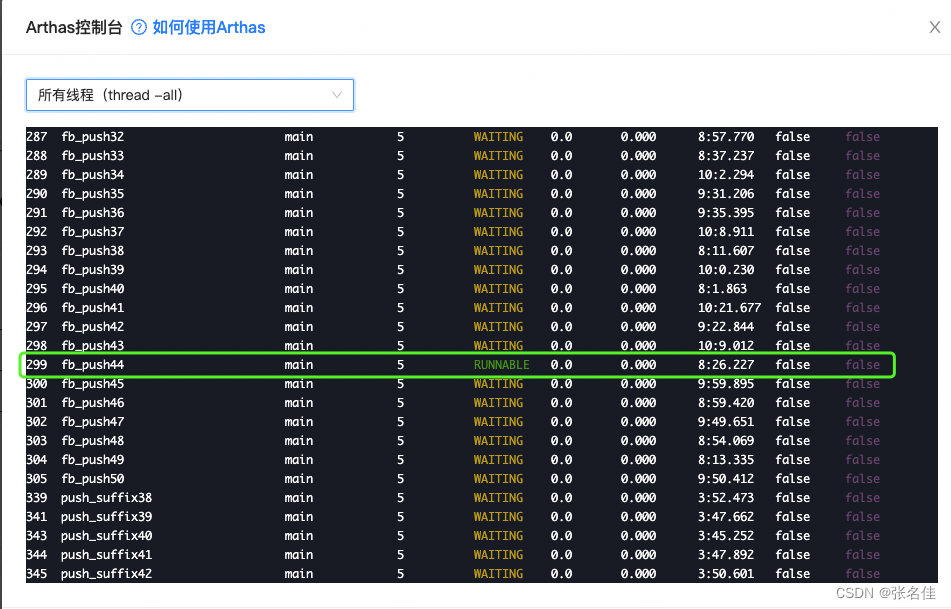
2.排查夯死原因
于是又找到了运维打了jstack日志(运维累了。。。)可以看到fb_push_44夯死在fb的网络请求中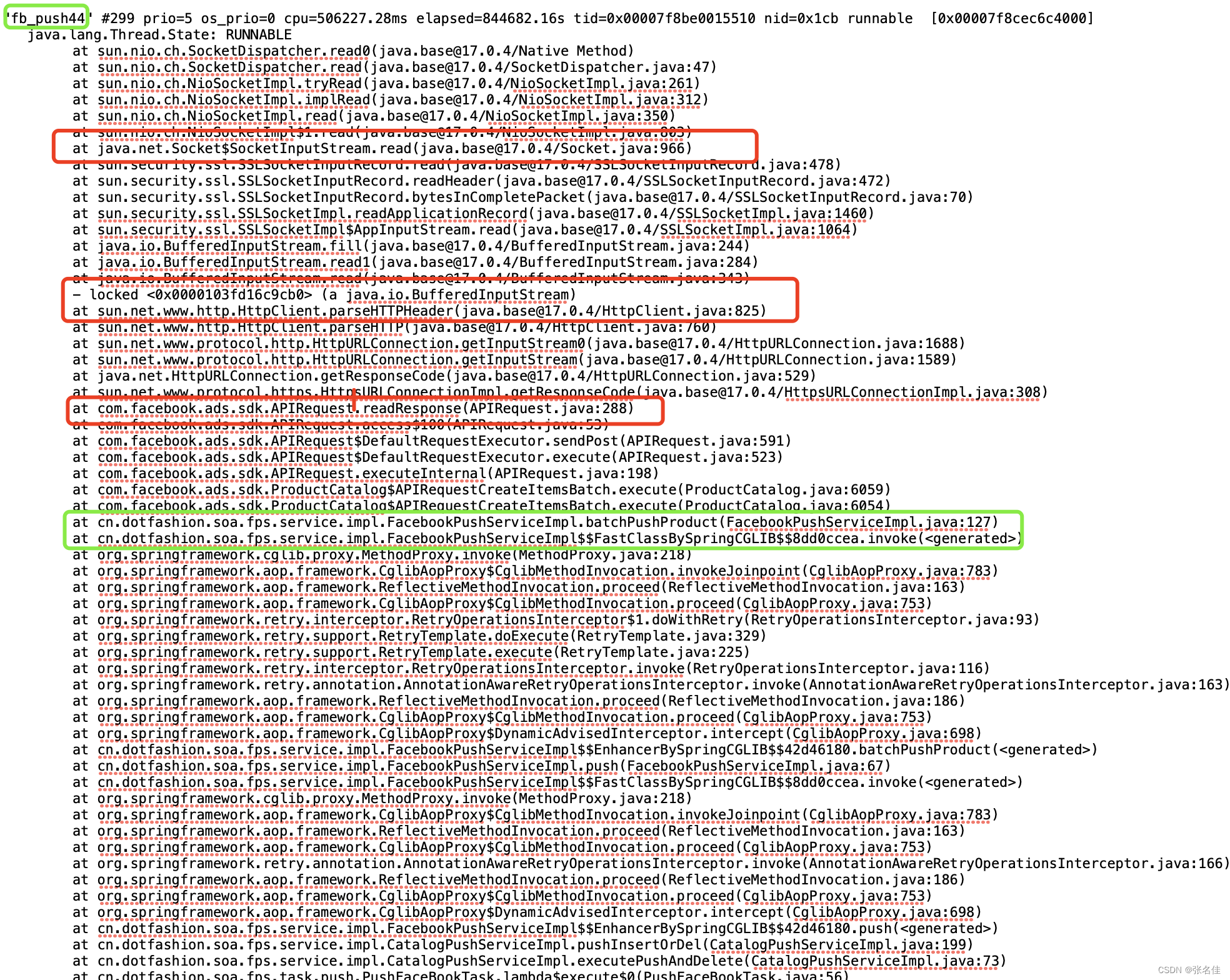
绿色的是我的最后一次交互业务代码,红色的为facebook-sdk封装的网络请求的api,可以发现问题出现在读取respose,初步怀疑是没有设置超时时间,于是我看了一下源码发现真的没有设置超时时间
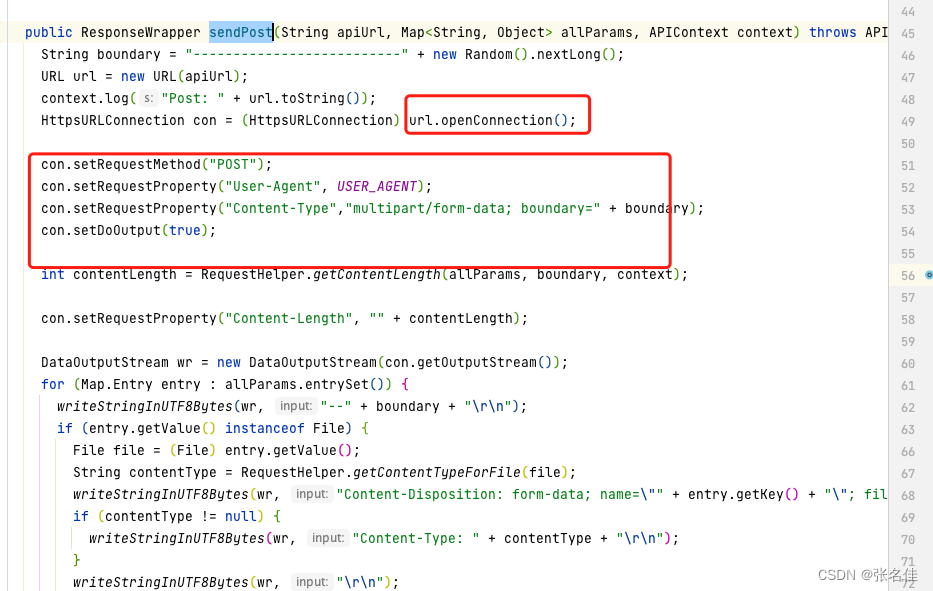
1.发现连接对象是HttpsURLConnection,set方法并为设置任何超时时间参数,去看看具体的的属性有无默认值
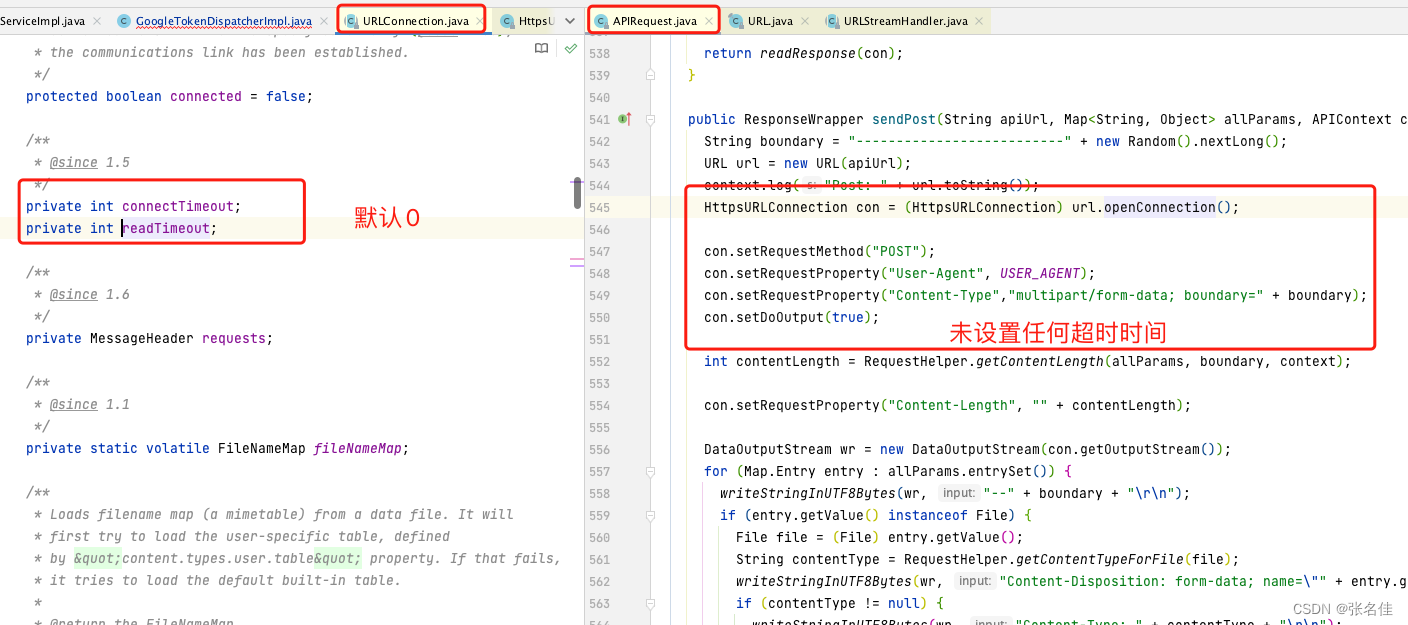
2.发现JDK提供的HttpsURLConnection初始化时间都是0,即永不超时,而SDK中也为设置,所以也就导致了线程夯死
3.结论
任务网络请求,一定要设置超时时间,否则就是坑啊。。。