题目:市场营销中资源分配问题的直接异质因果学习
Direct Heterogeneous Causal Learning for Resource Allocation Problems in Marketing
论文链接:https://export.arxiv.org/pdf/2211.15728v2.pdf

摘要:资源分配是市场营销中一类重要的决策问题,机器学习(Machine Learning,ML)+运筹优化(Operation Research,OR)的两阶段方式是此类问题最常见的解决方案。其中,ML阶段预估影响决策的因素,其预估结果输入到OR阶段进行优化问题的求解。然而,这种解耦的方案设计引入两个问题:ML阶段的模型只关注参数预估的准确性,而没有考虑下游OR阶段对预估参数的使用方式及最终的优化目标;OR阶段也忽略了ML阶段中模型预估的误差,其优化算法中复杂的数学运算会对模型误差进一步放大。为了解决上述问题,论文提出通过对OR算法进行分析与推导,进而引入决策因子(可以通过简单比较直接得到决策结果的因子),来建立ML与OR之间的联系。在ML阶段,通过设计自定义的损失函数,对个体的决策因子进行直接学习,从而获得无偏估计并输入到OR阶段,而后对其执行排序或比较操作获取最终的决策结果,以避免在OR阶段引入额外误差。论文应用上述框架解决了市场营销中二元营销动作的选择问题和多元营销动作的预算分配等问题,在公开数据集和外卖营销实际场景上的实验表明了该方法的有效性。
介绍
营销是提高用户粘性和平台收益的最有效机制之一。因此,各种各样的营销活动被广泛地运用在许多网络平台上。例如,freshppo中易腐产品的降价被用来促进销售(Hua et al. 2021),淘宝交易中的优惠券可以刺激用户活动(Zhang et al. 2021),快手视频平台中的激励措施可以提高用户留存率(Ai et al. 2022)。
尽管增加了收益,但营销活动也会消耗大量的营销资源(如预算)。因此,由于数量有限,只有部分个人(如商店或商品)可以被分配营销待遇。在市场营销中,这样的决策问题可以表述为资源分配问题,并且已经被研究了几十年。
现有研究大多采用两阶段方法来解决这些问题(Ai et al. 2022;Zhao等。2019;Du, Lee和Ghaffarizadeh 2019)。如图1(a)所示,第一个阶段为ML,通过predictive/uplift模型预测不同处理下个体的(增量)响应。第二阶段是OR,将ML中的预测结果作为组合优化算法的输入。因此,现有工作主要集中在预测/隆起建模的解耦优化和组合优化方面。
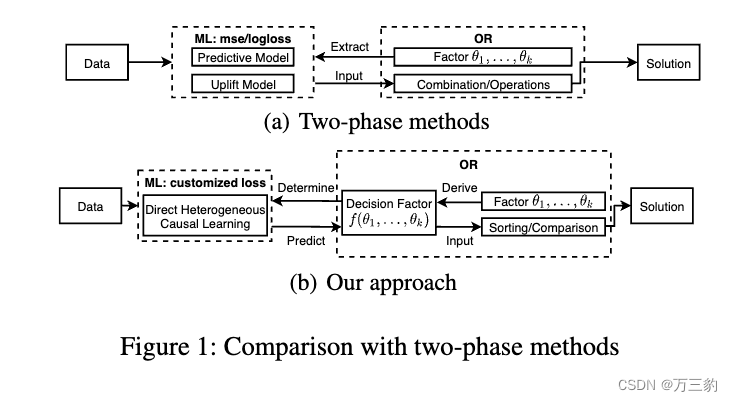
两相法虽然应用广泛,但存在两个主要缺陷。第一种是在ML中对预测结果进行多次中间计算后得到解,例如在or中多因子组合或复杂的数学运算。因此,预测参数精度的提高可能与最终解不存在正相关关系。二是模型预测的误差没有得到尊重,在OR中对预测结果进行复杂的操作导致累积误差增加。由于累积误差的存在,OR中的理论最优算法并不总能达到实际最优,在某些情况下甚至不如启发式策略。因此,该解耦优化为ML和OR不能对原始问题进行全局优化。
我们提出了一种解决资源分配问题的新方法,而不是两阶段方法,以缓解上述缺陷。首先,我们将算法的决策因子定义为仅通过排序或比较操作就可以直接获得解的因子。如图1(b)所示,我们将由OR推导出的决策因子作为学习目标,在ML中进行直接异质因果学习。根据该定义,在OR中对预测结果没有可选的数学运算。因此,一个模型在决策因子上的排名表现直接决定了解的质量,改进模型可以保证更好的解。具体来说,模型误差可以用来衡量排名表现,在OR中得到尊重而不被放大。因此,新的挑战是如何在OR中识别这样一个决策因素,以及如何在ML中对其进行直接预测。
根据这一思路,我们研究了市场营销中的两个关键问题。第一个是二元处理分配问题。在忽略治疗所产生的费用(不考虑费用的版本)时,可将条件平均治疗效果(CATE)视为决策因素。用于预测CATE的常见提升模型包括元学习者(K unzel et al. 2019;Nie and Wager 2021)和因果森林(Wager and Athey 2018;Athey, Tibshirani, and Wager 2019)。前者由多个基模型组成,后者通常将广义随机森林(GRF)和双机器学习(DML)方法相结合。与之不同的是,我们提出了一种新的基于神经网络的隆升模型进行直接预测,该模型在理论和实践上都取得了良好的效果。尽管增加了收入,治疗也会产生不同的成本。在这个成本意识的版本中,可以将个人的ROI (Return on Investment)视为决策因素,由增量收入和增量成本之分来计算。然而,现有的因果推断工作大多不涉及治疗费用,无法适用于这种直接的预测。虽然一些作品(Du, Lee, and Ghaffarizadeh 2019)研究了类似的问题,但理论上它们的损失函数不能收敛到稳定的极值点。在本文中,我们设计了一个凸损失函数,以保证在损失收敛时对个体的投资回报率的无偏估计。
作为第二个案例研究,我们将我们的方法应用于具有多重处理的预算分配问题,并在本文中提出了一个新的评估指标。拉格朗日对偶是解决预算分配问题的一种有效算法。然而,该算法的决策因子包含拉格朗日乘数,它是不确定的,并且随着预算的不同而变化很大。用所有可能的拉格朗日乘数直接预测这样的决策因素是困难和不现实的。本文提出了一种拉格朗日对偶方法的等效算法,该算法中的决定因子是确定的,与拉格朗日乘子无关。此外,本文还建立了相应的因果学习模型。当自定义损失函数收敛时,可以得到对决策因子的直接预测。最后,我们还提出了一种新的评价指标MT-AUCC来估计预测结果,该指标类似于隆起下面积曲线(Area Under Uplift Curve, AUUC) (Rzepakowski和Jaroszewicz 2010),但涉及多个处理和增量成本。
大规模模拟和在线A/B测试验证了我们方法的有效性。在离线模拟中,我们使用了从在线广告/送餐平台的随机对照试验(RCT)中收集的两个真实数据集。多项评估指标和在线AB测试表明,我们的模型和算法取得了显著的改进,与最先进的技术相比,目标奖励平均提高了10%以上。
相关工作
两阶段的方法
机器学习(ML)和运筹学(OR)的结合是解决资源分配问题最常用的方法之一,本文称之为两阶段方法。在第一阶段,设计了隆升模型来预测不同处理下个体的增量响应。除了元学习器(K unzel et al. 2019;Nie and Wager 2021)和因果森林(Wager and Athey 2018;Athey, Tibshirani, and Wager 2019;Zhao, Fang, and Simchi-Levi 2017;Ai等人,2022),表征学习(Johansson, Shalit, and Sontag 2016;沙利特,约翰逊,桑塔格2017;Yao et al. 2018)也用于隆起建模。一些工作(Betlei, Diemert, and Amini 2021;Kuusisto et al. 2014)提出了一个统一的学习框架来对CATE进行排名。拉格朗日对偶作为最有效的算法之一,在第二阶段经常被用于解决许多不同领域的决策问题。例如,它是为了解决营销中的预算分配问题而开发的(Du, Lee, and Ghaffarizadeh 2019;Ai et al. 2022;Zhao et al. 2019),并计算在线广告中的最优竞价策略(Hao et al. 2020)。
直接学习方法
策略学习和强化学习是直接学习治疗分配策略而不是治疗效果的两种重要方法,避免了ML和OR的结合。基于双稳健估计器(Athey and Wager 2021),提出了使用观测数据进行政策学习的一般框架,并将其工作扩展到多行动政策学习(Zhou, Athey, and Wager 2022)。作为现实世界的应用,工作(Xiao et al. 2019;Zhang et al. 2021)将序列激励营销中的优惠券分配问题表述为约束马尔可夫决策过程,并提出了强化学习来解决该问题。然而,所有上述方法都通过使用拉格朗日乘法器将资源约束移到奖励函数中。因此,模型可能需要随着拉格朗日乘子的变化而不断变化。
决策导向学习(DFL)
与我们的动机类似,DFL致力于根据下游优化任务学习模型参数,而不是预测精度。然而,许多现有的作品DFL要求决策变量的可行区域是固定的,并且确定地已知(Wilder, Dilkina, and Tambe 2019;Elmachtoub和Grigas 2022;Shah等人,2022;Mandi et al. 2022)。与我们最相关的工作可能是Donti、Amos和Kolter 2017年的工作,他们解决了一个包含概率和确定性约束的随机优化问题。然而,这项工作假设决策变量是连续的,并通过拉格朗日对偶来处理概率约束,这与我们的研究明显不同。
二元处理分配问题
不考虑费用的治疗分配问题
成本意识治疗分配问题
多重治疗的预算分配问题
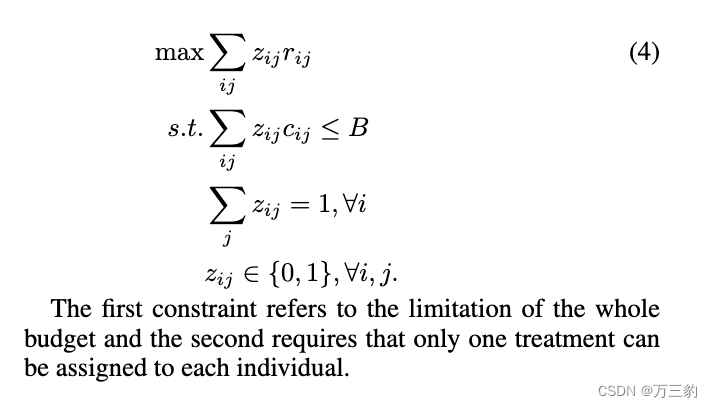 评估
评估
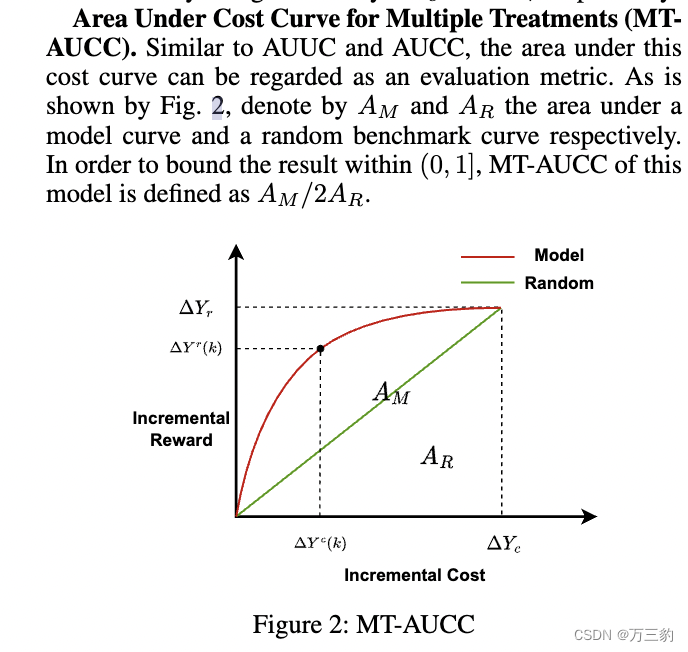
虽然已经开发了AUUC(隆起曲线下面积)和AUCC(成本曲线下面积)(Du, Lee, and Ghaffarizadeh 2019)来分别评估不含/含处理成本的隆起模型的排名性能,但没有用于估计不同处理下边际效用(' ij)的评价指标。后者直接关系到MTBAP的经营目标。为此,本文提出了一种新的评价指标MT-AUCC (Area Under Cost Curve for Multiple treatment)
评价
离线仿真

结论
本文提出了一种基于决策因子的资源分配问题求解方法。将其作为学习目标,可以避免对预测结果进行替代数学运算。这一思想解决了市场营销中的两个关键问题,在理论和实践上都有很大的优势。大规模的离线模拟和在线AB测试验证了该方法的有效性。我们未来的工作将集中于这种方法在更复杂的营销场景中的应用。例如,多个营销活动可能同时进行,并相互作用。因此,在这种情况下推导决策因子并进行直接的异质因果学习更具挑战性。