Redis数据备份与恢复

文章目录
- Redis数据备份与恢复
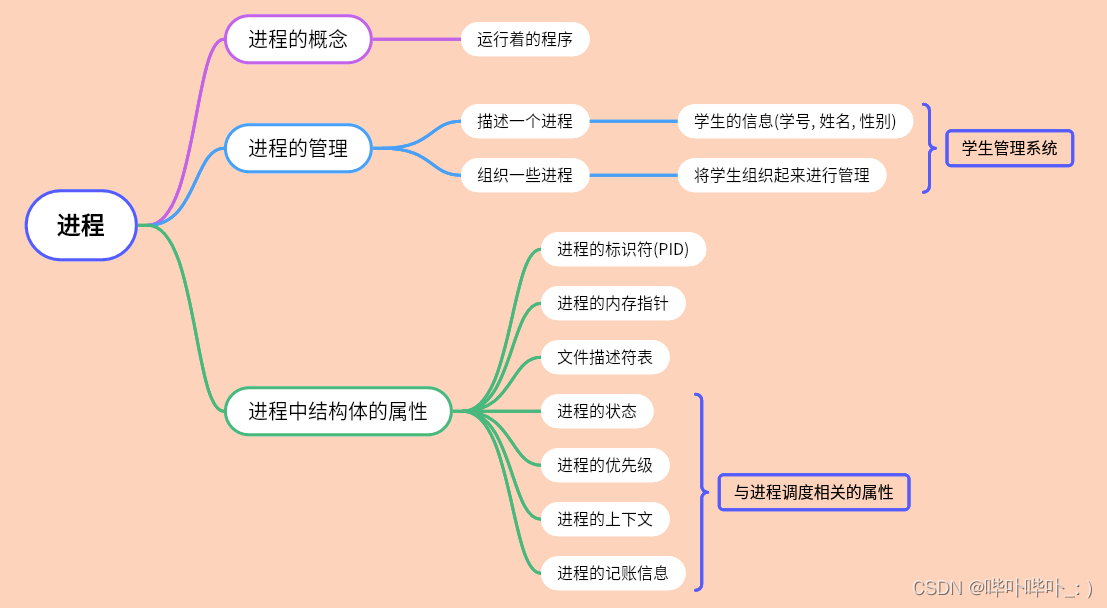
- 1. Redis备份的方式
- 2. RDB持久化
- 2.1 什么是RDB?
- 2.2 Fork操作
- 2.3 save VS bgsave
- 2.4 关于RDB备份的一些配置项
- 2.5 RDB的备份与恢复
- 2.6 RDB的自动触发
- 2.7 RDB的优势与劣势
- 3. AOF持久化
- 3.1 什么是AOF?
- 3.2 AOF的启动/恢复/修复
- 3.3 AOF同步频率设置
- 3.4 AOF重写机制(Rewrite压缩)
- 3.4.1 如何实现重写
- 3.4.2 何时重写
- 3.4.3 AOF重写流程
- 3.4.4 AOF持久化流程
- 3.4.5 AOF的优势与劣势
1. Redis备份的方式
Redis所有的数据都是保存在内存中, 但可以定期通过异步的方式将数据保存到磁盘上,这种方式叫半持久化RDB(Redis DataBase)模式。还有一种方式是保存每一次的数据变化(增量保存),是全持久化AOF(Append Only File)模式。
2. RDB持久化
2.1 什么是RDB?
RDB:在指定的时间间隔内将内存中的数据集快照写入磁盘,即snapshot快照,恢复时也是直接将快照文件读到内存中。
这个备份过程是如何实现的呢?
Redis会单独创建(fork)一个子进程来进行持久化,会先把数据写入到一个临时文件中,待持久化过程都结束后,再用这个临时文件替换上一个持久化完成的文件,即上一个快照文件。如果需要进行大规模数据的恢复,且对于数据恢复的完整性不是特别敏感,那么RDB的方式就比AOF的方式更加高效,RDB的一个缺点就是最后一次持久化的数据可能会丢失。
2.2 Fork操作
- Fork操作的作用是复制一个与当前进程一样的进程。新进程的所有数据(变量、环境变量、程序计数器等)都和原进程一致,但是是一个全新的进程,并作为原进程的子进程。
- 在Linux系统下,fork()会产生一个和父进程完全相同的子进程,但子进程此后都会进行exec系统调用,影响效率。基于此,Linux中引入了写时复制(Copy On Write)技术。
- 一般而言,父进程和子进程会共用段物理内存,只有进程空间的段内容要发生变化时,才会把父进程修改的内容复制一份给子进程。
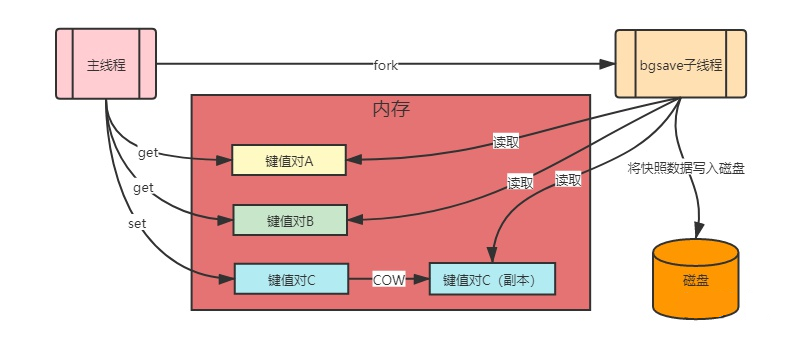
由上图可以清晰地看到,Redis进行bgsave时,会先fork出一个子进程。子进程和父进程共享段内存,当主进程对键值对C的内容进行修改时,Linux会利用写时复制技术,为子进程复制出键值对C副本,子进程在向磁盘中写入快照文件时会读取该副本内容。
2.3 save VS bgsave
- save:save时只管保存,其它不管,这会导致Redis主进程全部堵塞,无法响应客户端的请求,禁用。
- bgsave:Redis会在后台异步进行快照操作,快照操作的同时,主进程还可以响应客户端请求。可以通过lastsave命令获取最后一次成功快照的时间。
有一点需要注意,虽然bgsave操作不会阻塞主进程,但是fork操作会阻塞主进程,频繁地进行快照同样会对Redis性能造成很大的影响。
2.4 关于RDB备份的一些配置项
-
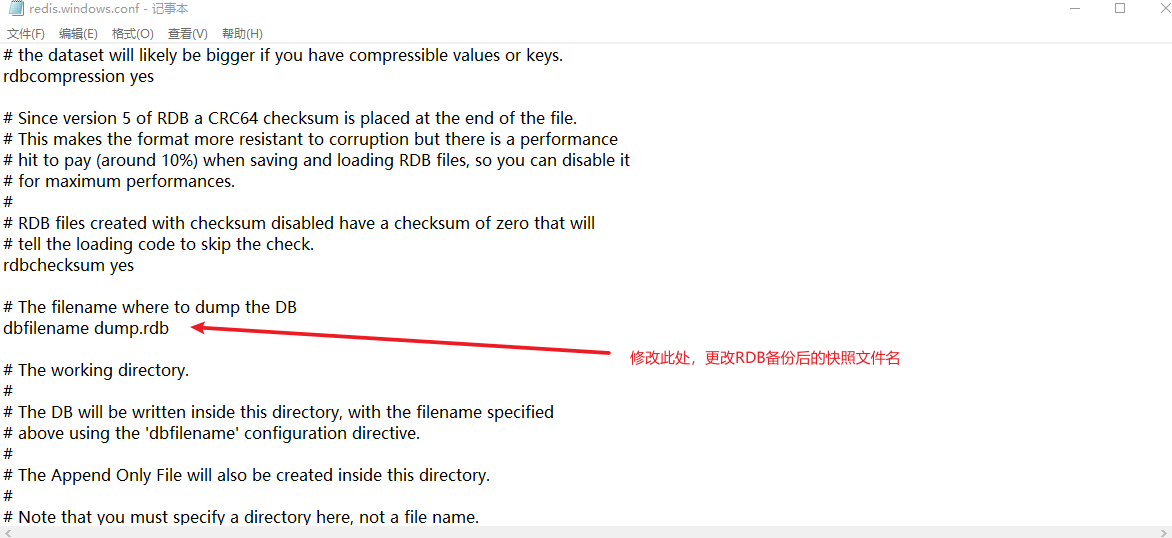
dbfilename
通常,RDB备份后产生的快照文件名为dump.rdb,这个可以在redis.windows.conf中进行修改,如下所示:
-
stop-writes-on-bgsave-error
当Redis无法写入磁盘时,服务器会直接关掉Redis的写操作,默认为Yes,推荐开启。 -
rdbcompression
对于存储到磁盘中的快照,可以设置是否进行压缩存储。如果该选项为yes,Redis会采用LZF算法进行压缩。
如果不想消耗CPU进行压缩,也可以选择设置为no。 -
rdbchecksum检查完整性
在快照存储后,可以让Redis使用CRC64算法进行数据校验,但是这样做会增加约10%的性能消耗。如果希望得到最大的性能提升,可以关闭,推荐开启。
2.5 RDB的备份与恢复
- 先通过config get dir指令查询rdb文件的目录
- 关闭redis服务
- 将备份的快照文件(如dump.rdb)拷贝到查询出来的目录下
- 启动Redis,备份的快照数据将会被直接加载
2.6 RDB的自动触发
- 在redis.windows.conf中通过配置save 修改自动触发的时机。这条命令表示在seconds时间间隔内,触发了changes次修改,就会自动触发bgsave命令生成RDB快照文件。如save 1 400表示如果在1s内发生了400次修改,就会自动触发bgsave操作。
- 主从复制时,当从节点从主节点进行全量复制时,会触发bgsave操作。主节点会生成快照文件并发送到从节点去。
- 执行debug reload命令重新加载Redis时会触发bgsave命令。
- 默认情况下执行shutdown命令时,如果没有开启AOF持久化,会触发bgsave命令。
2.7 RDB的优势与劣势
优势:
- 适合大规模的数据恢复
- 效率高,对数据完整性和一致性要求不高的场景可以直接使用
- 节省磁盘空间,恢复速度快
劣势:
- 虽然Linux使用写时复制技术,让子进程和父进程共享内存空间,只在写入的时候为子进程拷贝一份数据。但是当数据量庞大的时候,这个过程还是非常消耗性能。
- 在备份周期一段时间内做一次备份,如果在这个过程中Redis出现了意外宕机,那么最后一次快照数据就会丢失。
3. AOF持久化
3.1 什么是AOF?
AOF即以日志的形式来记录每个操作(增量保存),将Redis执行过的所有写指令记录下来(读操作不记录),只许追加文件但不允许改写文件。
在Redis启动处会读取该文件重新构建数据,也就是Redis重启时会根据日志的内容将写指令从头到尾执行一次已完成数据恢复工作。
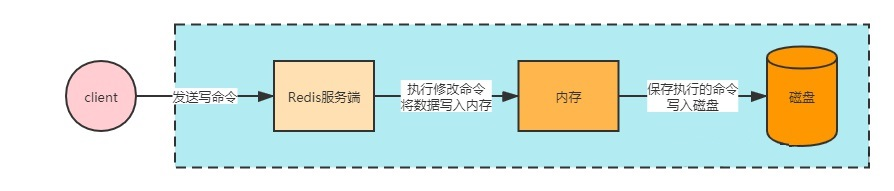
注意,AOF默认不开启,可在配置文件中将appendonly改成yes去开启,同时备份的文件名也可以进行修改,如下图所示:

3.2 AOF的启动/恢复/修复
AOF的备份机制和性能虽然和RDB不同,但是备份和恢复的操作同RDB一样,都是拷贝备份文件,需要恢复时再拷贝备份文件到Redis工作目录下,启动Redis服务后会自动进行加载。
正常恢复:
- 修改redis.windows.conf中的appendonly no,改为yes
- 将有数据的aof文件复制一份到对应目录(利用config get dir查看目录)
- 重启Redis重新加载即可自动恢复数据
异常恢复:
- 修改redis.windows.conf中的appendonly no,改为yes
- 如遇到AOF文件损坏,通过redis-check-aof --fix appendonly.aof进行恢复
- 备份写坏的AOF文件
- 重启Redis重新加载数据
3.3 AOF同步频率设置
AOF同步频率设置有三个选项,分别为always,everysec,no
- appendfsync always: 始终同步,每次Redis的写入操作执行完毕后都会立刻记入日志;性能较差但数据完整性比较好
- appendfsync everysec: 每秒同步,每秒将写操作记入日志一次,如果Redis出现意外宕机,本秒的数据可能丢失
- appendfsync no: Redis不主动同步,把同步的时机交给操作系统。如果Redis出现意外宕机,会丢失大量数据
3.4 AOF重写机制(Rewrite压缩)
AOF采用文件追加方式,文件会越来越大,而且AOF文件越大,恢复的时间就越长。AOF增加了重写机制,当AOF文件的大小超过所设定的阈值后,Redis就会启动AOF的文件内容压缩,只保留可以恢复数据的最小指令集,也可以使用指令bgrewriteaof。
3.4.1 如何实现重写
AOF文件持续增长而过大时,会fork出一条新进程来将文件进行重写(先写临时文件最后再rename的方式);redis4.0后的重写,就是把rdb的快照,以二进制的形式附在新的aof头部,作为已有的历史数据,从而替换掉原先的写操作。
3.4.2 何时重写
Redis会记录上一次重写的AOF大小,默认配置时当AOF文件大小时上次rewrite后大小的已被且大于64M时触发。
重写虽然可以节约大量的磁盘空间,减少回复时间。但是每次的重写还是有一定负担的,因此Redis要满足一定的条件才会进行重写。
auto-aof-rewrite-percentage:设置重写的基准值,假设为x%,文件超过x%时才开始重写。
auto-aof-rewrite-min-size:设置重写的最小值,当AOF文件大小达到这个值且满足条件才能重写。
假设上次重写后AOF文件的大小为base_size,则满足以下式子时Redis才会进行AOF文件重写:
AOF当前大小 ≥ base_size * (1 + auto-aof-rewrite-percentage)
s.t. AOF当前大小 ≥ auto-aof-rewrite-min-size
3.4.3 AOF重写流程
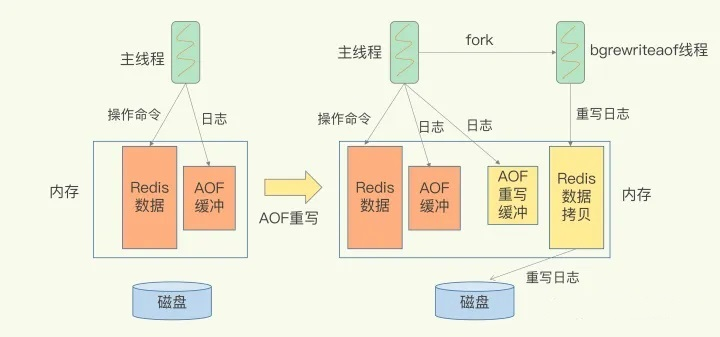
- bgrewriteaof触发重写,首先判断当前是否有bgsave或bgrewriteaof在运行,如果有,则等待该命令结束后再继续执行
- 主进程fork出子进程执行重写操作,保证主进程不会被阻塞
- 子进程遍历Redis内存中的数据到临时文件。为了保证重写阶段新的写操作也被记录,此时客户端的写请求会同时写入到aof_buf缓冲区和aof_rewrite_buf重写缓冲区,保证原AOF文件的完整以及新AOF文件生成期间新的数据修改动作不会丢失
- 子进程写完AOF文件后,向主进程发信号,主进程统计信息
- 主进程把aof_rewrite_buf中的数据写入到新的AOF文件
- 使用新的AOF文件覆盖旧的AOF文件,完成AOF重写
3.4.4 AOF持久化流程
- 客户端的请求写命令会被追加到AOF缓冲区内
- AOF缓冲区根据AOF持久化策略【always、everysec、no】将操作同步到磁盘的AOF文件中
- AOF文件大小超过重写策略或手动重写时,会对AOF文件进行rewrite,压缩AOF文件的容量
- Redis服务启动时,会重新加载AOF文件中的写操作以达到数据恢复的目的
3.4.5 AOF的优势与劣势
优势:
- 备份机制更文件,丢失数据概率更低
- 可读的日志文本,通过操作AOF文件,可以处理误操作
劣势:
- 比起RDB方式而言,AOF占用更多的磁盘空间
- 恢复备份速度更慢
- 每次读写都同步的话,有一定的性能压力
- 存在个别bug会导致恢复问题
AOF和RDB同时开启,Redis恢复哪个?
AOF和RDB同时开启,Redis默认取AOF的数据(数据不会存在丢失)。