系列文章目录
文章目录
- 系列文章目录
- 前言
- 一、概述
- 二、GPU架构基础
- 2.1 GPU概述
- 2.2 GPU的架构
- 2.3 自主查询GPU相关信息
- 三、CUDA编程概念
- 3.1 CUDA线程模型
- 3.1 线程层次结构
- 1.引入库
- 2.读入数据
- 总结
- 参考文献
前言
GPU作为机器学习的基础运算设备,基本上是无人不知无人不晓。可是你真的知道GPU的运行逻辑么?你真的会用GPU么?本文提供了GPU结构的背景知识、操作的执行方式以及深度学习操作的常见限制。
一、概述
在推理特定层或神经网络使用给定 GPU 的效率时,理解 GPU 执行的基础知识很有帮助。本文将介绍:
1. GPU的基本结构(GPU架构基础)
2. 操作如何划分和并行执行(GPU 执行模型)
3. 如何用算术强度估计性能限制(了解性能)
4. 松散的深度学习操作类别和往往适用于每个类别的性能限制(DNN 操作类别)
二、GPU架构基础
2.1 GPU概述
GPU(Graphics Processing Unit),又称显示核心、视觉处理器、显示芯片,是一种专门在个人电脑、工作站、游戏机和一些移动设备(如平板电脑、智能手机等)上做图像和图形相关运算工作的微处理器。
我们通常所说的显卡,实际上是由GPU和显存共同构成的。

图1.某显卡内部结构
总有人会用CPU和GPU进行对比。事实上,在同等的价格和功耗范围内 ,GPU 能够提供比 CPU 高得多的指令吞吐量和内存带宽,这使得许多应用可以利用这些优势在 GPU 上获得远超 CPU 的运算性能。
GPU 和 CPU 之间的这种能力差异之所以存在,是因为它们的设计目标不同:
- CPU 旨在以尽可能快的速度执行
一系列线程,并且具有并行执行几十个这样线程的能力;- GPU 则旨在尽可能多的并行执行
数千个线程(通过将更多的晶体管用于数据处理而不是数据缓存和流量控制,尽可能摊销,使数千个较慢的单线程能实现更大的数据吞吐量)。
图 1 显示了 CPU 与 GPU 的芯片资源分布示例,可以看出GPU的运算核心数目是远远超过CPU的。

图1. CPU 与 GPU 整体架构对比
2.2 GPU的架构
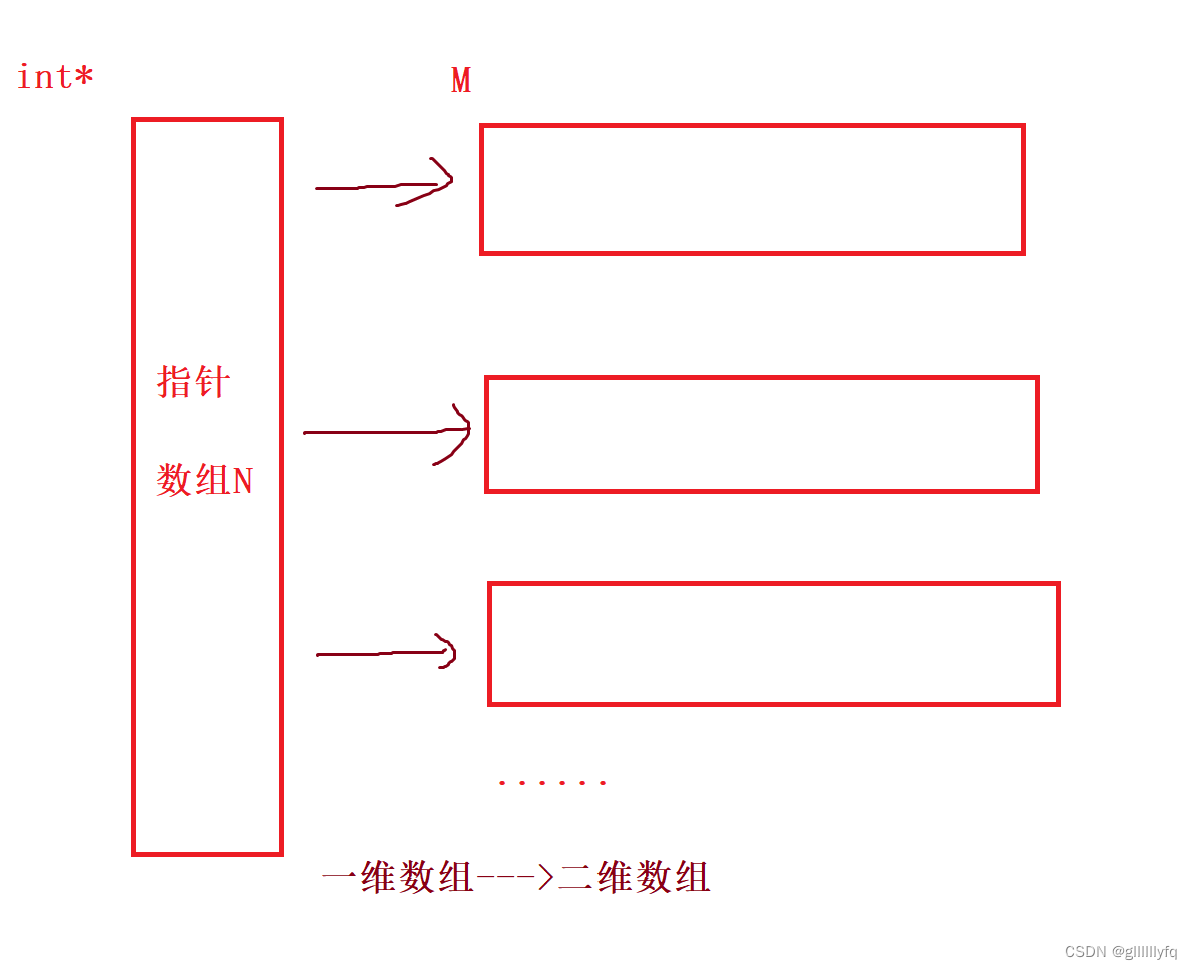
GPU主要由运算单元和层级存储结构(若干级存储器)组成。宏观上来说,NVIDIA GPU 由多个流式多处理器 SMs (Streaming Multiprocessors) 、片上 L2 缓存 (on-chip L2 cache) 和高带宽 DRAM (high-bandwidth DRAM) 组成。算术和其他指令由 SM 执行,数据和代码通过 L2 缓存从 DRAM 读取,如图2所示:

图2. GPU 架构简化视图
每个 SM 都有自己的指令调度器和各种指令执行流水线。作为现代神经网络中最频繁的操作,乘、加两种运算扮演了FC层和CONV层构建块的角色,二者都可以视为向量点积的集合。
下表显示了 NVIDIA 最近的 GPU 架构上针对每个 SM 单位时钟内的乘加运算数量。每个乘加包括两个操作,因此可以将表中的吞吐量乘以 2 以获得每个时钟的 FLOP 计数。再将这些乘以 SM 的数量和 SM 时钟速率可以获得 GPU 的 FLOPS 速率:
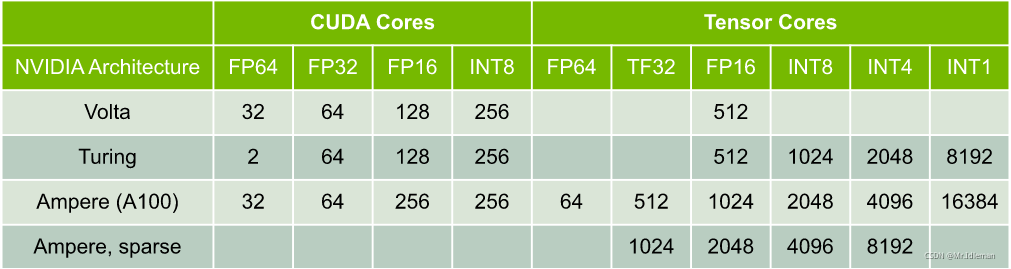
图3.每个 SM 单位时钟内的乘加运算数量
如图3所示, FP16 操作可以在 Tensor Cores 或 CUDA Cores 中执行。此外,图灵架构可以在 Tensor Cores 或 CUDA Cores 中执行 INT8 操作。
Tensor Cores 在 Volta GPU 架构中被引入,以加速机器学习和科学应用中的矩阵乘法和累加运算。这些指令对小矩阵块(例如,4x4 块)进行操作。注意,Tensor Cores 可以以比输入更高的精度计算和累加乘积。例如,在使用 FP16 输入进行训练期间,Tensor Cores 可以在不损失精度的情况下计算乘积并以 FP32 进行累加。而当数学运算不能用矩阵块来表述时,它们会在 CUDA Cores中执行。例如,2个半精度浮点型(FP16)张量的元素相加将由 CUDA Cores 执行,而不是由 Tensor Cores 执行。
2.3 自主查询GPU相关信息
在Linux上,Nvidia 的 CUDA 默认自带nvidia-smi指令来查询GPU有关信息:

图4.使用 nvidia-smi 指令查询 GPU 信息 但使用上述指令输出的结果是不含核心等信息的,这里如果我们需要查看相关信息,可以调用pycuda的driver模块查看,代码如下: |
import pycuda.autoinit
import pycuda.driver as cuda
(free,total)=cuda.mem_get_info()
print("Global memory occupancy:%f%% free"%(free*100/total))
for devicenum in range(cuda.Device.count()):
device=cuda.Device(devicenum)
attrs=device.get_attributes()
#Beyond this point is just pretty printing
print("\n===Attributes for device %d: "%devicenum + str(device.name()))
for (key,value) in attrs.items():
print(str(key)+':'+f"\033[1;31m{str(value)}\033[0m")
输出结果如图所示:
Global memory occupancy:98.432977% free
===Attributes for device 0: Tesla P100-PCIE-16GB
ASYNC_ENGINE_COUNT:2
CAN_MAP_HOST_MEMORY:1
CLOCK_RATE:1328500
COMPUTE_CAPABILITY_MAJOR:6
COMPUTE_CAPABILITY_MINOR:0
COMPUTE_MODE:DEFAULT
CONCURRENT_KERNELS:1
ECC_ENABLED:1
GLOBAL_L1_CACHE_SUPPORTED:1
GLOBAL_MEMORY_BUS_WIDTH:4096
GPU_OVERLAP:1
INTEGRATED:0
KERNEL_EXEC_TIMEOUT:0
L2_CACHE_SIZE:4194304
LOCAL_L1_CACHE_SUPPORTED:1
MANAGED_MEMORY:1
MAXIMUM_SURFACE1D_LAYERED_LAYERS:2048
MAXIMUM_SURFACE1D_LAYERED_WIDTH:32768
MAXIMUM_SURFACE1D_WIDTH:32768
MAXIMUM_SURFACE2D_HEIGHT:65536
MAXIMUM_SURFACE2D_LAYERED_HEIGHT:32768
MAXIMUM_SURFACE2D_LAYERED_LAYERS:2048
MAXIMUM_SURFACE2D_LAYERED_WIDTH:32768
MAXIMUM_SURFACE2D_WIDTH:131072
MAXIMUM_SURFACE3D_DEPTH:16384
MAXIMUM_SURFACE3D_HEIGHT:16384
MAXIMUM_SURFACE3D_WIDTH:16384
MAXIMUM_SURFACECUBEMAP_LAYERED_LAYERS:2046
MAXIMUM_SURFACECUBEMAP_LAYERED_WIDTH:32768
MAXIMUM_SURFACECUBEMAP_WIDTH:32768
MAXIMUM_TEXTURE1D_LAYERED_LAYERS:2048
MAXIMUM_TEXTURE1D_LAYERED_WIDTH:32768
MAXIMUM_TEXTURE1D_LINEAR_WIDTH:268435456
MAXIMUM_TEXTURE1D_MIPMAPPED_WIDTH:16384
MAXIMUM_TEXTURE1D_WIDTH:131072
MAXIMUM_TEXTURE2D_ARRAY_HEIGHT:32768
MAXIMUM_TEXTURE2D_ARRAY_NUMSLICES:2048
MAXIMUM_TEXTURE2D_ARRAY_WIDTH:32768
MAXIMUM_TEXTURE2D_GATHER_HEIGHT:32768
MAXIMUM_TEXTURE2D_GATHER_WIDTH:32768
MAXIMUM_TEXTURE2D_HEIGHT:65536
MAXIMUM_TEXTURE2D_LINEAR_HEIGHT:65000
MAXIMUM_TEXTURE2D_LINEAR_PITCH:2097120
MAXIMUM_TEXTURE2D_LINEAR_WIDTH:131072
MAXIMUM_TEXTURE2D_MIPMAPPED_HEIGHT:32768
MAXIMUM_TEXTURE2D_MIPMAPPED_WIDTH:32768
MAXIMUM_TEXTURE2D_WIDTH:131072
MAXIMUM_TEXTURE3D_DEPTH:16384
MAXIMUM_TEXTURE3D_DEPTH_ALTERNATE:32768
MAXIMUM_TEXTURE3D_HEIGHT:16384
MAXIMUM_TEXTURE3D_HEIGHT_ALTERNATE:8192
MAXIMUM_TEXTURE3D_WIDTH:16384
MAXIMUM_TEXTURE3D_WIDTH_ALTERNATE:8192
MAXIMUM_TEXTURECUBEMAP_LAYERED_LAYERS:2046
MAXIMUM_TEXTURECUBEMAP_LAYERED_WIDTH:32768
MAXIMUM_TEXTURECUBEMAP_WIDTH:32768
MAX_BLOCK_DIM_X:1024
MAX_BLOCK_DIM_Y:1024
MAX_BLOCK_DIM_Z:64
MAX_GRID_DIM_X:2147483647
MAX_GRID_DIM_Y:65535
MAX_GRID_DIM_Z:65535
MAX_PITCH:2147483647
MAX_REGISTERS_PER_BLOCK:65536
MAX_REGISTERS_PER_MULTIPROCESSOR:65536
MAX_SHARED_MEMORY_PER_BLOCK:49152
MAX_SHARED_MEMORY_PER_MULTIPROCESSOR:65536
MAX_THREADS_PER_BLOCK:1024
MAX_THREADS_PER_MULTIPROCESSOR:2048
MEMORY_CLOCK_RATE:715000
MULTIPROCESSOR_COUNT:56
MULTI_GPU_BOARD:0
MULTI_GPU_BOARD_GROUP_ID:0
PCI_BUS_ID:0
PCI_DEVICE_ID:4
PCI_DOMAIN_ID:0
STREAM_PRIORITIES_SUPPORTED:1
SURFACE_ALIGNMENT:512
TCC_DRIVER:0
TEXTURE_ALIGNMENT:512
TEXTURE_PITCH_ALIGNMENT:32
TOTAL_CONSTANT_MEMORY:65536
UNIFIED_ADDRESSING:1
WARP_SIZE:32
这里我们可以重点关注到:
第3行:该GPU型号为 Tesla P100-PCIE-16GB GPU;第17行:该 GPU 的 L2_CACHE 大小为 4194304 Bytes;第74行:该 GPU 的多处理器(SM)数量为 56 个;第71行、72行:该 GPU 的平均块最大线程数和平均多处理器最大线程数分别是1024和2048。
三、CUDA编程概念
3.1 CUDA线程模型
CUDA的线程模型结构如下图所示,分别包括Thread(单个线程)、Thread Block(线程块)、Grid(线程网格)、Kernel(核心):
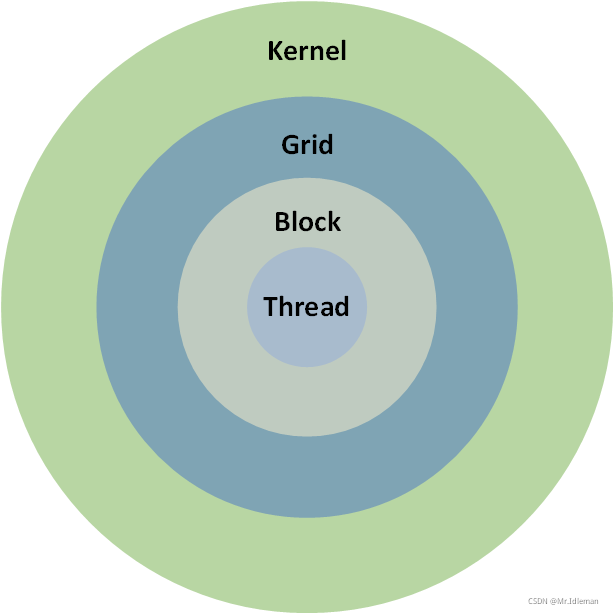
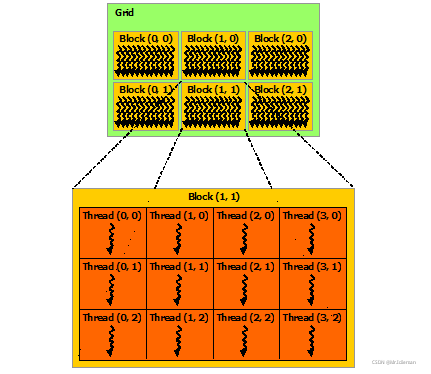
图5. 线程块网络
每个Thread和Block都有自己的ID,这样我们就可以通过ID找到对应的线程和线程块。
- Thread:线程。并行的基本单位
- Thread Block:线程块,互相合作的线程组。
线程块有如下几个特点:
a. 允许彼此同步
b. 可以通过共享内存快速交换数据
c. 以1维、2维或3维组织- Grid:一组线程块。
a. 以1维、2维组织
b. 共享全局内存- Kernel:在GPU上执行的核心程序,这个kernel函数是运行在某个Grid上的。
One kernel ⇔ \Harr ⇔ One Grid
3.1 线程层次结构
1.引入库
代码如下(示例):
import pycuda.autoinit
import pycuda.driver as cuda
(free,total)=cuda.mem_get_info()
print("Global memory occupancy:%f%% free"%(free*100/total))
for devicenum in range(cuda.Device.count()):
device=cuda.Device(devicenum)
attrs=device.get_attributes()
#Beyond this point is just pretty printing
print("\n===Attributes for device %d: "%devicenum + str(device.name()))
for (key,value) in attrs.items():
print(str(key)+':'+f"\033[1;31m{str(value)}\033[0m")
2.读入数据
代码如下(示例):
data = pd.read_csv(
'https://labfile.oss.aliyuncs.com/courses/1283/adult.data.csv')
print(data.head())
该处使用的url网络请求的数据。
总结
提示:这里对文章进行总结:
例如:以上就是今天要讲的内容,本文仅仅简单介绍了pandas的使用,而pandas提供了大量能使我们快速便捷地处理数据的函数和方法。
参考文献
- NVIDIA Developer Guide:GPU Performance Background User Guide
- NVIDIA Developer Guide:NVIDIA CUDNN Documentation
- NVIDIA Developer Guide:CUDA TOOLKIT Documentation
- NVIDIA Datasheet: Volta-Architecture-Whitepaper
- NVIDIA Datasheet: Turing-Architecture-Whitepaper
- 知乎:【CUDA教程】一、认识cuda
- 知乎:NVIDIA GPU的一些解析(一)
- 知乎:NVIDIA GPU 架构梳理
- 知乎:请问英伟达GPU的tensor core和cuda core是什么区别?
- 百度百科:图形处理器
- CSDN:CUDA 编程概念简介,NVIDIA GPU显卡