目录
一、离线任务平台定义
二、实际开发那种的实现方式分析
三、企业应用与链接分享
(一)具体企业应用举例
(二)离线任务平台相关文章和论文链接
四、开源代码库参考
一、离线任务平台定义
离线任务平台通常是指一种基于云计算或分布式计算技术,用于处理批量离线数据的计算平台。它可以自动化地执行一系列离线数据处理任务,如数据清洗、数据转换、数据分析、机器学习模型训练等。离线任务平台通常包括数据存储、数据处理和数据输出三个主要组件。在离线任务平台上,用户可以定义和配置数据处理任务,然后提交任务并等待任务完成。任务完成后,用户可以从输出目录中获取结果数据。
离线任务平台在数据处理和数据分析领域广泛应用,尤其是在大数据场景下,它可以大大提高数据处理的效率和准确性。常见的离线任务平台包括Apache Hadoop、Apache Spark、Amazon EMR等。
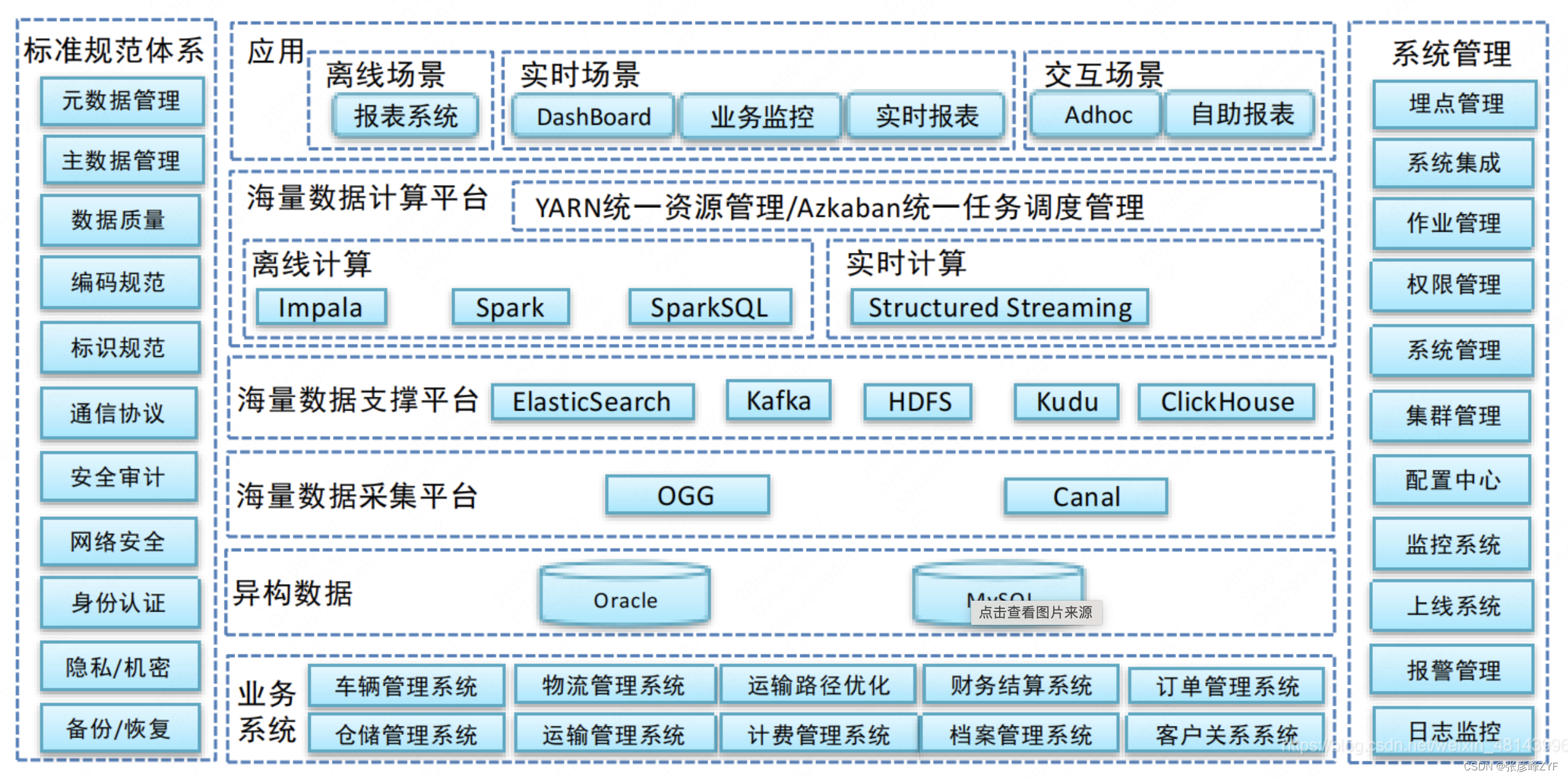
在业务应用中,离线任务平台通常指一种数据处理平台,用于对大规模离线数据进行处理和分析,以便于业务决策和优化。离线任务平台可以接收多种数据源,如数据仓库、数据库、数据湖等,并可以对这些数据进行清洗、转换、聚合、统计和挖掘等处理操作,以生成新的业务数据和洞察。离线任务平台通常具有可扩展性、容错性、高可用性、高性能和灵活性等特点,能够适应不同的数据处理场景和业务需求。
在具体业务应用中,离线任务平台可以用于很多场景,如电商网站的用户行为分析、金融公司的风险管理、医疗健康领域的疾病监测和预测等。离线任务平台可以根据具体业务需求进行定制化开发和部署,同时也可以基于已有的数据处理框架和工具进行快速构建和上线。通过离线任务平台,企业可以更好地了解和把握业务数据,从而优化业务流程和提高业务效益。
二、实际开发那种的实现方式分析
离线任务平台的实现通常需要基于分布式计算和云计算技术,并结合一些数据处理框架和工具。下面是一般的实现方式:
- 数据存储:离线任务平台需要一个稳定可靠的数据存储系统,通常包括数据仓库、数据库、数据湖等。这些数据存储系统可以用于存储原始数据、清洗后的数据、处理中间结果和最终输出数据等。
- 数据处理:离线任务平台通常需要使用一些数据处理框架和工具,如Apache Hadoop、Apache Spark等。这些工具可以用于数据清洗、转换、聚合、统计、挖掘等操作。通过这些工具,可以构建出适合特定业务场景的数据处理流程。
- 分布式计算:离线任务平台需要基于分布式计算技术,将数据处理任务划分为多个子任务,并在多个计算节点上并行执行。通过分布式计算,可以提高数据处理的效率和可靠性。
- 任务调度:离线任务平台需要一个任务调度系统,用于管理和调度各个任务的执行。任务调度系统可以根据不同的任务依赖关系和优先级,自动分配计算资源,保证任务按照预期的顺序和时间完成。
- 可视化工具:离线任务平台通常需要提供可视化的数据展示和分析工具,以便于用户查看和分析任务的输出结果。这些可视化工具可以提供图表、报表、仪表盘等形式的数据展示和分析。
总之,离线任务平台的实现需要综合运用分布式计算、云计算和数据处理技术,并结合具体的业务需求进行定制化开发和部署。
三、企业应用与链接分享
离线任务平台在企业中的应用非常广泛。
(一)具体企业应用举例
- 阿里巴巴:阿里巴巴使用自己开发的MaxCompute离线数据处理平台进行数据处理和分析。MaxCompute提供了海量数据的存储和计算能力,可以处理TB、PB级别的数据。阿里巴巴的很多业务,如淘宝、支付宝、阿里云等,都在使用MaxCompute平台进行数据分析和处理。
- 美团:美团使用Apache Hadoop和Apache Spark等分布式计算和数据处理工具,搭建了自己的离线任务平台。美团的很多业务,如外卖、酒店、电影等,都在使用离线任务平台进行数据分析和处理。
- 字节跳动:字节跳动使用自己开发的Bytedance Data平台进行数据处理和分析。Bytedance Data平台可以支持PB级别的数据处理和存储,并提供了多种数据处理工具,如Apache Hadoop、Apache Flink等。
- 百度:百度使用自己开发的PaddlePaddle平台进行机器学习模型训练和推理。PaddlePaddle平台提供了多种机器学习算法和工具,支持海量数据的训练和推理。
- 推特:推特使用自己开发的Scalding和Summingbird等工具进行数据处理和分析。这些工具可以帮助推特对大量的社交网络数据进行清洗、聚合和分析。
- 脸书:脸书使用Apache Hadoop和Apache Hive等工具进行数据处理和分析。这些工具可以帮助脸书对大量的用户行为数据进行清洗、聚合和分析。
总之,离线任务平台在企业中的应用非常广泛,不同企业根据具体的业务需求和数据处理场景,选择不同的数据处理框架和工具,并进行定制化开发和部署。
(二)离线任务平台相关文章和论文链接
- 阿里巴巴MaxCompute平台:《MaxCompute: A High-Performance Large-Scale Data Computing Platform》
链接:https://www.usenix.org/system/files/conference/nsdi13/nsdi13-final170_update.pdf - 美团离线任务平台:《从数据处理到机器学习,美团的技术全景图谱》
链接:404 Page not found - 美团技术团队 - 字节跳动Bytedance Data平台:《Bytedance Data Platform》
链接:Proceedings of the VLDB Endowment - 百度PaddlePaddle平台:《PaddlePaddle: An Open-Source Platform for Deep Learning》
链接:https://www.usenix.org/system/files/conference/atc17/atc17-guo.pdf - 推特Scalding和Summingbird工具:《Scalding: A Scala Library for Hadoop MapReduce》和《Summingbird: A Framework for Integrating Batch and Online MapReduce Computations》
链接:Towards complex actions for complex event processing | Proceedings of the 7th ACM international conference on Distributed event-based systems 和 https://www.usenix.org/system/files/conference/nsdi14/nsdi14-paper-kulkarni.pdf - 脸书Hadoop和Hive工具:《Apache Hadoop Goes Realtime at Facebook》和《Hive: A Warehousing Solution Over a Map-Reduce Framework》
链接:https://www.usenix.org/system/files/conference/osdi10/osdi10-final-115.pdf 和 Proceedings of the VLDB Endowment
四、开源代码库参考
一些常见的离线任务平台及其对应的开源代码库:
- Apache Hadoop: 这是一个开源的分布式计算平台,支持批处理、流处理和交互式查询等多种数据处理模式。Hadoop的代码可以在Apache官网上获取:Apache Hadoop
- Apache Spark: 这是一个快速、通用的分布式计算引擎,支持批处理、流处理、机器学习和图计算等多种数据处理模式。Spark的代码可以在Apache官网上获取:Apache Spark™ - Unified Engine for large-scale data analytics
- Apache Flink: 这是一个开源的分布式流处理和批处理计算引擎,支持低延迟和高吞吐量的实时数据处理。Flink的代码可以在Apache官网上获取:Apache Flink® — Stateful Computations over Data Streams | Apache Flink
- Apache Beam: 这是一个开源的统一的分布式计算模型,支持批处理和流处理等多种数据处理模式。Beam的代码可以在Apache官网上获取:https://beam.apache.org/
- Apache Storm: 这是一个开源的分布式实时计算系统,支持高吞吐量和低延迟的实时数据处理。Storm的代码可以在Apache官网上获取:Apache Storm
- Apache Kylin: 这是一个开源的分布式分析引擎,支持快速的交互式SQL查询和OLAP分析。Kylin的代码可以在Apache官网上获取:Apache Kylin | Analytical Data Warehouse for Big Data
- Alibaba Blink: 这是一个开源的流批一体化计算引擎,支持流处理、批处理和交互式查询等多种数据处理模式。Blink的代码可以在GitHub上获取:https://github.com/alibaba/blink
- Tencent TDSQL: 这是一个开源的分布式SQL引擎,支持PB级别的数据处理和多维度的数据分析。TDSQL的代码可以在GitHub上获取:https://github.com/Tencent/TDSQL
这些平台的代码库中包含了各种组件和工具,可以帮助用户构建和管理自己的离线任务平台。用户可以根据自己的需求和场景选择适合自己的平台和工具,或者基于这些代码库进行二次开发和定制。