编者按:本文主要介绍了科学的演变历史,从笛卡尔到生成式人工智能。文章探讨了数学在验证科学原理中的作用,并介绍了新机器学习工具如何验证新的科学。
文中提到,将生成式人工智能与Excel或iPhone进行比较是低估了这一新技术的潜在影响。生成型人工智能的效果很可能相当于电学(electricity)或香农的信息论(Shannon’s Information Theory)。
Generative AI will be a Superpower!
作者 | Robert Hacker
编译 | 岳扬
认为科学意味着可观察和可重复的实验的观点,始于17世纪的笛卡尔,目前这种观点在某种程度上已经结束了。
相比之下,全球共识(Global understanding) 是基于由知识基础设施(knowledge infrastructure) 支持的计算模型(computational models) 。
——[英] 尼古拉斯·米尔佐夫《如何观看世界》
阿拉伯数字使得数字能够很容易地被操作,这就导致数学能够作为验证科学的工具使用。 事实上,科学史也可以说就是新数学(new mathematics)验证科学中新的基本原理的历史。如今我们有一套新的“数学”工具,即过去五年中人工智能(AI)和机器学习(ML)的成果。这种新的机器学习(ML)真的不是仅仅关于生成文本或艺术作品,而是关于在一个比我们以前探索过的更基本的水平上验证新的科学。写此篇文章的目的就是为了谈论新的机器学习(ML)工具验证新的科学这一话题。
现代科学始于牛顿和笛卡尔的研究成果。牛顿让我们对物理学最初有了一个准确的了解,他也被认为是发展微积分的功臣。这种物理科学和数学的结合至今仍在影响着研究,特别是在工程和物理学中应用偏微分方程的多变量问题。 笛卡尔因使用代数来解释几何学而备受赞誉,一个几何形状可以通过一系列的方程(代数)来解释,其中可以用坐标定位一个点,点决定线,线决定平面和形状。这种代数方法支持了笛卡尔的科学观点——即认为科学是从宏观到微观层面对有形事物的自上而下的检查,关注物质、结构和线性、确定性的因果关系。不出所料,笛卡尔除了研究数学和科学之外,还是一位经验主义哲学家(empiricist philosopher)。他的“自然”哲学在接下来的两百年里一直影响着科学,直到今天。
科学的下一个重大进展是量子理论。量子物理学的大部分基础是建立在新的数学上。首先,路德维希·玻尔兹曼(Ludwig Boltzmann)给我们提供了统计力学,将概率和不确定性引入物理科学的研究中。麦克斯韦、庞加莱、海森堡、薛定谔、玻尔、普朗克和爱因斯坦都在玻尔兹曼的工作基础上使用数学。让我们产生对世界的新理解,当然这个理解建立在以概率方式运行的亚原子、不可见粒子上。我们不可能离笛卡尔的自然哲学有多远。科学现在专注于不可见的东西。幸运的是,数学和科学的下一个突破,即混沌理论(Chaos Theory) ,帮助我们将量子物理学的不确定性与我们每天看到的自然世界联系起来。
1972年,麻省理工学院教授爱德华·洛伦兹(Edward Lorenz)提出了确定性混沌的概念。IBM的研究员Benoît Mandelbrot推进了Lorenz的工作,建立了“自然界中模式形成的数学基础(a mathematical basis of pattern formation in nature)”[1],并证明了确定性的、对初始条件敏感的非线性系统(SDIC)可以在计算机上建模。曼德尔布罗特(Mandelbrot)不仅解释了自然科学中以前几乎不为人所知的一部分,而且他引入了 “分形(fractals)” 的概念来解释在整个自然界中不断重复的模式。随着这些模式的记录,数学变得很容易,并且计算机化极大地促进了对气象学、地质学和生物学等领域的混沌现象建模的进一步研究。无论笛卡尔的形而上学和认识论在量子物理学之后还留下了什么,混沌理论展示了对自然模式的新理解,展示了数学去解释以前无法解释的科学的另一种方式。混沌理论也证明了一个或许更重要的观点,科学可以通过应用计算机建模来寻找系统中的模式来理解。科学对系统的这种关注后来被应用到另一类系统——复杂性科学。
1984年,诺贝尔物理学奖得主默里·盖尔曼(Murray Gell-Mann)与一批杰出的科学家和学者一起成立了圣塔菲研究所(Santa Fe Institute)来探索复杂系统(complex systems)。盖尔曼解释了复杂性,“我们应该寻找的是如今出现的、高度跨学科的伟大综合科学”盖尔曼说。[2]其中一些已经走上了成功的道路,如:分子生物学、非线性科学、认知科学。但他说,肯定还有其他新兴的科学,建立这个新的研究所的目的就是寻找它们。与混沌系统(chaotic systems)相比,复杂系统(complex systems)不是确定性(deterministic)的,如下图所示。确定性系统表现出“独特的演化(unique evolution)”,即“模型的给定状态总是跟随着相同的状态转换历史(a given state of a model is always followed by the same history of state transitions)”。[3]
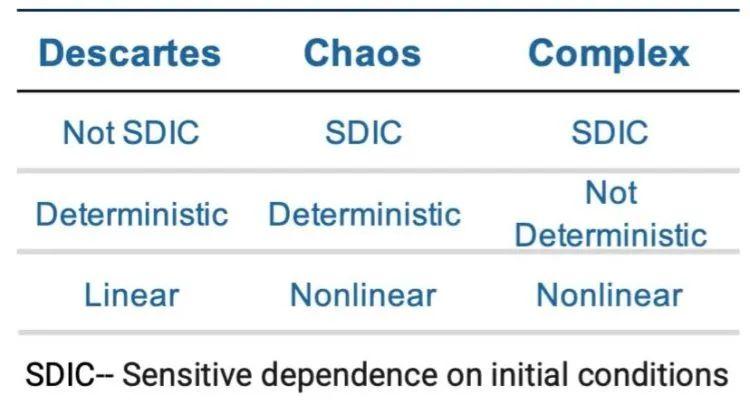
“非线性(nonlinear) ”的特征,即“系统不需要随着变量的变化而成比例地变化”[4],为从数学上捕捉所有自然和人工系统是包括反馈回路的网络这一想法提供了灵活性。这种连通性,即不同的网络变量在不同的时间点处于不同的状态,解释了复杂系统的不确定性(non-deterministic nature)、系统的多变量性(multi-variable nature)和这些系统的突创性(emergent quality)。突创(Emergence) 是一种系统特征,其中整体的特征不能用组件来相加解释,水变成冰就是一个突创的例子。复杂性(complexity) 向我们展示的是另一种类型的系统,它由远远超出笛卡尔科学的原理来解释。
复杂系统(complex systems)的一个特征解释了为什么机器学习(ML)作为解释科学的工具代表产生了巨大的进步。 复杂系统是自下而上的层级结构,这意味着量子粒子结合形成原子,原子变成分子,然后变成细胞、器官(系统),最终变成人类(系统)。诺贝尔经济学奖得主赫伯特·西蒙(Herbert Simon)把这种部件的组合称为综合(combining) [5],它是人类的创造力和不断进化的基础。每当你拉动拉杆,老虎机就会旋转,结果就会改变。在系统层次结构任何一级的很多结果都能提高生存能力,而很多变化也不能。无论是人工合成还是自然过程,这种综合过程都能创造出多样性,从而潜在地改善结果。这种组合过程的概念是计算生物学、化学和物理学的知识基础。
哈佛大学传奇生物学教授EO Wilson解释得很好。
“我们淹没在信息中,同时又渴望智慧。从今以后,世界将由组合器(synthesizers)来进行管理,人们能够在正确的时间组合正确的信息,进行批判性的思考,并明智地做出重要的选择。”
基于这一思想,威尔逊创立了后来被称为计算生物学(computational biology)的理论——将机器学习(ML)应用于生物学研究。在生物学中,我们不仅要考虑生物的物种,还要考虑所有的基因组及其组成成分的多层次结构。随着数据集规模的不断增加,机器学习(ML)的应用从数据分析(data analytics) 扩展到预测性分析和规范性分析(predictive and prescriptive analytics) , 从生物学扩展到医学、农业、材料科学和信息物理(cyber-physical)应用。机器学习(ML)是用于跨学科模式识别的完美工具。最终,我们认识到机器学习(ML)不仅仅可以用于分析数据,还可以用于设计医学、材料科学、农业和其他领域问题的解决方案。机器学习(ML)可以分析组件的合成组合,以确定最佳的理论解决方案。我们不再需要评估成千上万的解决方案。机器学习(ML)预先筛选了解决方案,减少了工作量,更重要的是缩短了上市时间(对于拯救生命的解决方案)。
汉娜·弗莱(Hannah Fry)解释了事情的真相。
“数学是对现实的抽象,而不是复制现实,它在这个过程中提供了真正的价值。通过允许人类从抽象的角度来看待世界,您创建了一种唯一能够捕获和描述模式和机制(patterns and mechanisms)的语言,否则这些模式和机制将永远保持隐藏状态。而且,正如过去200年来任何一位科学家或工程师都会告诉你的那样,理解这些模式(patterns)是能够利用它们的第一步。” [6]
正如威尔逊(Wilson)所预料的那样,机器学习(ML)通过使用模式识别算法,成为历史上进行数学运算的最佳工具。 正如复杂性经济学家(complexity economist)布莱恩·阿瑟(W. Bryan Arthur)的解释:“我们用方程操纵系统,使其达到我们所寻求的某种形式:某种解的表达式,某种公式,某种必要条件,某种数学结构,某种所寻求的对系统中包含的真理的证明。” …“算法为我们提供了研究形成过程的可能性。研究人员研究什么样的生成过程会产生给定的模式,以及这可能如何随着不同的算法设计而变化。 因此,因此,形成的模式或结构与形成它的算法之间存在着来回反复。这种风格(style)变成了实验性的:算法产生某种结构,这个结构反馈给查询产生它的算法。” [7]机器学习(ML)进化的下一步是重新定位这个“生成过程”。
随着机器学习(ML)的普及和其实用性的提高,云计算蓬勃发展。根据Synergy Research预测,到2026/2027年,云计算的收入将超过1万亿美元。[8]云计算与更好的数据库技术相结合,支持针对特定问题扩大数据集大小。 随着数据库技术的改进,可用ML算法的分类也得到了改进。其中有一组算法是生成式人工智能(Generative AI),它因根据文本和艺术作品数据产生原创文本作品和艺术作品而备受关注,更重要的发展是生成式人工智能在科学领域的应用。
生成式人工智能有很多种版本——无监督、有监督和强化。不管是哪种风格的算法,合成数据要么被用作文字或艺术作品形式的输出,要么被用作新的训练数据来改进算法。将合成数据用作训练数据有许多用途,包括让用户匿名。然而,我认为更令人兴奋的发现是由计算机科学家Daphne Koller,MacArthur Genius和早期生物医学公司Insitro的首席执行官说明的。利用合成数据,Insitro发现了医疗数据集中的新特征,而这些特征是研究人员以前不知道的。基本上,算法看到了人类看不到的模式,并在新的合成数据中复制了它们。科勒认为,在未来的合成数据集中重复出现的新特征可能会将医学研究带到基础医学科学的一个全新水平。[9]这种逻辑也可以应用于自然科学的几乎任何计算领域,从而开启新层次的基础理论研究。
风险投资公司a16z的联合创始人马克·安德烈森(Marc Andresseen)在最近的一次播客中指出,新技术让我们能够“重新审视基本原理” 。科学家历来受到实验工具的限制。生成性人工智能有可能在根本层面上改变科学。现代科学史最初是由经验数据分析形成的,并得到数学的验证。 如今,随着合成数据的出现,我们即将实现用数学处理整个科学发现过程,而科学家们只做验证。正如Air Street Capital的风险投资人所说,“人工智能优先(AI-first)源于设计”。《化学信息学杂志》(Journal of Cheminformatics)对这种人工智能优先的设计进行了很好的解释:
“近年来,人工智能和机器学习(AI/ML)在研发药物中的应用迅速增加,为药物设计项目提供了AI辅助设计工具。人工智能的优势在于从来自不同来源的大量数据中发现模式(patterns),最大限度地增强人类在分子优化等挑战性任务中的能力。分子从头生成(De novo Molecular Design)的进步使得药物设计的计算机设计-制造-测试-分析(DMTA)周期中的设计步骤能够自动化。[10]
高级研究人员使用机器学习(ML)来加速新方法——DMTA,以在相关行业中增加新化学品和药物的开发。研究人员将持续改进算法以优化这一过程,但许多科学研究已经转移到正在彻底改变生物学、化学和医学的计算模型上。
Stable Diffusion创始人Emad Mostaque在《麻省理工学院技术评论(MIT Technology Review)》(2023年2月)中强调了这一点。
“谷歌和微软正在全力以赴,将生成性人工智能作为其未来的核心。没有什么“发展生成式AI还为时过早”,这些万亿美元的公司正在转移他们的整个战略和重点。我想不起有哪一次技术和战略转变像这样迅速而有意义。”
将生成式人工智能与Excel或iPhone进行比较是低估了这一新技术的潜在影响。生成型人工智能的效果很可能相当于电学(electricity)或香农的信息论(Shannon’s Information Theory)。Generative AI will be a Superpower! [11]
事实上我们一无所知,因为真理在深处。
In reality we know nothing, for truth is in the depths.
——Democritus
END
参考资料
[1] https://bu.ac.bd/uploads/BUJ1V5I12/6.%20Hena%20Rani%20Biswas.pdf
[2] Complexity: The Emerging Science at the Edge of Order and Chaos by M. Mitchell Waldrop
[3] https://www.statisticshowto.com/deterministic-function-nondeterministic/
[4] https://www.statisticshowto.com/deterministic-function-nondeterministic/
[5] https://monoskop.org/images/9/9c/Simon_Herbert_A_The_Sciences_of_the_Artificial_3rd_ed.pdf by Herbet A. Simon
[6] The Mathematics of Love by Hannah Fry
[7] https://beijer.kva.se/wp-content/uploads/2020/03/Disc269_Arthur_2020.pdf by W. Brian Arthur
[8] https://www.nextplatform.com/2023/01/26/cloud-spending-to-top-1-trillion-in-four-years/
[9] https://www.mckinsey.com/industries/life-sciences/our-insights/it-will-be-a-paradigm-shift-daphne-koller-on-machine-learning-in-drug-discovery
[10] https://jcheminf.biomedcentral.com/articles/10.1186/s13321-022-00667-8
[11] Many have used this phrase. It is not clear to me who deserves the credit.
本文经原作者授权,由Baihai IDP编译。如需转载译文,请联系获取授权。
原文链接:
https://www.topbots.com/the-evolution-of-science-from-descartes-to-generative-ai/
关于原作者: 作者Robert H. Hacker是StartUP FIU的co-founder 和 Director。曾在**麻省理工学院斯隆管理学院(MIT Sloan School of Management)任教。