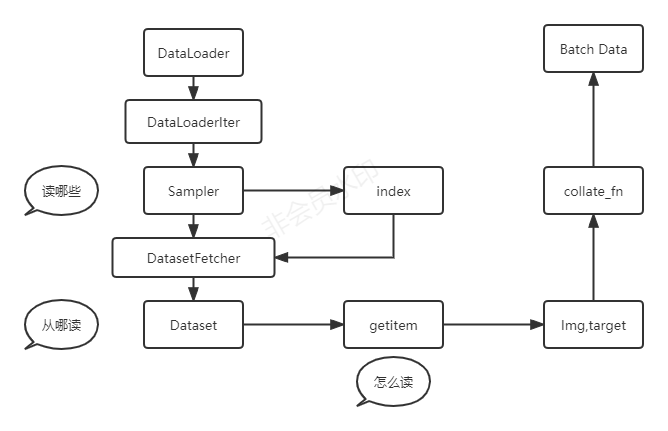
列表结构
typedef struct {
PyObject_VAR_HEAD
/* Vector of pointers to list elements. list[0] is ob_item[0], etc. */
PyObject **ob_item;
/* ob_item contains space for 'allocated' elements. The number
* currently in use is ob_size.
* Invariants:
* 0 <= ob_size <= allocated
* len(list) == ob_size
* ob_item == NULL implies ob_size == allocated == 0
* list.sort() temporarily sets allocated to -1 to detect mutations.
*
* Items must normally not be NULL, except during construction when
* the list is not yet visible outside the function that builds it.
*/
Py_ssize_t allocated;
} PyListObject;
其中定义了一个名为PyListObject的结构体。下面是这个结构体中的各个成员变量的详细解释:
-
PyObject_VAR_HEAD:这是一个宏定义,它定义了一个PyObject对象的头部。在PyListObject结构体中,这个宏定义的作用是将PyListObject与PyObject对象关联起来,以便在Python解释器中进行类型检查和垃圾回收等操作。这个宏定义包含了以下内容:
PyObject ob_base; Py_ssize_t ob_size;其中,PyObject是一个C语言结构体,表示Python对象的基础部分。ob_size是一个Py_ssize_t类型的整数,用于表示对象的大小。当使用PyObject_VAR_HEAD宏定义一个对象的头部时,ob_size会被设置为0,这表示这个对象的大小是变长的,可以动态地分配内存。在Python中,许多对象,例如列表、元组、字典等,都是变长的,因此通常会使用PyObject_VAR_HEAD来定义这些对象的头部。这个宏定义的作用是将Python对象的头部和实际的数据结构关联起来,以便在Python解释器中进行类型检查和垃圾回收等操作。
-
PyObject **ob_item:这是一个指针数组,用于存储Python列表中的元素。列表中的第一个元素存储在ob_item[0]中,以此类推。这个数组的大小由成员变量allocated决定。
-
Py_ssize_t allocated:这是一个整型变量,表示ob_item数组中分配的内存空间大小。allocated的值必须大于等于列表中实际元素的个数ob_size。如果allocated的值为负数,则表示列表已被排序或已发生了变异,需要进行特殊处理。在Python的实现中,当对一个列表进行排序或者其他改变列表结构的操作时,为了避免出现潜在的问题,Python会对这个列表的allocated成员变量进行一个特殊的标记,将其值设置为负数,表示列表已经被排序或发生了变异。这个标记的作用是在随后的操作中,比如插入或删除元素时,检查这个列表是否已经被修改,如果是,则需要重新分配内存空间,并将allocated的值设置为正数。这个特殊处理的作用是保证了列表在被修改时的安全性,同时也保证了内存分配的效率。在Python中,列表的内存分配是动态的,如果不进行特殊处理,可能会出现内存分配过多或者过少的情况,导致程序效率降低。因此,为了保证Python程序的高效性和正确性,对于列表的修改操作,Python实现中会进行特殊处理,以确保内存的合理分配和程序的正确性。
-
Invariants:这是一组不变式,用于描述列表ob_item和PyListObject结构体中的其他成员变量之间的关系。具体来说,这些不变式包括:
- 0 <= ob_size <= allocated:ob_size表示列表中实际元素的个数,allocated表示ob_item数组的大小。这个不变式表明,ob_size必须小于等于allocated,并且ob_size和allocated必须都是非负数。
- len(list) == ob_size:这个不变式表示列表的长度必须等于ob_size。
- ob_item == NULL implies ob_size == allocated == 0:如果ob_item为NULL,则表示列表为空。此时,ob_size和allocated都必须为0。
- list.sort() temporarily sets allocated to -1 to detect mutations.:当对列表进行排序操作时,allocated的值会被暂时设置为-1,以便检测列表是否发生了变异。
-
Items must normally not be NULL, except during construction when the list is not yet visible outside the function that builds it.:在大多数情况下,列表中的元素不能为NULL。但是,在构建列表的函数中,如果列表还没有被返回并且在函数外部不可见,那么列表中的元素可以为NULL。
列表初始化
static int
list___init___impl(PyListObject *self, PyObject *iterable)
/*[clinic end generated code: output=0f3c21379d01de48 input=b3f3fe7206af8f6b]*/
{
/* Verify list invariants established by PyType_GenericAlloc() */
assert(0 <= Py_SIZE(self));
assert(Py_SIZE(self) <= self->allocated || self->allocated == -1);
assert(self->ob_item != NULL ||
self->allocated == 0 || self->allocated == -1);
/* Empty previous contents */
if (self->ob_item != NULL) {
(void)_list_clear(self);
}
if (iterable != NULL) {
if (_PyObject_HasLen(iterable)) {
Py_ssize_t iter_len = PyObject_Size(iterable);
if (iter_len == -1) {
if (!PyErr_ExceptionMatches(PyExc_TypeError)) {
return -1;
}
PyErr_Clear();
}
if (iter_len > 0 && self->ob_item == NULL
&& list_preallocate_exact(self, iter_len)) {
return -1;
}
}
PyObject *rv = list_extend(self, iterable);
if (rv == NULL)
return -1;
Py_DECREF(rv);
}
return 0;
}
用于初始化Python列表对象。下面是这个函数的具体实现:
- 首先,函数会检查列表的一些不变量,确保它们满足要求。这些不变量包括:列表中元素数量的范围在0到allocated之间,allocated是已分配的内存数量,ob_item指向列表元素的指针数组。如果不变量不满足要求,函数会抛出一个assertion failure。
- 如果列表中已经有元素了,则调用_list_clear函数清空列表中的所有元素。
- 如果传入的iterable参数不为空,则根据iterable的长度预分配足够的内存空间。如果预分配的内存空间失败,则返回-1表示操作失败。
- 调用list_extend函数,将iterable中的所有元素添加到列表中。如果操作失败,则返回-1表示操作失败。
- 返回0表示操作成功。
总体来说,该函数的作用是初始化Python列表对象。它首先检查列表的一些不变量,确保它们满足要求。然后,它清空列表中的所有元素,并根据传入的iterable参数预分配足够的内存空间。最后,它调用list_extend函数,将iterable中的所有元素添加到列表中。
列表插入操作
int
PyList_Insert(PyObject *op, Py_ssize_t where, PyObject *newitem)
{
if (!PyList_Check(op)) {
PyErr_BadInternalCall();
return -1;
}
return ins1((PyListObject *)op, where, newitem);
}
- 首先检查op是否为Python列表类型。如果op不是Python列表类型,则会抛出一个PyErr_BadInternalCall异常,并返回-1表示操作失败。
- 调用ins1函数,在指定位置where处将newitem插入到列表op中。
- 返回ins1函数的返回值,表示操作是否成功。
static int
ins1(PyListObject *self, Py_ssize_t where, PyObject *v)
{
Py_ssize_t i, n = Py_SIZE(self);
PyObject **items;
if (v == NULL) {
PyErr_BadInternalCall();
return -1;
}
if (n == PY_SSIZE_T_MAX) {
PyErr_SetString(PyExc_OverflowError,
"cannot add more objects to list");
return -1;
}
if (list_resize(self, n+1) < 0)
return -1;
if (where < 0) {
where += n;
if (where < 0)
where = 0;
}
if (where > n)
where = n;
items = self->ob_item;
for (i = n; --i >= where; )
items[i+1] = items[i];
Py_INCREF(v);
items[where] = v;
return 0;
}
- 首先获取列表的当前长度n,然后检查要插入的元素v是否为NULL。如果v为NULL,则表示出现了内部调用错误,会抛出一个PyErr_BadInternalCall异常,并返回-1表示操作失败。
- 如果列表已经达到了最大长度,那么插入操作无法进行,会抛出一个PyExc_OverflowError异常,并返回-1表示操作失败。
- 调用list_resize函数扩展列表的大小,使其能够容纳一个新的元素。如果扩展失败,会返回-1表示操作失败。
- 根据插入位置where的值,更新其值。如果where小于0,则表示从列表末尾开始往前数,因此需要计算出正确的位置。如果where大于n,则表示要在列表末尾插入元素,因此需要将where的值设置为n。
- 定义一个名为items的指针数组,用于存储列表中的元素。
- 使用for循环,将从where位置开始的所有元素往后移动一个位置,以腾出一个位置用于插入新元素。
- 使用Py_INCREF宏对新元素进行引用计数,然后将其插入到列表的where位置。
- 返回0表示插入操作成功。
总体来说,这个函数的作用是在Python列表中插入一个新元素。它首先检查输入参数是否正确,然后通过调用list_resize函数扩展列表的大小,并将所有元素往后移动一个位置,以腾出一个位置用于插入新元素。最后,使用Py_INCREF宏对新元素进行引用计数,并将其插入到指定位置。
列表删除操作
static PyObject *
list_remove(PyListObject *self, PyObject *value)
/*[clinic end generated code: output=f087e1951a5e30d1 input=2dc2ba5bb2fb1f82]*/
{
Py_ssize_t i;
for (i = 0; i < Py_SIZE(self); i++) {
PyObject *obj = self->ob_item[i];
Py_INCREF(obj);
int cmp = PyObject_RichCompareBool(obj, value, Py_EQ);
Py_DECREF(obj);
if (cmp > 0) {
if (list_ass_slice(self, i, i+1,
(PyObject *)NULL) == 0)
Py_RETURN_NONE;
return NULL;
}
else if (cmp < 0)
return NULL;
}
PyErr_SetString(PyExc_ValueError, "list.remove(x): x not in list");
return NULL;
}
这是一个名为list_remove的函数,用于从Python列表中移除指定的元素。下面是这个函数的具体实现:
- 定义一个名为i的Py_ssize_t类型变量,用于遍历列表中的所有元素。
- 使用for循环遍历列表中的所有元素。在每次循环中,从列表中获取一个元素obj,并使用PyObject_RichCompareBool函数将这个元素与待移除元素value进行比较。
- 如果比较的结果为1,则表示找到了待移除元素。此时,调用list_ass_slice函数,将列表中从i到i+1的元素删除,并返回Py_RETURN_NONE表示移除操作成功。
- 如果比较的结果为-1,则表示出现了异常。此时,直接返回NULL表示操作失败。
- 如果比较的结果为0,则继续遍历下一个元素。
- 如果在整个循环中都没有找到待移除元素,则会抛出一个PyExc_ValueError异常,并返回NULL表示操作失败。
总体来说,list_remove函数的作用是从Python列表中移除指定的元素。它遍历列表中的所有元素,将每个元素与待移除元素进行比较,找到待移除元素后调用list_ass_slice函数将其从列表中删除。如果整个列表中都没有待移除元素,则会抛出一个异常表示操作失败。
列表修改
#define PyList_SET_ITEM(op, i, v) (_PyList_CAST(op)->ob_item[i] = (v))
在 CPython 中,#define PyList_SET_ITEM(op, i, v) (_PyList_CAST(op)->ob_item[i] = (v)) 是一个宏定义,用于修改 Python 列表对象中指定索引位置的元素。
这个宏定义中包含了三个参数:
op:要修改的 Python 列表对象。i:要修改的元素的索引位置。v:新的元素值。
在宏定义中,使用了 _PyList_CAST 函数将 op 转换成了 PyListObject* 类型,从而可以使用 ob_item 成员来访问列表对象的元素。具体实现中,宏定义将指定索引位置 i 处的元素值设置为新的元素值 v,实现了 Python 列表对象中指定元素的修改。
列表查找
#define PyList_GET_ITEM(op, i) (_PyList_CAST(op)->ob_item[i])
在 CPython 中,#define PyList_GET_ITEM(op, i) (_PyList_CAST(op)->ob_item[i]) 是一个宏定义,用于获取 Python 列表对象中指定索引位置的元素。
这个宏定义中包含了两个参数:
op:要访问的 Python 列表对象。i:要访问的元素的索引位置。
在宏定义中,使用了 _PyList_CAST 函数将 op 转换成了 PyListObject* 类型,从而可以使用 ob_item 成员来访问列表对象的元素。具体实现中,宏定义返回了指定索引位置 i 处的元素值,实现了 Python 列表对象中指定元素的访问。
列表比较
static PyObject *
list_richcompare(PyObject *v, PyObject *w, int op)
{
PyListObject *vl, *wl;
Py_ssize_t i;
if (!PyList_Check(v) || !PyList_Check(w))
Py_RETURN_NOTIMPLEMENTED;
vl = (PyListObject *)v;
wl = (PyListObject *)w;
if (Py_SIZE(vl) != Py_SIZE(wl) && (op == Py_EQ || op == Py_NE)) {
/* Shortcut: if the lengths differ, the lists differ */
if (op == Py_EQ)
Py_RETURN_FALSE;
else
Py_RETURN_TRUE;
}
/* Search for the first index where items are different */
for (i = 0; i < Py_SIZE(vl) && i < Py_SIZE(wl); i++) {
PyObject *vitem = vl->ob_item[i];
PyObject *witem = wl->ob_item[i];
if (vitem == witem) {
continue;
}
Py_INCREF(vitem);
Py_INCREF(witem);
int k = PyObject_RichCompareBool(vitem, witem, Py_EQ);
Py_DECREF(vitem);
Py_DECREF(witem);
if (k < 0)
return NULL;
if (!k)
break;
}
if (i >= Py_SIZE(vl) || i >= Py_SIZE(wl)) {
/* No more items to compare -- compare sizes */
Py_RETURN_RICHCOMPARE(Py_SIZE(vl), Py_SIZE(wl), op);
}
/* We have an item that differs -- shortcuts for EQ/NE */
if (op == Py_EQ) {
Py_RETURN_FALSE;
}
if (op == Py_NE) {
Py_RETURN_TRUE;
}
/* Compare the final item again using the proper operator */
return PyObject_RichCompare(vl->ob_item[i], wl->ob_item[i], op);
}
这是一个名为list_richcompare的函数,用于比较两个Python列表是否相等。下面是这个函数的具体实现:
- 定义两个PyListObject指针vl和wl,用于表示输入的两个Python列表。
- 检查v和w是否都是Python列表类型。如果其中一个不是Python列表类型,则返回Py_RETURN_NOTIMPLEMENTED。
- 将v和w强制转换为PyListObject类型,并将它们分别赋值给vl和wl。
- 如果两个列表的长度不同,并且比较操作是相等或不等操作,那么可以快速确定它们不相等,返回Py_RETURN_FALSE或Py_RETURN_TRUE。
- 使用for循环从前往后遍历列表vl和wl中的所有元素,找到第一个不相等的元素。
- 如果所有元素都相等,而且列表的长度相同,则返回Py_RETURN_RICHCOMPARE(Py_SIZE(vl), Py_SIZE(wl), op)。
- 如果找到了不相等的元素,则根据比较操作op返回一个新的PyObject对象,用于表示两个列表的比较结果。
总体来说,list_richcompare函数的作用是比较两个Python列表是否相等。它首先检查输入参数是否正确,然后遍历两个列表中的所有元素,找到第一个不相等的元素,并根据比较操作op返回一个新的PyObject对象,用于表示两个列表的比较结果。这个函数通常会被Python解释器调用,用于支持Python列表的比较操作
列表内置方法
static PyMethodDef list_methods[] = {
{"__getitem__", (PyCFunction)list_subscript, METH_O|METH_COEXIST, "x.__getitem__(y) <==> x[y]"},
LIST___REVERSED___METHODDEF
LIST___SIZEOF___METHODDEF
LIST_CLEAR_METHODDEF
LIST_COPY_METHODDEF
LIST_APPEND_METHODDEF
LIST_INSERT_METHODDEF
LIST_EXTEND_METHODDEF
LIST_POP_METHODDEF
LIST_REMOVE_METHODDEF
LIST_INDEX_METHODDEF
LIST_COUNT_METHODDEF
LIST_REVERSE_METHODDEF
LIST_SORT_METHODDEF
{"__class_getitem__", (PyCFunction)Py_GenericAlias, METH_O|METH_CLASS, PyDoc_STR("See PEP 585")},
{NULL, NULL} /* sentinel */
};
这是一个名为list_methods的数组,它包含了Python列表对象支持的所有方法。下面是这个数组的具体实现:
- "getitem"方法:用于根据索引返回列表中的元素。具体实现中,它调用list_subscript函数,并将列表对象和索引作为参数传入。
LIST___REVERSED___METHODDEF:该宏定义一个名为"reversed"的方法,用于返回一个逆序迭代器。具体实现中,它调用list_reverse和PyObject_GetIter函数,返回一个新的逆序迭代器对象。LIST___SIZEOF___METHODDEF:该宏定义一个名为"sizeof"的方法,用于返回列表对象占用的内存大小。具体实现中,它调用list___sizeof___impl函数。- LIST_CLEAR_METHODDEF:该宏定义一个名为"clear"的方法,用于清空列表中的所有元素。具体实现中,它调用list_clear函数。
- LIST_COPY_METHODDEF:该宏定义一个名为"copy"的方法,用于返回一个新的列表对象,包含原列表中的所有元素。具体实现中,它调用list_copy函数,返回一个新的列表对象。
- LIST_APPEND_METHODDEF:该宏定义一个名为"append"的方法,用于在列表的末尾添加一个元素。具体实现中,它调用list_append函数。
- LIST_INSERT_METHODDEF:该宏定义一个名为"insert"的方法,用于在列表中的指定位置插入一个元素。具体实现中,它调用list_insert函数。
- LIST_EXTEND_METHODDEF:该宏定义一个名为"extend"的方法,用于将一个可迭代对象中的所有元素添加到列表的末尾。具体实现中,它调用list_extend函数。
- LIST_POP_METHODDEF:该宏定义一个名为"pop"的方法,用于移除并返回列表中指定位置的元素。具体实现中,它调用list_pop函数。
- LIST_REMOVE_METHODDEF:该宏定义一个名为"remove"的方法,用于移除列表中第一个与指定值相等的元素。具体实现中,它调用list_remove函数。
- LIST_INDEX_METHODDEF:该宏定义一个名为"index"的方法,用于返回列表中第一个与指定值相等的元素的索引。具体实现中,它调用list_index函数。
- LIST_COUNT_METHODDEF:该宏定义一个名为"count"的方法,用于返回列表中与指定值相等的元素数量。具体实现中,它调用list_count函数。
- LIST_REVERSE_METHODDEF:该宏定义一个名为"reverse"的方法,用于将列表中的元素倒序排列。具体实现中,它调用list_reverse函数。
- LIST_SORT_METHODDEF:该宏定义一个名为"sort"的方法,用于将列表中的元素进行排序。具体实现中,它调用list_sort函数,该函数是一个静态函数,实现了Python列表对象的快速排序算法。具体实现中,它使用了经典的快速排序算法,将列表中的元素按照指定的比较函数进行排序。
- "class_getitem"方法:用于支持泛型类型。具体实现中,它调用Py_GenericAlias函数,并返回一个新的泛型别名对象。
- NULL:这是一个标志,用于标记方法列表的末尾。








![[译]自下而上认识Elasticsearch](https://img-blog.csdnimg.cn/4a5d5d63a27448289d09d0881b66285a.png#pic_center)