一.HTTP协议的含义
http是什么?
超文本传输协议(Hyper Text Transfer Protocol,HTTP)是一个简单的请求-响应协议,它通常运行在TCP之上。‘超’可以理解为除了文本之外的图片,音频和视频,和一些其他的一些文件。
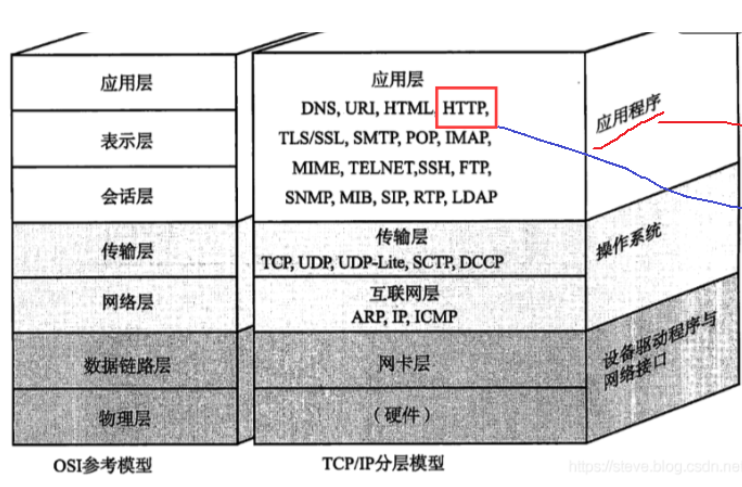
在应用层中开发应用程序,最重要的任务之一是制定通信协议,HTTP协议就是应用层协议中较为经典的协议。
二.HTTP协议的应用场景
1.浏览器和服务器(我们通过浏览器来浏览网页)
2.手机和服务器之间的通信
3.服务器和服务器之间的通信
HTTP协议是基于TCP协议的一种应用层协议,无论是通过哪个应用进行实现(不一定非要是浏览器),一定要满足的是按照协议的格式对数据进行编码和解码
编码完成后通过socketapi发送,接收到数据之后再按照协议的规定进行解析即可。
三.HTTP协议发展的历史
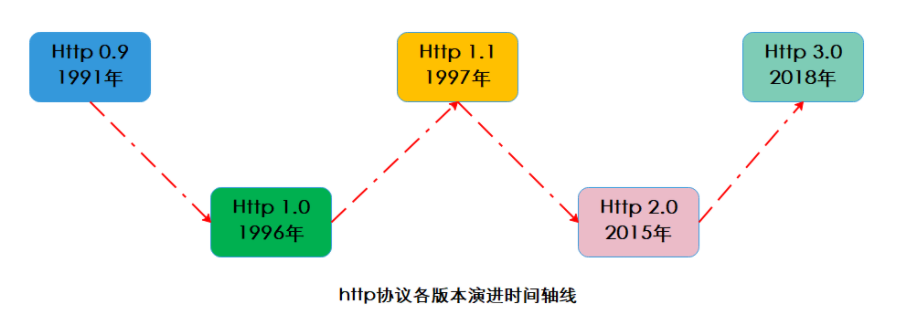
HTTP协议往往是基于TCP协议进行实现的(HTTP0.9 1.0 1.1 2.0 全部是基于TCP实现的,HTTP3基于UDP实现)
四.HTTP交互的过程:
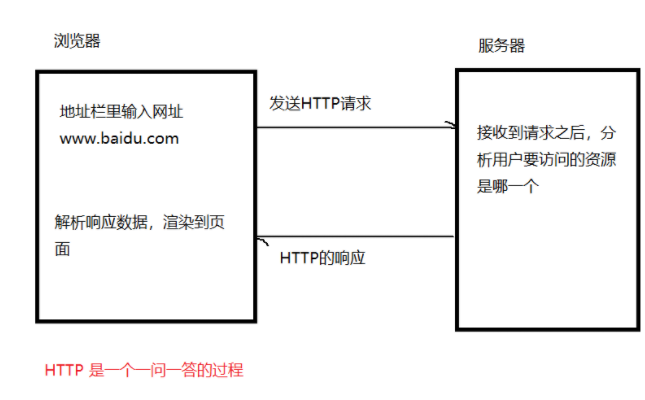
我们拿百度主页的URL进行说明:
https://www.baidu.com/
我们能够观察到的是:对于百度的URL来说,它的协议类型是HTTPS,HTTPS是在HTTP基础上做的加密解密的工作,我们后续再对其进行具体介绍。
四.理解HTTP协议的工作过过程,这里我们使用一个工具FIddler来进行抓包工作,fiddler为何能抓取网络通信中的请求和响应呢?我们从其模型的角度进行分析:
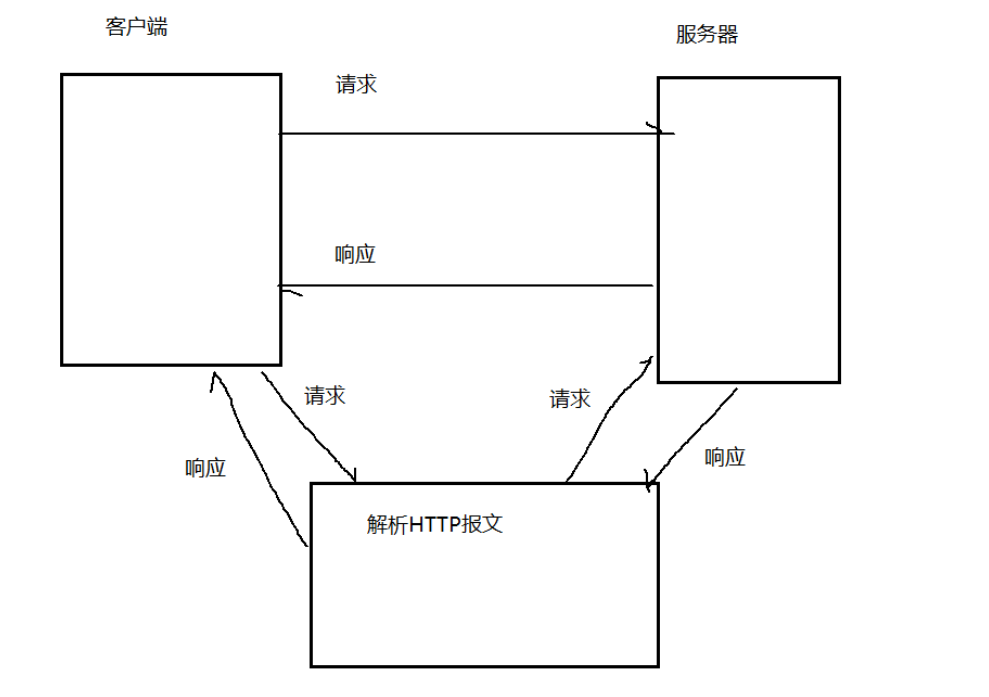
在使用fiddler之前,我们进行网络通信是客户端和服务器进行直接交互,而fiddler相当于这两者之间的‘中间人’,在客户端往服务端发送请求时会先把请求发送给fiddler,fiddler对具体请求进行解码,然后重新编码发送给服务器,同理,服务器发送给客户端的响应,同样先在fiddler中进行解码然后重新编码发送给客户端,fiddler作为两者进行通信的中间人,了解两者之间网络通信的所有细节。
4.1抓包结果分析
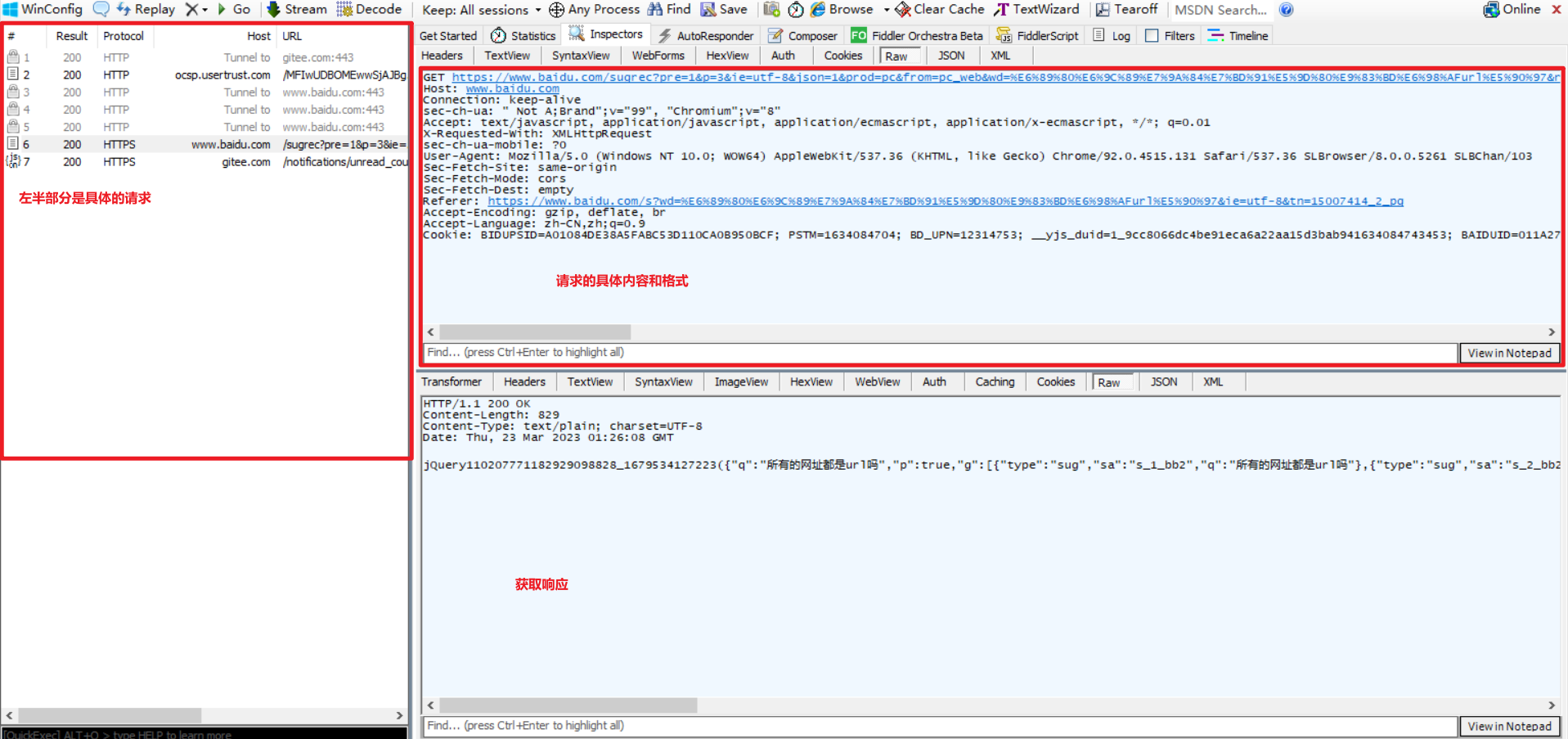
抓包结果可以划分为三个区域:左半部分是所有的请求:右上部分是请求的具体内容和格式,右下部分是服务端返回响应的具体内容和形式。
我们拿出右上角和右下角的数据进行具体讲述:
右上角的数据是请求报文:
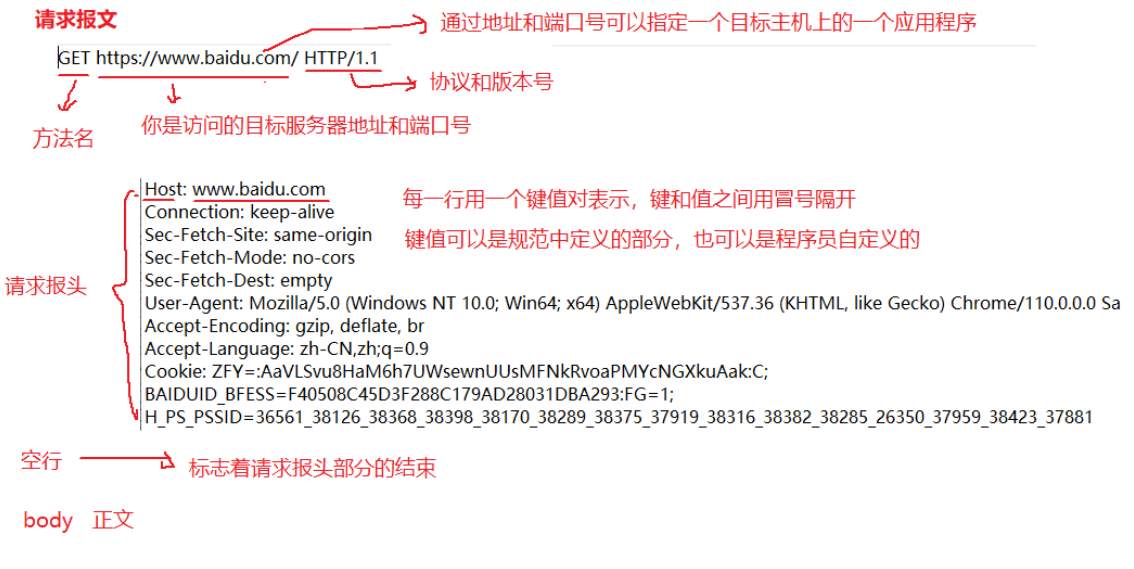
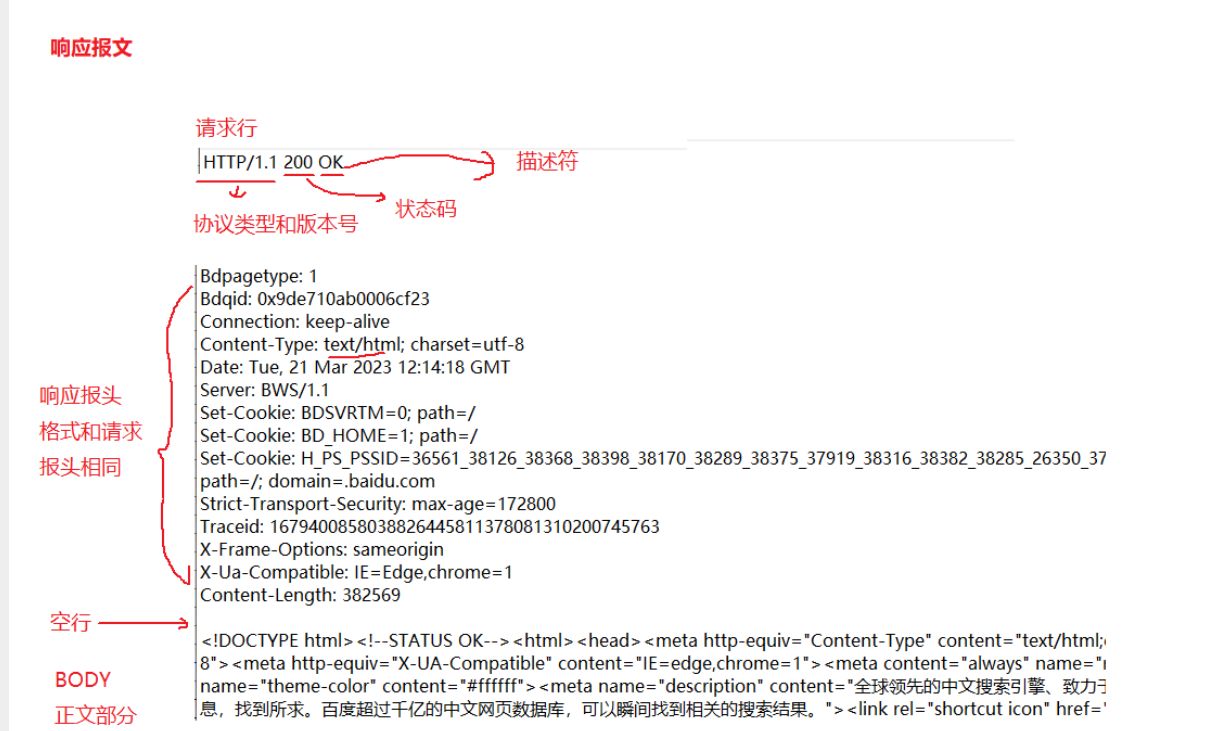
右下角的数据是响应报文:
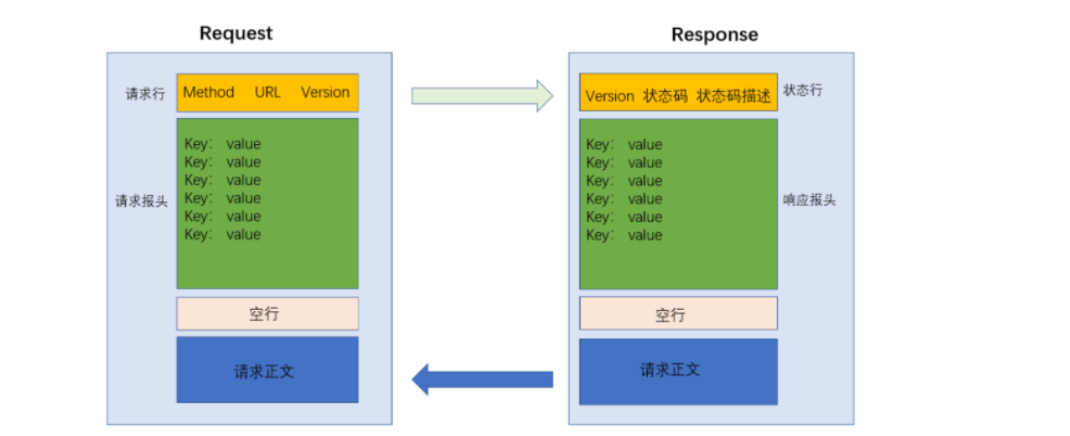
对于请求报文和响应报文中具体的格式如下:
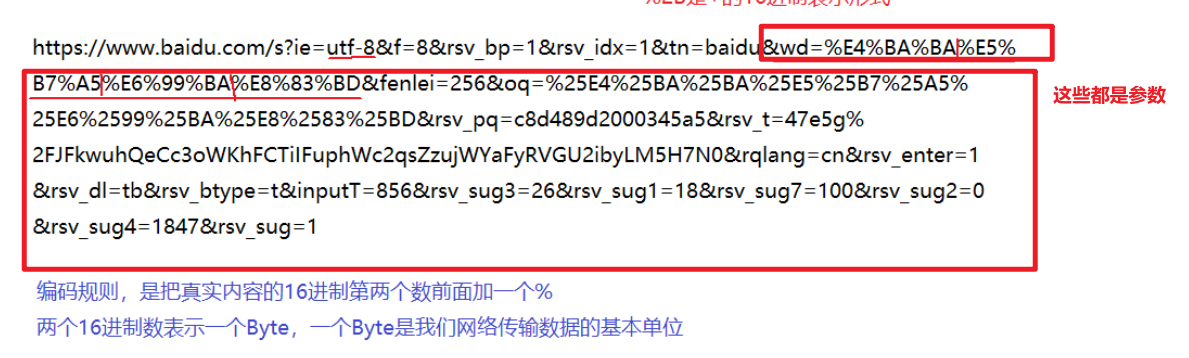
网络通信中的编码规则:把真实的内容的16进制第二个数前面加一个% 两个16进制表示一个Byte Byte是我们网络传输数据的基本单位。
五.认识URL
URL:在WWW上,每一信息资源都有统一的且在网上的地址,该地址就叫URL(Uniform Resource Locator,统一资源定位器),它是WWW的统一资源定位标志,就是指网络地址。
5.1URL的基本格式:

我们拿一个具体的实例对其进行说明:
六.认识方法
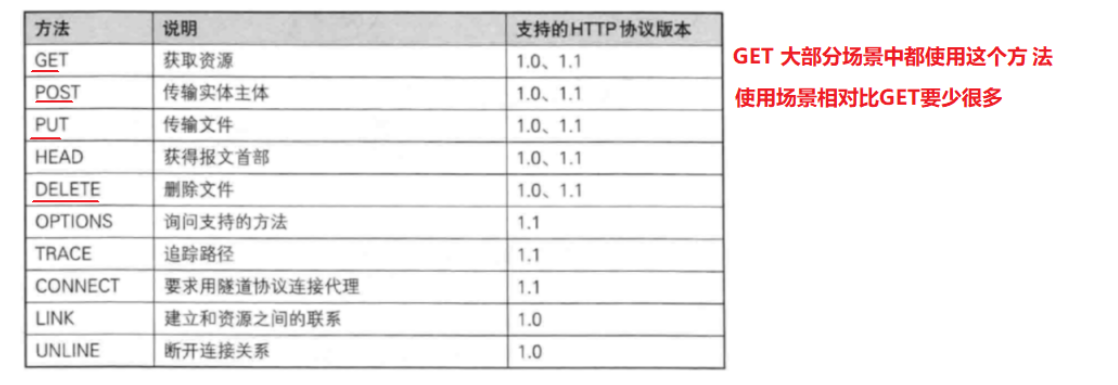
那么在构造方式中,怎样去发送一个get请求呢?
1.通过浏览器输入URL,浏览器会默认发出一个get请求
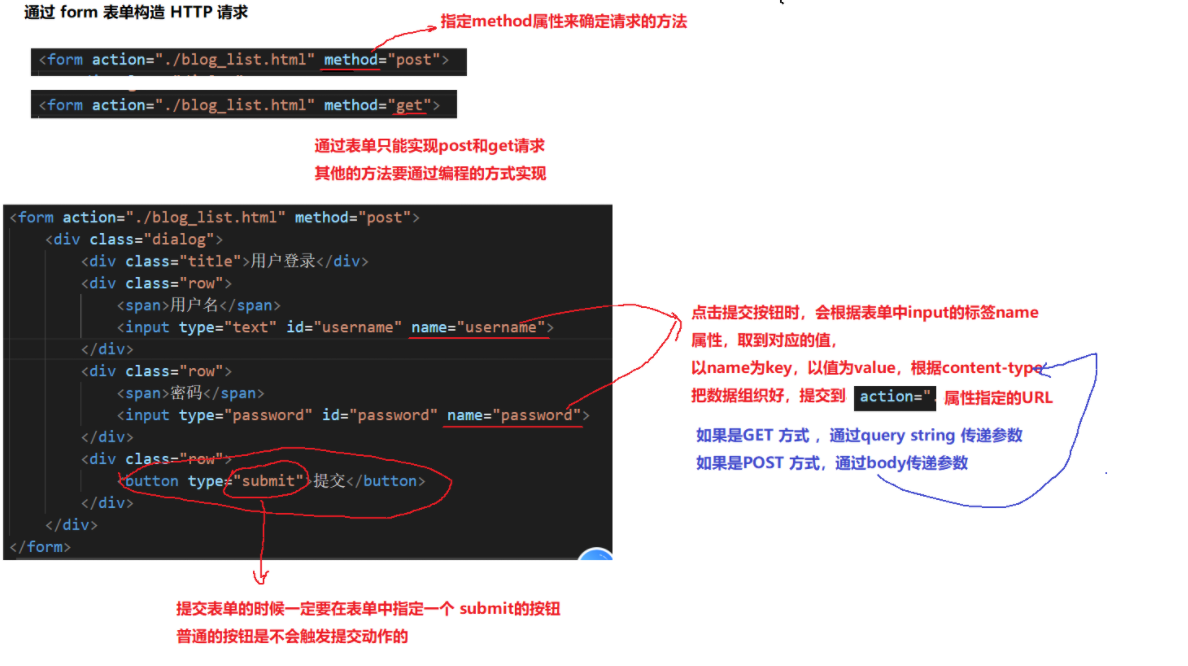
2.通过form表单指定method方法为get
3.通过AJAX方式发送get请求
4.HTML中的link ,img,script等标签,也会触发get请求
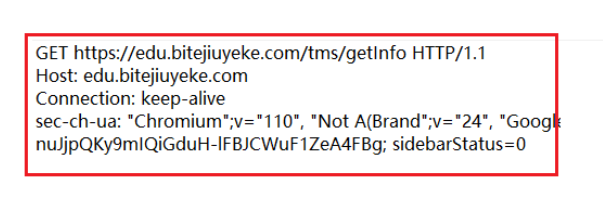
GET请求的特点:
1.首行的第一部分为GET
2.URL的query string可以为空,也可以不为空
3.header部分有若干个键值对结构
4.body部分为空
关于GET请求中的URL长度问题:
有人说GET请求中 query string的长度有限,有人说 1kb,2kb,1mb.....
但是事实上:

我们通过查看RFC标准来看,GET请求的URL长度并不受限,如果在发送GET请求时URL的长度受限,则可能是以下两个原因:
1.浏览器本身对地址栏的长度做出了限制
2.某个服务器在接收请求时对URL长度做出了限制
POST请求:
如何发送post请求?
1.通过form表单的method=POST
2.通过AJAX的方式指定方法为POST


POST请求的特点:
1.首行的第一个部分为POST
2.URL中的query string一般为空,也可以不为空
3.header部分有若干个键值对结构
4.body部分一般不为空。body内的数据格式通过header中的Content-Type指定。body的长度由header中的Content-Length指定
Content-Length存在的意义:
TCP是字节流的方式传输数据的,在接收解析时会有一个粘包问题,通过标明Content-Length来截取body中的有效数据能够正确的完成拆包。
常见的面试题:
Q:同学,你来谈一谈GET和POST的区别:
1.从总体而言,GET和POST没有本质区别,两种方法可以相互替代
2.语义不同:GET一般用于获取数据,POST一般用于提交数据
3.使用习惯:GET的body通常为空,需要传递的数据需要通过query string传递,POST的query string一般为空,需要的数据通过body传递。
4.GET请求一般是幂等的,POST请求一般是不幂等的(幂等:在多次访问同一个接口,获取到的数据均相同)
5.在幂等的基础上GET可以被缓存,POST不能被缓存。
既然GET请求每次访问的结果都相同,所以通过建立缓存能够节省带宽资源,提高访问速度,但是这也意味着如果我们修改了某个静态文件,要记得强制刷新,否则有可能不生效。
六.关于请求报头和响应报头
我们通过截取请求报头的部分内容,对报头进行解释:
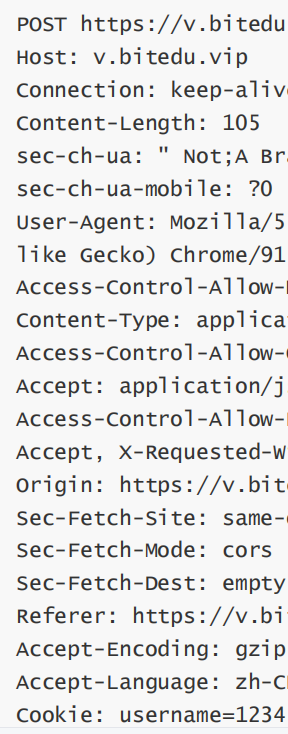
1.Host
表示服务器主机的地址和端口.
2.Content-Length
表示 body 中的数据长度.(正文的长度)
3.
Content-Type
表示请求的 body 中的数据格式.

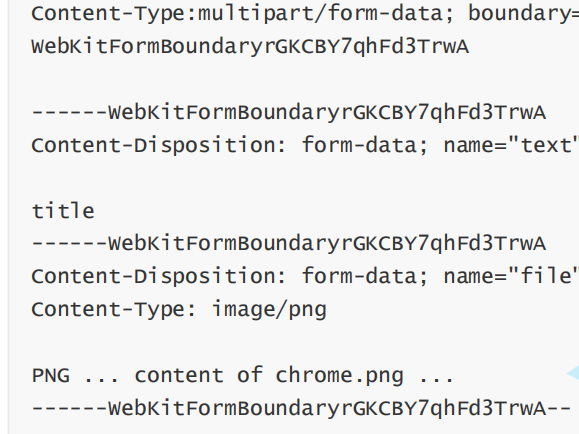

4.User-Agent (简称 UA)

5.Referer
表示这个页面是从哪个页面跳转过来的. 形如
www.baidu.com//表示是从百度跳转过来的,
关于Referer的典型应用:广告计费系统:
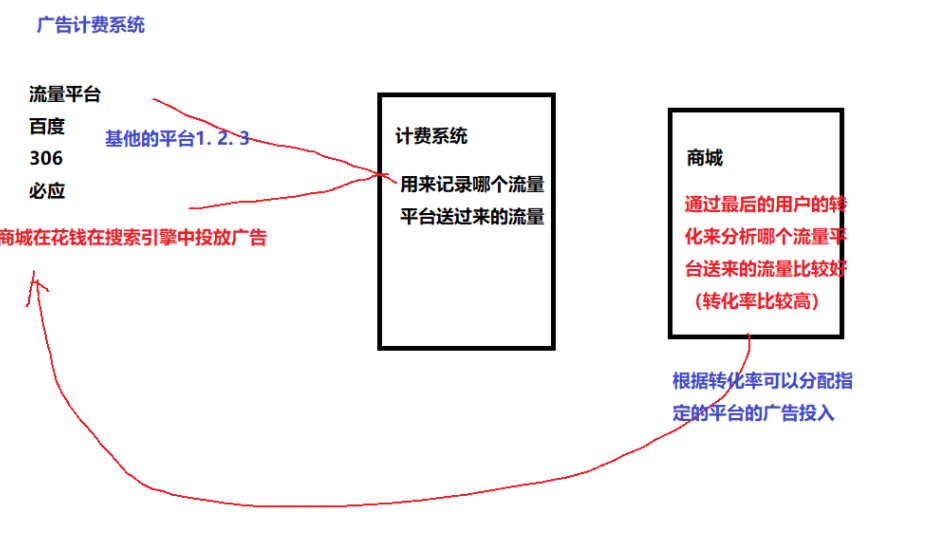
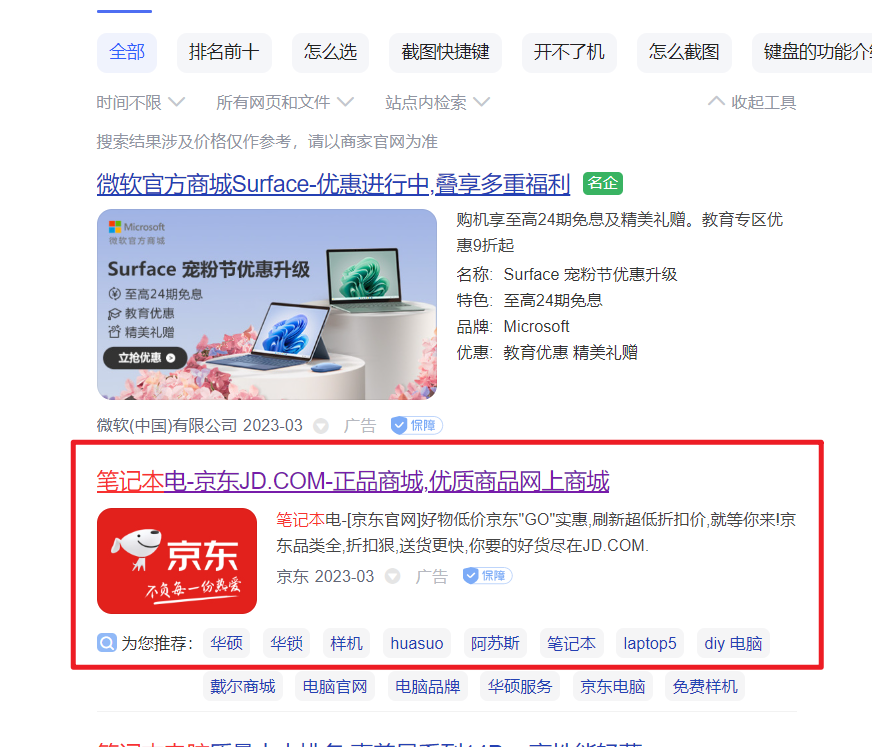
我们在百度上搜索笔记版的关键字:我们通过搜索结果打开京东的官网:
我们通过抓取以下URL,我们观察其referer,能得出这样的结论:京东商城页面的referer是京东的click页面,也就是说通过click的referer来记录的是通过哪个搜索页面跳转过来的:即是哪个搜索引擎接了京东的广告,通过点击次数或者点击和购买的转化比率计费。


Cookie:服务器在用户电脑上保存一些简单的数据,通常是字符串
cookie由服务端产生,通过服务端的set-cookie返回给用户端,等用户端再次发送请求时,将cookie信息重新发送给服务端,服务端进行校验部分信息(也就是说,cookie由服务端产生,最终返回给服务端,中间储存在浏览器中。)
cookie既然可以存储简单的信息数据,那它的作用有哪些呢?
其中比较重要的一个作用是储存用户信息:
这种功能在现实世界中如何理解呢?
我们以在医院看病为例子吧:
通常我们在医院中看病首先要挂号,挂完号后会得到一张就诊卡,就诊卡里记录着患者身份信息(客户端信息),通过这张卡,我们可以在医院的任何科室进行就诊,我们在不同科室就诊时,需要刷一下卡(确认身份),患者的身份信息被储存在医院的系统中(服务器),而这张卡是患者身份的标识(cookie)
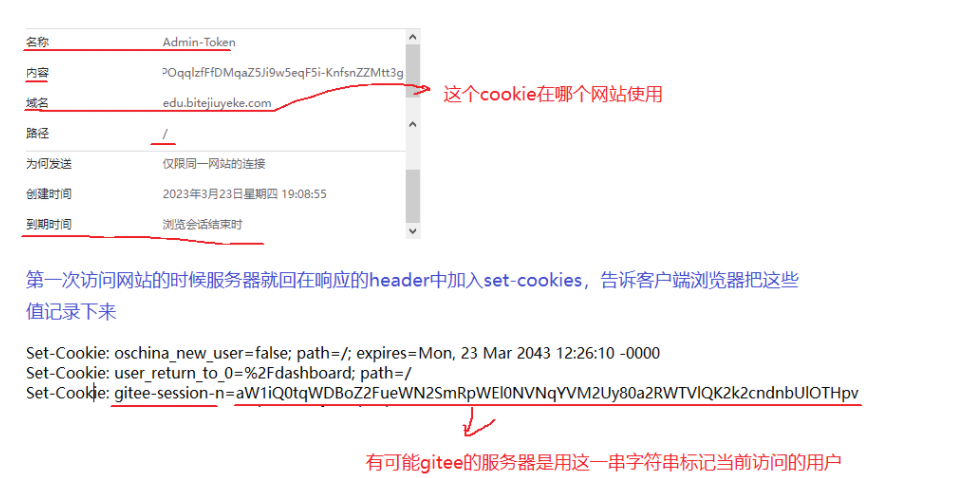
浏览器中写cookie一般有两种方式:
①在响应报文中的headers(报头)中通过set-cookies设置
②通过js的方式写入
七.HTTP的响应详解:状态码
1.200 正常返回结果
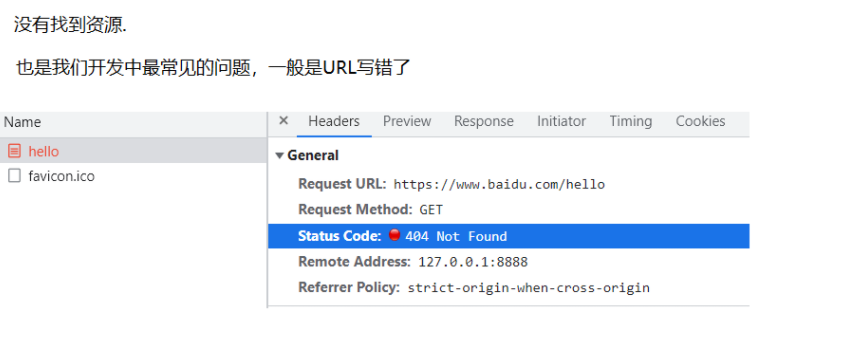
2.404 NOT FOUND资源丢失
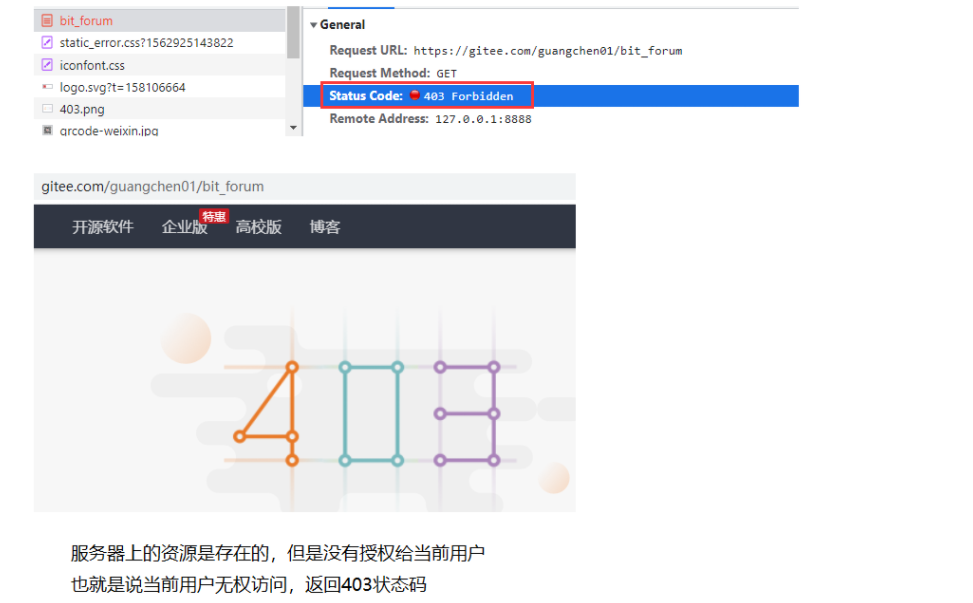
3.403 Forbidden 访问禁止(存在这个页面,但是当前客户端无权访问)
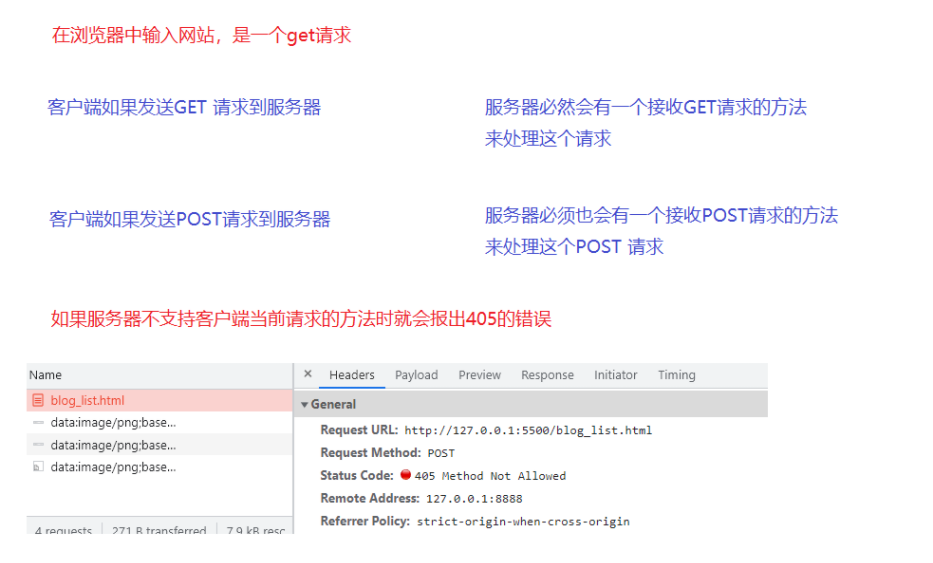
405 Method NOT Allowed 方法不被允许
301 永久重定向
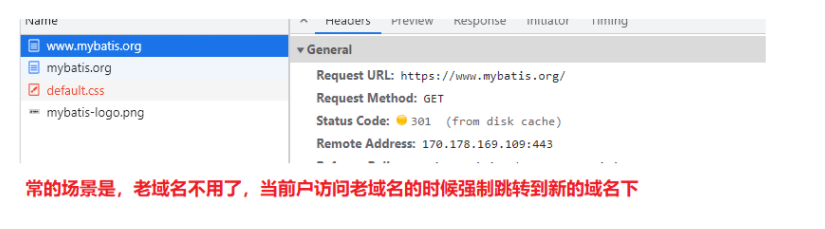
302临时重定向
场景:当我们访问某个页面时进行跳转:比如当我们登录一个页面成功后进行页面跳转
响应报文中的location表示要跳转的地址
500服务器错误
服务器出现内部错误. 一般是服务器的代码执行过程中遇到了一些特殊情况(服务器异常崩溃)会产生这个
状态码. 咱们平时常用的网站很少会出现 500 (但是偶尔也能看到)
504访问超时
在服务器负载相对较大的情况下,处理单条请求的时间会变长,如果时间过于长,可能出现超时情况

八.通过form表单构造HTTP请求
九.通过ajax构造HTTP请求
Ajax即Asynchronous Javascript And XML(异步JavaScript和XML)在 2005年被Jesse James Garrett提出的新术语,用来描述一种使用现有技术集合的‘新’方法,包括: HTML 或 XHTML, CSS, JavaScript, DOM, XML, XSLT, 以及最重要的XMLHttpRequest。 [3] 使用Ajax技术网页应用能够快速地将增量更新呈现在用户界面上,而不需要重载(刷新)整个页面,这使得程序能够更快地回应用户的操作。 [3]
1.关于同步和异步
同步(synchronize):当我们发送请求时,在得到响应之前,我们不能进行其他操作,程序进入阻塞状态
异步(Asynchronous ):当我们发送请求时,在得到响应之前,我们依然可以进行其他操作,当得到响应的时候获取响应并进行下一步操作即可。
2.ajax的实现方式
①手动调用ajax,这个过程相对比较麻烦,在这里我们不做赘述
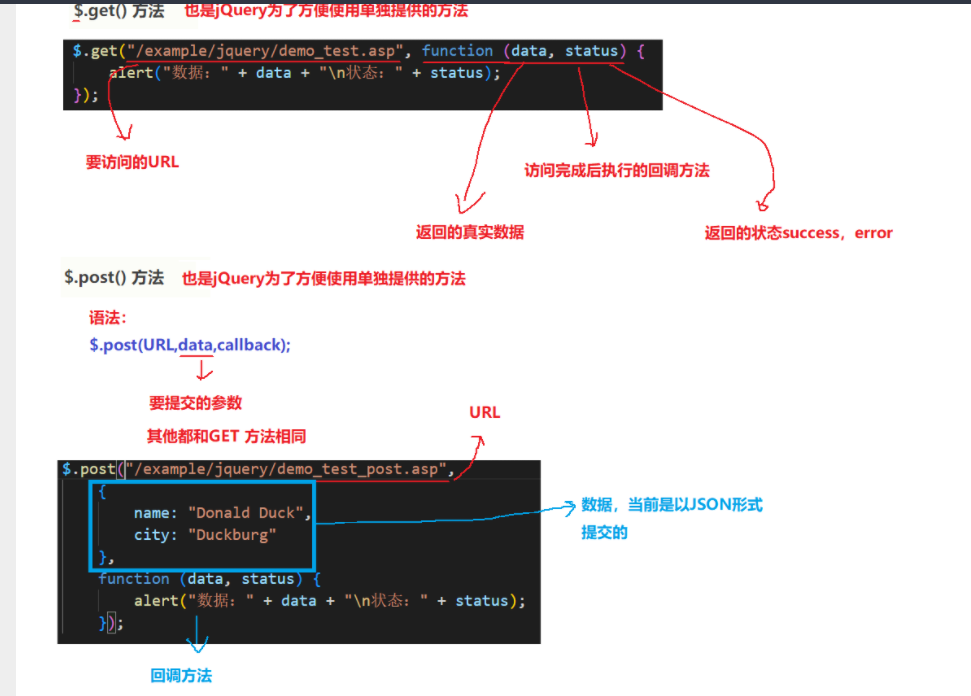
②使用Jquery对ajax进行封装,我们在此进行讲述
2.1引入JQuery的两种方式
①下载jQuery资源,引用相对路径
②调用网络上的CDN,调用网络资源

3.使用jQuery实现方法


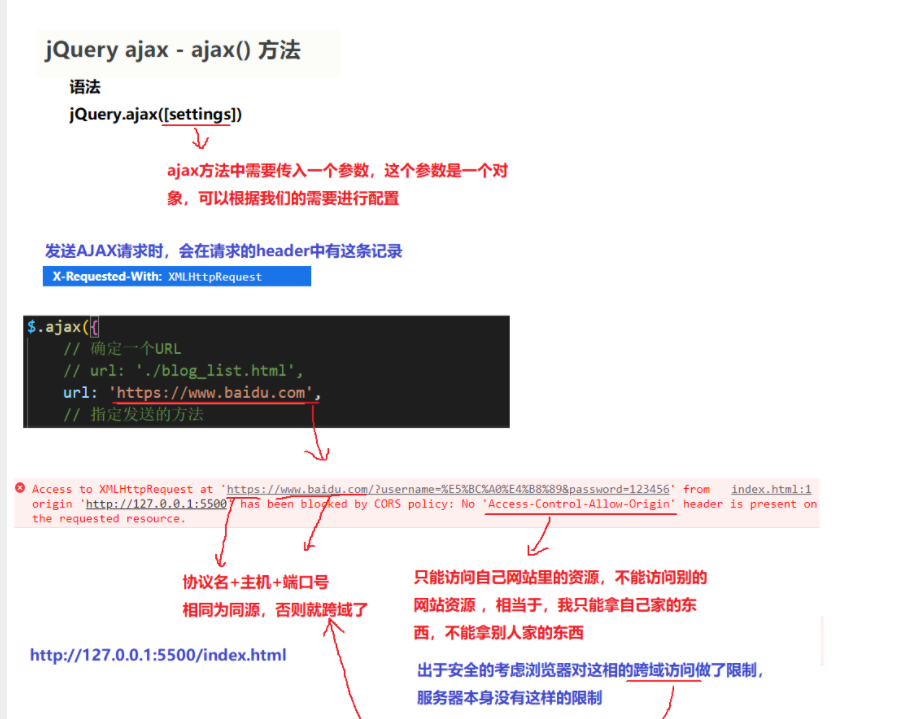
十.HTTPS协议
HTTPS协议是什么?
HTTPS协议也是一个应用层协议,是在HTTP协议的基础上进行了一层加密,这个加密层通常是TLS和SSL
HTTP协议是按照明文的协议进行数据传输的,这也就造成了一定的风险:数据在传输过程中存在被篡改的风险:
我们分析以下场景:当我们在网络中下载某个软件,当浏览器弹出下载框时,我们发现弹出来的下载软件并不是自己想下载的软件:
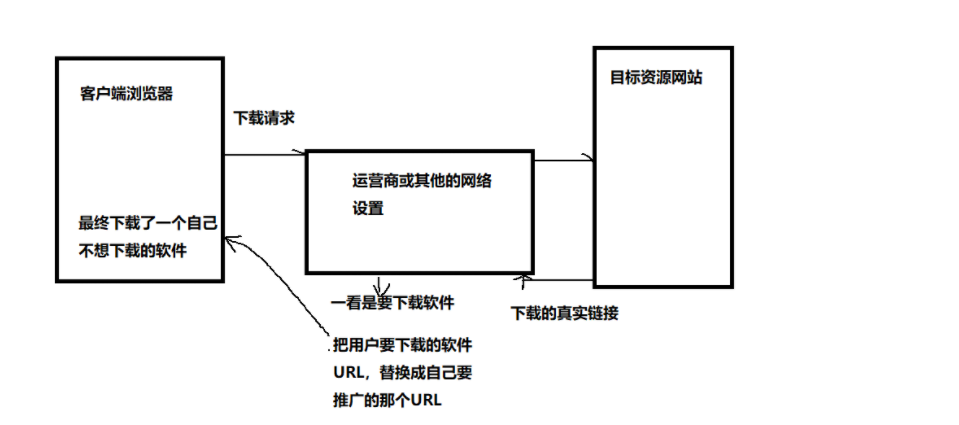
我们分析其中的问题:
正是因为以明文的形式进行数据传输,在获得响应的途中被别有用心的人发现这是一条下载响应,将对应的URL进行替换,来达到下载他自己推广的软件,而这个问题被称作‘运营商劫持’
所以我们要对传输的数据进行加密。
1.对称加密
何为对称加密?
对称加密其实就是通过同一个 "密钥" , 把明文加密成密文, 并且也能把密文解密成明文.
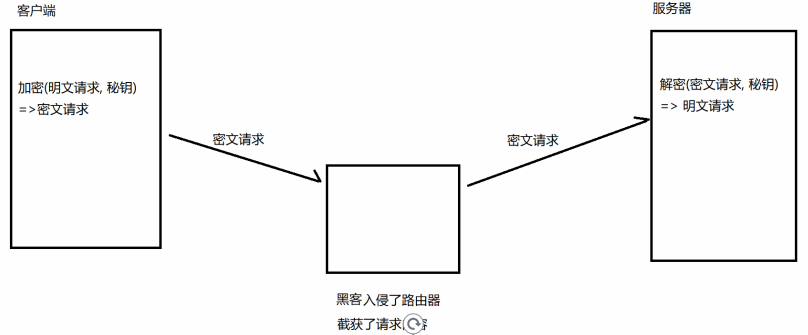
引入对称加密之后, 即使数据被截获, 由于黑客不知道密钥是啥, 因此就无法进行解密, 也就不知道请求的
真实内容是啥了.
但事情没这么简单. 服务器同一时刻其实是给很多客户端提供服务的. 这么多客户端, 每个人用的秘钥都
必须是不同的(如果是相同那密钥就太容易扩散了, 黑客就也能拿到了). 因此服务器就需要维护每个客户
端和每个密钥之间的关联关系, 这也是个很麻烦的事情~
比较理想的做法, 就是能在客户端和服务器建立连接的时候, 双方协商确定这次的密钥是啥~
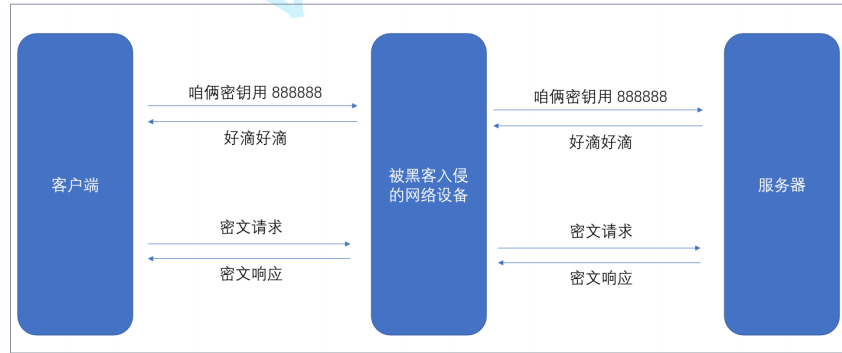
但是如果把密钥直接在网络传输中直接以明文传输,那么这个密钥也就是形同虚设了。
所以我们这时引入更安全的加密方式:非对称加密
何为非对称加密?
非对称加密就是存在一把公钥和私钥,对对称加密的密钥进行加密,如果使用公钥进行加密,必须用私钥进行解密,相反,如果用私钥进行加密,就要用公钥进行解密,私钥加密不能私钥解密,公钥同样也是如此。
除此之外,公钥在数据传输过程中由服务器传输给客户端,谁都可以获取,但是没有私钥,公钥也没什么用。这样,客户端服务端在初次加密时使用公钥将对称加密的密码进行加密,服务端用私钥进行解密,并在解开对称加密的密钥之后用这个对称密钥给客户端返回响应。
在后面数据传输的过程中,都使用这个对称加密进行数据传输。
由于对称加密的效率比非对称加密高很多, 因此只是在开始阶段协商密钥的时候使用非对称加密,
后续的传输仍然使用对称加密.
但是此时,新的问题又产生了,我们看以下的场景:
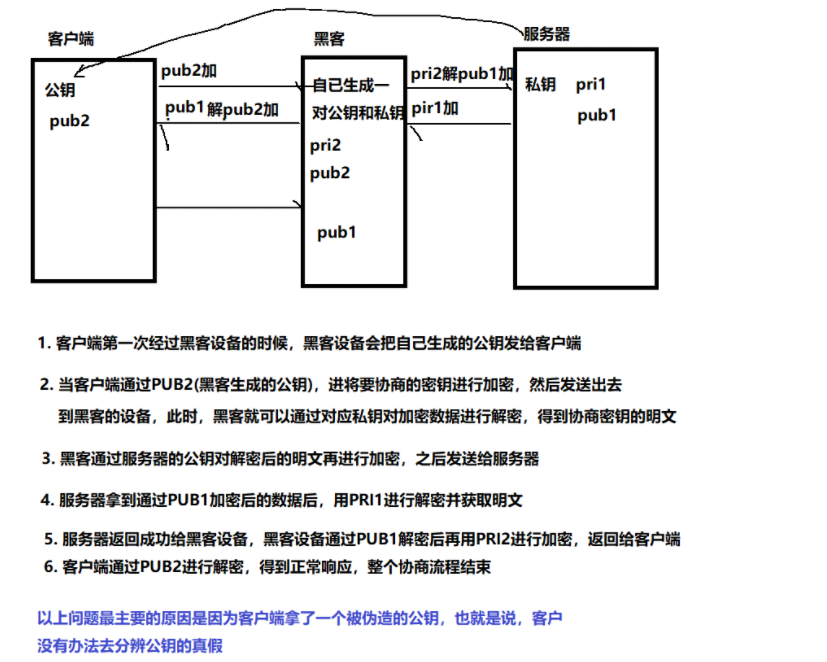
那我们又该使用什么策略来判断公钥的真伪呢?
这时引入证书:
在客户端和服务器刚一建立连接的时候, 服务器给客户端返回一个证书.
这个证书包含了刚才的公钥, 也包含了网站的身份信息.
这个证书可以理解成是一个结构化的字符串, 里面包含了以下信息:
证书发布机构
证书有效期
公钥
证书所有者
签名
......
我们如何判断证书的真伪呢?
1.判断证书是否过期
2.是否是我们所信任的机构颁发的
3.证书的内容是否生效:证书在颁布时存在一个签名:这是一个hash值(通过MD5算法计算),同时证书本身也会生成一个hash值(同样是MD5算法),一旦证书的数据被修改,证书的hash值就会被改变,但是在这个过程中,签名的hash值不会改变,那么我们的验证策略也相对比较简单了:通过比对签名的hash值和整个证书的hash值相比对,一致则有效,不一致则无效。
但是如果黑客把内容改了,也把数据通过md5算法重新计算,并把签名改为这个值,那么我们又该如何验证它的真伪性呢?
其实思路也相对简单:既然签名是一个比对标准值,那么我们让黑客没办法拿到这个标准值进行比对即可:同样引入一对公钥和私钥,对正数签名进行加密:私钥由证书颁发机构持有,不进行网络传输,由于该机构被信任,所以这个公钥在最开始就存在于我们的操作系统,当证书传来的时候,我们使用公钥进行对签名解密,然后再比对判断数据是否有效。
总结:
第一组(非对称加密): 用于校验证书是否被篡改. 服务器持有私钥(私钥在注册证书时获得), 客户端持有公
钥(操作系统包含了可信任的 CA 认证机构有哪些, 同时持有对应的公钥). 服务器使用这个私钥对证书的
签名进行加密. 客户端通过这个公钥解密获取到证书的签名, 从而校验证书内容是否是篡改过.
第二组(非对称加密):用于协商生成对称加密的密钥. 服务器生成这组私钥-公钥对, 然后通过证书把公钥
传递给客户端. 然后客户端用这个公钥给生成的对称加密的密钥加密, 传输给服务器, 服务器通过私钥解
密获取到对称加密密钥.
第三组(对称加密):客户端和服务器后续传输的数据都通过这个对称密钥加密解密.