从2013年成立开始,星环科技就专注于大数据基础技术与企业数据业务的更好结合,同时面对中国更为复杂的数据应用场景,研发了多种更贴合国内大数据应用需求的大数据管理技术,在大数据技术领域有多项基础技术突破。星环科技在坚持技术自研的道路上,创造了多个世界级的技术成果,本篇介绍星环科技大数据技术。

— 星环科技大数据技术概述 —
为了应对新的数据业务化需求,解决原有的技术问题,星环科技重新设计大数据技术栈,建立一个高度统一的数据平台,能够有效的解决大数据的4个V问题,打通大数据价值输出的技术链条,从而加速大数据从持久化、统一化、资产化、业务化到生态化的价值路径,这就是星环科技大数据3.0技术体系。

星环科技2015年即实现了基于Hadoop的分布式分析型数据库,是首个支持完整的SQL标准、存储过程、分布式事务的分布式分析型数据。同年推出低延时流计算引擎,在业界率先推出StreamSQL的SQL语言扩展,降低流应用开发的难度,同时推出延时低于5ms的计算引擎,远低于Spark Streaming的计算延时。
2017年在业内率先推出基于Docker和Kubernetes的大数据云服务,实现大数据产品更好的跨平台和云化能力,是业内最早采用Kubernetes技术的厂商,而Cloudera到了2020年Q3才完成相关的研发工作。
2018年发布支持万亿级图点和边数据的分布式图数据库,提供了强大的图分析与存储能力,加速了认知智能的计算。同年发布基于闪存的新一代分布式分析数据库,基于Raft协议和闪存自研的新一代列式存储,能够显著的提升交互式分析性能,满足数据仓库和全量数据交互式分析的场景要求。
— 设计考量与总体架构 —
在设计之初,我们定义新一代的大数据技术必须具有以下特点:
(1)统一融合的数据平台,取代混合架构
目前的企业数据业务架构中,往往需要包含数据湖、数据仓库、数据集市、综合搜索等不同数据系统,很多企业采用复杂的混合架构,不仅产生庞大的数据冗余,也严重限制了数据应用的时效性。新的大数据平台需要能一站式的满足所有需求,应对从快速响应到海量分析的各层级需求,淘汰混合架构的模式。
(2)开发方式的融合,SQL作为统一接口
SQL作为经过历史检验的结构化查询语言,具有庞大的用户群和灵活性,而以往通过API开发的方式存在应用兼容性差、开发难度高等问题。新一代大数据平台需要使用SQL来支持全部功能,包括数据仓库、在线交易、搜索引擎、时空数据库等,降低开发者门槛,加快产品开发与上线速度。
(3)大数据云化,推进大数据普惠化
云计算的弹性和随处接入可以让更多的数据业务和开发者使用大数据技术,因此新的大数据技术需要能够提供云化的能力。在硬件层面上,大数据平台对CPU、GPU、网络、存储等资源进行统一管理和调配,基于容器技术实现云上的大数据应用统一部署,平台租户按需申请大数据的技术和产品。
(4)大数据与应用生态的融合,支撑数据业务化和业务数据化
数据业务化是大数据技术最终的价值体现,在数据层面上,平台所有数据统一存储,建立统一的数据仓库与数据资产目录,各业务部门根据需求调用;在模型层,通过建立模型市场,租户训练好的模型可以选择一键发布至模型市场,其他租户直接调用。在应用层,平台内用户可将业务验证过的应用发布至企业级应用市场,共享给其他用户,所有运行的应用被统一管理。
为了满足企业对大数据的更高的融合要求,同时能够支撑新型的数据存储和计算要求,星环科技整体上重新设计了大数据技术栈,同时尽量保证各个层级之间由通用的接口来打通,从而保证后续的可扩展性,避免了Hadoop技术的架构缺点,同时逐步完成了大数据基础技术的自主研发,经过7年多的发展,整体技术栈已经基本完成了自研过程。

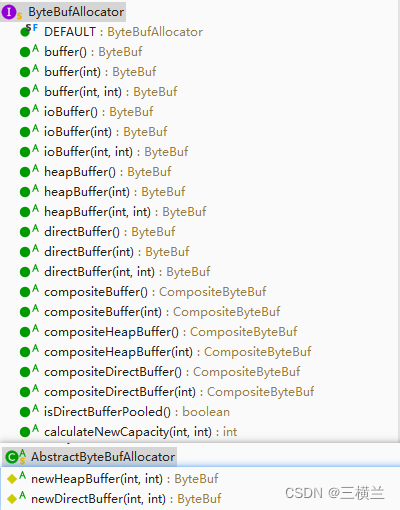
上图是星环科技大数据技术栈的逻辑架构图。自下而上,最底层是可以管理和调度各种计算任务的资源调度层,我们选择基于Kubernetes技术来打造。随着数据应用的发展,计算任务不仅仅只是MapReduce,还可能是Spark、深度学习,甚至是MPI类的高性能计算任务,也可以是弹性的数据应用,因此专门为Hadoop设计的YARN就无法满足需求。通过对Kubernetes和大数据底层的创新,我们的资源调度层不仅可以支撑各种计算任务,还可以与云计算底层打通,解决大数据云化的问题。
为了更好的适应未来的数据存储与分析的需求,支撑各种新的存储引擎,我们抽象出了统一存储管理层,能够插拔不同的存储引擎来实现对不同类型的数据的存储、检索和分析的请求。未来针对某些特定的应用可能都会有专用的分布式存储引擎来支撑,在使用统一的分布式块存储管理层之后,架构师们只需要设计一个单机版本的存储引擎或者文件系统,并接入存储管理层,就可以实现一个分布式存储引擎,支持分布式事务、MVCC、索引、SQL表达式下推等功能,这样可以极大的降低存储开发的复杂度。
在块存储管理层之下就是各个数据库内核或存储,包括用于分析型数据库的列式存储、NoSQL的Bigtable、打造搜索引擎的全文索引、面向图计算的图存储引擎等,这些引擎接收上层的执行计划,然后生成对存储层的scan/put/write/事务等操作,完成特定的处理任务。
在存储层之上就是统一的计算引擎层,我们选择了基于DAG的计算模式来支持大数据的各种计算。相对于MPP模式,DAG计算能够更好的适合大规模集群之间的各种通信和计算任务,并且有更高的可扩展性,能够满足包括图计算、深度学习在内的多迭代的计算特性,同时通过代码生成等技术,也可以将性能优化到非常接近native代码的水平。
最上面是统一的开发接口层,对分析数据库、交易数据库等,我们通过标准的SQL开发接口提供给开发者,降低数据开发和分析的复杂度。此外,通过完善的SQL优化器设计,可以做到无需特殊的优化,SQL业务也能有非常高的性能,甚至比直接API级编程更好,而无需了解底层架构的细节。对于图数据库,我们提供Cypher语言接口,而优化器系统则全部复用SQL优化器。此外,开发接口层还提供了统一的事务处理单元,从而保证数据开发都有完整的事务保证,确保数据的ACID。
— 开发接口层 —
统一的开发接口层的核心是SQL编译器、优化器和事务管理单元,它可以提供给开发者比较好的数据库体验,无需基于底层API来做业务开发,保证对传统业务的支持程度,还可以更好的优化业务。

不同于传统的大数据SQL引擎(如Hive),我们重新设计了SQL编译器,它包含了三个Parser,可以从SQL、存储过程或者Cypher语句生成语义表达式,以及一个分布式事务处理单元。一个SQL经过Parser处理后,会再经过4组不同的优化器来生成最佳的执行计划,最终将执行计划推送给向量化的执行引擎层。
-
lRBO(Rule-Based Optimizer)根据已有的专家规则进行优化,不同的存储引擎或者数据库开发者会提供专门的优化规则,目前我们已经积累了数百条优化规则。其中,最有效的优化规则都是针对IO相关的优化,如过滤下推、隐式过滤条件折叠、基于分区或分桶的IO优化、Partition消除、多余字段消除等技术,将SQL中能够节省掉的各种IO操作尽最大可能的消除,从而提升整体性能。
-
ISO(Inter SQL Optimizer)用于存储过程内部的优化,当一个存储过程里面有多个SQL存在类似的SQL查询或分析的时候,它可以将这些操作合并在一起,从而减少不必要的计算任务或者SQL操作。为了让存储过程有较好的性能,PL/SQL解析器会根据存储过程中的上下文关系来生成SQL DAG,然后对各SQL的执行计划进行二次编译,通过物理优化器将一些没有依赖关系的执行计划进行合并从而生成一个最终的物理执行计划DAG。因此,一个存储过程被解析成一个大的DAG从而stage之间可以大量并发执行,避免了多次执行SQL的启动开销并保证了系统的并发性能。
-
MBO(Materialize-Based Optimizer)是基于物化视图或Cube的优化器,如果数据库中已经有物化视图或Cube已构建好,而SQL操作能够基于这个物化对象来优化的话,MBO就会生成对相应的物化对象的操作,从而减少计算量。
-
CBO(Cost-Based Optimizer)即基于成本的优化器,它会根据多个潜在的执行计划的IO成本、网络成本和计算成本来选择一个最佳的执行计划,而成本的估算则来自元数据服务。在未来,我们还计划引入机器学习的能力,通过对历史执行SQL的统计信息的有效分析,生成更加健壮的执行计划。一些非常有效的优化规则包括多表Join顺序调优、JOIN类型选择、任务并发度控制等。

SQL编译器和优化器对大数据技术栈非常关键,正如我们在前序章节的分析结论,它是能够决定整个技术的生态建设能否成功的关键。除了SQL接口外,分布式事务和接口对大数据技术栈也是非常关键的组成。可以复杂的系统架构和容错设计下保证数据的一致性,以及有多种事务隔离级别的支持,从而能够拓展数据库去支撑更多的应用。
— 计算引擎层 —
我们的执行引擎选择了基于DAG的模式,此外为了有更好的执行效率,我们使用量化执行引擎技术来加速数据处理。量化执行引擎即每次计算对批量的数据进行处理,而不是逐个记录。对列式的数据存储,向量执行引擎有非常高的提速效果。另外与学术界很多研究进展相似,星环科技也采用的是同一个计算引擎支持实时计算和离线计算,从而更好支持流批统一的业务场景。
在解决数据库的计算性能的可扩展性的方法上,目前主流的计算框架有两种,一种是基于MPP(Massive Parallel Processing)的加速方式,另一种是基于DAG(Directed Acyclic Graph)。整体上来看,基于MPP的方式在容错性、可扩展性和对业务的适配上灵活性不足,不能满足我们对未来多样化的数据服务支撑的需求,因此我们选择了基于DAG的计算模式,同时在它的基础上深度优化执行性能,既能支持更多样化的数据计算需求,也能够获得极致的性能。
| 技术点 | MPP | DAG |
| SQL编译 | 依赖单机数据库的SQL能力 | 自研SQL编译器 |
| 数据存储 | Share nothing架构 | 共享分布式存储架构 |
| 元数据信息 | 比较有限的meta信息,全局的计算任务的优化有难度 | 有全局的meta信息,可以更好地协调executor之间的数据通信、任务启停 |
| Shard内性能 | 本地库的执行速度高,理论上是DAG的上限 | 可以通过执行器、Codegen等技术来优化性能 |
| 容错性 | 依赖各个数据库完成切分任务,因此容错性不足 | 共享数据存储,Task的设计上可以简单、有幂等性,更好容错 |
| 数据通信性能 | 依赖数据分布来减少数据通信的性能损耗,因此不灵活 | 依赖全局的数据元信息来减少通信的性能损耗,更加灵活 |
| 核心优势 | 优化器成熟,本地执行性能更好 | 灵活性、容错性更高,能够更好的减少数据通信消耗 |
| 架构问题 | 总体性能依赖业务特性和数据分布 部分MPP的可扩展性还需要提高 | SQL、事务、优化器等仍需持续改进,基本逼近MPP的性能 |
从2018年开始,企业对实时计算的需求的增长非常迅速,此外由于实时计算多是生产系统,相对于分析系统在技术上也有更高的要求,包括:
-
高并发:瞬间高并发的数据操作或者分析
-
低延时:要求毫秒级的处理响应时间
-
准确性:数据不丢不重、业务高可用
-
业务连续性:在线对接生产的数据业务
为了能够系统的适应业务需求,我们放弃了对Spark或者Flink等开源方案,而是完整的设计了整个的实时计算产品。首先,我们重新设计了流计算引擎的计算模式,保证其对数据流的计算延时能够低至5毫秒级别,同时必要完整的设计了整个数据通路,确保其数据的不丢不重,以及整个链路的安全性。
此外,在计算模式上,流数据不仅可以跟其他时间窗口的数据进行复杂计算,还需要跟历史数据(持久化在各种数据库中的数据)进行计算,因此我们引入了CEP引擎(Complex Event Processing Engine),能够对多个输入事件进行计算,执行包括复杂模式的匹配和聚合计算等,也支持各种滑动窗口类计算,同时也可以与历史数据或持久化数据进行关联计算。
对于复杂的应用业务,我们设计了规则引擎(Rule Engine)来处理业务规则,并且可以兼容其他规则引擎设计的业务规则,从而可以实现复杂的业务规则。最后为了更好的应对业务指标,我们也在流引擎中增加了基于内存的分布式缓存,用于加速数据指标的高速存储和读取,同时支持数据的订阅与发布。
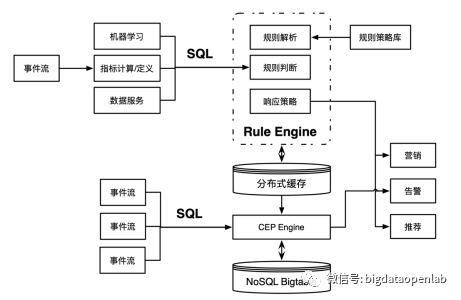
在SQL模型层,我们定义了StreamSQL的SQL语言扩展,新增了Stream、Stream Application和Stream Job等对象。一个Stream用于接收从一个数据源传来的数据,可以是直接接收,也可以对数据进行一定的转换操作。一个Stream Job定义了具体的流上的数据操作逻辑,如规则匹配逻辑、实时ETL逻辑等。一个Stream Application是一组业务逻辑相关的Stream Job的组合。
| USE APPLICATION cep_example; CREATE STREAM robotarm_2(armid STRING, location STRING) tblproperties( "topic"="arm_t2", "kafka.ZooKeeper"="localhost:2181", "kafka.broker.list"="localhost:9092" ); CREATE TABLE coords_miss(armid STRING, location STRING); INSERT INTO coords_miss SELECT e1.armid, e1.location FROM PATTERN( -- 当机械臂经过位置A后未经过位置B,则预警 e1=robotarm_2[e1.location='A'] NOTNEXT e2=robotarm_2[e2.armid=e1.armid AND e2.location='B'] ) WITHIN ('1' minute); |
— 分布式块存储管理层 —
统一的分布式块存储管理层,是我们对新一代大数据技术做的重大改造。数据的一致性是分布式系统的根基,Paxos协议的出现在理论上保证其可行性,而之后更加简洁的Raft协议在工程的实现上更加高效。而工程上多个开源分布式存储在实现数据高可用和数据一致性的方式上也有不少的不足。譬如Cassandra在架构上能够保证高可用,但是它会存在Replica数据不一致的问题,此外也无法支持事务性操作;HBase底层使用HDFS保证数据持久化和一致性,但是HMaster采用了主备的方式,切换过程可能比较长,因此有单点故障问题,不能保证可用性;Elasticsearch也类似,分区内数据的一致性在生产中也是一个问题。
随着企业数据业务发展的深入,更多的专用存储引擎的需求会被引入,譬如专门面向地理信息的数据存储与分析、图数据、高维度特征的存储与计算等专用场景,再加上对现有的4大类NoSQL存储的需求,针对每个场景去实现单独的存储引擎工作量非常大,也有重复造轮子问题。
为了解决这个问题,我们将各个分布式存储的通用的部分抽象出来放在存储管理层,包括数据的一致性、存储引擎的优化接口、事务的操作接口、MVCC接口、分布式的元数据管理、数据分区策略、容错与灾备策略等功能,通过自研的基于Raft的分布式控制层来协同各个角色。各个存储引擎只需要实现其单机的存储引擎,然后接入统一的存储管理层就可以成为一个高可用的分布式存储系统。

在实现上,我们使用Raft协议来做各个存储之间的一致性保证,主要包括:
-
各个单机存储组成的tablet副本之间的状态机同步
-
Master的选主和状态机同步
-
事务协同组的选主和状态机同步
-
存储服务的恢复服务能力
-
其他管理运维能力
— 资源调度层 —
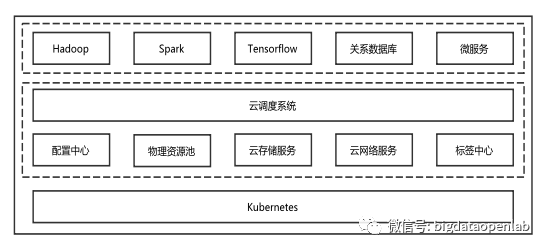
类似于操作系统的调度模块,资源调度层是整个大数据平台能够有效运行的关键技术。下图是资源调度层的总体架构,最底层是Kubernetes服务,在其上层运行着我们自研的产品或服务。其中配置中心用于实时的收集和管理云平台内运行的服务的配置参数;物理资源池是通过各个资源池化后的逻辑资源;云存储服务是基于本地存储开发的分布式存储服务,会持久化有状态服务的数据,保证应用数据的最终持久化和系统灾备能力;云网络是自研的网络服务,提供应用和租户类似VPC的网络能力。在此之上是云调度系统,它接收应用的输入,从配置中心、标签中心、云存储和网络服务中获取实时的运行指标,从资源池中获取资源的使用情况,从而根据运行时的信息进行精确的调度决策。调度系统之上就是各类的应用服务,包括大数据、AI、数据库类,以及各种微服务,也就是云平台可以良好支撑的各种应用。
— 小结—
本篇介绍了星环科技大数据技术,未来星环科技将继续完善这个新的大数据架构体系,增加更多的新型数据存储与计算能力,同时完善数据业务化的技术拼图,包括基于机器学习的数据治理、数据服务发布等能力,进一步夯实数据与业务之间的技术缺口,让大数据技术更好的发挥出价值。





![[MAUI 项目实战] 手势控制音乐播放器(四):圆形进度条](https://img-blog.csdnimg.cn/eaecf39b83074eb79c774b56c21145ea.gif)